
Inspiration
AI-generated content is fluent, fast, and persuasive — but often unchecked. We noticed that most AI tools optimize for output speed, not trust. DuckPod was inspired by a simple question: What if AI had to earn credibility instead of assuming it?
What it does
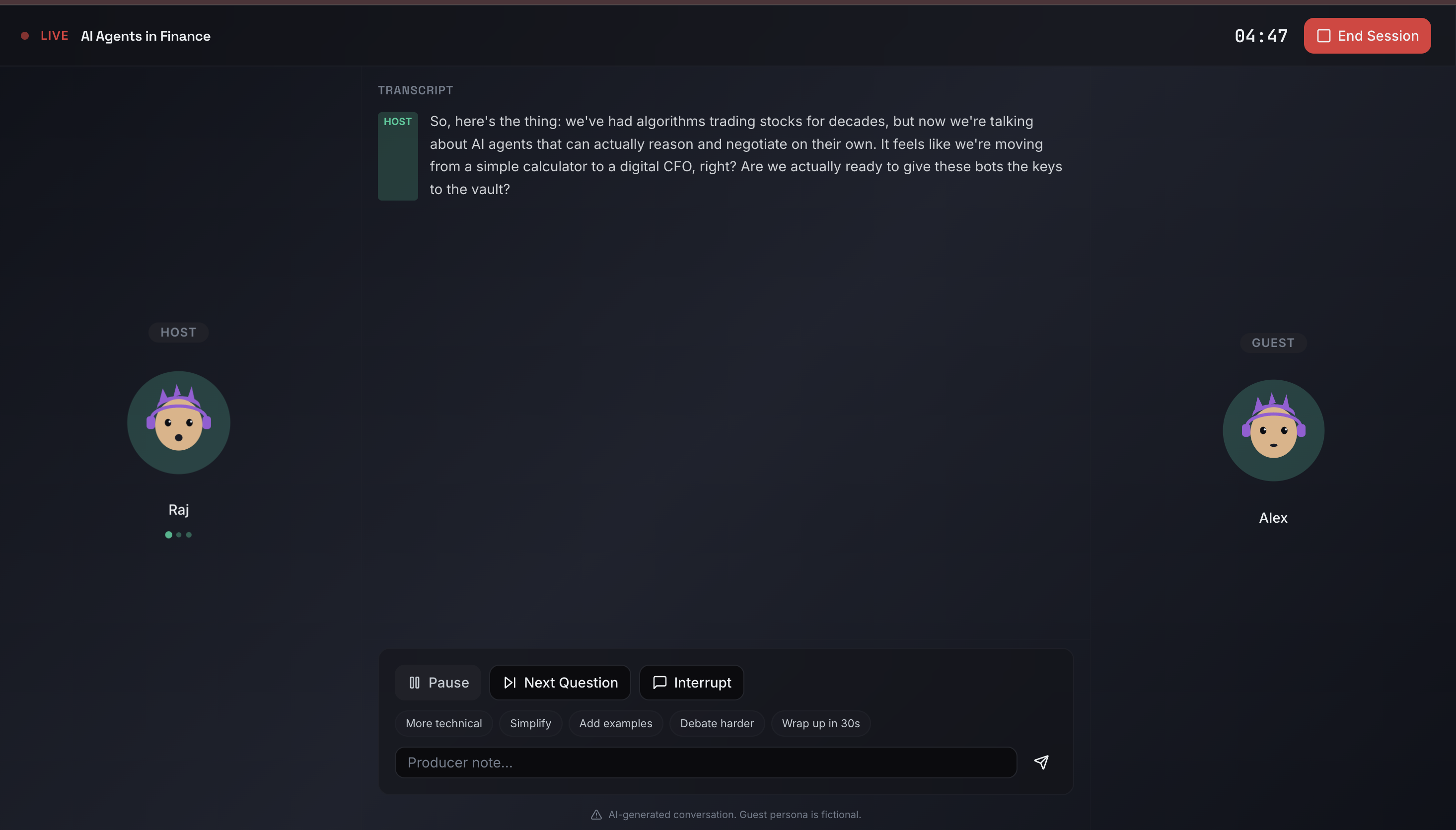
DuckPod is a human-first AI podcast Agent. It generates short AI-hosted podcast episodes and then requires a structured human audit. After listening to an episode, users evaluate it using a trust rubric: Grounding (facts vs vibes) Consistency Transparency Manipulation resistance Usefulness
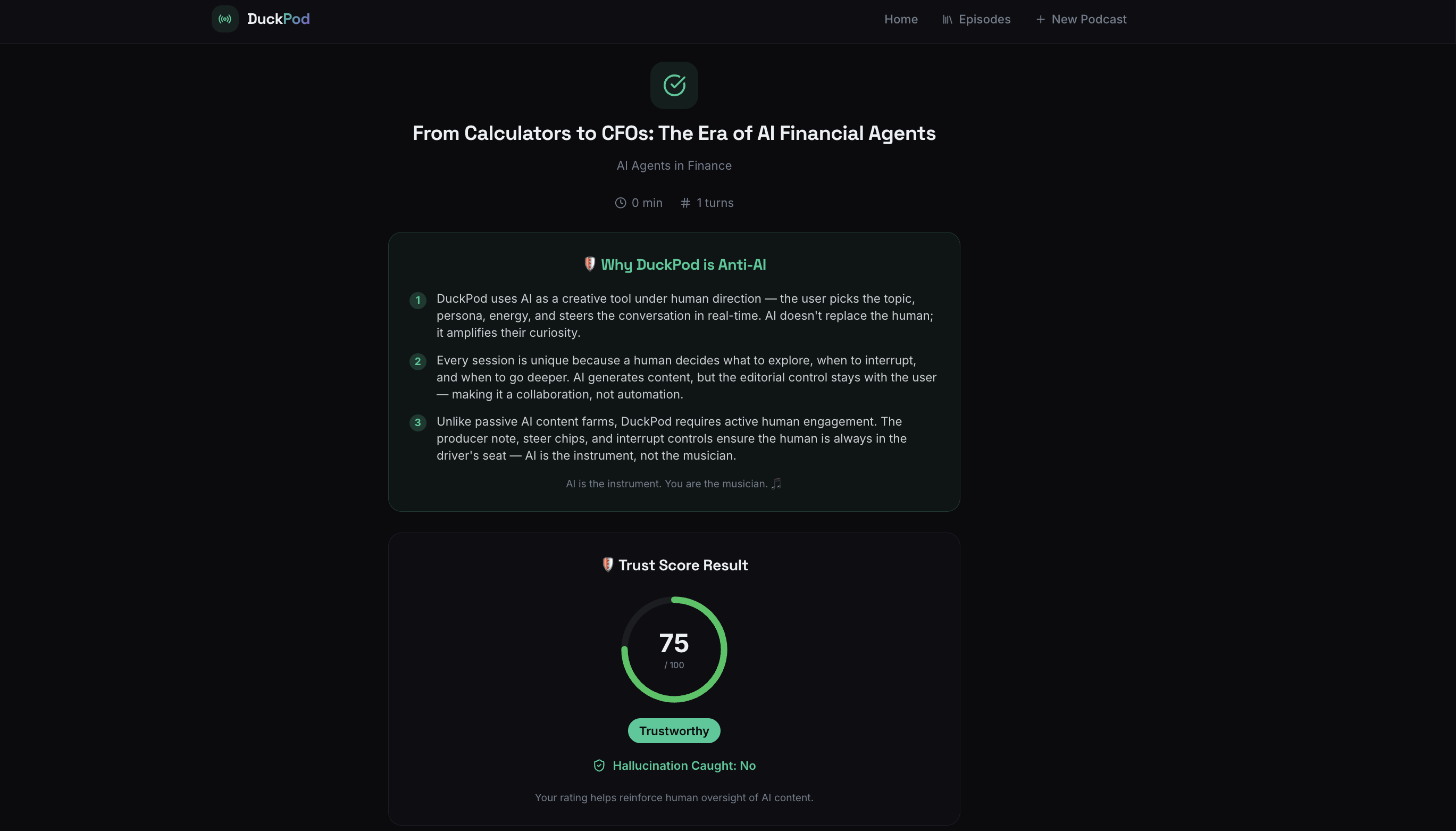
The system computes a Trust Score (0–100) and flags potential hallucinations. AI speaks. Humans decide if it deserves trust.
How we built it
Frontend built using Lovable with a structured multi-page flow
Gemini API for podcast script generation and claim extraction
NodeJS and Supabase for session storage, reflections, and trust score persistence
Deterministic scoring logic for Trust Score and hallucination detection
Human-in-the-loop evaluation layer to enforce accountability
We designed it as a state-driven flow: Setup → Studio → Reflection → Trust Report.
Challenges we ran into
Making AI outputs structured enough for auditing
Designing a scoring system that felt fair but decisive
Preventing AI from “judging itself”
Balancing simplicity with meaningful evaluation
Ensuring the Trust Score felt transparent, not arbitrary
Accomplishments that we're proud of
Built a full human-audit layer over AI-generated content
Created a weighted Trust Score that prioritizes grounding
Implemented deterministic hallucination detection logic
Delivered a clean audit-style UI that reinforces human authority
Positioned AI as a tool, not a decision-maker
What we learned
AI fluency can mask uncertainty
Trust requires structure, not vibes
Human-in-the-loop design is powerful
Accountability mechanisms increase confidence
Clear scoring systems reduce ambiguity
What's next for DuckPod
Citation-required mode with live source validation
Adversarial questioning mode
Multi-model comparison (Gemini vs others)
Confidence gap detection (AI confidence vs human trust)
Shareable Trust Cards for AI literacy education
Built With
- css
- elevenlabs
- gemini
- javascript
- mistral
- next.js
- node.js
- python
- react
- tailwind
- typescript
- voice

Log in or sign up for Devpost to join the conversation.