-
-
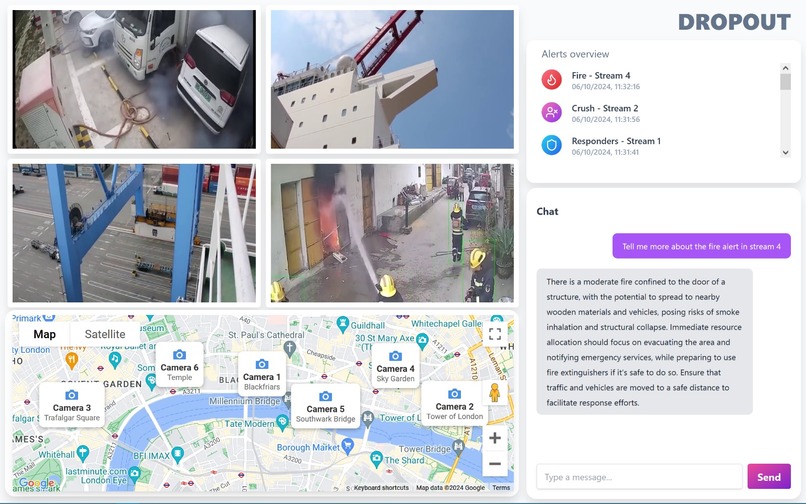
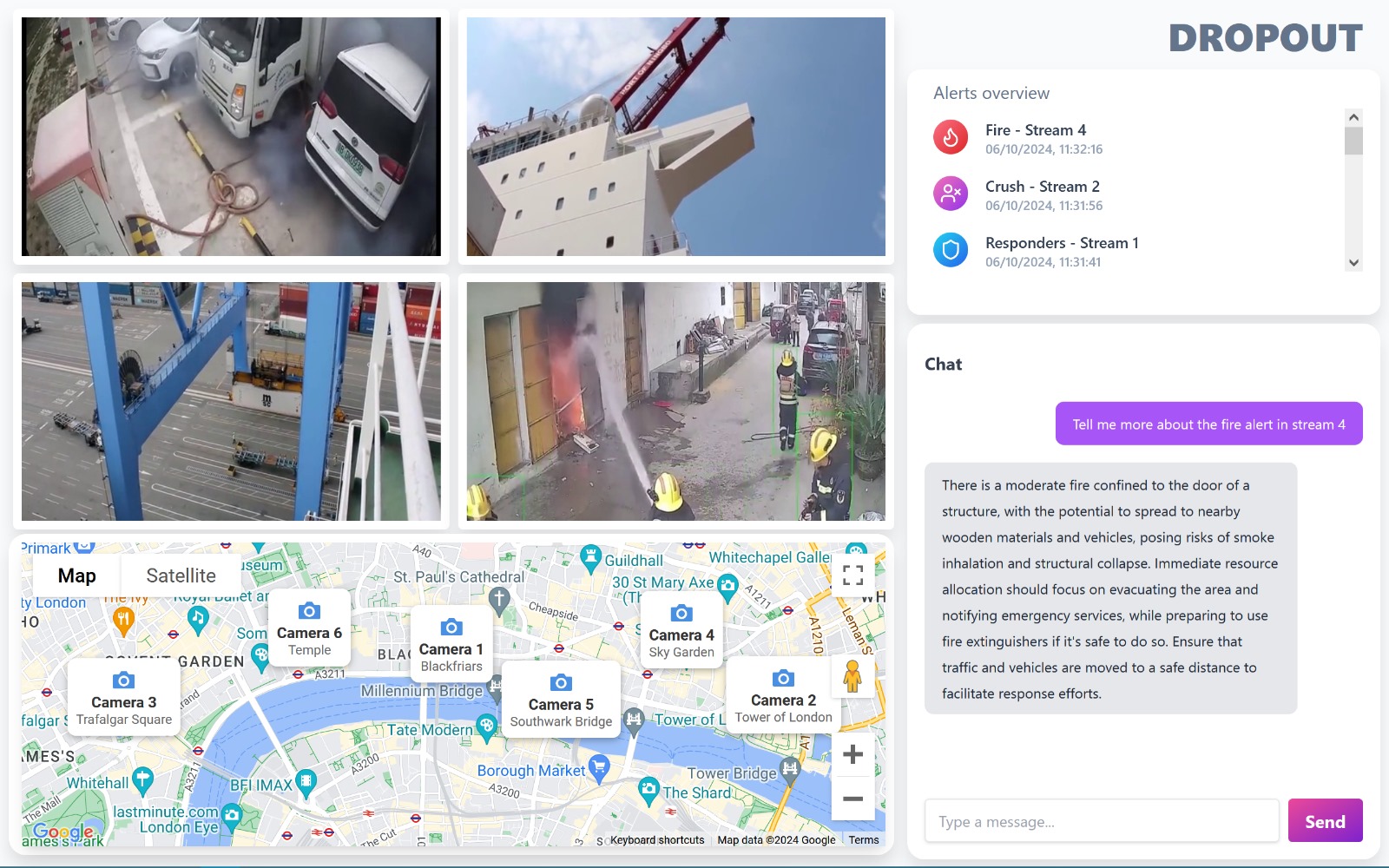
Screenshot of video feeds and chatbot's COT response
Inspiration
At Notting hill Carnival 2024 the police struggled to manage large crowds parading through streets. Additionally, the increasing risk of spontaneous battery fires in carparks and warehouses poses a risk to workers and the general public. We decided to solve both of these solutions, with a platform to integrate multiple camera feeds and automatically analyse them to detect the presence of hazards, and monitor the increase in crowd density.
What it does
Dropout contains two main features, the automatic detection of hazards and advising the coordination first responders.
Video feeds are displayed to the user, and periodically analysed for hazards such as crowd crush, fire, smoke, and emergency responders. If a hazard is detected, an alert is displayed to the user with context of where the camera is and what the hazard detected is. The user can ask questions about these alerts, where the images are sent for deep analysis, and all context is then passed to our dynamic inference-time compute finetuned CoT model, where we produce a stratergy for a response. This strategy is passed to a chatbot, who interperates this
How we built it
Our video streams poll a Vision Language Model (VLM) by Mistral called Pixtral, sending groups of frames for the VLM to annotate in multiple feeds. If a hazard is detected in a feed, an alert is sent to a central user console which creates an opportunity for the operator to interact with the alert.
When the operator requires more information, context of the camera location and its feed are sent to Pixtral again for a deeper analyse to provide a more detailed response. These responses are then
The release of o1 has demonstrated a new paradigm of model architecture, where more compute time can be spent at inference to produce better reasoned responses. These reasoning models use a supervisor agent to rate the validity of the steps in the CoT generation.
To achieve this, we've finetuned a Mistral 7b model with a Chain-of-Thought and used a prompt-optimised Mistral 7b Instruct model as a validator. This allows for a fully custom chain of thought generator with verified steps, producing a better reasoned response for advising emergency responders
This CoT prompt is used to inform our chatbot's response, to ensure its advice is relevant to what is seen in the image, and what is known about the camera's properties.
Challenges we ran into
We had to swap to Firefox, as the dataload on chrome became too much. Mistral CoT models have been trained before, but not with validator models, adding training complexity and interpretation. A common issue with reasoning models is an increase in hallucinations, which we mitigated with a smaller token output.
Accomplishments that we're proud of
As far as we can tell, this is the first attempt at inference time compute with a Mistral model. We're particularly proud of how accuracy we can evaluate crowd sizes, and how our platform can suggest the reallocation of resources in response to simply just image and location. The interactivity of our site is of paramount importance, and the simplicity of how we interact with the site is of particular pride to us.
What we learned
We have learned the fiddly-ness of finetuning, especially with the logical progression involved with Chain-of-Thought. We've been consistently impressed with the generalisability of Mistral's smaller language models, and especially how detailed the descriptions of the Pixtral image model have been.
What's next for DROPOUT
Next, automatic deployment of resources for fire suppression systems or crowd control officers are now promising with more validation and testing of our platform. Our name is inspired by our team member dropping out of Cambridge to pursue his start-up



Log in or sign up for Devpost to join the conversation.