-
-

IRL Membrane Distillation Chamber
-
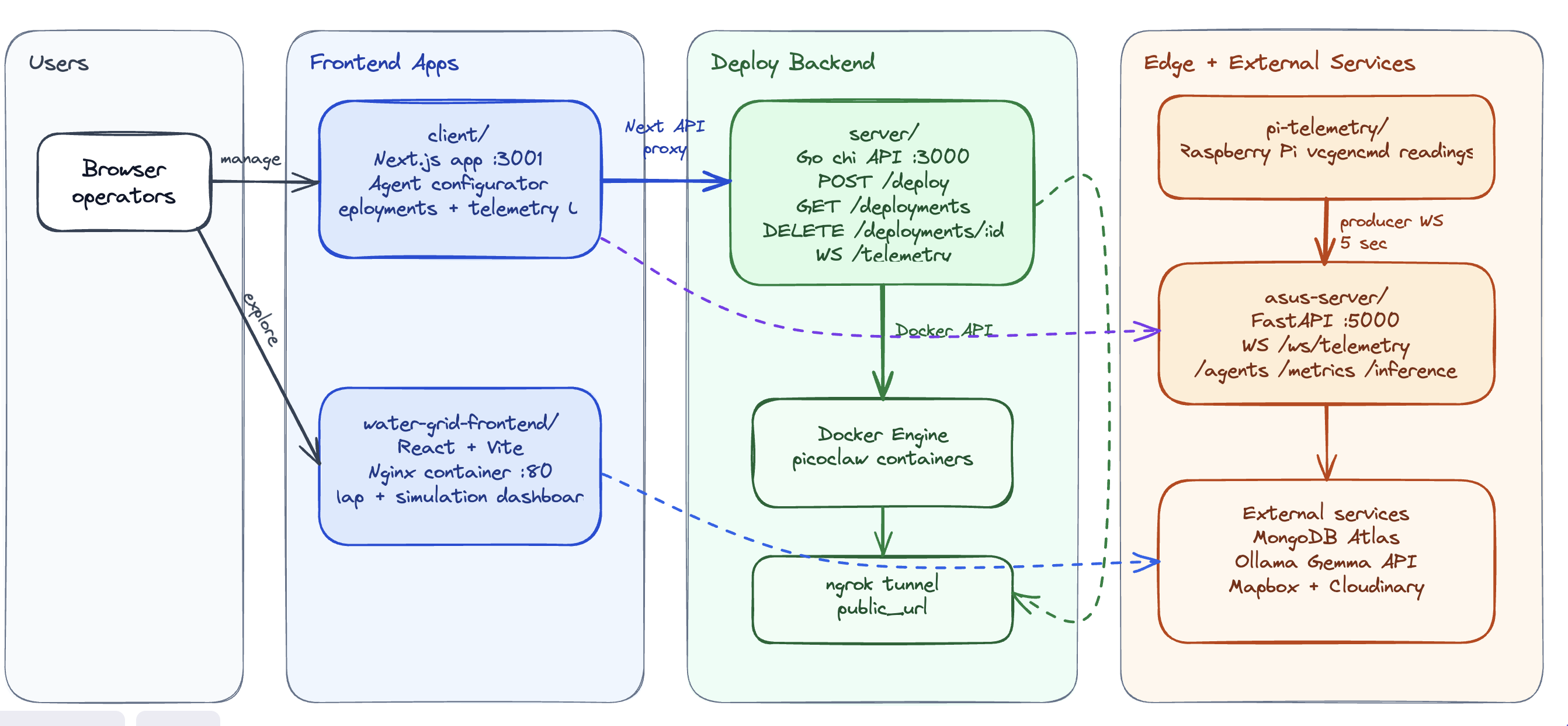
System Architecture
-
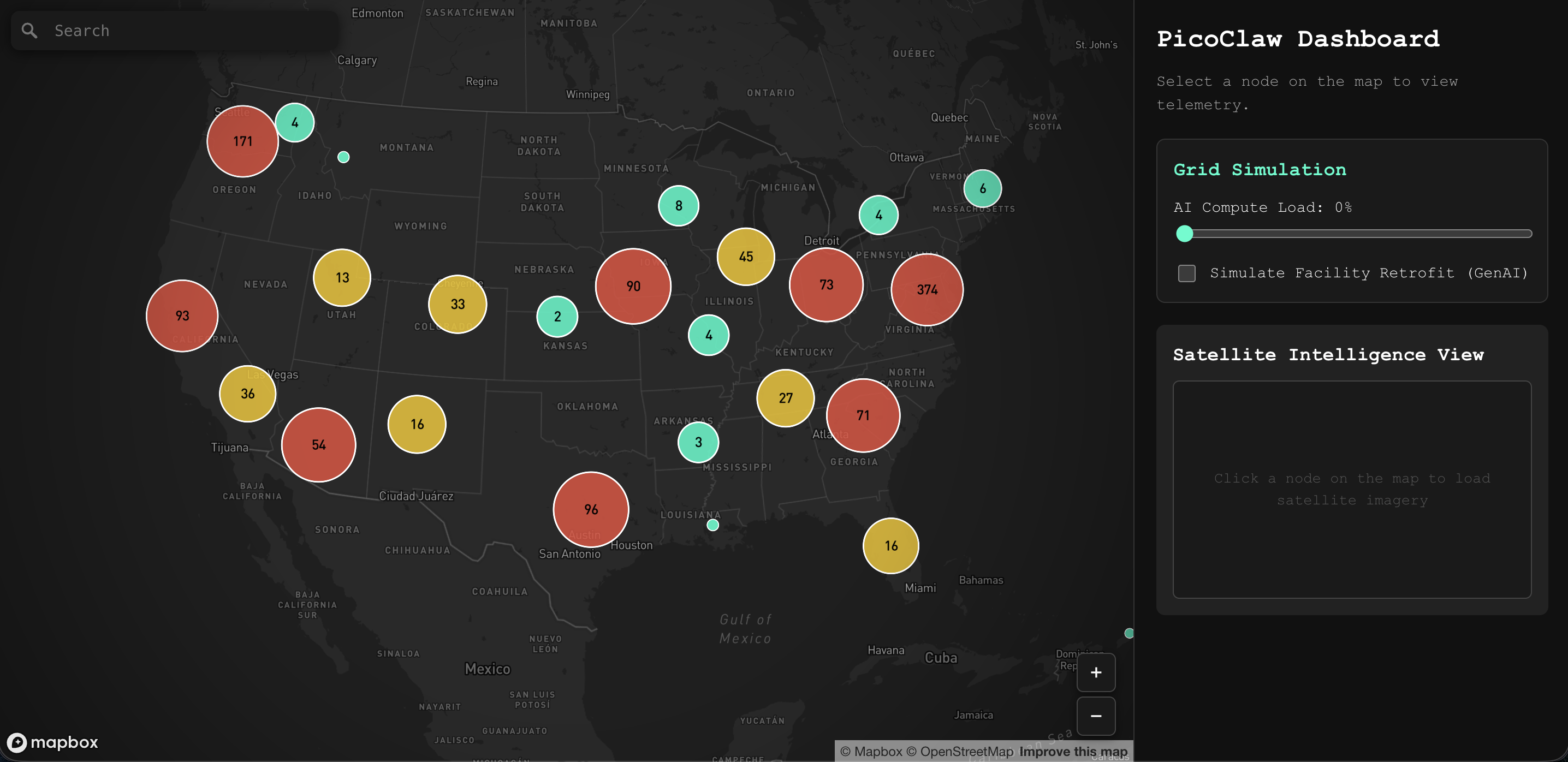
Data Center Map & Simulation
-
Hero
-
Landing
-
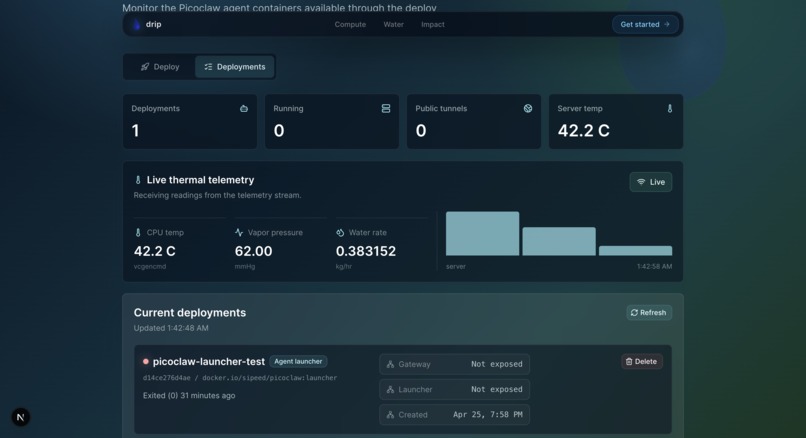
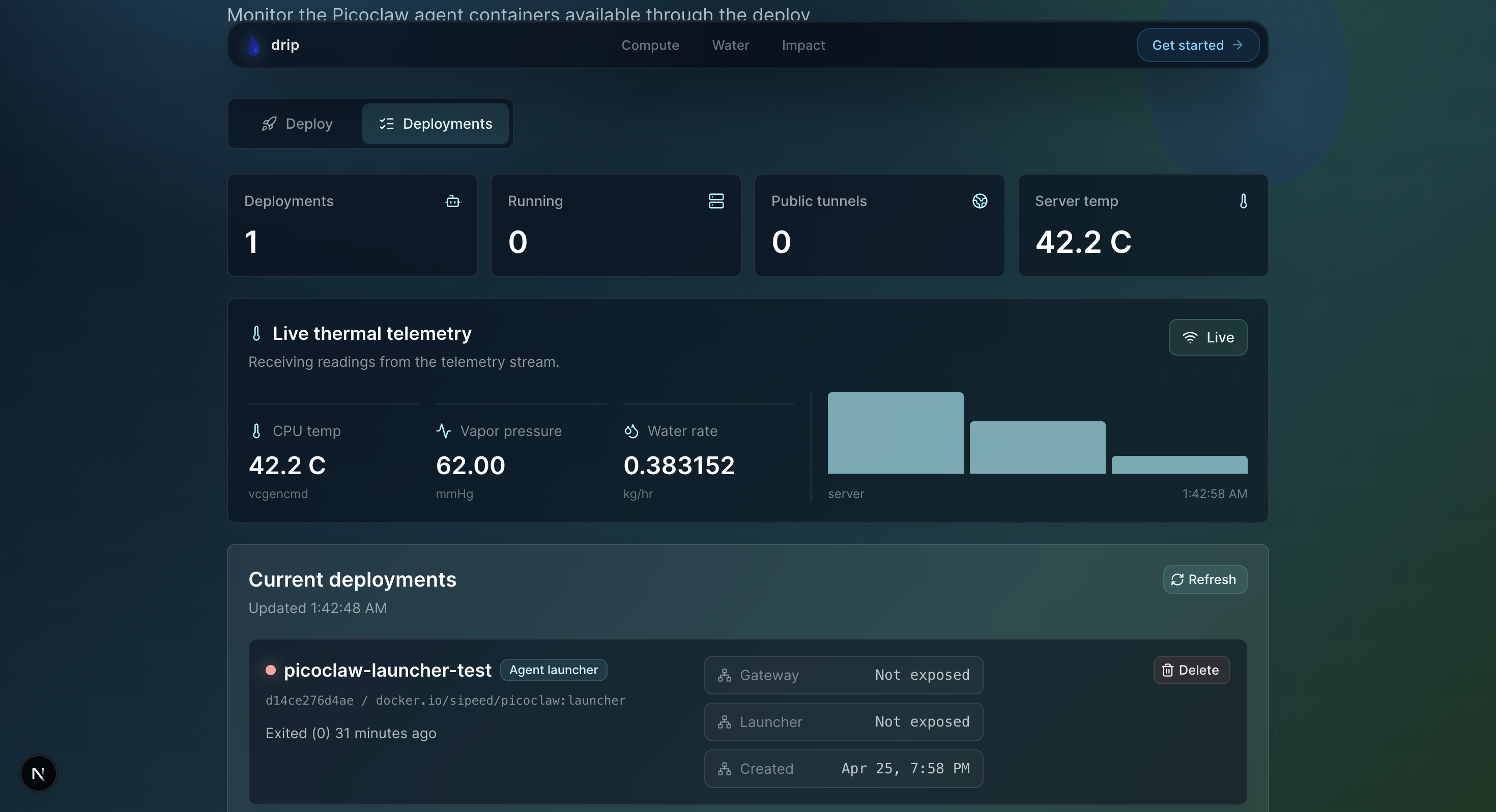
Live Telemetry Readings

Inspiration
We’re from Florida, a state currently facing severe drought conditions. Seeing this crisis pushed us to ask how we, as tech students, could build something that gives back to the planet. Traditional evaporative cooling systems depend on clean freshwater and often waste it in the process. As AI infrastructure continues to grow rapidly, we wanted to rethink that tradeoff. Instead of letting AI consume more water, our goal is to use its waste heat to help generate it.
What it does
Our project, Drip, combines edge computing with custom chemistry hardware to transform AI waste heat into clean water.
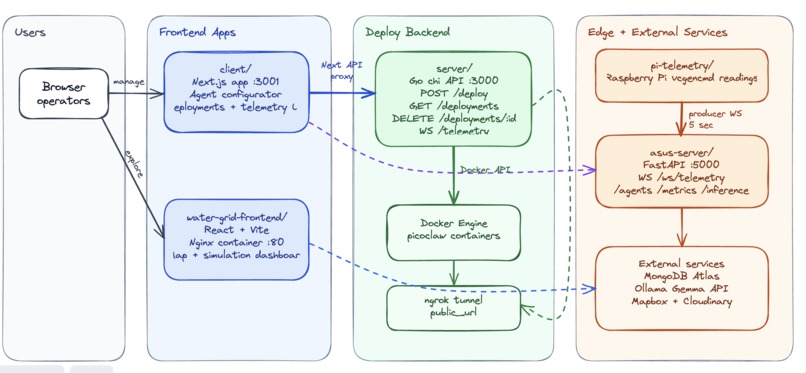
Software & Compute : We built a prototype using a Raspberry Pi 5 for easy, one-click user deployments. The Pi simulates a datacenter using containers to provide isolated environments for agent deployments to run. The ASUS server runs dynamic instances of the Ollama Gemma 4 E4B LLM for each user. Through a Tailscale network, the PicoClaw container uses our server as a cloud interface, granting it seamless access to Gemma's compute.
Hardware & Desalination : Alongside the software, we engineered a custom Membrane Distillation (MD) Chamber and a closed-loop liquid cooling system for the Pi 5. Membrane Distillation treats saline water, which we collected from Santa Monica Beach, and turns it into freshwater. The Pi simulates an AI data center by expelling waste heat during usage. This heat is transferred to the hot chamber of our MD system. Conversely, the cold chamber utilizes a Peltier module attached to an insulated lunchbox. Water circulates in parallel through both the hot and cold sides. As vapor pushes through a hydrophobic membrane filter and touches the cold side, it instantly condenses back into a liquid state, generating fresh water. Our custom liquid cooling system for the Pi operates in a closed loop to ensure no water is lost to evaporation.
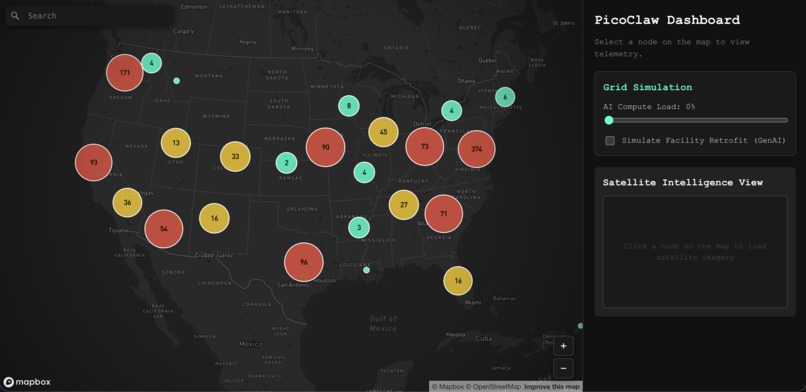
Impact Visualization: We also developed a map using a public dataset of U.S. data centers to demonstrate the massive impact our MD concept would have if adopted nationwide, visualizing the sheer volume of water that could be generated instead of wasted.
How we built it
Networking & Deployment We started by bringing the Raspberry Pi 5 online as a liquid-cooled edge node. After SSHing into the device, we configured a Tailscale mesh network so the Pi could be securely accessed for development. The pi was configured with software to deploy agent instances through one click to loally running docker containers. These agent instances would be exposed to the internet via ngrok tunneling for 24/7 use by the user.
For inference, each PicoClaw container routes requests to an Ollama Gemma 4B instance running on the ASUS Micro Server, which acts as our local AI “cloud.” The Pi and ASUS server communicate over an Ngrok tunnel, creating a secure TCP pathway between the deployment node and the inference backend. This lets us separate compute orchestration from model serving while still keeping the system portable and demo-friendly.
We also built a PicoClaw deployer website that gives users a one-click deployment flow for spinning up containers on their edge devices. The dashboard streams live telemetry from the Pi, including thermal output, chamber temperatures, and runtime status. That data is then used to estimate projected water yield from expelled waste heat and the temperature gradient between the hot and cold chambers.
Hardware & Chemistry The physical build required a chemistry-driven heat transfer setup. We connected the Raspberry Pi to a custom liquid cooling block, allowing waste heat from the processor to transfer into the hot chamber, which was built from a thermos. This heat transfer can be modeled by:
$$ q = mc\Delta T $$
where (q) is the heat absorbed by the water, (m) is the mass of the water, (c) is the specific heat capacity, and (\Delta T) is the temperature change.
The cold chamber was built using an insulated lunchbox and a Peltier module, acting as a miniature refrigerator. The temperature difference between the hot and cold sides creates the driving force for membrane distillation. The bridge between these zones is the MD chamber, constructed from polycarbonate panels, hex bolts, flat washers, wingnuts, tubing, silicone gaskets, and a hydrophobic membrane filter. This chamber contains two shallow compartments that allow hot and cold water to circulate on opposite sides of the membrane, powered by 12V water pumps.
The separation process is driven by a vapor pressure gradient across the membrane:
$$ \Delta P = P_{\text{hot}} - P_{\text{cold}} $$
The vapor pressure on each side can be estimated using the Antoine equation:
$$ \log_{10}(P_{\text{vap}}) = A - \frac{B}{C + T} $$
where Pvap is the saturation vapor pressure of water, T is the water temperature, and A, B, and C are Antoine constants for water.
Water evaporates from the warm saline side, passes through the membrane as vapor, and condenses on the cold side, leaving salts and contaminants behind. The overall vapor flux can be approximated by:
$$ J = C_m(P_{\text{hot}} - P_{\text{cold}}) $$
where J is the water vapor flux, Cm is the membrane mass-transfer coefficient, and Phot - Pcold is the vapor pressure difference created by the temperature gradient.
The membrane coefficient can be written as:
$$ C_m = \frac{\varepsilon}{\tau \delta}D_{\text{eff}}\frac{M_w}{RT_m} $$
where ε is the membrane porosity, τ is the tortuosity, δ is the membrane thickness, Deff is the effective vapor diffusivity through the membrane pores, Mw is the molar mass of water, R is the gas constant, and Tm is the average membrane temperature.
Challenges we ran into
As Computer Science and Information Technology students, stepping into a chemistry-heavy domain was our biggest hurdle. We had to conduct extensive feasibility research to manage the many moving parts of the physical build. Thankfully, after rigorous testing, we verified that the system successfully generates water.
Integrating new technologies from our sponsors (ASUS, Cloudinary, and Arista) required reading extensive documentation and using AI assistance to synergize the components. On the server side, we initially struggled with the ASUS Micro Server. We wanted to distribute its compute for a Gemma 4 vLLM across multiple users to simulate a data center. We ultimately figured out how to host multiple instances of the Ollama LLM per user instead with a custom Async Engine to handle multiple user requests. Routing this data and establishing reliable networking between the edge devices (the Pi and the server) also proved to be a significant technical challenge.
Accomplishments that we're proud of
We are incredibly proud to have verified that our Membrane Distillation process actually works and generates fresh water. In a world where clean water is becoming a scarce resource, proving this concept has real-world applicability is a huge win. We are also proud to have built a highly cohesive project—every software and hardware component synergizes perfectly with a clear, unified purpose.
What we learned
We learned an immense amount about chemistry and the mechanics of Membrane Distillation. On the software side, we wrote our server in Go—a completely new language for us—and experienced its benefits in optimization and speed. We also gained hands-on experience with the ASUS server, the Cloudinary AI React Starter Kit, and advanced networking concepts through the Arista challenge. Most importantly, we learned that AI doesn't have to be a drain on our environment; it can be used to combat drought and replenish our natural resources.
What's next for Drip
We want this in every AI and data center! SAVE THE PLANET!
Built With
- asus-ascent-gx10
- cloudinary
- gemma
- go
- javascript
- next.js
- ngrok
- python
- raspberry-pi
- react
- tailscale
- typescript











Log in or sign up for Devpost to join the conversation.