Most people don't lose evictions in court. They lose before they ever get there.
Quick reality check. In the US there are around 2.6 million eviction filings every year (Eviction Lab). Landlords show up with a lawyer about 80% of the time. Tenants? Around 3%. And here is the part that actually kept me up at night: a huge number of people don't lose because they had no case. They lose because they missed a deadline. You get served, a clock starts, and if you don't file a written response in time, the landlord can win automatically. No hearing. No story you get to tell. Just gone.
So the thing that decides whether someone keeps their home often isn't "did you have a defense." It's "did you know the date, and did you put something on file by it." That is a brutal way to lose, and it is exactly the kind of problem software should be able to help with.
The detail that broke my brain
Here is what pushed me to actually build this. In 2025, California changed the law. AB 2347 doubled the time a tenant gets to respond to an eviction, from 5 court days to 10. Good change. Except if you search it today, a ton of pages, blogs, even some legal sites, still say 5 days. So a normal AI chatbot, trained on the open internet, will confidently hand you the wrong number. And in this exact situation, the wrong number can cost you your home.
That is the entire reason DueProcess exists. Not "AI that sounds smart." AI that is grounded in current, official sources, and that actually knows when to shut up.
What it does
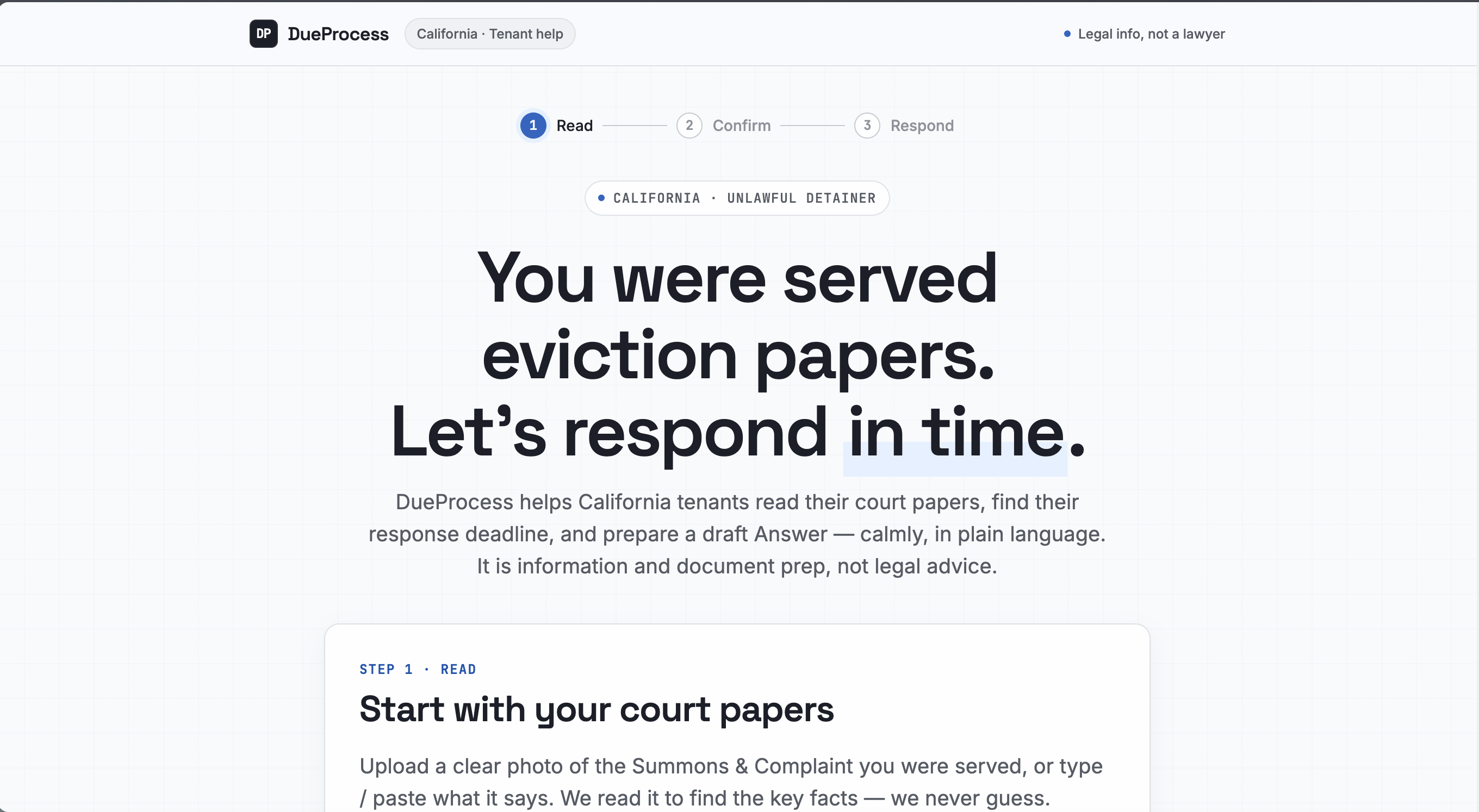
DueProcess is basically an AI caseworker for someone facing eviction who can't afford a lawyer.
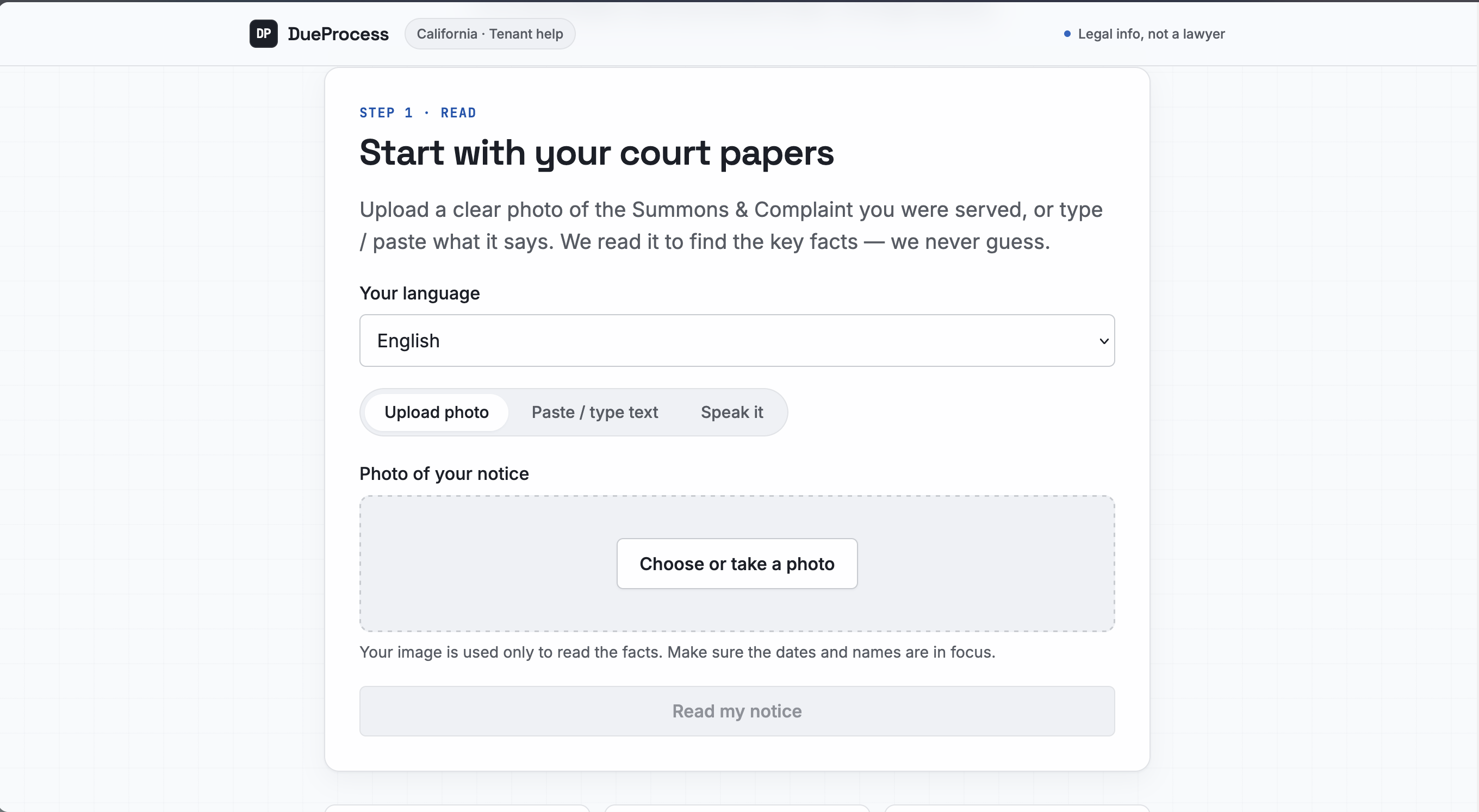
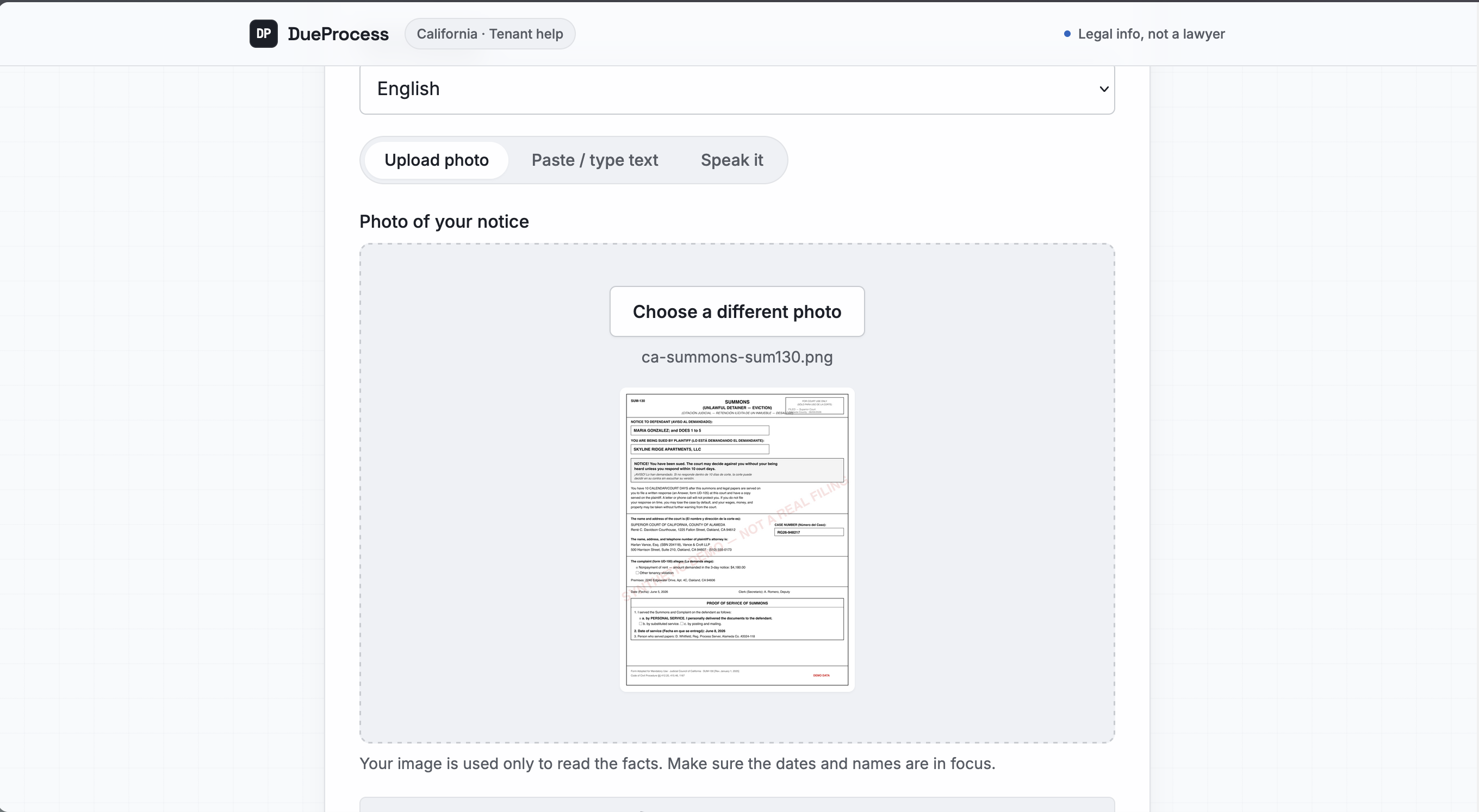
- You upload a photo of the court papers you were served. A vision model pulls out the facts: who is suing you, when you were served, and how.
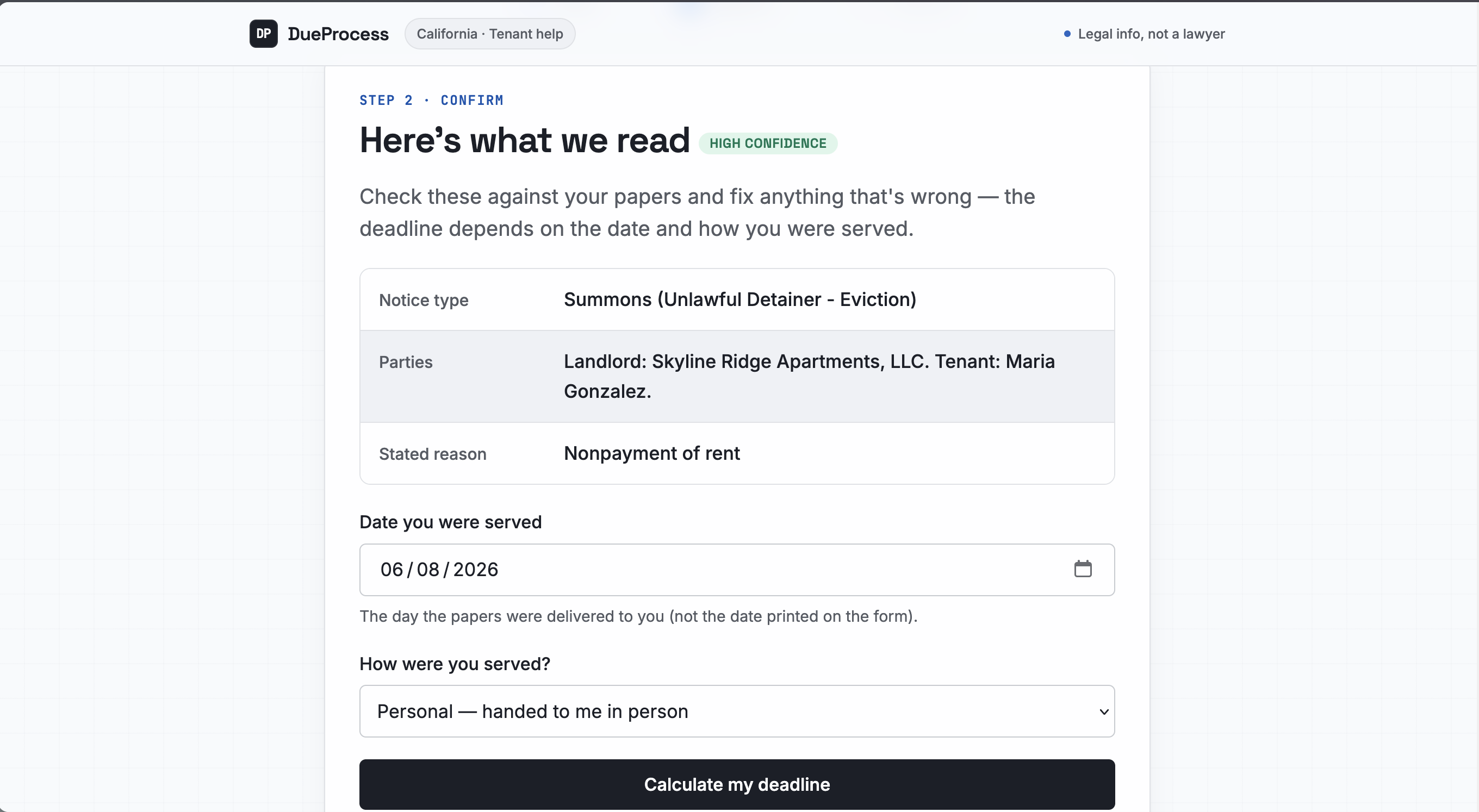
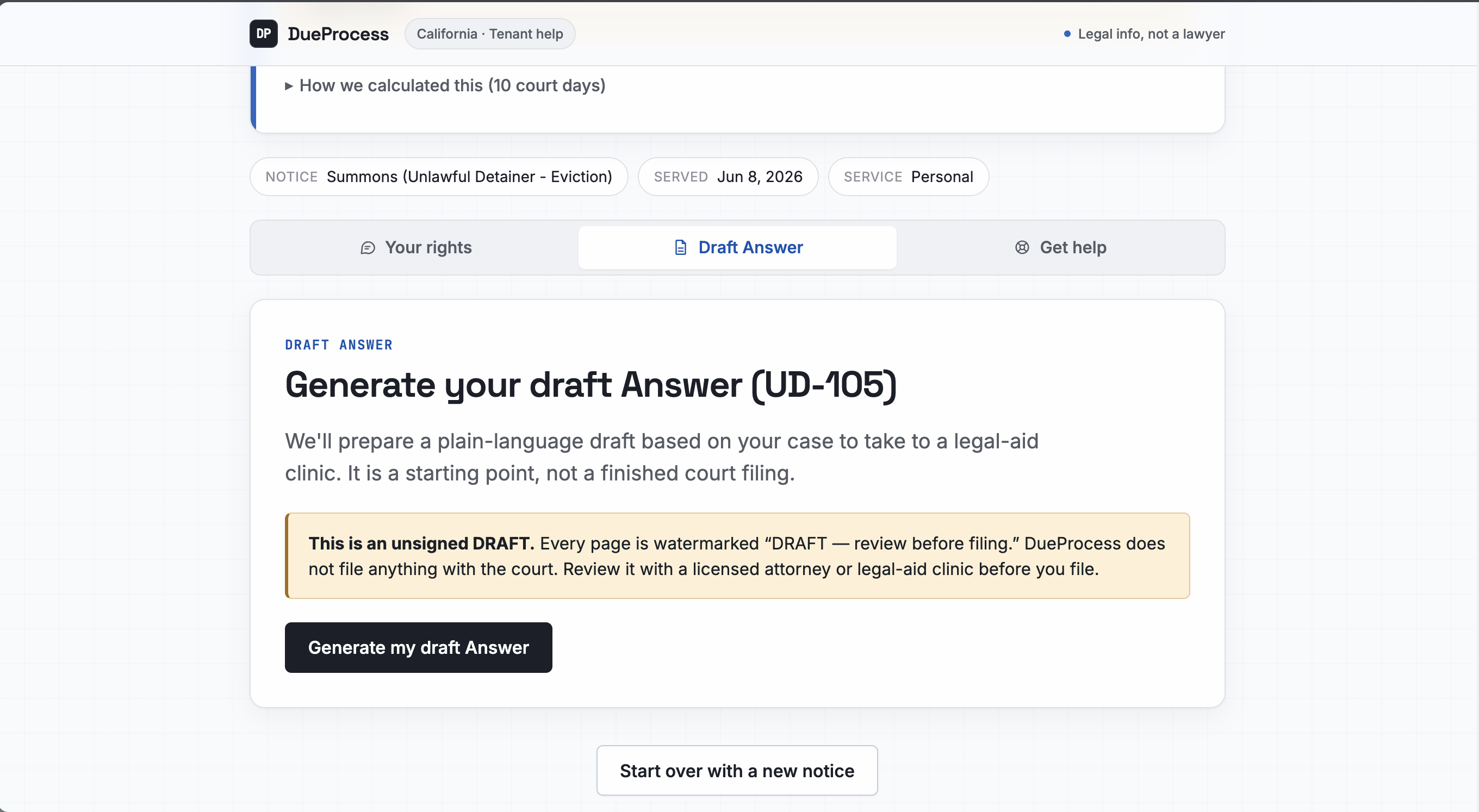
- It computes your actual deadline. Not with the LLM. With deterministic code that counts court days, skips weekends and California court holidays, and gives you the exact date you have to respond by. It always tells you to confirm with the court, because it is careful on purpose.
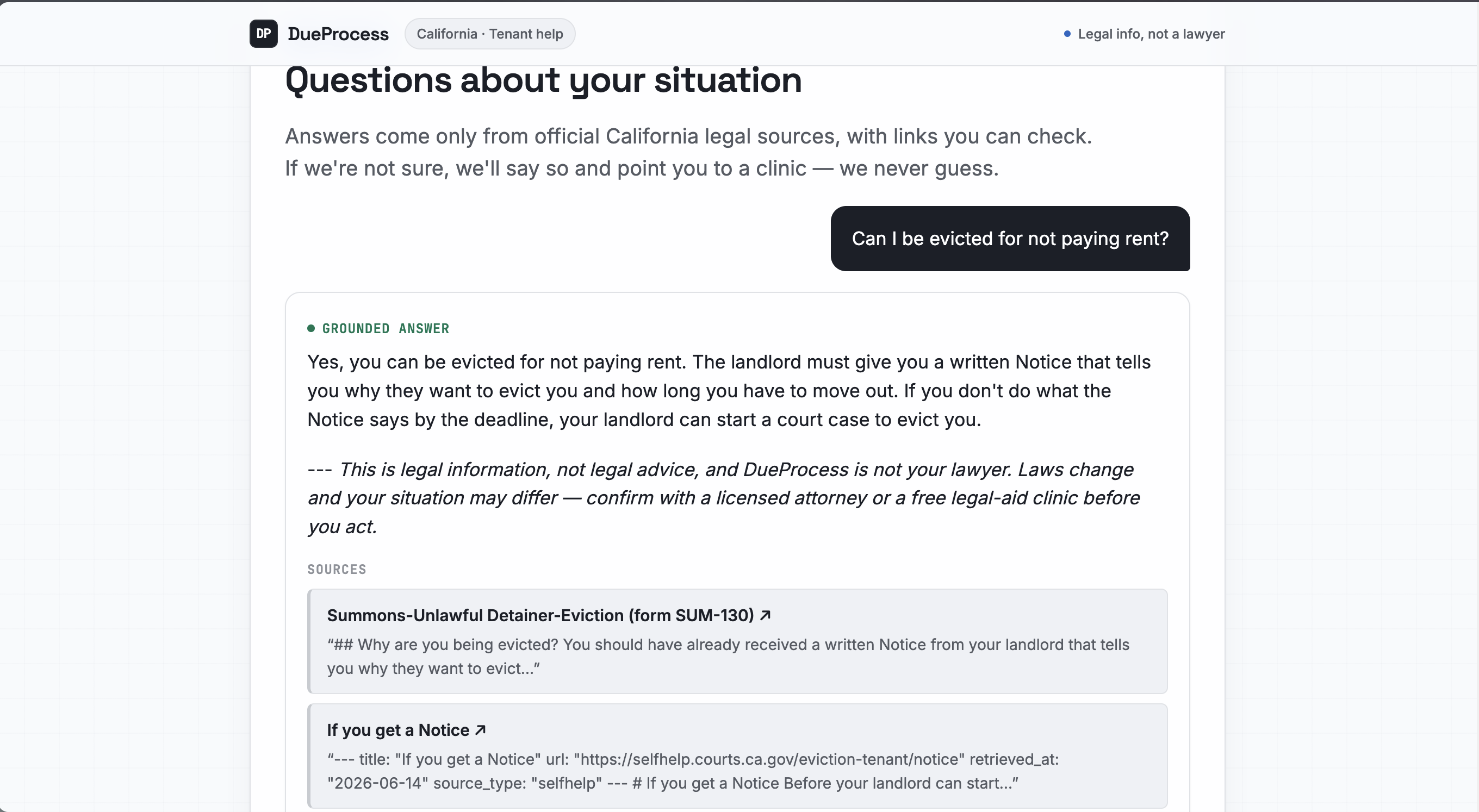
- You can ask it about your rights, and every answer is built only from official California sources, with a citation on every claim. Ask it something it isn't sure about, or something outside what it actually knows, and it refuses and points you to a real legal aid clinic instead of making something up.
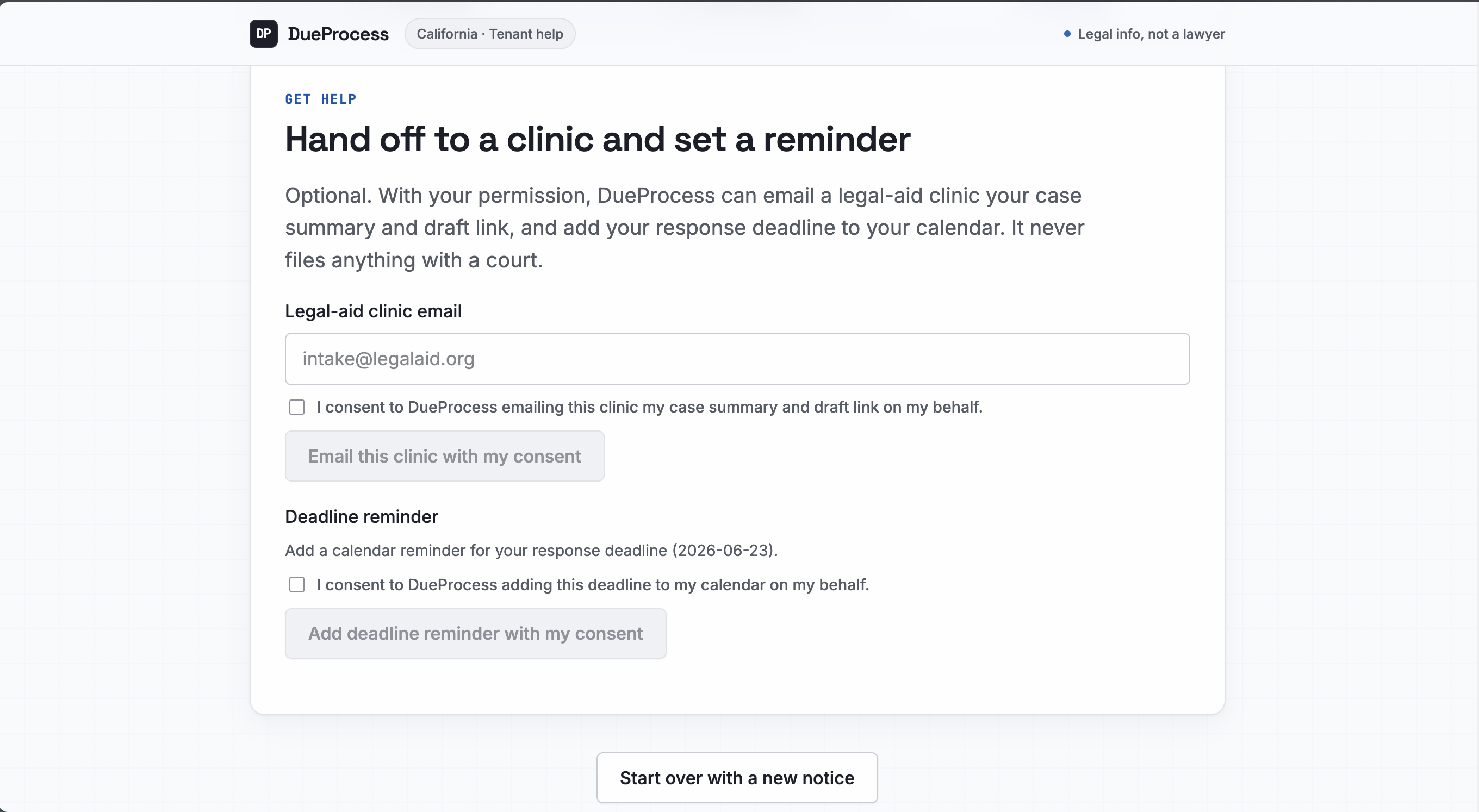
- It drafts your response as a clearly watermarked DRAFT for you to review and file, can set a reminder before your deadline, and can email a legal aid clinic. It never files for you, and it never pretends to be your lawyer. ## How it works under the hood
The core design decision is a hard split between perception and computation, and honestly this is the part I am most proud of.
LLMs do the soft stuff: reading the photo, writing plain-language answers, drafting prose. Deterministic code does anything that actually matters legally and can be checked. The deadline is the obvious example:
$$\text{deadline} = \text{nthCourtDay}(\text{serviceDate} + 1,\; n = 10)$$
where court days exclude weekends and California court holidays. The model never picks that date. Code does. So if the model has a bad day, the worst case is clunky wording, not a wrong legal deadline.
For answers, I built retrieval over a corpus of current California court self-help pages, statutes (CCP 1167, 1162, 1170.5), and the official forms, using hybrid search (semantic plus keyword) via Cloudflare AI Search. Then two guardrails, enforced in code and not vibes:
- Cite or abstain. If a legal claim doesn't map to a retrieved source, it does not get shown. No citation, no claim.
- Confidence gate. If retrieval is weak or the question is out of scope, it abstains and hands off to legal aid. Everything runs on open-source models on Cloudflare's edge. Llama 4 Scout reads the notice (natively multimodal), Kimi K2.6 handles the grounded reasoning and drafting. State lives in D1 (cases, deadlines, documents), R2 (uploaded notices and generated drafts), and Durable Objects (which fire the deadline reminders). mem0 keeps case memory across sessions, so it behaves like an actual ongoing caseworker and not a goldfish. The whole thing is one Next.js app deployed to Cloudflare Workers through OpenNext.
Why you can actually trust this one
There was a famous "robot lawyer," DoNotPay. In 2025 the FTC came down on it, partly over missed deadlines and unusable documents, after it came out that they never actually tested whether the thing worked. That story hangs over this entire space.
So I did the opposite. I evaluated it. I ran the pipeline against Stanford RegLab's housing_qa benchmark and measured retrieval accuracy, answer accuracy, and how often it correctly refuses: [drop your real numbers here]. The point is not "trust me." The point is "here are the numbers, and here is a system built to be right or stay silent."
How I built it (the actually cracked part)
I built this from scratch during the hackathon. The build itself was an AI orchestration run: Devin AI running Claude Opus 4.8 across multiple parallel git worktrees in tmux, each agent owning one isolated module against a frozen set of shared contracts so they could move in parallel without stepping on each other. i steered the model whenever it went wrong, and also fixed it's errors manually before committing
i am using kimi 2.6 model via cloudflare workers AI
Challenges I ran into
Legal accuracy is unforgiving. There is no "eh, close enough." A wrong date is somebody's home. Making sure the system never invents a statute, a citation, or a deadline meant ripping the consequential math out of the model entirely and making uncited answers literally impossible to return.
Current law versus stale training data. The 5 versus 10 day thing forced a strict "only ground to current official sources" rule across the whole pipeline.
And the hardest one, weirdly: making it refuse well. Building something that answers is easy. Building something that knows the edge of what it knows, and stops there, took more effort and matters more.
What I learned
For high-stakes social good AI, the trust architecture is the product. Grounding, abstention, deterministic computation of anything that matters, and real measurement. A flashy model with no guardrails is worth less than a careful system that knows its limits. The model is the easy part now. The judgment built around it is the actual job.
What's next
More states (the corpus is built to swap in new jurisdictions), full multilingual and voice intake for people who can't easily read a dense legal notice or don't speak English, and partnering with legal aid organizations for real warm handoffs and accuracy feedback. To work with a legaltech law firm and get this reviewed by the SMEs
The honest part
DueProcess gives legal information and helps you prepare documents. It is not legal advice, and it is not a lawyer. Right now it covers California only. Everything it generates is a draft for you to review and file yourself. It is a bridge to overworked legal aid clinics, not a replacement for one. Always confirm your deadline with the court.
Built With
- ai
- claude
- cloudflare
- cloudflare-ai-search
- cloudflare-d1
- cloudflare-r2
- cloudflare-workers
- cloudflare-workers-ai
- composio
- devin
- durable-objects
- fastapi
- hugging-face
- kimi-k2.6
- llama-4-scout
- llm
- mem0
- next.js
- opennext
- opus
- python
- simple-legal
- tmux
- typescript


Log in or sign up for Devpost to join the conversation.