Domain-Specific Search Engine
DSSE, pronounced dɐs'ɪ, is a comprehensive implementation of the entire stack required for Search Engines. DSSE uses Term Frequency–Inverse Document Frequency to predict cluster levels, and works on the concept of a knowledge base, creating an ontology for the domain-specific data that exists. DSSE is implemented on all layers, from a web crawler, to indexing (including a refinement using the above mentioned clustering algorithm) and a web application with a chatbot interface for queries.
The domain for this Implementation is Walmart, a hugely popular e-commerce website.
Table of Contents
About
Idea
Domain Specific Search Engines are bound to be more efficient than a general purpose graph based engine. This is because an effective ontology can be created and an useful knowledge base can then be traversed, with the words being semantically close to each other. A simple but effective WordNet (for example, the one maintained by Princeton) can be used to traverse a crawled domain specific database. Moreover, a chatbot interface is easy to use and has higher reach, which is why we have used it as our interface.
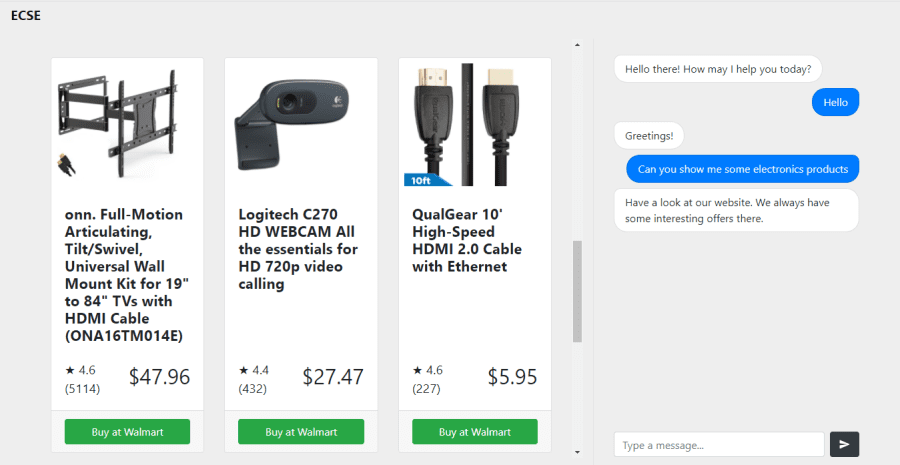
And well, here is the result!

As you can see, we have implemented a search assistant associated with the the search service that effectively enables the user to pass his queries in plain ol' English.
Why is this important?
- Provide Instant Support With The Right Context
- 98% of your visitors will leave without converting if you don't engage them proactively on your website
- Save Time Answering FAQs With Automation

Web-Crawling
We crawled through about 2k pages - to get 20k objects, This was done through parcel, in Python. The objects were fetched with several smart timeouts and using Cloud-powered speed to usefully scrape a large E-Commerce Website (Walmart).
Indexing
We indexed all the crawled objects using their links, and the categories they belonged to, in an hierarchical structure, using a Knowledge Base. The data was cleaned, and the categorical similarity was expressed using the "related tags" information we scraped.
Clustering
We start with the numerical statistic, the TF-IDF, commonly used in Information Retrieval tasks in NLP. This numeric effectively converts the unique tags of a product, and creates a singular data-point per product for the next algorithm.
Now, we use the K-means algorithm from the scikit-learn library to efficiently cluster the similar products. Since this is an Unsupervised Machine Learning Algorithm, it becomes tricky to evaluate the models. However, using the elbow method, we were able to find the best 'K', the cluster size, for each and every domain; be it movies or books or personal-care items. We compared this with K-modes algorithm, which did not yield better results. Thus, we went with a more robust approach using TF-IDF and K-Means algorithm.
Normalized Ratings
We used IMDb's normalized algorithm, to accurately represent the lower confidence which make sense with lesser number of ratings. The formula we used was:
weighted rating (WR) = (v ÷ (v+m)) × R + (m ÷ (v+m)) × C
Where v = number of votes, R = average rating, C = average vote, m = smoothing parameter to represent lesser confidence below it (which we manually set to 30)
After this we normalized the rating gained per category, putting range ∈ [0,1], and using that as a weight to give a maximum of 10% increment in priority by the engine (a number we agreed upon after testing)
Searching
The Search Engine works on a Semantic Similarity Model, weighted with a modified ratings score (the one IMDB uses for their ranking), which is sped up by a hierarchical knowledge base model, made using the categories and subcategories used when web-crawling.
PsuedoCode:
assume a weighted knowledge tree
go through the hierarchy:
for each hierarchy:
find the node semantically the closest:
at lowest hierarchy:
find the semantically closest object
and weight it with the rating (after normalization)
The queries are recieved via a bot which usues Google Cloud's DialogueFlow API to extract intent from the sentence and then converts the sentence to a query which is further executed. The main focus of using of the bot was to provide an user friendly way to do queries, using domain specific knowledge to improve the results.
Members
Original contributors to the project were Vishva Saravanan, Mayank Goel, Tanishq Chowdhary and Kunwar Shaanjeet Singh Grover.
Basic Working Version



Log in or sign up for Devpost to join the conversation.