

DRISHTI - Project Description
Inspiration
DRISHTI (Digital Reliable Intelligent Support for The visually Impaired) was created to address critical gaps in assistive technology for visually impaired individuals. We recognized that existing solutions are fragmented, expensive, and don't provide real-time visual understanding or reliable safety monitoring. Our goal was to build a unified platform that combines AI-powered vision assistance with proactive fall detection, empowering users to navigate the world more independently and safely.
What it does
DRISHTI is a comprehensive Android application that serves as a digital companion for visually impaired users:
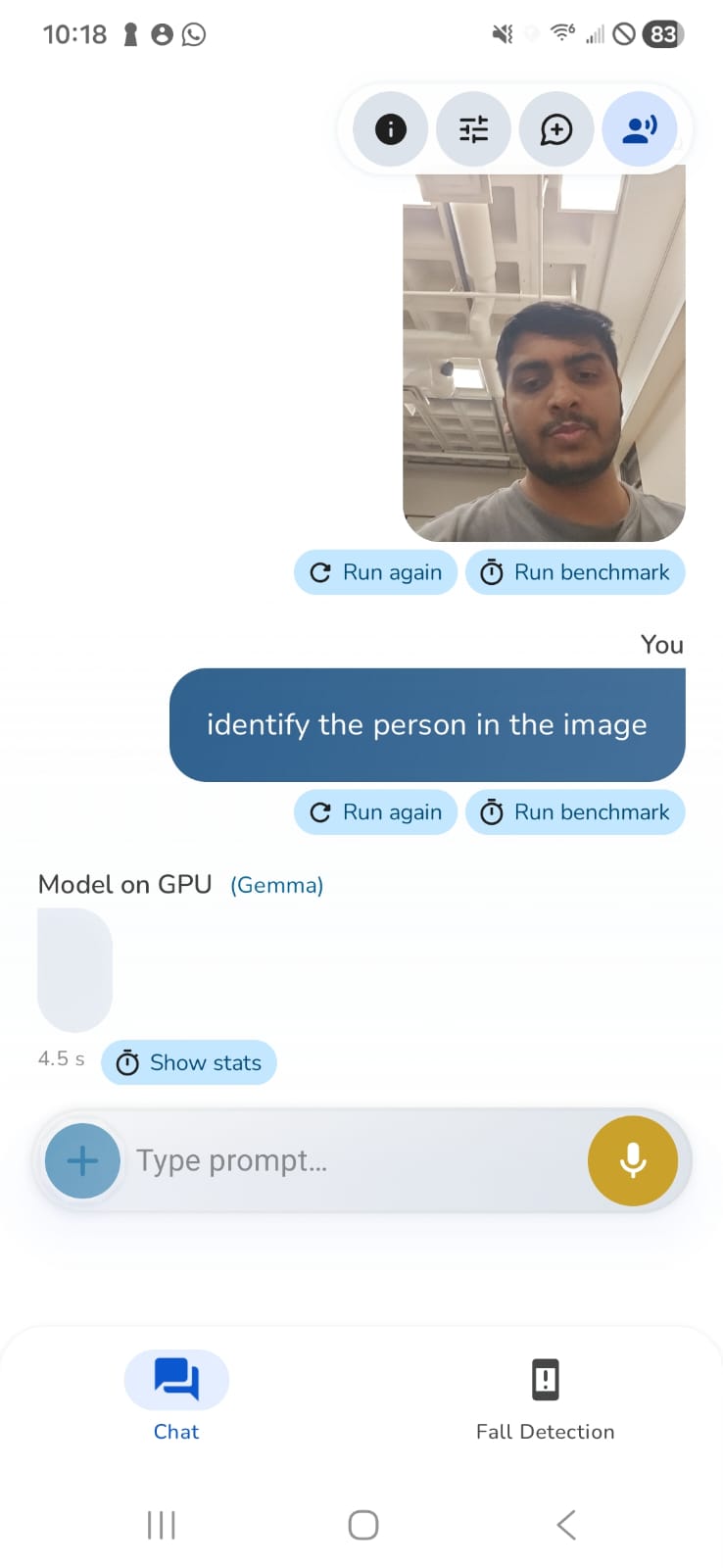
Vision Assistant: Real-time image understanding using Google's Gemma-3n E2B model with conversational voice interface. Users can ask questions about images and receive natural language descriptions.
Face Recognition: Advanced face identification using ArcFace embeddings. Pre-loaded database recognizes familiar people in photos with audio announcements ("Indresh and Gayatri").
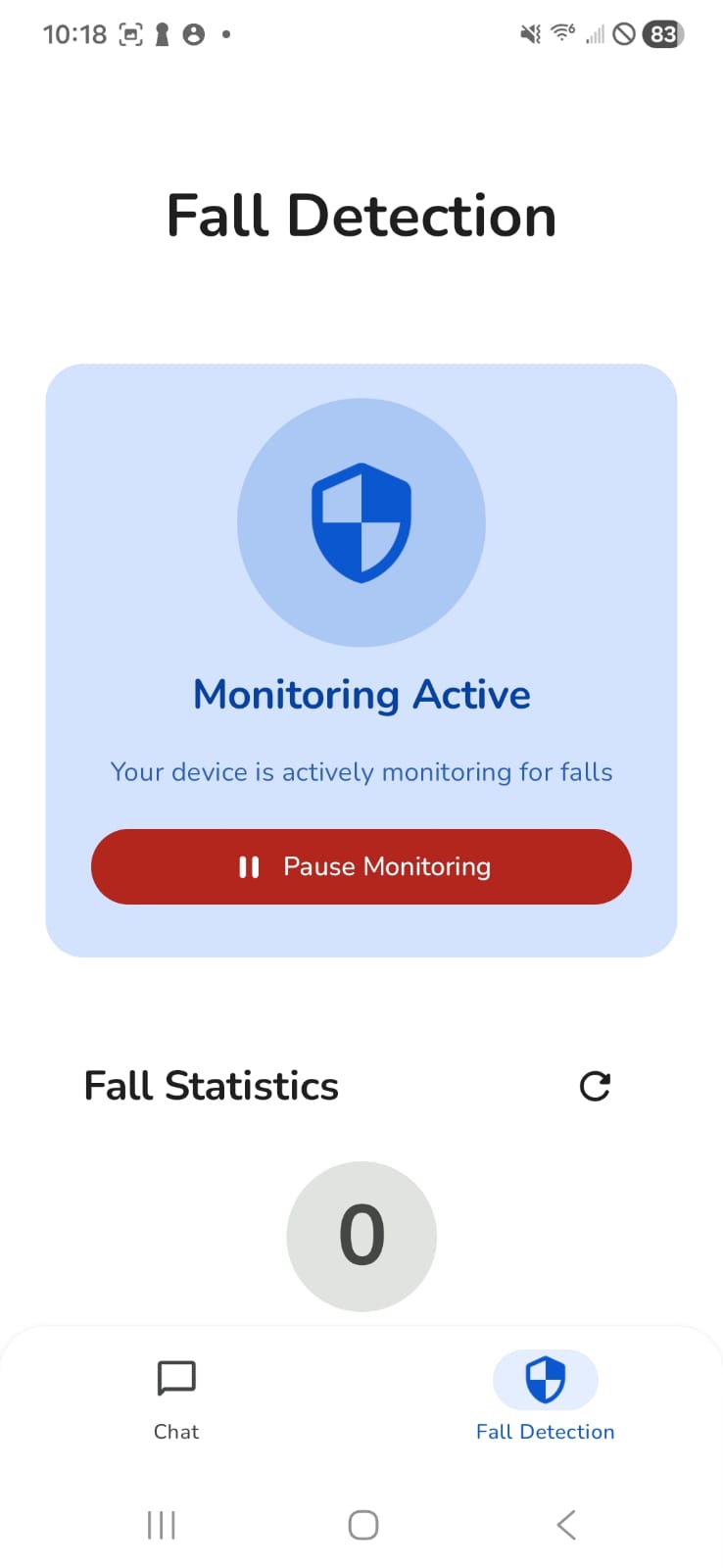
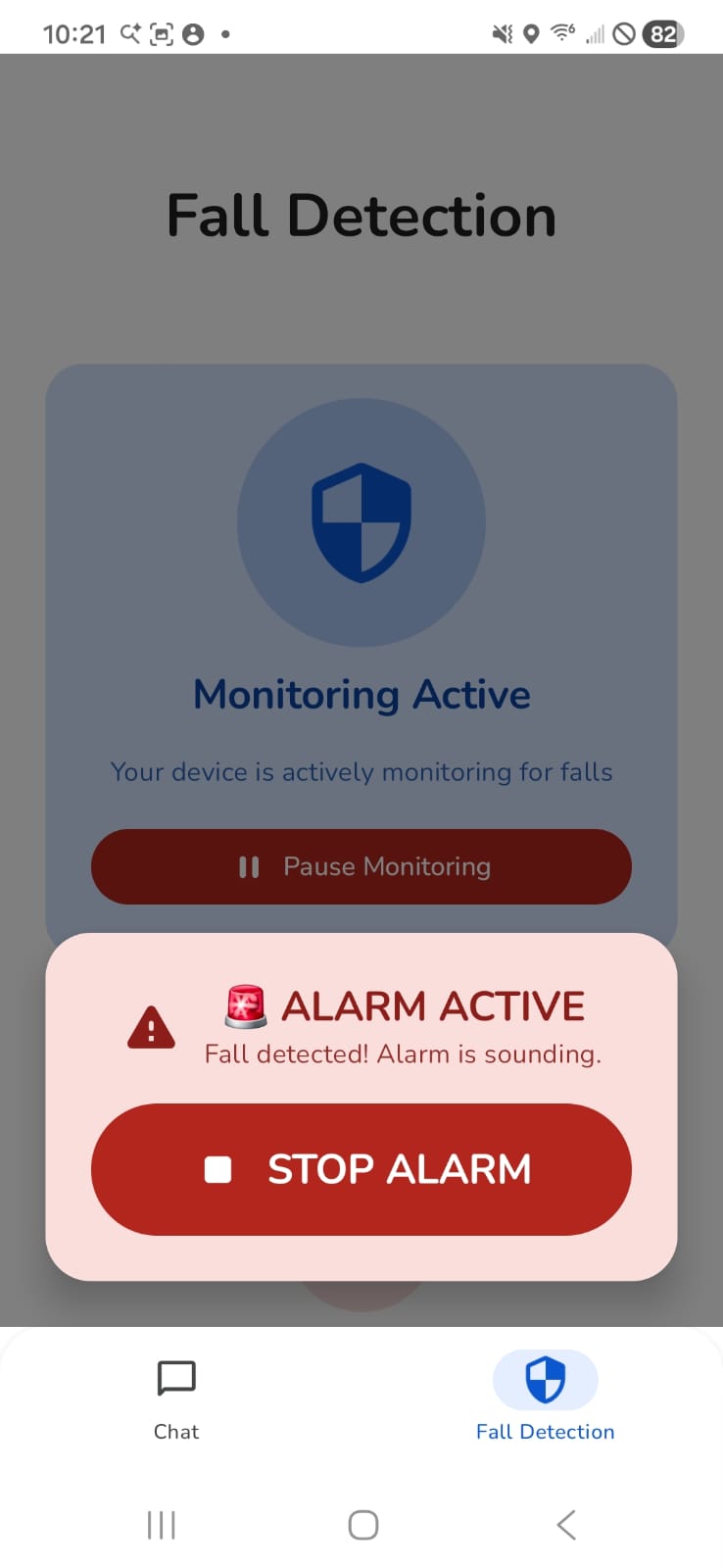
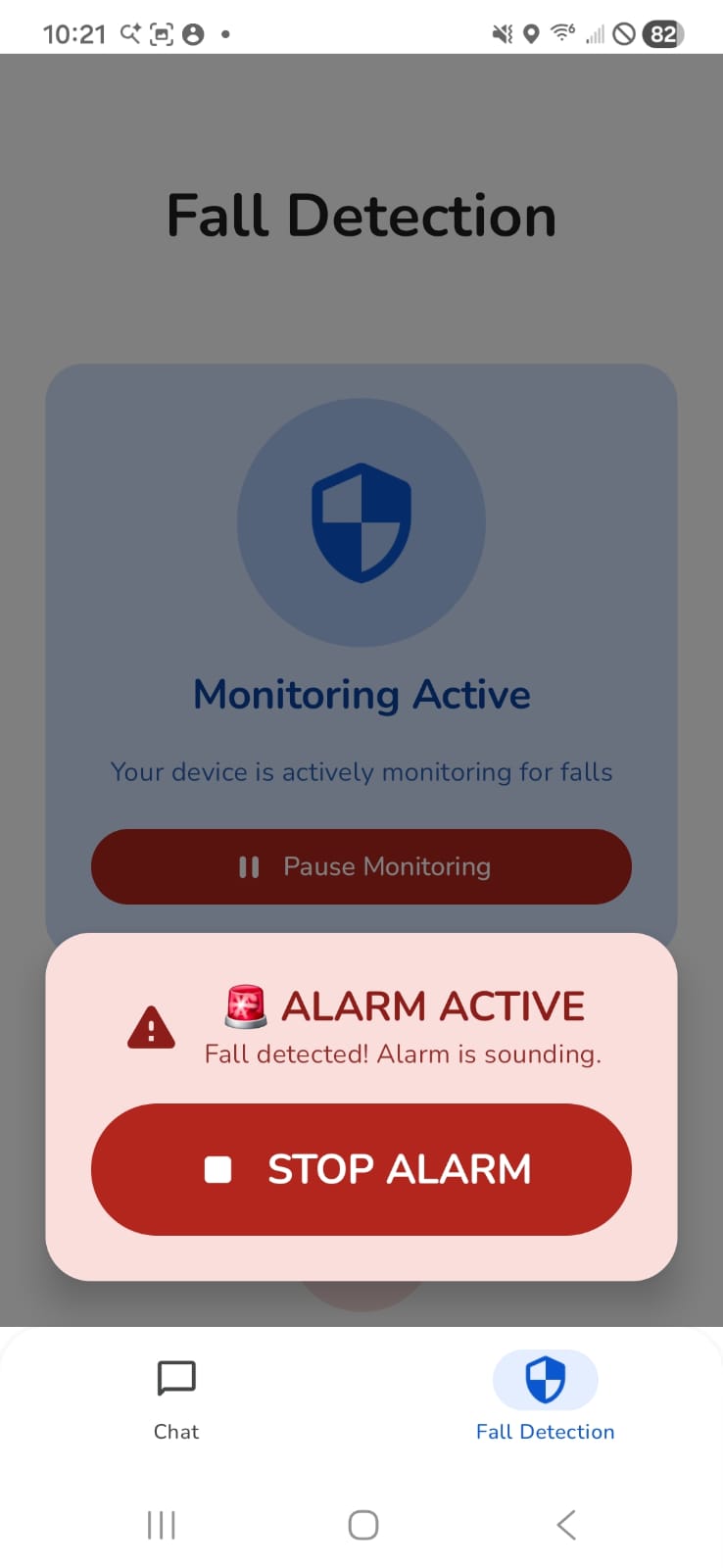
Fall Detection: Continuous monitoring using accelerometer and gyroscope sensors. Detects falls through multi-phase pattern recognition (free-fall → impact → rotation) and triggers 12-second countdown alert with automatic emergency contact dialing and GPS location sharing.
Raspberry Pi Integration: Button-triggered camera capture, ultrasonic distance sensor for obstacle detection, and buzzer alerts. Seamless HTTP communication with Android backend.
Accessibility: Full text-to-speech support, voice input, and screen reader optimization throughout.
How we built it
Android App (Kotlin): Built with Jetpack Compose, MVVM architecture, and Hilt dependency injection. Integrated TensorFlow Lite for ArcFace face recognition, Google Gemma-3n E2B for vision-language understanding, and ML Kit for face detection. Implemented foreground services for reliable background fall detection monitoring.
Face Recognition Pipeline: Pre-processes reference images from assets, uses ML Kit for face detection, generates 512-dimensional ArcFace embeddings, computes average embeddings per person, and matches in real-time using cosine similarity.
Fall Detection Algorithm: Monitors accelerometer (free-fall < 8.0 m/s², impact > 12.0 m/s²) and gyroscope (rotation > 2.0 rad/s) with temporal validation (200-1000ms duration). Triggers 12-second countdown with dismissible notification, then auto-dials emergency contact and sends GPS location via SMS.
Raspberry Pi: Python scripts using OpenCV for camera capture, RPi.GPIO for sensor control, and HTTP POST for image uploads. Ultrasonic sensor provides 20cm proximity detection with buzzer feedback.
LLM Integration: Local Gemma-3n E2B model with streaming responses, function-calling mechanism (<FUNC> tag) for face recognition mode, and real-time TTS integration.
Challenges
One of our major challenges was working with the Arduino UNO R4, which is still not a mature platform. It does not offer much flexibility in either Python or embedded C. Most of the documentation pushes users toward the graphical UI and abstracts away internal processes, leaving very little room for customization beyond the provided examples.
We initially planned to use external gyroscope and accelerometer sensors, but due to hardware limitations and availability, we had to fall back on the Android phone’s built-in sensors to implement fall detection.
Although we obtained a Raspberry Pi, it was not the 1GB RAM variant. This severely limited our ability to run even lightweight TensorFlow Lite support libraries, as the build process itself exceeded available memory.
Building a medical-grade assistive system also demanded robustness. Since hardware failures are possible in real-world use, we designed multiple fallbacks. If peripherals on the wearable belt fail, the system seamlessly switches to Android sensors and vice versa, ensuring continued functionality despite missing components like gyroscopes or accelerometers.
Accomplishments
We were among the first to deploy the Gemma 3B model with quantization for real-time visual question answering, achieving practical performance on-device. We also successfully utilized both GPU and CPU acceleration to optimize inference speed.
We implemented instant face classification and identification, allowing visually impaired users to register familiar faces and simply ask who is in front of them, receiving immediate audio feedback. This enables a truly personalized and independent social interaction experience.
Overall, we built a resilient system with multiple fallbacks, real-time AI capabilities, and seamless hardware–software integration—pushing the boundaries of what on-device assistive technology can achieve.
What's next for DRISHTI
- Runtime face database management (add/remove people)
- Live camera face recognition
- ML-based fall detection model
- Real-time object detection and OCR
- Smartwatch sensor integration
DRISHTI represents our commitment to using technology to create meaningful impact in people's lives.
Built With
- kotlin
- python
- raspberry-pi


Log in or sign up for Devpost to join the conversation.