-
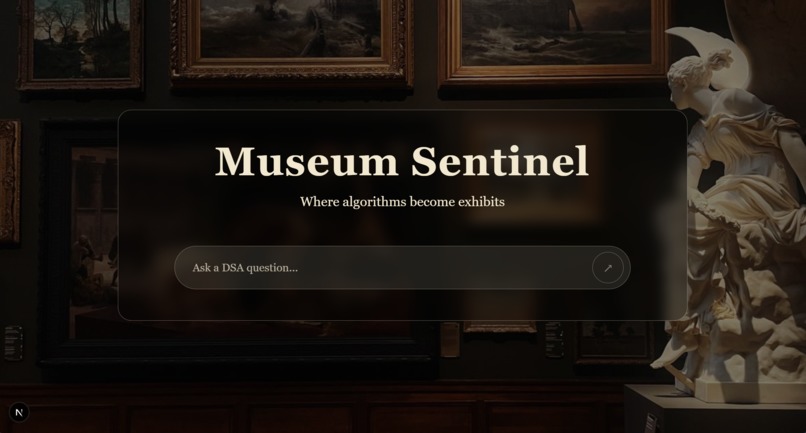
Website_UI
Inspiration
Museums. We built a Museum Sentinel: a calm, curator-style guide that teaches data structures and algorithms the way a docent leads a visit—structured, grounded in a fixed collection, and tuned to each visitor—not a generic web-wide chatbot.
What it does
- Answers from a read-only knowledge base (
Backend/dsa_mock_data.json) so explanations match curated material. - Personalizes using
user_memory.json(skills, struggles, preferences, interests, progress). - Reflects after each turn: updates the profile and appends
sessionstohistory_log.json(summary, takeaways, mood). - Loads the last three sessions into context so the assistant can connect threads.
- Keeps short-term dialogue with LangChain
ConversationSummaryBufferMemory. - Web stack: FastAPI backend + Next.js chat UI, with SSE streaming when available.
How we built it
| Piece | Details |
|---|---|
| LLM / agent | Python 3.12, LangChain, Google Gemini via langchain-google-genai, Pydantic for structured reflection |
| API | POST /ask, POST /ask/stream, GET /health, GET /memory; CORS for the frontend |
| Data | JSON on disk; atomic writes for profile updates; optional env overrides for file paths |
| Frontend | Next.js 16, React 19, TypeScript, Tailwind 4, react-markdown + remark-gfm |
Challenges we ran into
- “Failed to fetch” — The API was not running,
NEXT_PUBLIC_API_URLpointed at the wrong base URL, or CORS rejected the request because the page was opened from the Network/LAN URL (e.g.http://10.x.x.x:3000) instead ofhttp://localhost:3000orhttp://127.0.0.1:3000. - Windows PowerShell —
&&is often invalid for chaining commands; we used;or ran commands on separate lines. - Next.js dev — Only one
next devper project; a second instance fails until whatever owns port 3000 is stopped. - Latency vs memory — Reflection (profile +
history_log) means extra Gemini calls; we return the main answer first and run some persistence in background threads on the API path so the UI stays responsive. - Quotas — Gemini rate / quota limits; we mitigated with ordered multi-key failover when keys belong to different Google Cloud / AI Studio projects.
Accomplishments that we're proud of
- Three-layer memory — Curated KB + mutable profile (
user_memory.json) + session log (history_log.json) +ConversationSummaryBufferMemory, without ever writing to the read-only KB file. - Streaming UX —
POST /ask/stream(SSE) with a clean fallback toPOST /askwhen streaming is unavailable. - Operable repo —
GET /health, configurableCORS_ORIGINS, and a single rootREADME.mdcovering setup, HTTP API, environment variables, and Windows troubleshooting.
What we learned
- Grounding an LLM on a local JSON corpus while updating learner state in separate files (clear separation of concerns).
- LangChain chat memory plus structured post-turn reflection wired through a real FastAPI → browser stack.
- How to tell
Failed to fetch/ CORS apart from HTTP 4xx/5xx and backend500responses when debugging from the frontend.
What's next for DSA-AI-Agent
- Chunked / indexed retrieval as
dsa_mock_data.json(or the KB) grows. - Multi-user isolation — auth or per-device
user_memory.json/history_log.json. - Light evaluation — a small golden set of DSA prompts for regression checks.
- Deployment — containers + hosted frontend; secrets only in environment, never in git.
- Pedagogy — guided exhibit-style paths, quizzes, or spaced repetition driven off the profile in
user_memory.json.
Built With
- geminiapi
- langchain
- next.js
- pydantic
- python
- react
- typescript

Log in or sign up for Devpost to join the conversation.