-
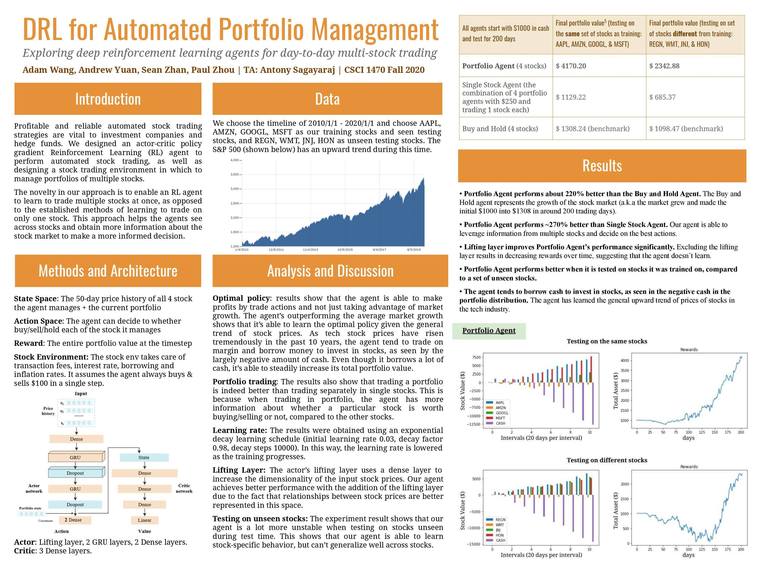
Poster
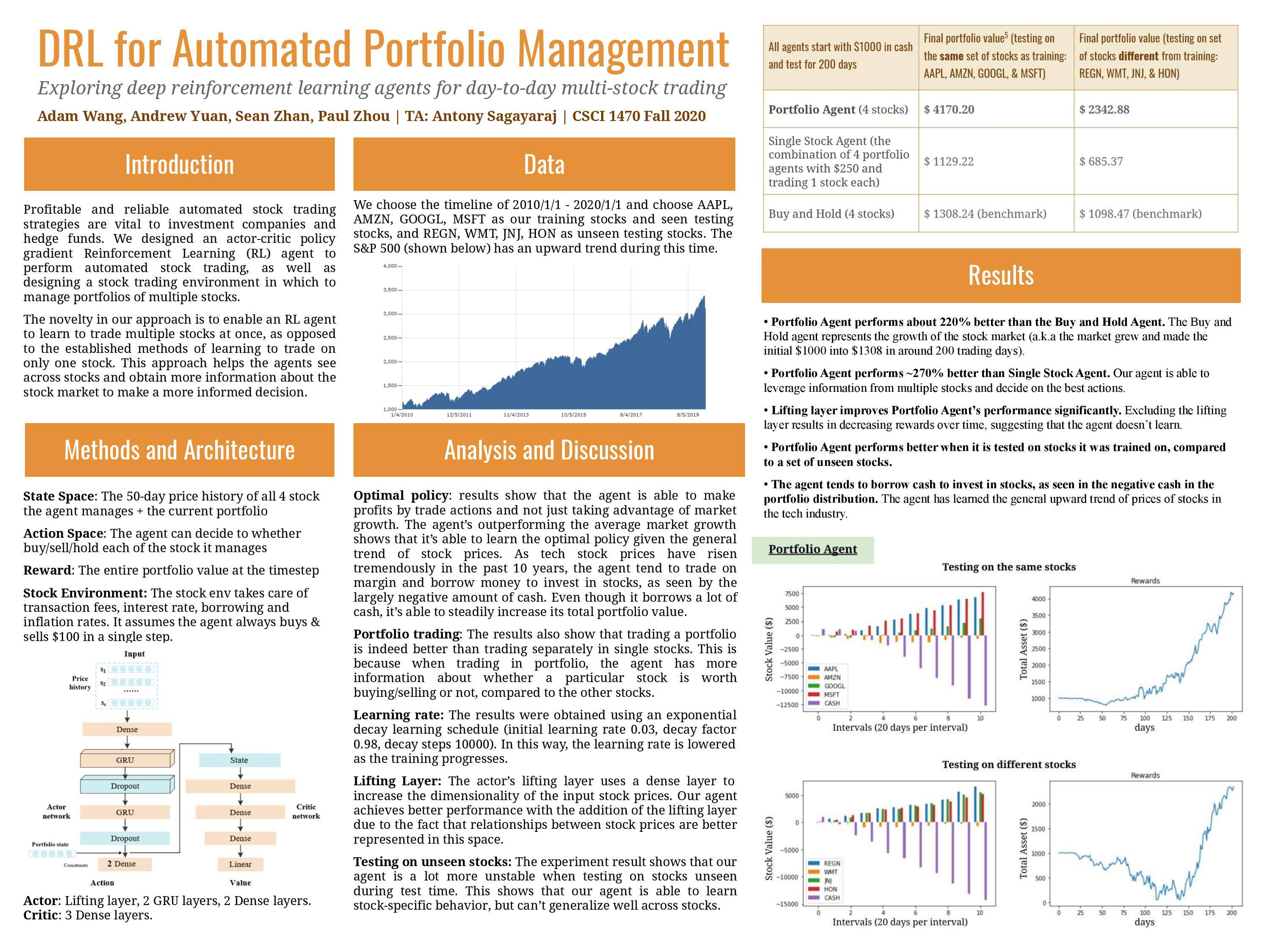
[Poster]
[Video]
[Final Write-Up]
Check in #2
Who
Adam Wang, Andrew Yuan, Sean Zhan, Paul Zhou
Introduction
Profitable automated stock trading strategy is vital to investment companies and hedge funds. It is applied to optimize capital allocation and maximize investment performance, such as expected return. Return maximization can be based on the estimates of potential return and risk. However, it is challenging to design a profitable strategy in a complex and dynamic stock market. We will use deep reinforcement learning (DRL) to solve the algorithmic trading problem of determining the optimal trading position at any point in time during a trading activity in the stock market. We will be implementing the actor-critic policy gradient algorithm for the RL agent and use an LSTM as the function approximator for action-value functions.
Related Work
Adaptive stock trading strategies with deep reinforcement learning methods In this paper, Wu et al. proposed a method to use GRU to extract important financial features form the stock data, and used both a Gated Deep Q Network and a Gated Deterministic Policy Gradient Network to to stock trading. They used historical stock data from 2008 - 2018 (consisting of prices and technical indicators from 9 different stocks) in the U.S., the U.K. and China as their training and testing data set. It is found that the proposed GDQN and GDPG not only outperform the turtle trading strategy, but also achieve more stable returns than state-of-the-art direct RL method and DRL strategies. It is also found that GDPG with an actor-critic framework is more stable than the GDQN with a critic-only framework in the ever-evolving stock market.
Application of Deep Q-Network in Portfolio Management uses a Deep Q-Network for portfolio management in a stock market.They propose an architecture combines a convolutional neural network and a Q-net, and they propose a discretization of the action space, defined as the weight of the portfolio in different assets. The state received by the Deep Q-Network consists of the portfolio weight vector from the previous period and the price tensor that includes closing, opening, highest and lowest price for the assets in the previous 𝑛 days for some window n. They use a train-set Jan 2 2015 - Dec. 30 2016 and the test-test Jan 5 2017 - Nov. 17 2017 of daily data. The results were evaluated using three metrics: the cumulative rate of return, the Sharpe Ratio and the Maximum Drawdown. They compared with traditional strategies such as Robust Mean Reversion, the Uniform Buy and Hold, and Online Moving Average Reversion and their results show to be 30% more profitable.
Learning Financial Asset-Specific Trading Rules via Deep Reinforcement Learning In this paper, DRL is used to learn asset-specific trading rules for each financial asset (e.g. a single stock). This paper introduces a DRL model (specifically, DQN) with various feature-extraction modules. Different vector representations of inputs are tested, and the best-performing method uses the raw values of the OHLC prices. This leaves the feature extraction module to learn a good representation of input.
The model contains two main modules: Part 1: Feature Extractor: “Different network structures including MLP, CNN, and GRU architectures are used to find the best model to extract rich features for signal generation.” We find that MLP performs better on testing data that has highly different price behavior than training data, while CNN and GRU have potential for similar price behavior. Part 2: Decision Making: “The extracted feature vector is then passed to the decision making module which is designed based on the DQN network. The output of this module is the action that the agent should take at the next time-step.”
Deep Reinforcement Learning for Automated Stock Trading: An Ensemble Strategy The paper combines three deep learning algorithms to find the best trading strategy. Proximal Policy Optimization (PPO) Advantage Actor Critic (A2C) and Deep Deterministic Policy Gradient (DDPG) The paper implements agents that trade multiple stocks from the 30 Dow Jones stocks. For each time step, there are three possible actions, buy sell hold, each action leads to three possible portfolio values In order to avoid the large memory consumption in training networks with continuous action space, they employ a load-on-demand technique for processing very large data In terms of the ensemble strategy: The paper implements three separate agents that train with PPO, A2C, DDPG respectively. They train these agents for a 3-month window. At the end of the 3-month window, the agent with the highest sharpe ratio will be picked to trade for the next window. The paper evaluates performance across the ensemble strategy and the three networks using the sharpe ratio, cumulative and annual return, annual volatility, and max drawdown.
Data
We will simply import this python package (https://pypi.org/project/yfinance/). The dataset includes historical market data (regular hours data when time intervals are specified), actions (dividends, splits), major holders, balance sheet, cashflow, options expirations. Our dataset includes S&P 500 stocks over ten years with their market opening and closing prices from each hour every day, as well as a few technical indicator calculated from those prices.
Methodology
We will design a Deep Reinforcement Learning agent to automate stock trading. Major challenges include preprocessing stock market data and adapting our model(s) to the yahoo finance database, evaluating whether our model has enough data to train on and when and if it is overfitting. Since we plan to train on ten years of S&P 500 stock market data, we also need to make our model as efficient as possible.
Our entire model consists of two major components: a Transformer encoder, and an RL agent to make decisions.
The transformer model is used to produce predictions about the close price of the next day. This transformer model is trained using supervised learning from historical stock data, using pairs of a history of stock prices and the closing price of the next day. This prediction is then feed into the RL model as input. This model is trained independently of the RL agent. Since this model can be trained independently to boost performance of the entire model, it is part of our target goal.
The RL agent uses a Actor-Critic Policy Gradient Network. We will use a Gated GRU as an information extractor and the actor network to decide on actions. The critic network will be a few stacked dense layers that predicts the final q value. The agent will be holding 10 stocks at once, and it will be able to choose whether to buy/sell/hold those 10 stocks and how much to sell/buy. The agent will choose an action from the action space described below.
There are three available actions that are based on a tree structure. The agent would first decide whether or not to act at all. Note that not acting is equivalent to holding. Then, the agent will decide whether to sell or buy. This prevents the agent from trading all the time and losing money due to transaction fees. Note that we would have a hyperparameter that represents the maximum stock value that the agent would trade at each time step. This prevents the agent from trading a huge amount of money in order to get a reward. Correspondingly, we would limit the learnable parameters for selling and buying to be some value between -1 and 1. The value represents the percentage of maximum stock value that the agent would buy or sell. (-1 means the agent would buy 100% of maximum stock value, 1 means the agent would sell 100% of maximum stock value).
We are also considering for the actor-critic algorithm to use a neural-network approximated action policy function, and a second network trained as a reward function estimator. The policy function approximator will be tested using a basic RNN, an LSTM and a CNN with input being a 3 by m by n tensor of high, close, low data of m assets over the past 50 time steps and output a portfolio vector indicating the balance of our portfolio. For this idea, we would get minute data and we would rebalance our portfolio every 30 minutes. All prices should be normalized by dividing by the most recent closing price, since only changes in price will determine portfolio management. The reward function is defined such as it is the agent's return minus a baseline’s return
Metrics
The notion of accuracy doesn’t apply to our project. We will be evaluating our model in the following ways:
Evaluate the performance of our model against a deterministic trading policy (the turtle policy for example), and see if our agent outperforms the policy. We will try to test the agent on stocks that it was not trained on, and compare its performance against stocks it was trained on to see if the agent can generalize. We will also evaluate our model using the various financial metrics described below to assess the stability and performance of the model.
Metrics that we may consider include: Arithmetic Return, Average Daily Return, Daily Return Variance, Time Weighted Return, Total Return, Sharpe Ratio, Value At Risk, Volatility, Initial Investment, and Final Portfolio Value. We can compare metrics across different models for the same testing data to see which models perform better for 1) testing data with behavior similar to training data and 2) testing data with behavior different from training data.
Base goal: Our RL agent should be able to make money on a test-set of a non-downward-trending market.
Target goal: The agent should perform as well as benchmarks indicated by the alpha metrics. We would also like to implement the Transformer encoder model, and evaluate whether adding an independent encoder/predictor will increase the performance of our model.
Stretch goal: The agent can perform various tasks such as option trading, including macro economic information such as news, and other info to enable the agent to make more well-informed decisions.
Ethics
Why is Deep Learning a good approach to this problem? In Stock trading, there are a great number of factors to take into account to make a decision of buying, selling, or holding. Deep networks are great function approximators when it comes to many variables. For stock markets, market data is complex, noisy, nonlinear, and non-stationary. When facing a complicated market envi- ronment, agents usually cannot achieve an optimal strategy. To address this problem, deep neural networks can come to the rescue. This is because deep neural networks can extract abstract and sophisticated features from different categories of raw data.
While standard machine learning models make predictions on prices, they don’t specify the best time to act, the optimal size of a trade or its impact on the market. With reinforcement learning, we are learning to make predictions that account for what effects each action has on the state of the market.
Who are the major “stakeholders” in this problem, and what are the consequences of mistakes made by your algorithm? If we make our algorithm public, some stockholders may use our imperfect model to make financial decisions and lose all of their investment. Mistakes made by our algorithm may have negative consequences on stockholders’ funds.
Explainability: Putting the DRL model into production has explanability issues: the model can only predict good actions, but it can not offer a great explanation for any certain actions. This has great problems in the real world, such as whether the investor should trust the model’s decision, and who should take responsibility/credit when a bad/good decision is made.
Division of Labor
Andrew: Preprocess Data from YFinance
Adam: Transformer for Feature Extraction
Sean: LSTM/GRU/CNN/MLP for in-DRL Feature Extraction
Paul: Actor-Critic / policy gradient algorithms
Paul: Train
Sean: Test
Andrew: Evaluation against other strategies
Adam: Metrics of each model
Built With
- tensorflow
- yfinance




 Zhan")

Log in or sign up for Devpost to join the conversation.