Inspiration
Protein design is powerful, but the workflow is expensive, fragmented, and hard to reason about. Researchers generate dozens of variants, run separate tools for fitness, folding, synthesis, and cost, and then still have to decide which designs are actually worth ordering. Each physical test costs real money and weeks of time, and most designs fail.
We wanted a system that doesn't just rank variants in isolation, but coordinates specialist agents that each evaluate a different part of the design problem, then recommends the most cost-effective set of variants to test, before a single dollar is spent on synthesis.
What it does
DryRun is a multi-agent AI platform for protein design. You provide a protein sequence, a design goal, and a budget. DryRun runs the sequence through a coordinated pipeline of specialist agents, each owning one decision:
- Design Generator creates candidate protein variants.
- Sequence Fitness scores biological plausibility.
- Fold Risk predicts structural stability and fragile regions.
- Synthesis Cost estimates manufacturing cost.
- Portfolio Optimizer selects the best set under budget.
- Design Council reviews the selected portfolio through stability, function, diversity, synthesis, and budget lenses.
- Reporting Agent produces a clear final recommendation.
In the background, toolbox agents run additional protein and DNA checks: codon optimization, DNA QC, hydropathy, restriction-site scanning, solubility, liability scanning, and thermostability estimation.
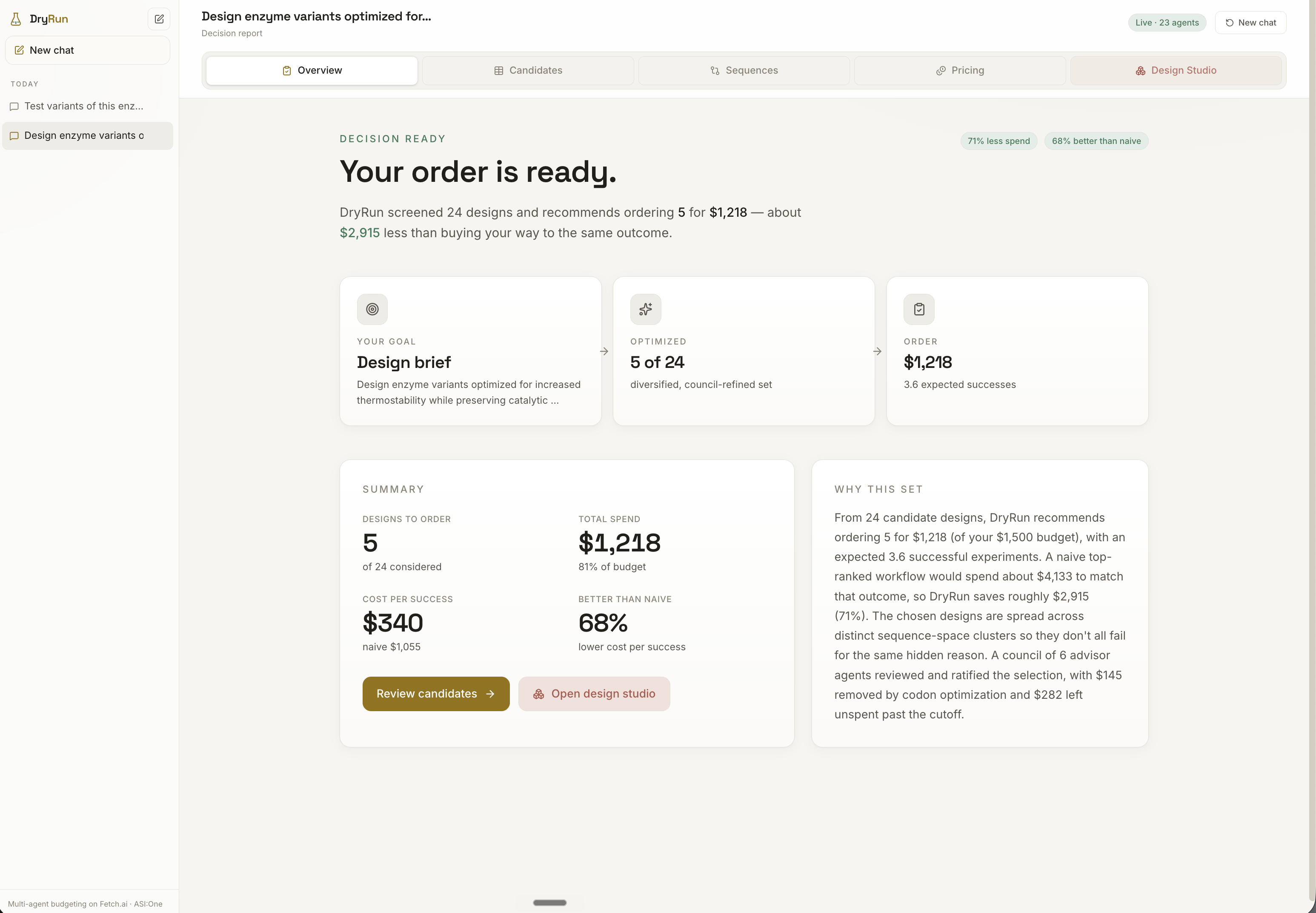
The result is a report that helps labs avoid wasting money on low-value variants and focus their budget on designs more likely to succeed.
The core idea: specialist agents that each own a real decision
The strongest part of DryRun is its multi-agent architecture, where each agent owns one specific part of the design problem and contributes real evidence to a shared decision, rather than one model trying to do everything at once.
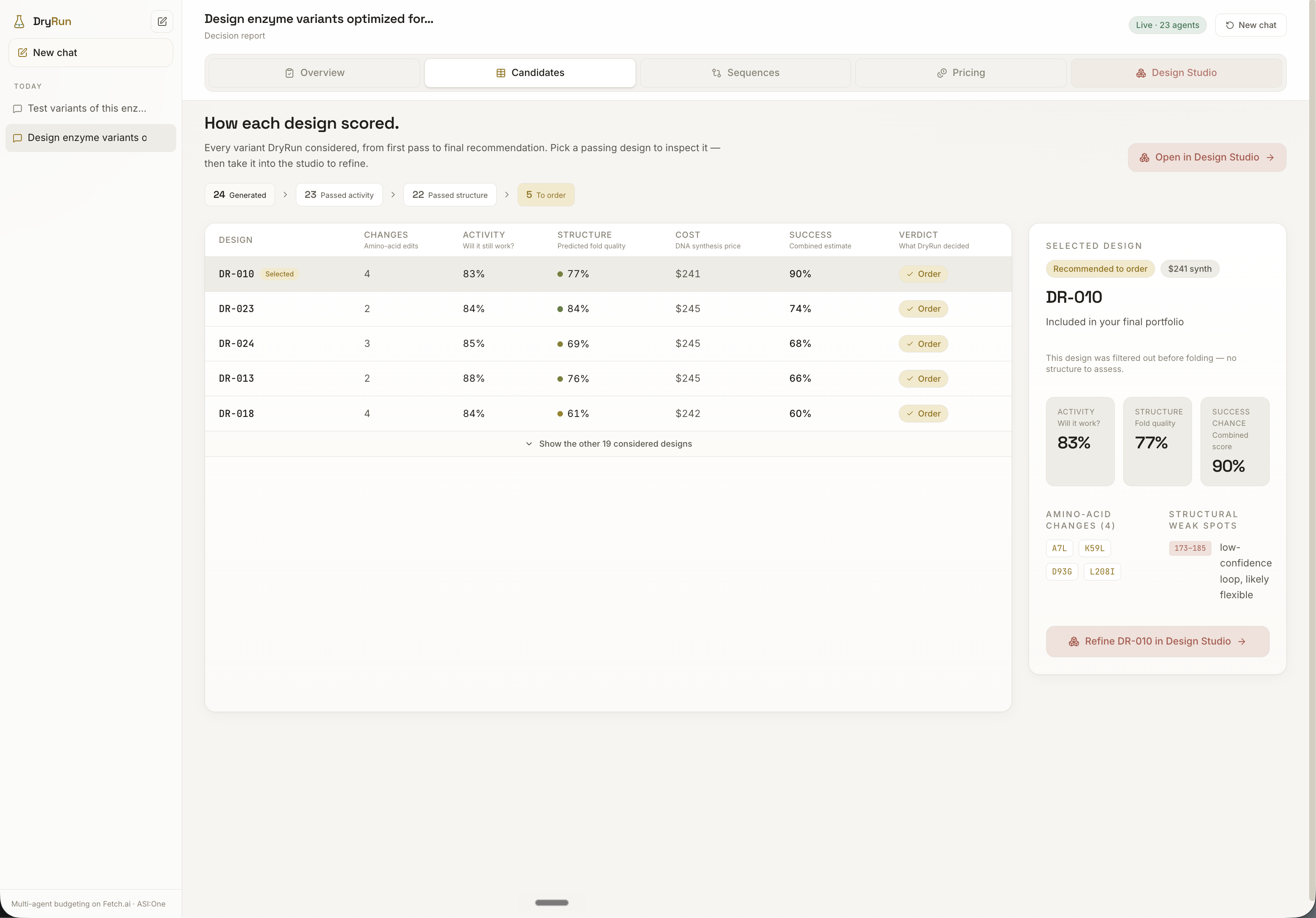
Protein design is genuinely many problems at once: is this variant biologically plausible, will it fold, where is it fragile, what will it cost to manufacture, is it diverse enough to hedge risk, does it have synthesis or solubility liabilities. DryRun gives each of these its own specialist agent. The Design Generator proposes variants, Sequence Fitness scores plausibility, Fold Risk predicts structure and fragile regions, Synthesis Cost prices each construct, and the Portfolio Optimizer selects under budget, while background toolbox agents run codon optimization, DNA QC, hydropathy, solubility, liability, and thermostability checks. Each agent enriches the same shared candidate objects, so dozens of independent signals converge into one coherent recommendation instead of a pile of disconnected outputs.
The agents coordinate over the Chat Protocol through Agentverse, every agent is independently discoverable and usable on its own, and the orchestrator routes work between them and recovers gracefully if any single agent fails. This is real agent-to-agent orchestration, not a single script wearing many hats.
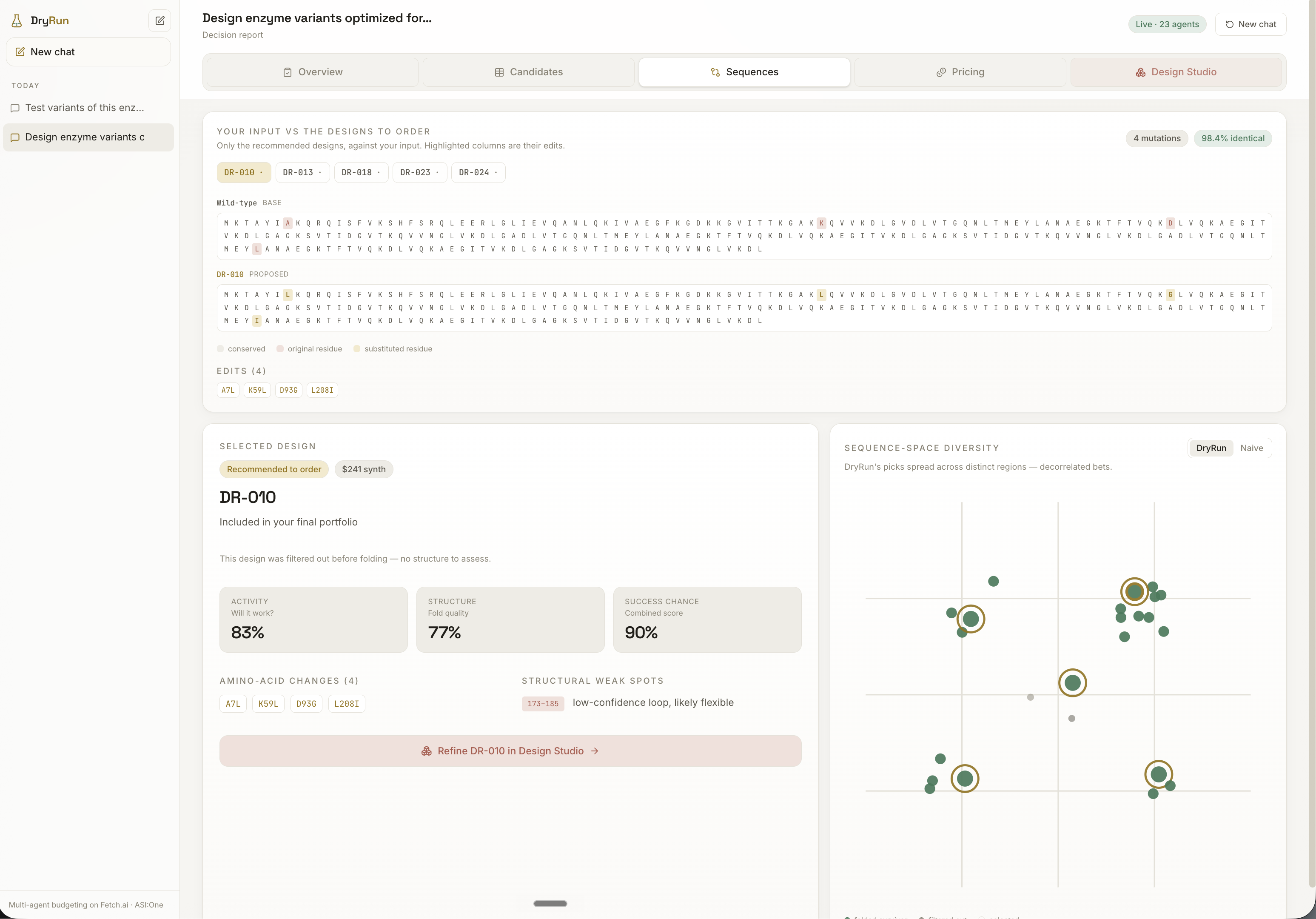
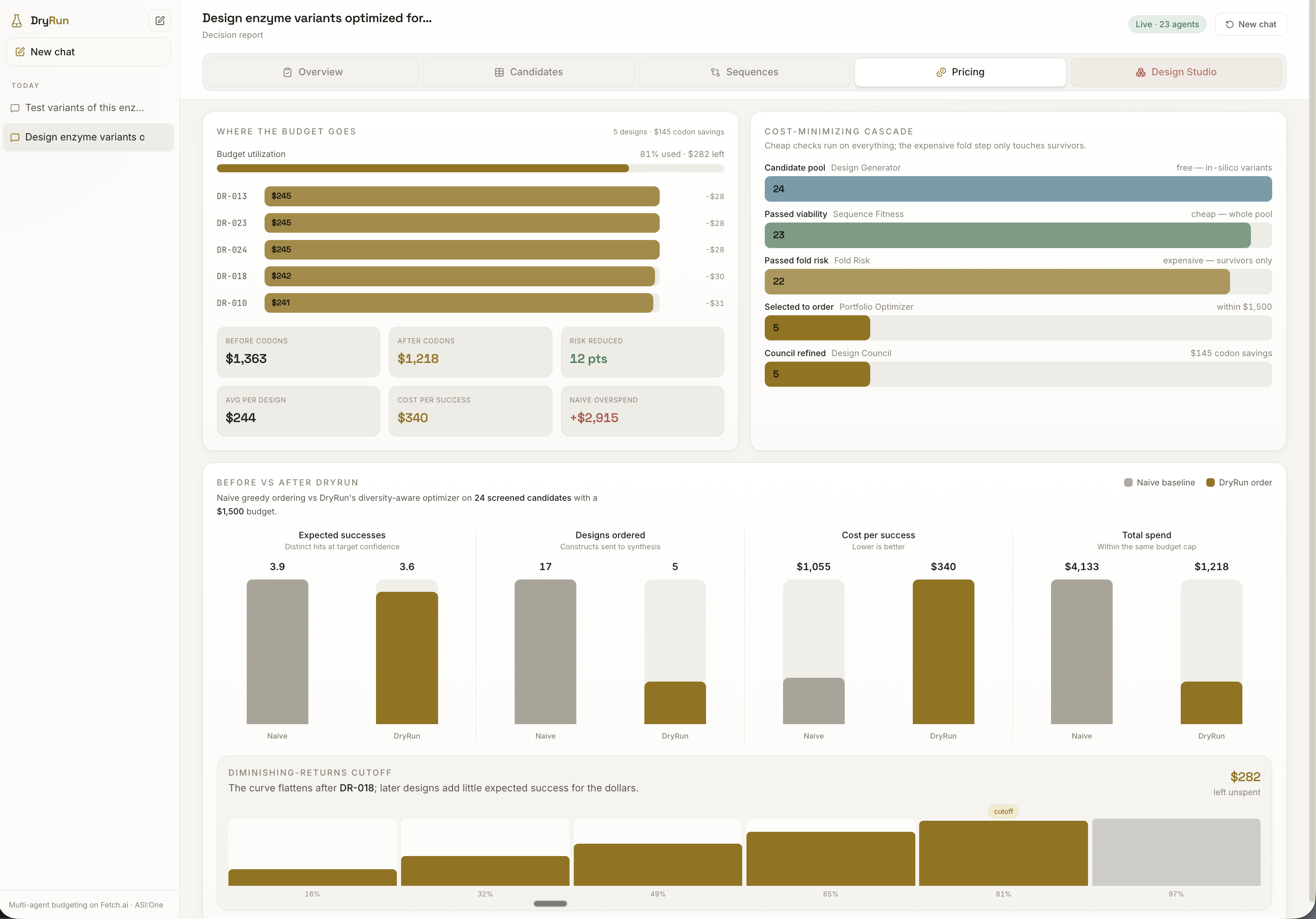
Sitting at the end of that pipeline, the Portfolio Optimizer turns all of that collected evidence into the actual decision. It is deliberately not a ranker: picking the top variants concentrates risk, because near-identical high-scoring designs tend to share the same hidden flaws and fail together. Instead, DryRun treats selection like building an investment portfolio, choosing a diversified set under budget so failures are decorrelated, maximizing the expected number of successful experiments per dollar rather than the score of any single design.
How we built it
The backend is Python with a distributed agent architecture built on uAgents. Each specialist agent has its own identity, task, capability, seed, and address, so agents can run locally in one Bureau or separately through Agentverse mailbox mode.
The orchestrator receives the user request, calls each specialist over the Chat Protocol, tracks request IDs, collects results, and falls back to an in-process pipeline if any marketplace agent fails. This keeps the system reliable while demonstrating real agent-to-agent coordination.
The pipeline is built around a shared candidate model. Each agent enriches the same candidate objects with new evidence: mutations, viability scores, fold confidence, fragile regions, synthesis risk, cost, success probability, and final selection status. This is what lets many agents contribute to one coherent decision instead of producing disconnected outputs.
The frontend is Next.js, React, TypeScript, Tailwind CSS, and 3D molecular visualization, designed to feel like a real product: sequence intake, a live run view, candidate detail pages, a molecule studio, and final report surfaces.
Challenges we ran into
The biggest challenge was coordinating many agents without making the system fragile. If one specialist timed out, an entire run could fail, so we built resilient fallbacks and made background toolbox calls non-blocking.
Another was turning complex protein-design signals into something understandable. Fold confidence, synthesis risk, GC content, fragile regions, and expected success only matter if the user can see how they shape the final recommendation.
We also had to balance realism and speed. Structure prediction is slow, so DryRun supports configurable fold backends and concurrent folding while keeping the demo responsive.
On the frontend, the challenge was clarity over volume. Protein design carries a lot of data, so we focused on the decision funnel: how many variants were generated, filtered, folded, priced, selected, and refined.
Accomplishments that we're proud of
We built a working multi-agent system that connects generation, scoring, folding, synthesis cost, optimization, review, and reporting into one workflow focused on reducing cost and improving success rate, rather than just generating variants.
We are especially proud of the Portfolio Optimizer, which chooses a diversified set under budget instead of the top-ranked variants, accounting for the fact that similar designs can fail for the same reason.
We are also proud that every agent has one clear responsibility, which is what keeps a system of this many agents reasonable to understand and reliable to run.
What we learned
We learned that agent systems are most useful when each agent has a clear job. The project became far easier to reason about once every agent did exactly one thing: generate, score, fold, price, optimize, review, or report.
We learned that cost is the real bottleneck in scientific AI. A model can suggest hundreds of variants, but labs need to know which experiments are worth paying for, so optimization under budget became the center of the product.
And we learned that a good AI interface for a technical domain is not just a chat box. Users need traces, scores, visualizations, comparisons, and clear explanations of why the system reached its recommendation.
What's next for DryRun
- Make every backend model fully production-grade and reduce real structure-prediction latency.
- Add richer wet-lab constraints, like vendor-specific synthesis rules.
- Expand the agent marketplace so researchers can plug in their own specialists, such as antibody developability, enzyme activity, toxicity screening, or assay planning.
- Validate the predicted cost-and-success improvements against real experimental outcomes.
Long term, DryRun could become an AI research operating system for protein engineering: a place where specialized agents collaborate to help labs reduce cost, improve success rate, and choose better experiments.
Built With
- 3d-molecular-visualization
- agentverse
- asi:one
- chat-protocol
- esm-2
- esmfold
- esmfold/nvidia-nim
- fastapi
- fetch.ai-agent-marketplace
- mol*
- multi-agent-orchestration
- next.js
- nvidia-nim
- protein-language-models
- pydantic
- python
- react
- tailwind-css
- three.js
- typescript
- uagents
- zustand

Log in or sign up for Devpost to join the conversation.