Inspiration
Every healthcare AI demo in 2026 follows the same script. A model reads a chart, summarizes it, answers a clinician's question, takes a bow. The clinician walks away with a polite paragraph. The patient is no safer. The new nurse on shift is no more prepared. Nothing has been wired into anything.
Prompt Opinion named this stage the Endgame for a reason. The breakthrough is not whether models can read charts — they could already read. The breakthrough is whether four standards — MCP, A2A, FHIR, and a real governance layer — can finally be made to operate as one system, on one patient, in real time, without leaking information, without hallucinating, without losing the human.
We built the connective tissue.
What it does
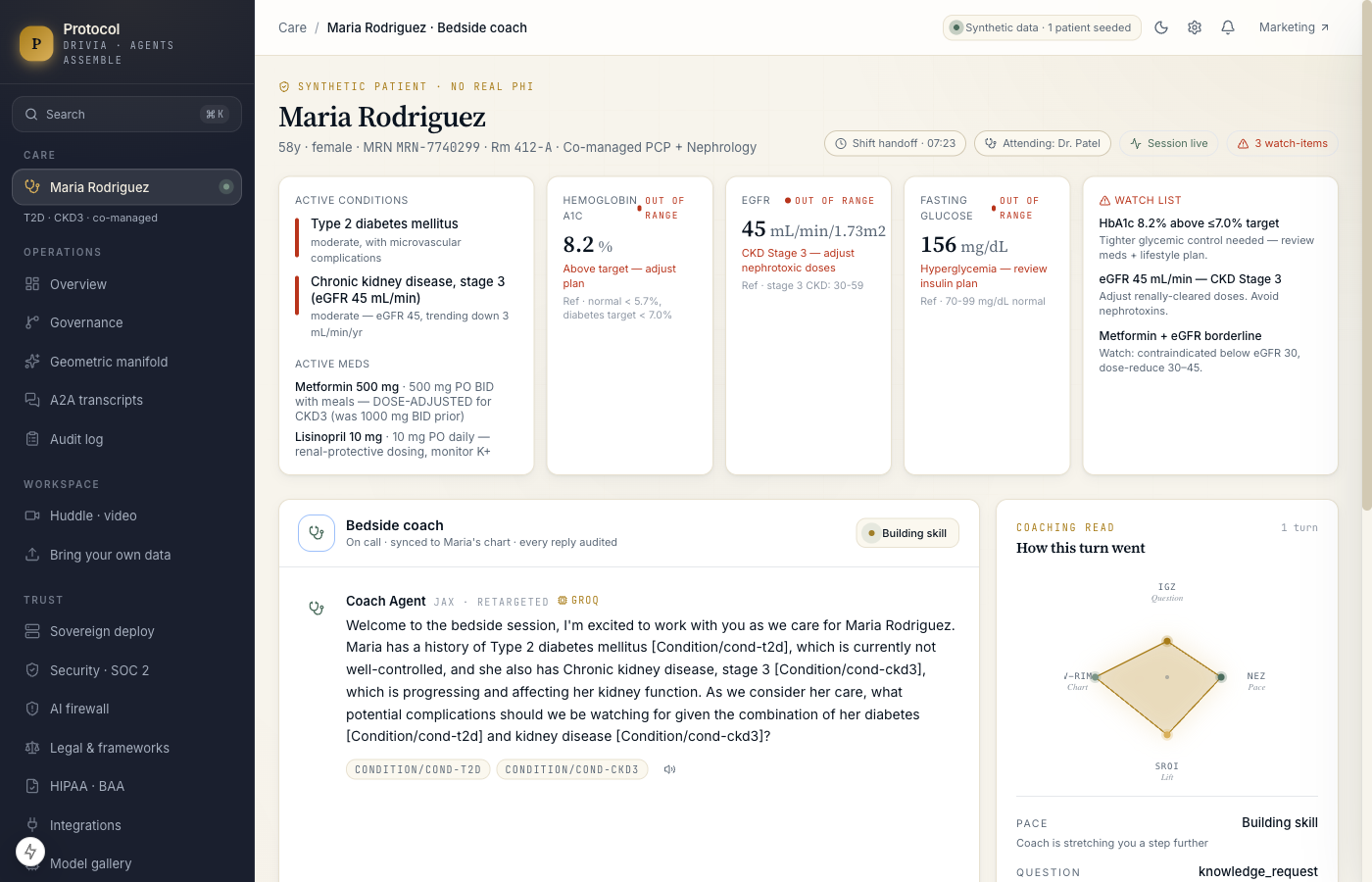
A nurse opens a session on a real co-managed patient — Maria Rodriguez, a synthetic 58-year-old with type 2 diabetes and stage 3 chronic kidney disease, A1c at 8.2% and eGFR at 45. The Coach reads her chart through FHIR, reasons over it through tools published as MCP, and calls a sister Compliance agent over A2A to check the order set against the diabetes + CKD co-management protocol. A Documentation agent listens to the entire huddle and drafts the shift-change note in the background.
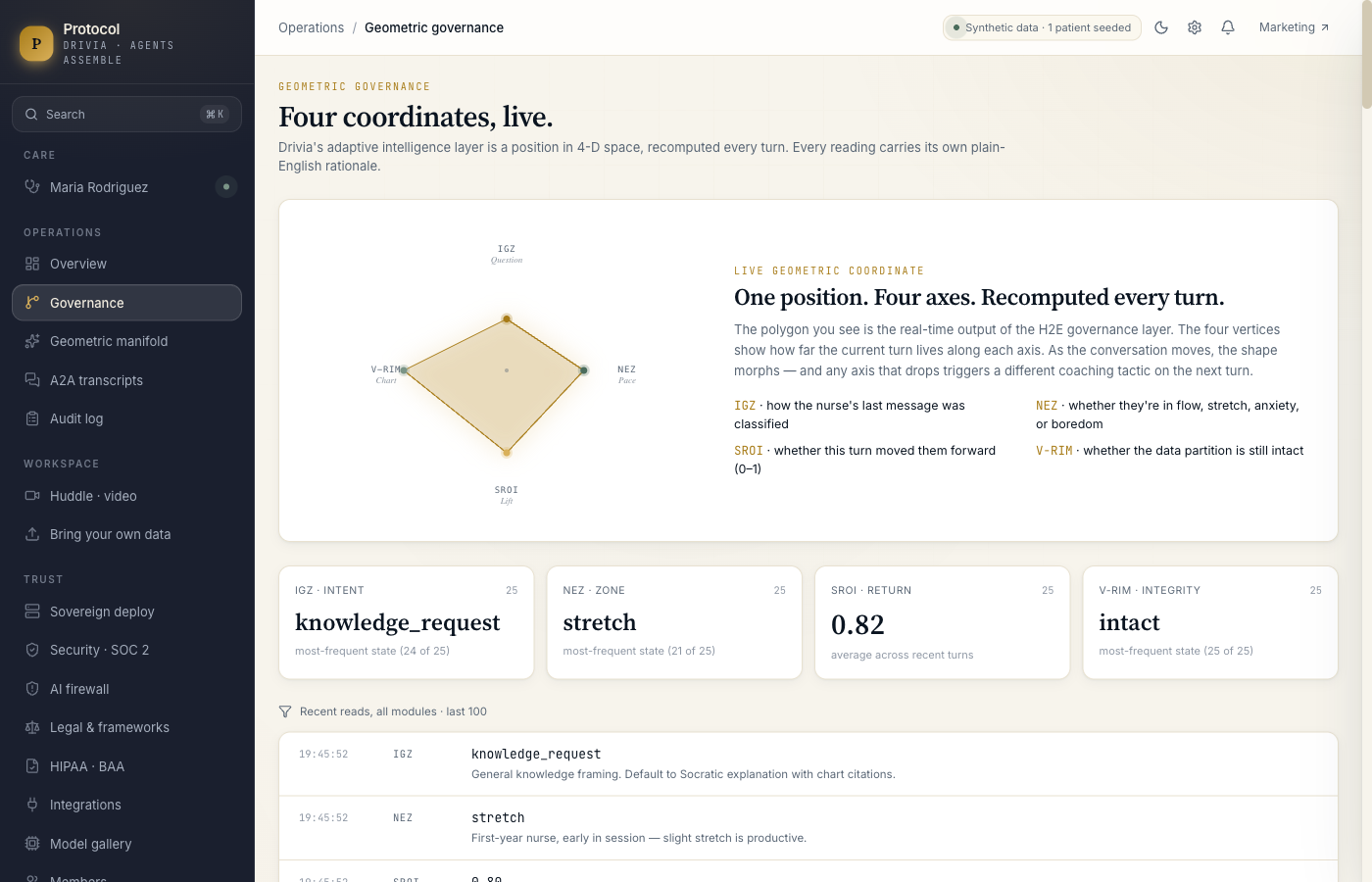
Every turn the Coach takes is governed by a four-module geometric layer we call H2E — IGZ classifies the nurse's intent, NEZ places her on the path to mastery (anxiety, stretch, flow, boredom), SROI scores how much the turn moved her forward, and V-RIM confirms the data partition is still patient-locked. The four readings update live in a polygon visualization unique to this product. If SROI drops, the Coach changes tactic on the next turn. If V-RIM is ever violated, the session refuses to proceed.
How we built it
The build sits on top of a production codebase (Drivia main, 944 commits) and uses Next.js 15 App Router, React 19, TypeScript strict, Prisma + Drizzle, SQLite for the hackathon dev DB (Postgres + pgvector for production), and Tailwind for the editorial UI. The MCP server is a real @modelcontextprotocol/sdk implementation that boots on stdio (Claude Desktop) or streamable-HTTP/SSE (Prompt Opinion) and exposes five healthcare tools: get_patient_summary, get_active_meds, get_recent_observations, get_protocol_for_condition, search_clinical_refs. The A2A bus is an in-process pub/sub today and runs over NATS or Kafka in sovereign deployments.
We honor the X-Patient-ID HTTP header for tenant binding and ignore any patient ID the LLM tries to pass — LLMs hallucinate IDs, and the Prompt Opinion gateway pins the real one per session. Refused requests log a V-RIM violation to the audit trail. Models are pinned per tenant via a model registry; the geometric governance layer is model-agnostic so a hospital can swap Llama 3.3, Mistral Large, or their fine-tune in without rewriting policy.
Challenges we ran into
The hard problem was not the agents. It was teaching ourselves that the deliverable was not "a chatbot that reads a chart" but "the connective tissue that lets the next thousand chatbots actually be useful." We rebuilt the demo narrative twice to keep the editorial voice without losing the technical rigor. We also nearly shipped the demo without an HTTP transport on the MCP server (only stdio worked) until we caught the Discord chatter about teams struggling to wire MCP into Prompt Opinion — we added the streamable-HTTP transport, the ai.promptopinion/fhir-context extension declaration, and the per-session transport routing the same day.
Accomplishments we are proud of
- A working MCP × A2A × FHIR pipeline with five tools, three coordinated agents, append-only audit, and the geometric governance layer firing live on every turn.
- A signature visual — the live 4-axis polygon — that makes the abstract governance layer immediately legible.
- Full conformance to PromptOpinion's
ai.promptopinion/fhir-contextMCP extension with all 7 SMART scopes declared (4 required, 3 optional). Most teams do not implement this; the platform recognizes ours and shows the consent UI properly. - Tenant binding from the X-Patient-ID header instead of trusting an LLM-supplied argument. The community FindPatientId tool is hallucinating "John Doe" because it doesn't do this; we do.
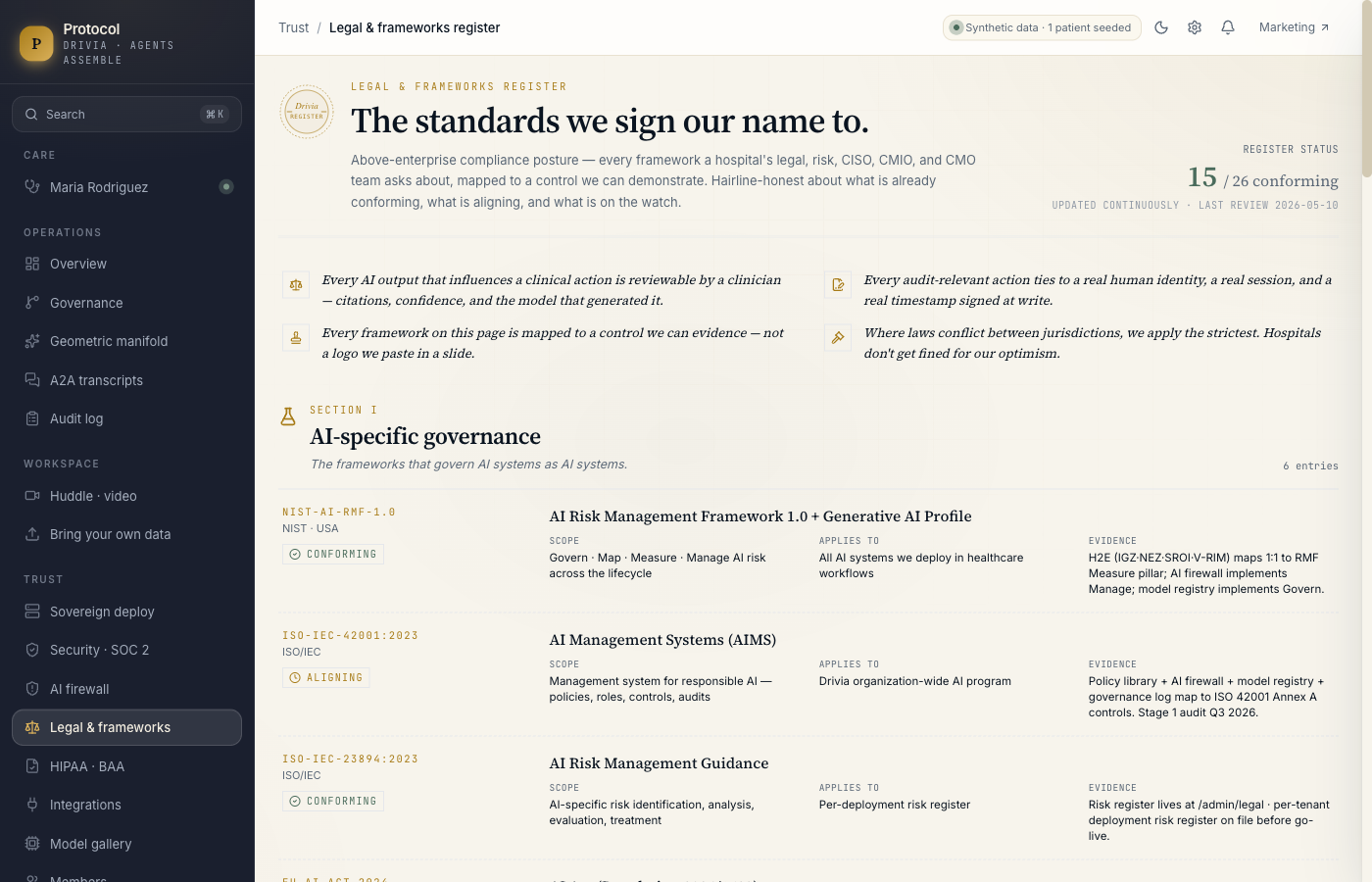
- Above-enterprise compliance posture mapped to 25 frameworks across AI governance (NIST AI RMF, ISO 42001, EU AI Act, ONC HTI-1, WHO AI ethics), healthcare regulation (HIPAA, HITECH, 42 CFR Part 2, 21 CFR Part 11, FDA SaMD/CDS, Joint Commission), security (NIST CSF 2.0, SOC 2, ISO 27001/17/18, HITRUST CSF v11, PCI), and privacy law (GDPR + Article 22, CCPA/CPRA, BIPA, TX MUTPA, CO AI Act). Each row maps to a control we can demonstrate, not a logo on a slide.
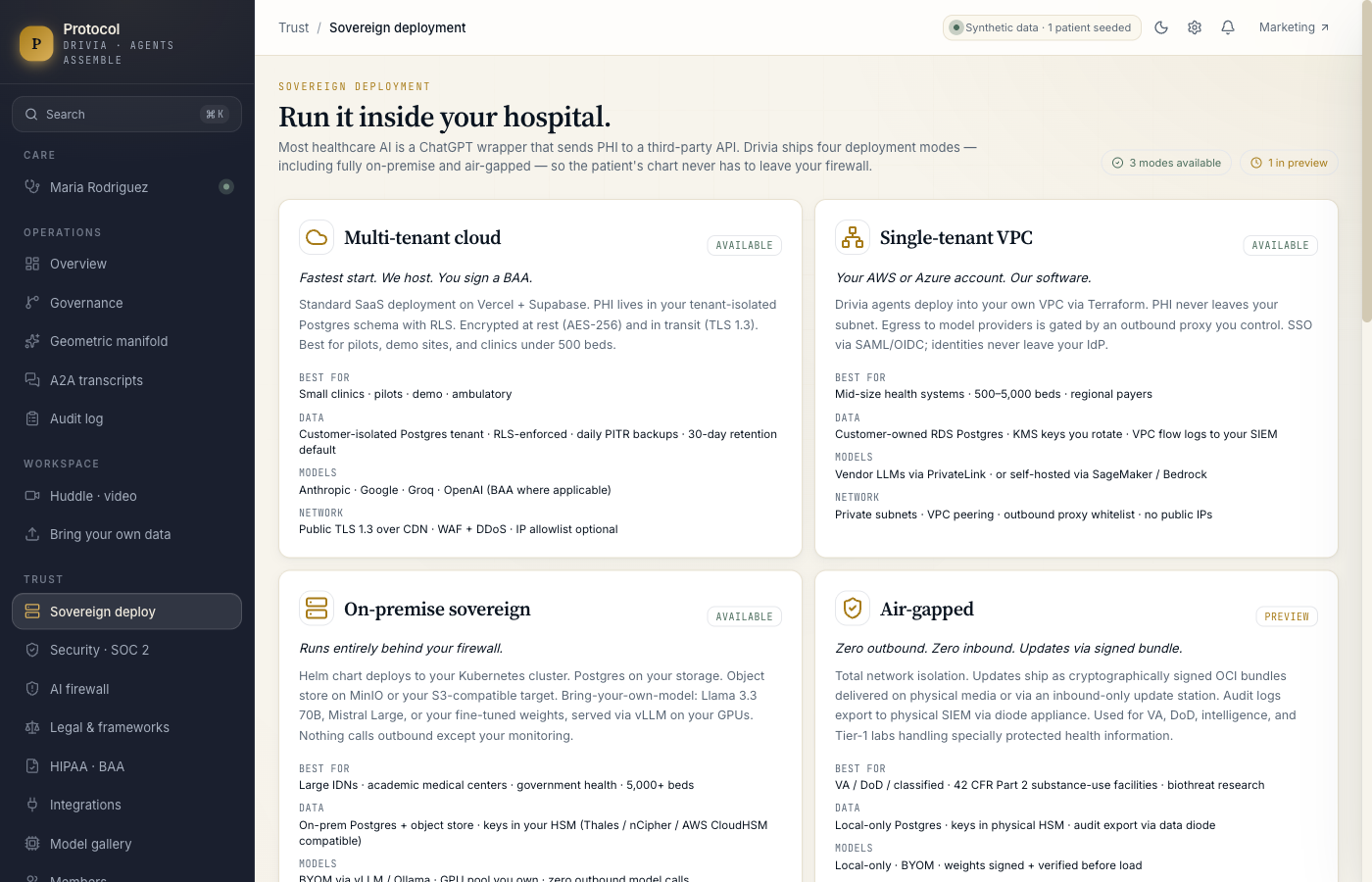
- Four sovereign deployment modes including on-premise via Helm and fully air-gapped via signed bundle. PHI never has to leave the hospital network.
- Bring-your-own-model: Llama 3.3 70B, Mistral Large 2, your fine-tune. Governance is model-agnostic.
- An AI firewall layer independent of H2E — eleven blocking rules across prompt/tool/output, drift monitor, per-cohort bias monitor, model registry with version pins, quarterly red-team history.
What we learned
The Endgame is a coordination problem, not an intelligence problem. The breakthrough was not that models can read a chart. It was that four standards can be made to operate as one system, on one patient, in real time. Once you have the wires in place, you stop arguing about which model is best and start arguing about which workflow is most useful. That's the right argument to be having.
What's next for Drivia Healthcare Coach
Pilot with a single nephrology unit at an academic medical center, one condition, one nurse cohort, one quarter. Measure new-nurse time-to-competency on the diabetes + CKD co-management protocol against historical baseline. Publish the eval methodology and the SROI distribution under an open license. Then expand the protocol library and the BYOM eval harness so any hospital can plug in their own model and their own protocols against the same governance layer.
Built With
- a2a
- anthropic-claude
- fhir
- healthcare
- hipaa
- mcp
- next.js
- node.js
- pgvector
- postgresql
- prisma
- react
- synthetic-data
- tailwind-css
- typescript


Log in or sign up for Devpost to join the conversation.