-

Front Page
-

Agent-Environment Tab
-

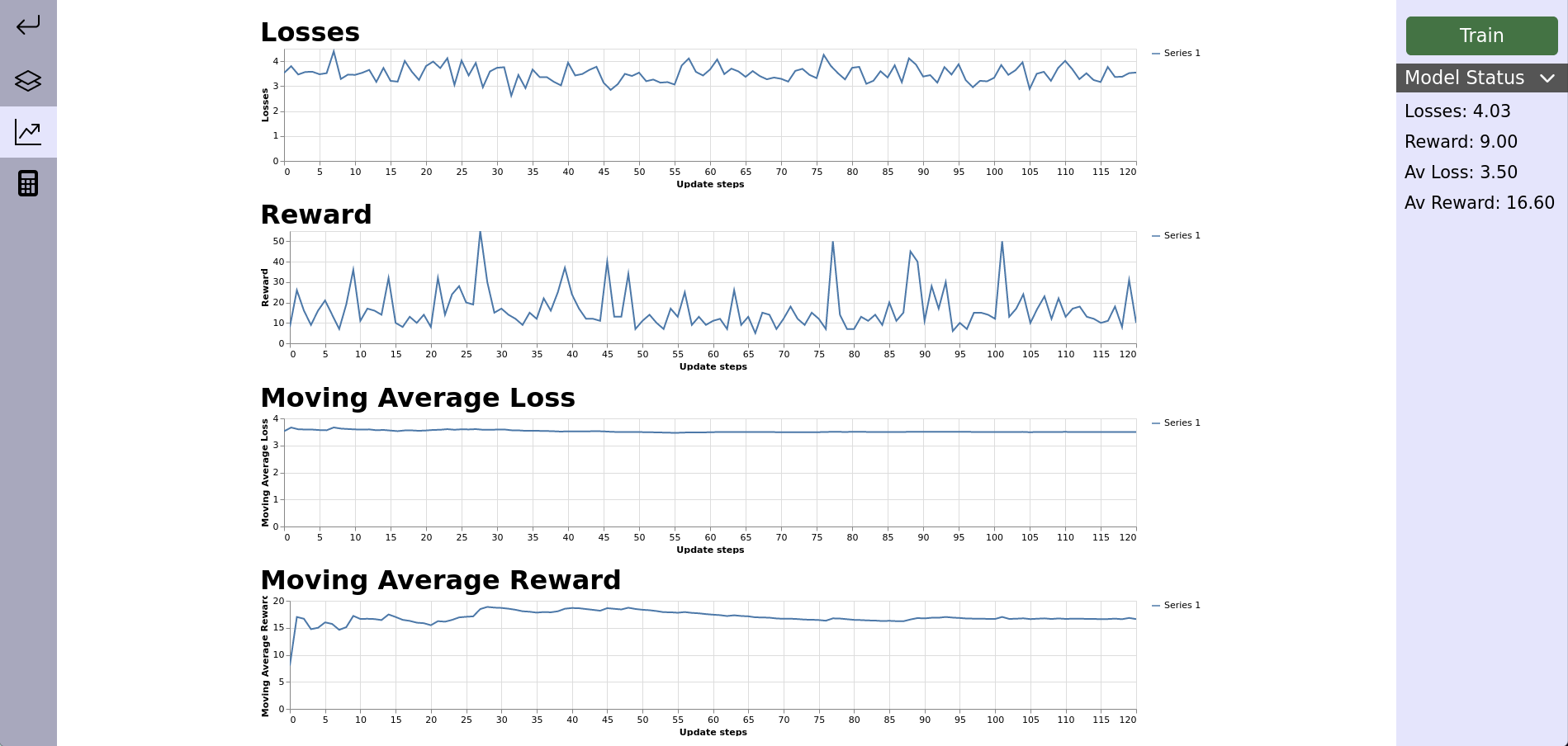
Metrics Tab
-
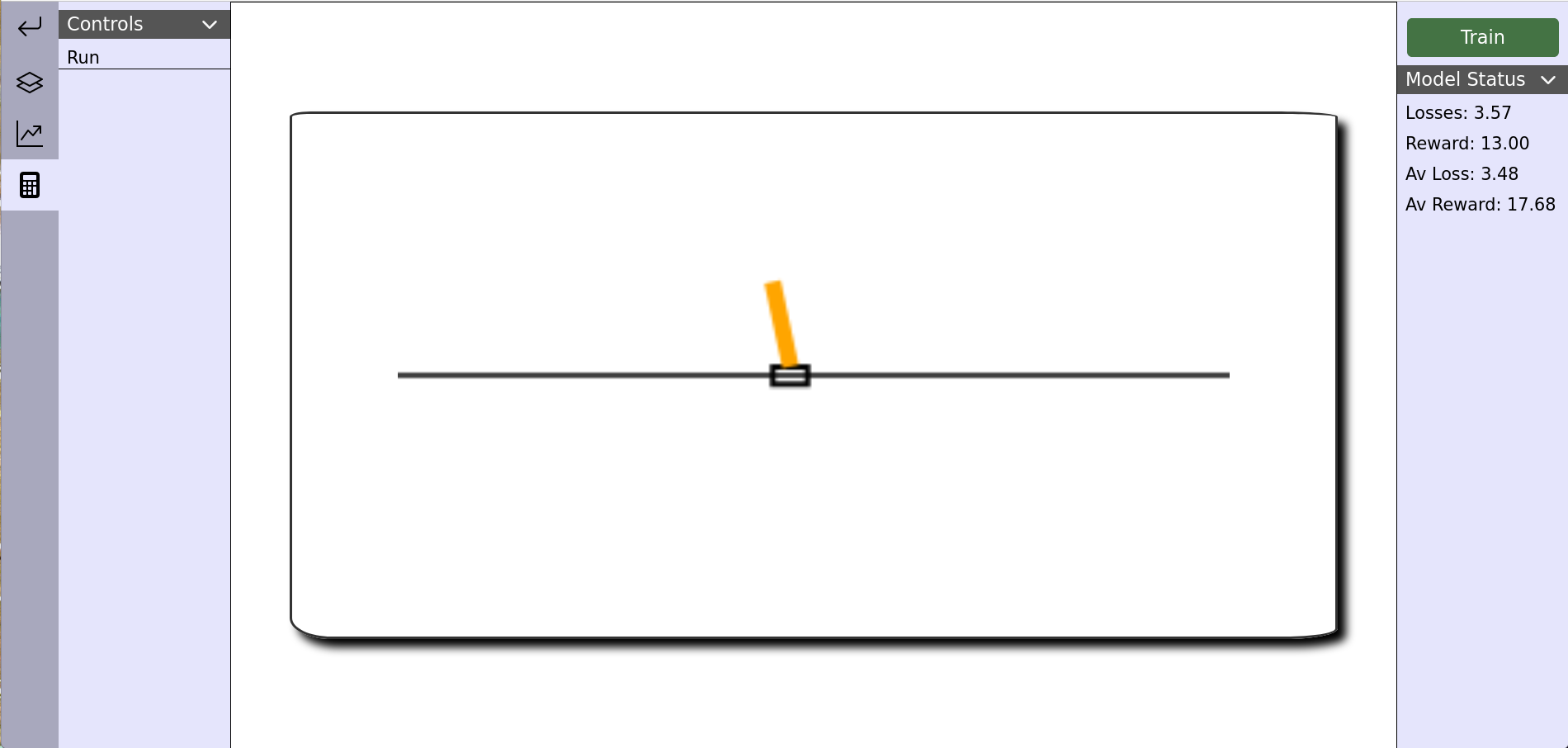
Visualization Tab

Inspiration
Our goal with DRL (Democratic Reinforcement Learning) is to give everybody a taste of Reinforcement Learning (RL).
Reinforcement learning is a fascinating field of AI that has been making headlines for the past few years. AlphaGo, OpenAI 5, AlphaStar - major advances in AI where even the strongest humans can no longer beat AI in extremely complicated games. Despite being so powerful, reinforcement learning is not complicated. In fact, it is a deeply intuitive technology inspired by our everyday experience of learning new things through trial and error. However, newcomers to the field are met with high entry barriers: there are a multitude of libraries, all interacting with each other and interfacing differently; moreover, resources from the field focus tend to focus on theory, while ignoring intuition.
With DRL, we hope to give people an easy-to-start, intuitive introduction to reinforcement learning by allowing them to train models and watch them learn right off the bat.
What it does
DRL is a webapp that empowers users to get started with reinforcement learning instantly.
When users enter the website, they are met with two drop-down menus that allow them to select the algorithm they want to try out, and what game they want to learn to play. After this, all is set to start training. Our users can start training their first state-of-the-art RL player with as little as three mouse clicks! A TensorFlow JS backend ensures fast and efficient training that users can follow in the "Results" tab. Finally, the "Visualization" tab allows users to watch the algorithm play and improve at the game, giving them a window into how the algorithm learns. With five mouse clicks, the user has gone through a complete RL workflow!
How we built it
At its core, DRL is a React webapp. On the ML side, we wrote all our RL algorithms from scratch in TensorflowJS, and also used it to visualize our metrics. Finally, to implement the environments that the algorithms train in, we used vanilla JS rendered to an HTML5 canvas.
Challenges we ran into
One core challenge was figuring out how to visualize the behavior of our algorithms while they were training. Training a model can take a large amount of processing power, so running a model while training and visualizing behavior can be infeasible on some machines. We successfully overcame this by intelligently caching state information about the environment.
An additional challenge was rendering the environments without degrading performance. The problem of rendering the environments without considering performance was already hard, as RL environments are not implemented in JS and we weren't sure of how to approach this. In the end, we got the environments rendering efficiently using HTML5 Canvas elements.
Accomplishments that we're proud of
We set out to create a webapp that would democratize access to reinforcement learning. The prototype we developed allows anyone to get the full RL experience with just five mouse clicks. We're proud of having developed this simple yet powerful app, that includes state-of-the-art algorithms (such as DQN), tracks progress while training, and renders the behavior of the algorithm.
What's next for DRL
This is just the beginning of what has everything to become a powerful education tool! Our next step is to implement more environments and state-of-the-art algorithms, to give the user a more complete experience of the current state of RL. In parallel with these algorithms, we also plan on writing a documentation page explaining each of them in an intuitive way, while also providing references for further reading.
Another feature that we are stoked about is giving the user the ability to modify existing environments and see how that affects the agent. We also want to give the user the chance of interacting directly with the environments, and playing against the agent when possible. By interacting with the agent, users will get a better sense of how their chosen algorithm behaves and how powerful RL can be.
Finally, to cater to a more academic audience (Ph.D. students, freelance researchers, or just curious people), we also plan on including an option to automatically generate a Python script that uses standard RL libraries (OpenAI Gym, Garage) to duplicate what the user has just done in the browser. We hope that this feature will help lower the entry barrier for users interested in starting their own RL research, but who are discouraged by the entry barriers associated with working with the standard libraries.
Acknowledgments
DRL was written from scratch but drew inspiration from multiple sources. The most important ones were ENNUI (a drag and drop interface for creating neural networks) and the examples from TensorFlow JS.
Made by: Joao Araujo, Eamon Ito-Fisher, William Ocamp, Nom Pham
Built With
- html5
- javascript
- react
- tensorflowjs

 Tran")



Log in or sign up for Devpost to join the conversation.