

Inspiration and the problem that our project solves
A couple of weeks ago we started seeing how news were appearing related to the challenges faced by many hospital doctors and pharmacists in Spain related to the provision of medicines to COVID-19 patients, due to the increased demand during the peak of infections. This was confirmed by several interviews that we had with doctors, pharmacists and other people from the Madrid regional Health Services. In the absence of sufficient medication, disused drugs started to be employed or the doses of those available needed to be modified. However, identifying the drug that can be used as a replacement for others is not a simple task. In some cases the same active substances are present in medicines under different brand names.
Our solution
In Drugs4COVID we are creating an open catalogue and a search engine for drugs used to treat COVID-19, based on the extensive scientific literature available around coronavirus (especially since 2003). We are using the CORD-19 dataset as a basis for our work. This dataset was released by the Allen Institute for Artificial Intelligence in March 2020.
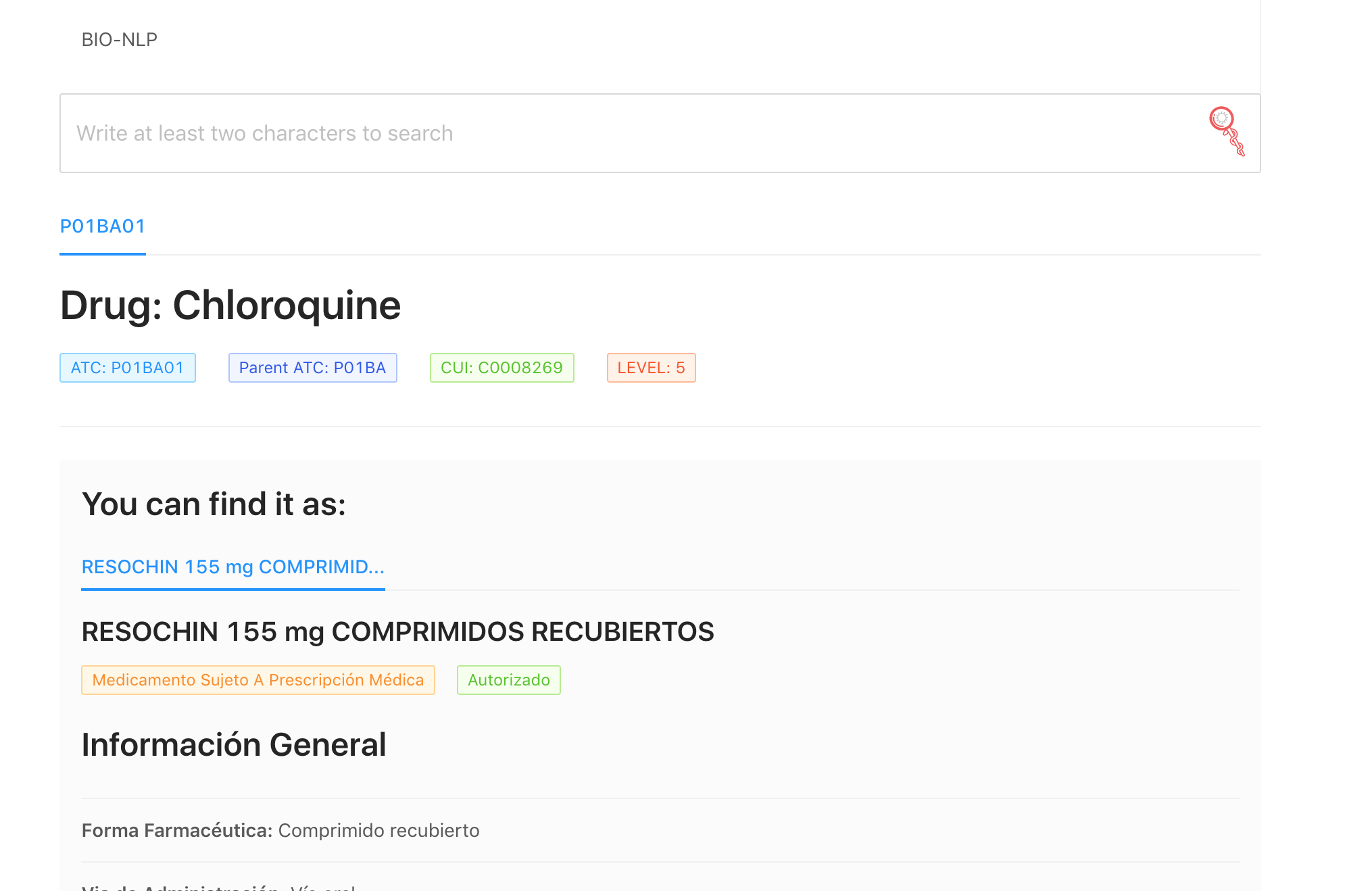
We have processed more than 60000 scientific papers. We have annotated them with the drugs and diseases that they contain. And then we have applied advanced Artificial Intelligence techniques to find similarities among them in how they are being used, and group them, so that now an improved search engine can be used for searching and navigating over the this large corpus of scientific texts. We can now look for the paragraphs that talk about COVID-19 and inflammation, for the most frequent diseases treated with chloroquine, or the drugs that are normally used with lopinavir. All this is available for our users in our search engine, including some examples, and for anybody who wants to reuse the results in an open knowledge graph that relates papers and their paragraphs, drugs and diseases.
What we have done over the weekend
We have set up our project website to describe all the results obtained so far. We have worked on all the underlying infrastructure, backends and APIs so as to make the results available for anybody to use, especially developers. We have also created a search engine to facilitate access for users. And we have created all the machinery to generate the knowledge graph, which is also available. Finally, we have designed a Citizen Science experiment that we will run in the coming weeks in order to validate and improve the results of our annotations, especially focused on the interactions between drugs and diseases.
Al this has been possible because of the hard work of a team of 20 people from our group, and a lot of our previous research results (for handling large sets of documents, annotation, named-entity recognition, knowledge graph generation, etc.).
The impact of Drugs4COVID to the crisis and after the crisis
Our inspiration came from the drug provisioning problem, which is still an issue in many regions in the world. But our impact can be extended into other problems that are relevant now. For instance, doctors are reporting new types of treatments that they are using with specific groups of patients, which are included in the corpus and are available for those who are looking for alternative treatments. We have also been asked for help by researchers working on tests and on vaccines, so as to provide them with tools to navigate through the scientific documentation available. And we have seen also many similar requests over the EUvsVirus hackathon slack channels.
After the crisis, these tools will be useful to create domain-specific search engines and knowledge graphs over a corpus of scientific documents more quickly, for a similar crisis or for many other situations where such a search engine and related tools would be valuable.
What we need to continue the project
We would like to obtain financial support to continue improving this solution. We want to add more types of annotations: other classifications of drugs, annotations of proteins that also appear in the corpus, etc. This would allow additional forms of search, exploration and navigation for researchers working on vaccines. We also want to improve the tools used to generate annotations, and work on creating relations among all the entities that we identify (drugs, diseases, etc.). To do this, we will run a Citizen Science project where we expect to receive tens of thousands of contributions from specialists. And we want to run a helpdesk where users will continue sending us the questions that they want to solved and we will continue improving the results that we provide.
All of our work is available in our GitHub repositories, so that anybody can contribute further in the future.
URLs
Our website: https://drugs4covid.oeg-upm.net Try it out (soon in our website): https://bio-nlp-dashboard.netlify.app/ Pitch video: https://youtu.be/Z6Qdn71nRFU
Built With
- bio-nlp
- html
- javascript
- librairy
- python











Log in or sign up for Devpost to join the conversation.