-
-
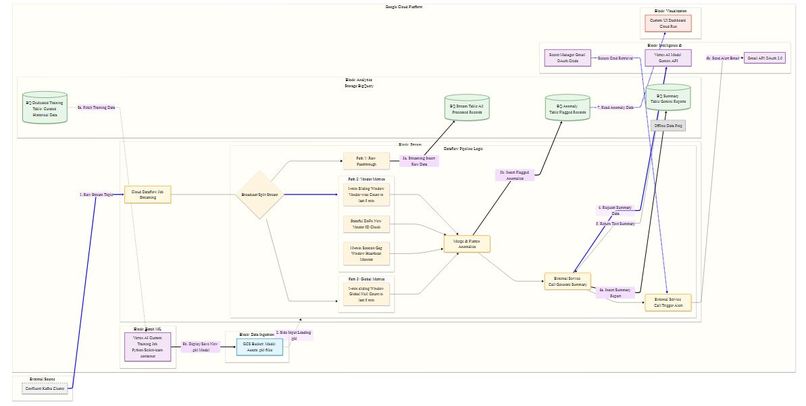
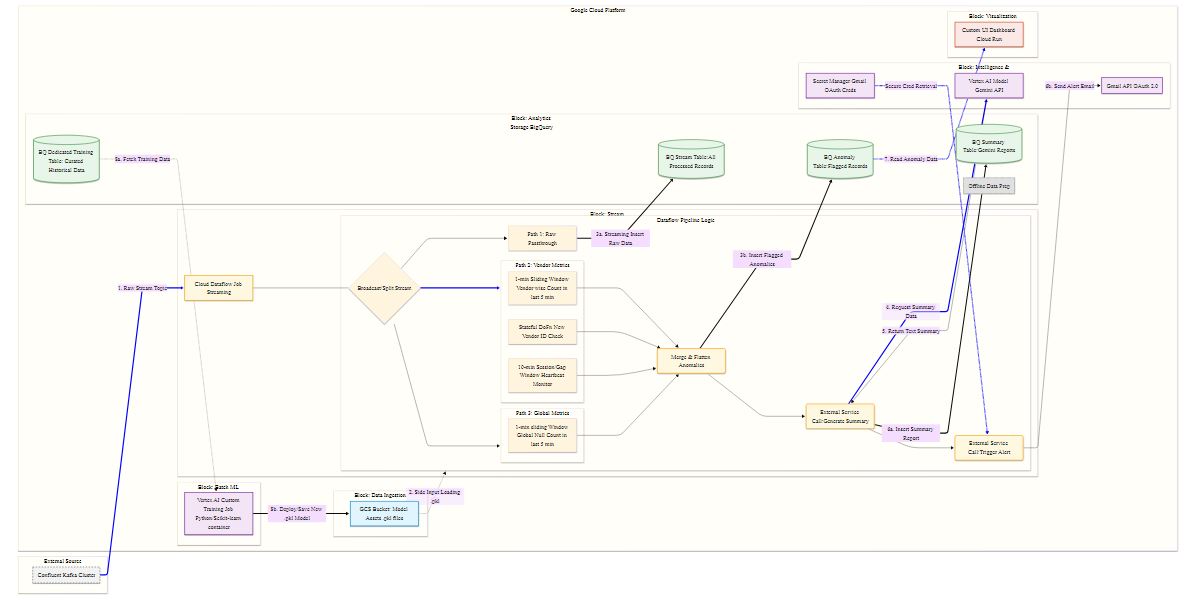
High level architecture: Kafka to BQ: Dataflow stream & Vertex AI anomaly detection. Gemini summarizes for BQ, dashboards & email alerts.
-
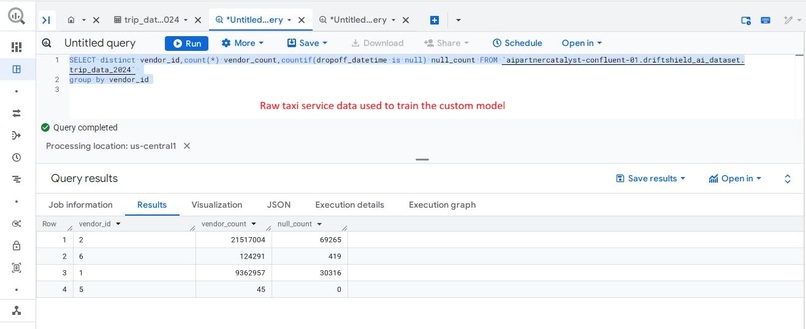
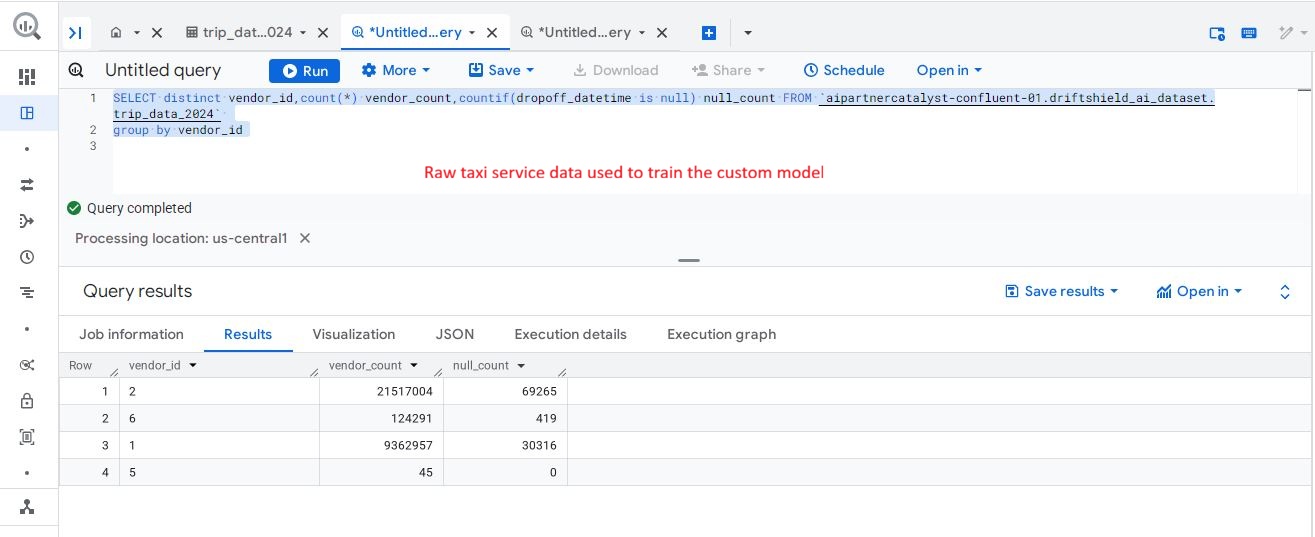
Curated BigQuery table used as the primary data source for training the custom anomaly detection model in Vertex AI.
-
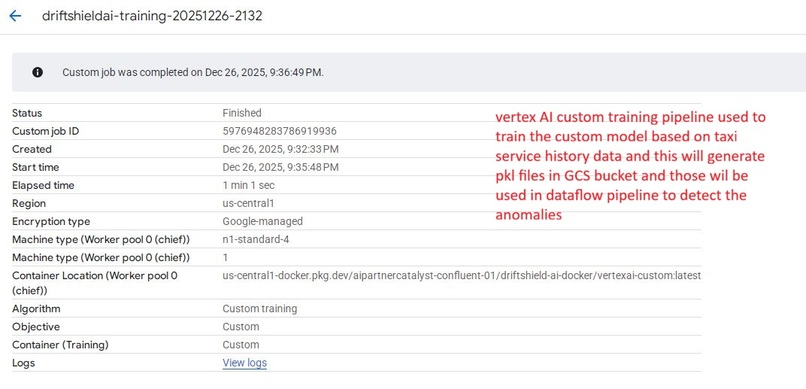
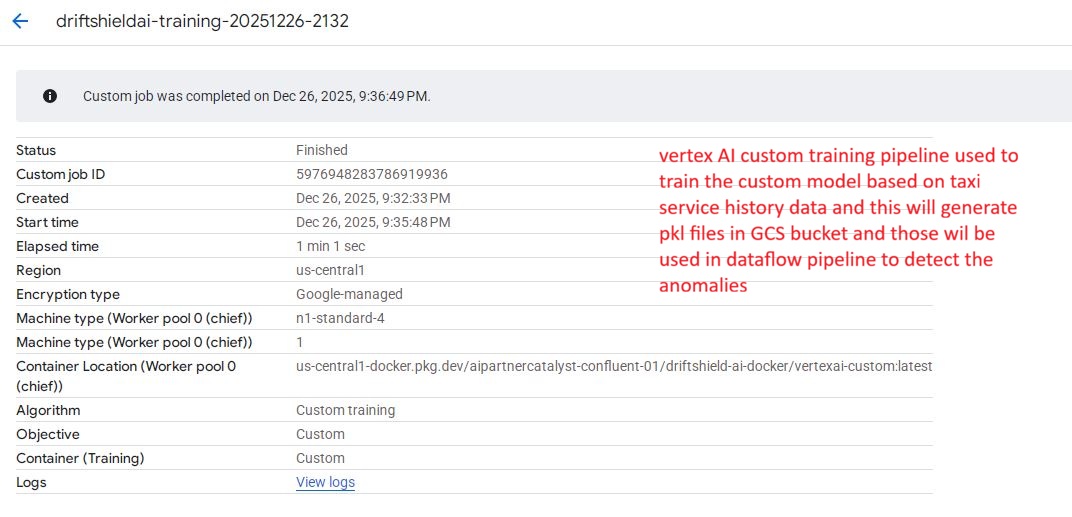
Custom training job execution in Vertex AI to produce model files (.pkl) for real-time anomaly detection in Dataflow.
-
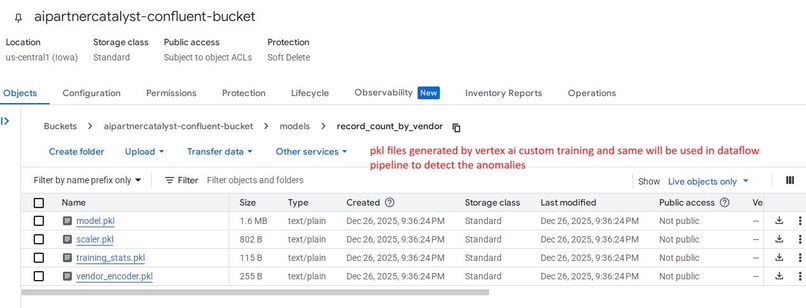
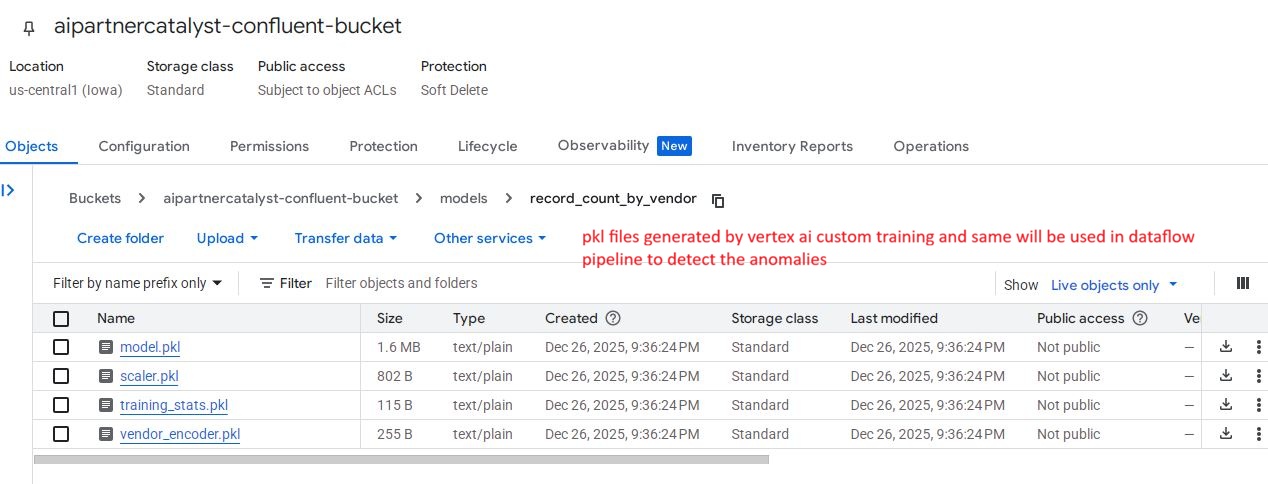
Model artifacts (.pkl) stored in GCS, generated by Vertex AI for real-time anomaly detection within the Dataflow pipeline.
-
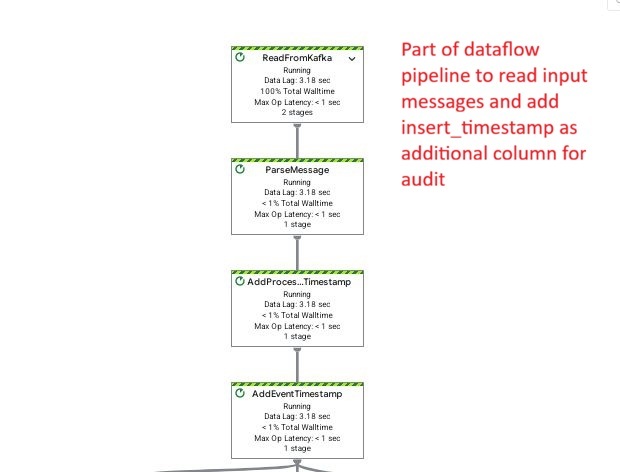
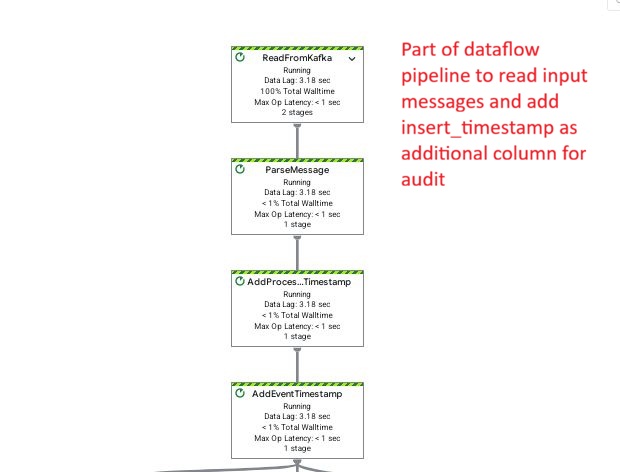
Dataflow step: Reading Kafka streams and adding an insert_timestamp audit column for tracking ingestion time in BigQuery.
-
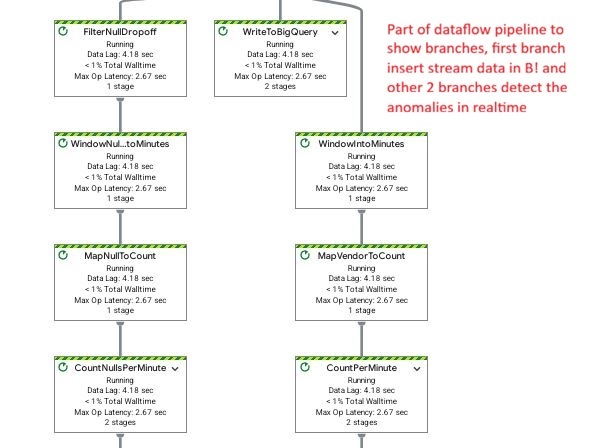
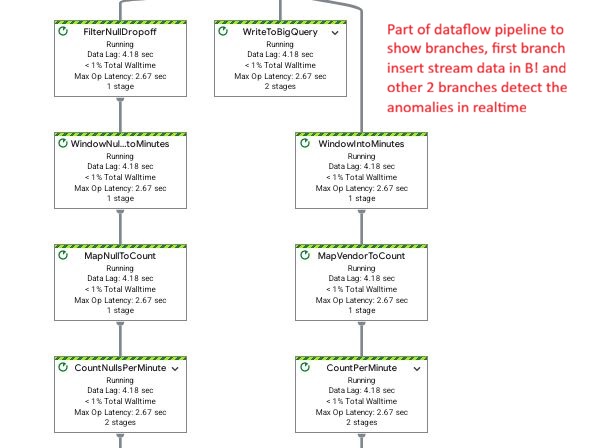
Dataflow branching: 1. Raw BQ ingestion, 2. Vendor anomaly detection, and 3. Null count detection for real-time monitoring.
-
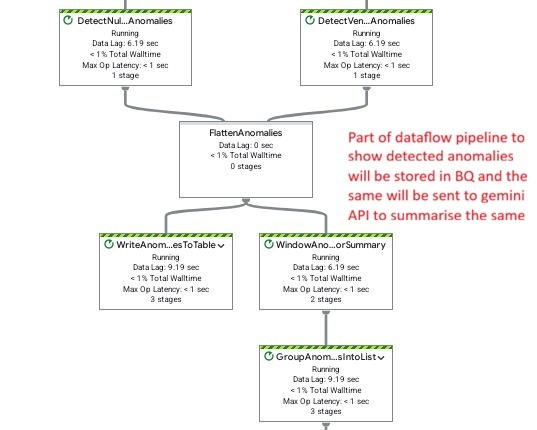
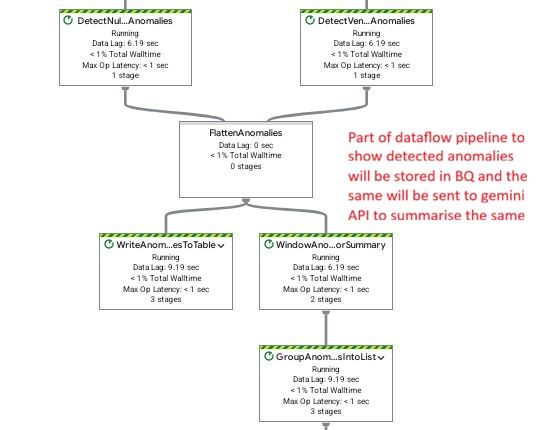
Dataflow pipeline: Flattening detected anomalies for BQ ingestion and invoking Gemini API to generate summary insights.
-
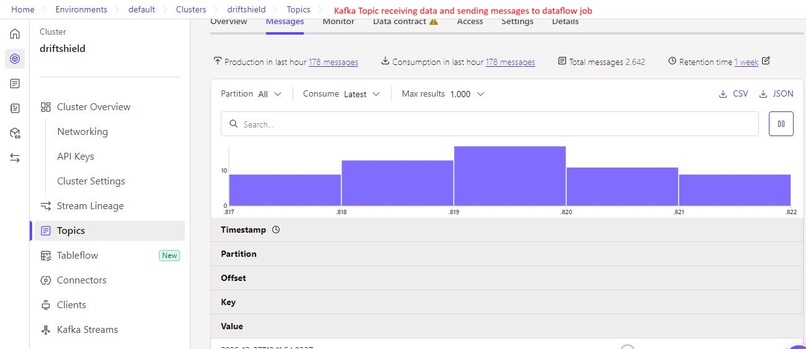
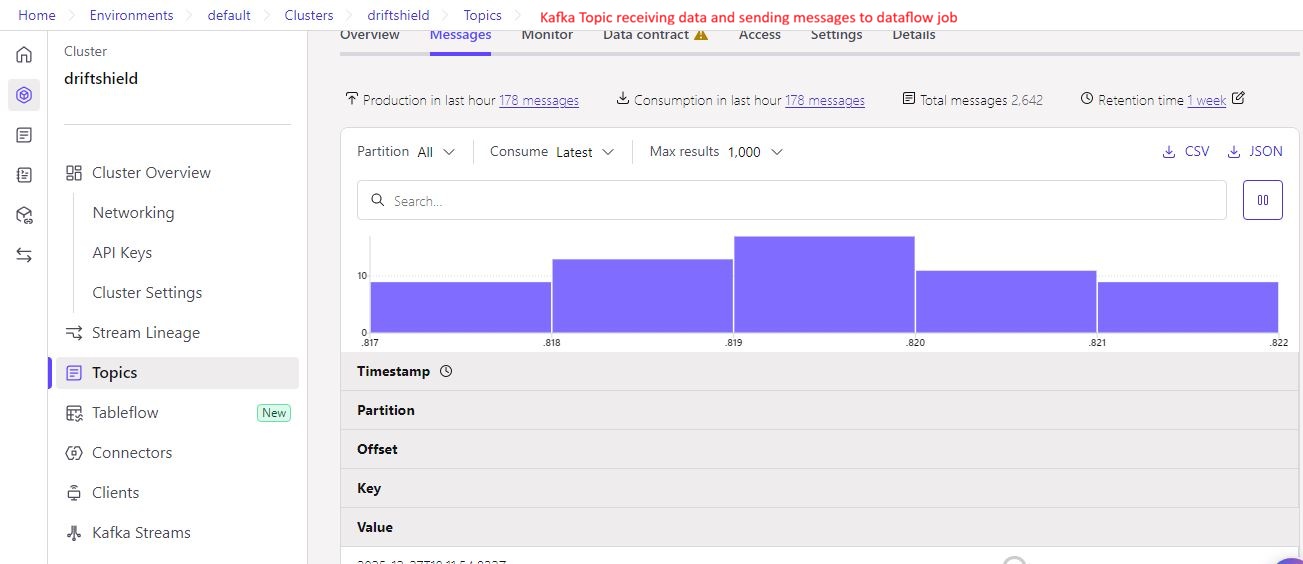
Raw data stream in Kafka, acting as the primary entry point for BigQuery ingestion and Vertex AI model processing.
-
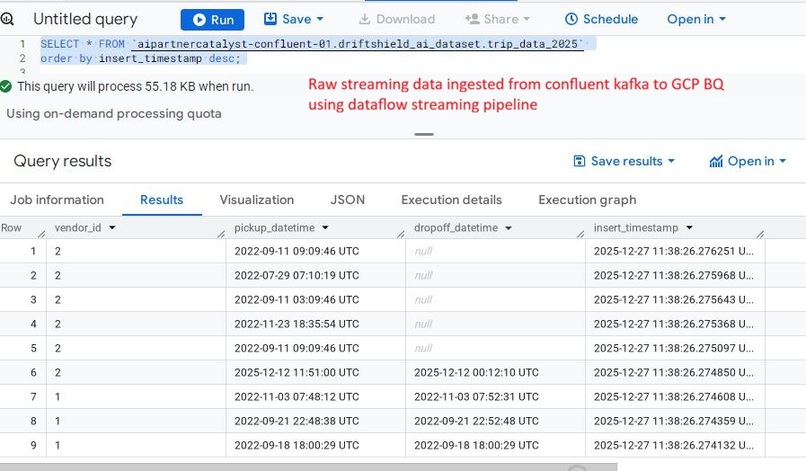
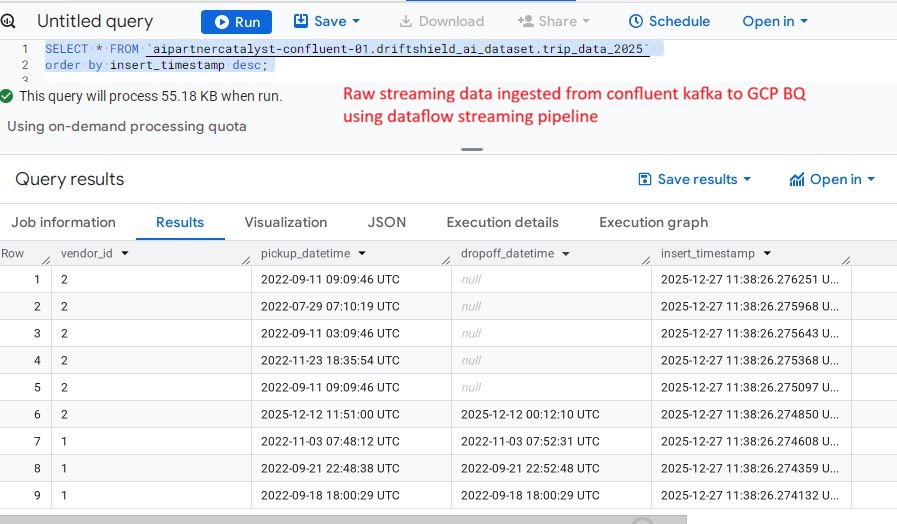
BigQuery destination table showing live streaming data from Kafka with the automatically appended insert_timestamp column.
-
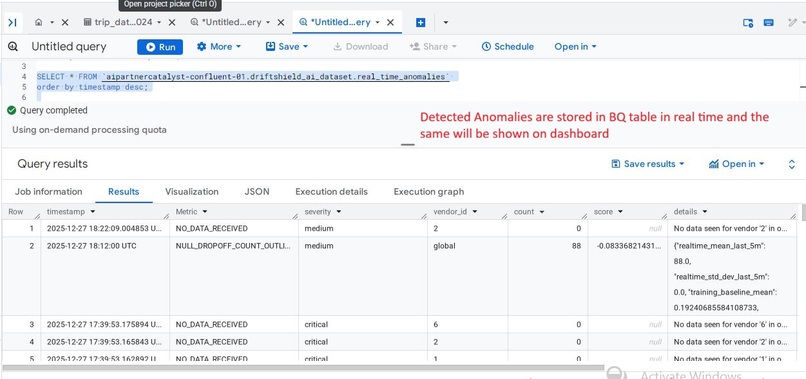
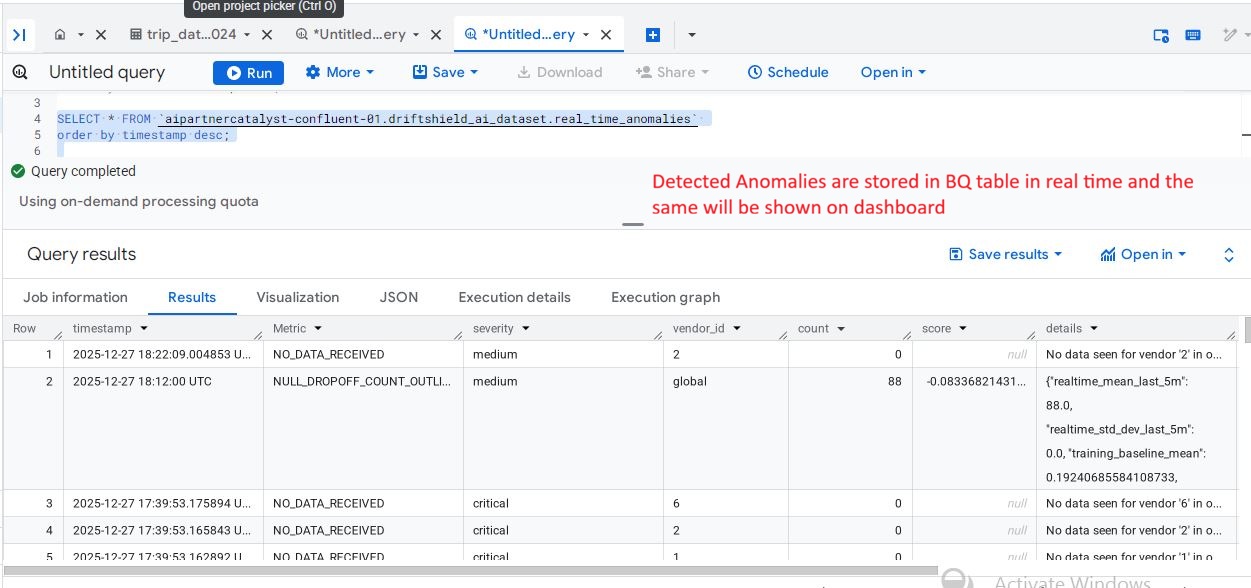
Detail Table in BigQuery: Storing flattened anomaly records including vendor metrics and null counts for historical auditing.
-
Cloud Run service used to deploy the interactive Anomaly Dashboard for tracking vendor trends and data quality metrics
-
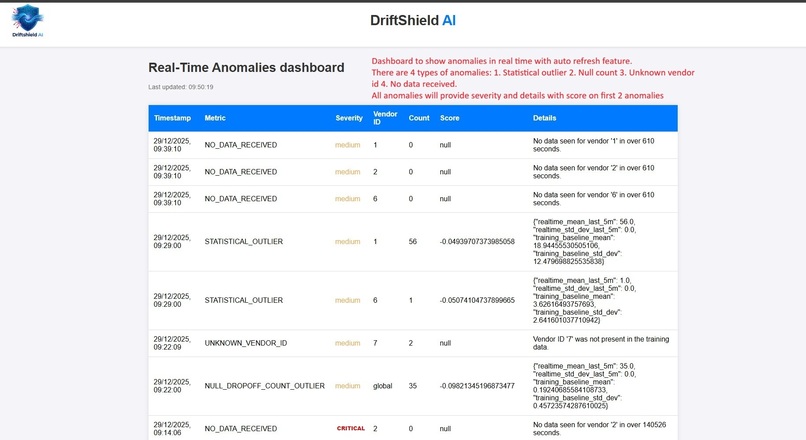
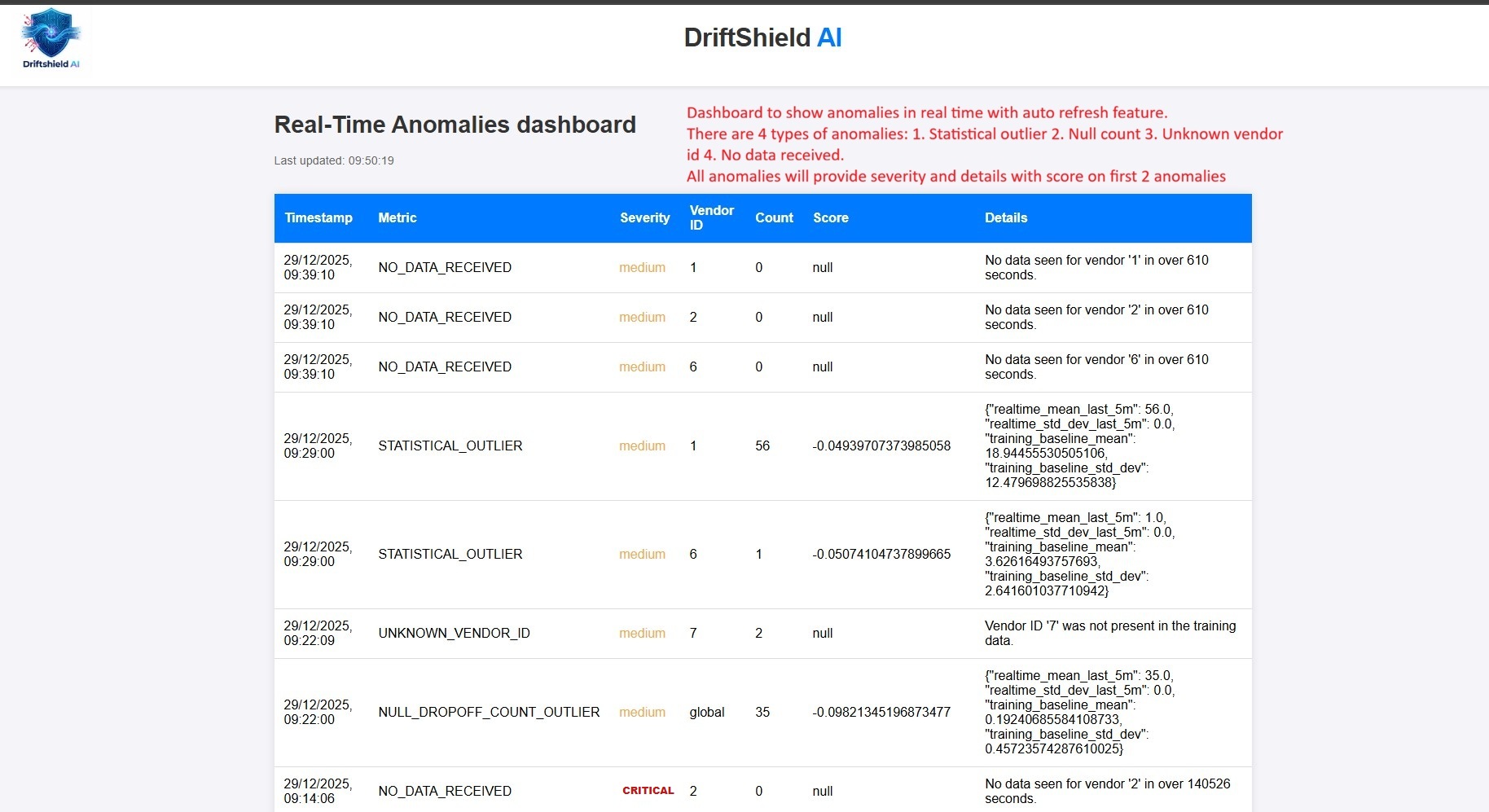
Real-Time Anomalies dashboard: : A unified view of alerts and AI/ML generated score with detail
-
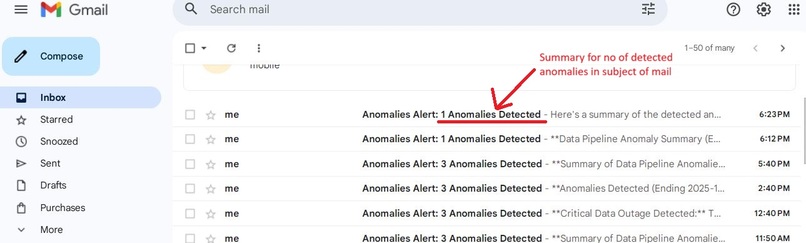
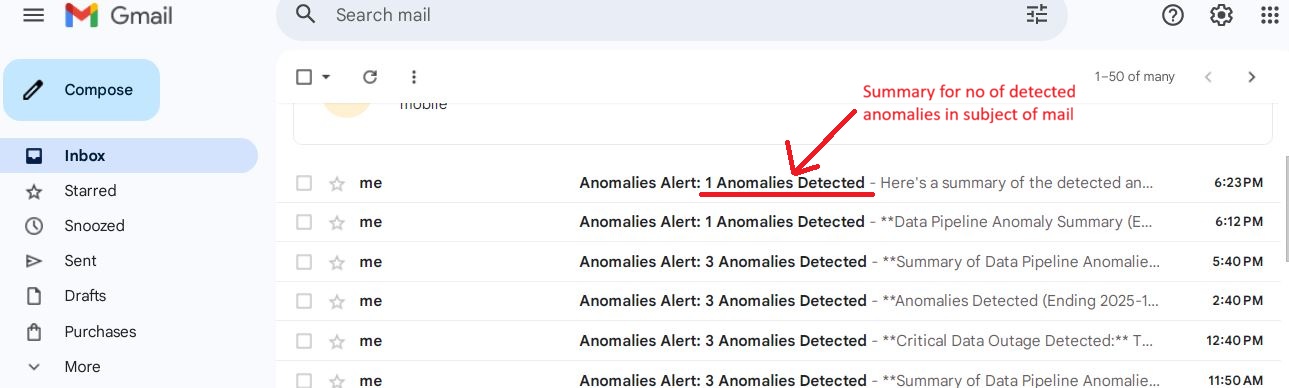
Mail alert view: Dynamic subject line showcasing the anomaly count to ensure immediate visibility for critical data quality issues.
-

Email content featuring a Gemini-generated summary, providing clear, natural language context for the detected data anomalies.
-
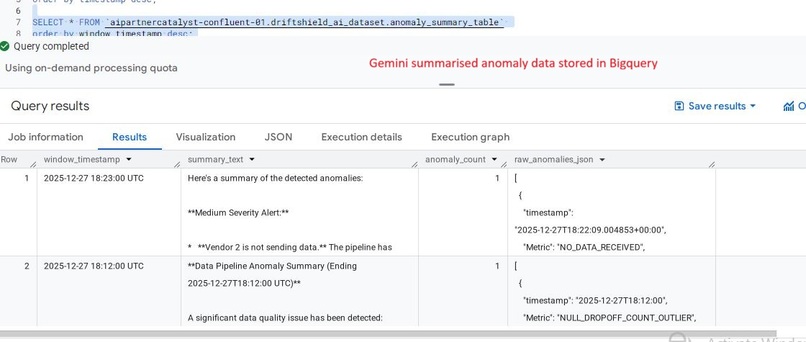
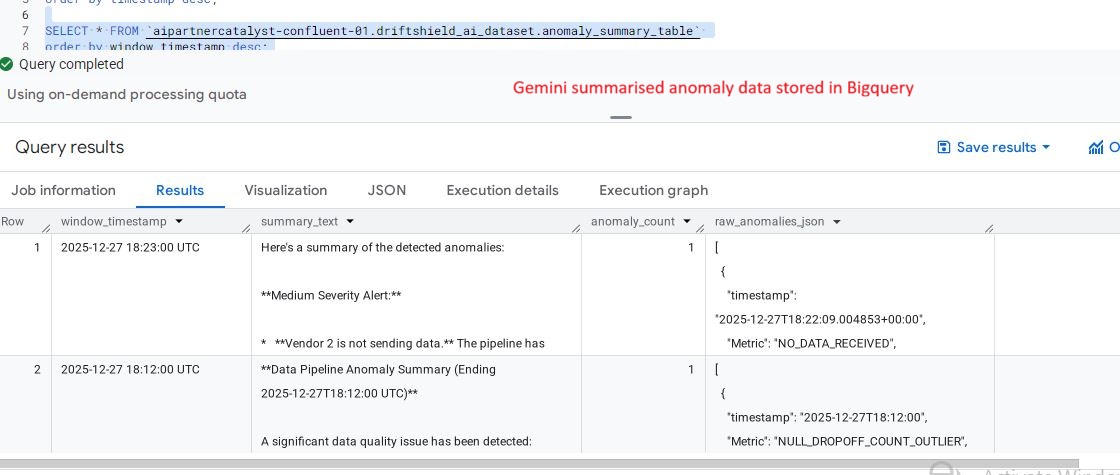
Gemini Summary Table: A dedicated table for AI-generated anomaly narratives, providing clear context for stakeholders and alerts.
-
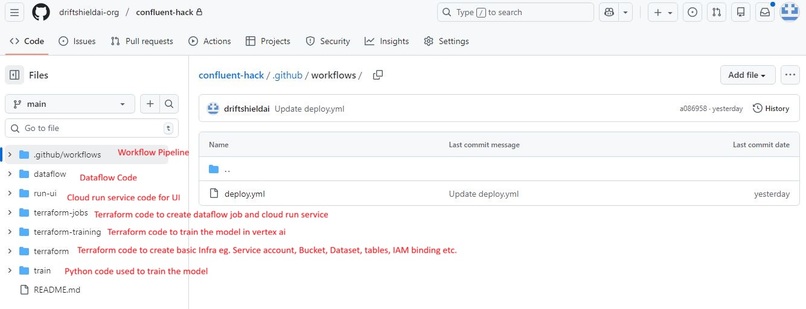
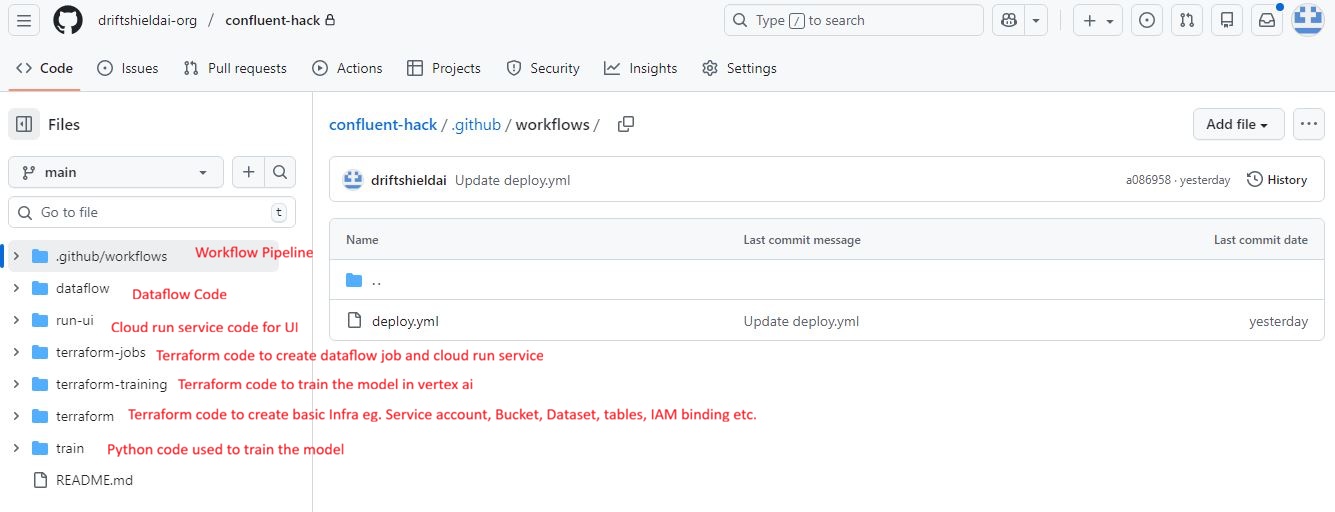
GitHub repository structure: Organized modules for Dataflow pipelines, Vertex AI training scripts, and the Cloud Run dashboard code.
-
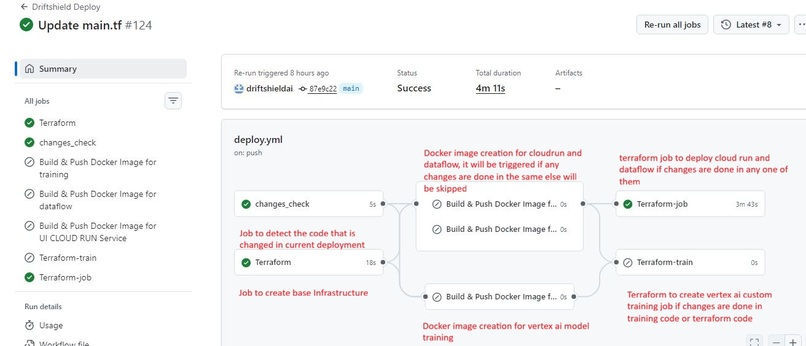
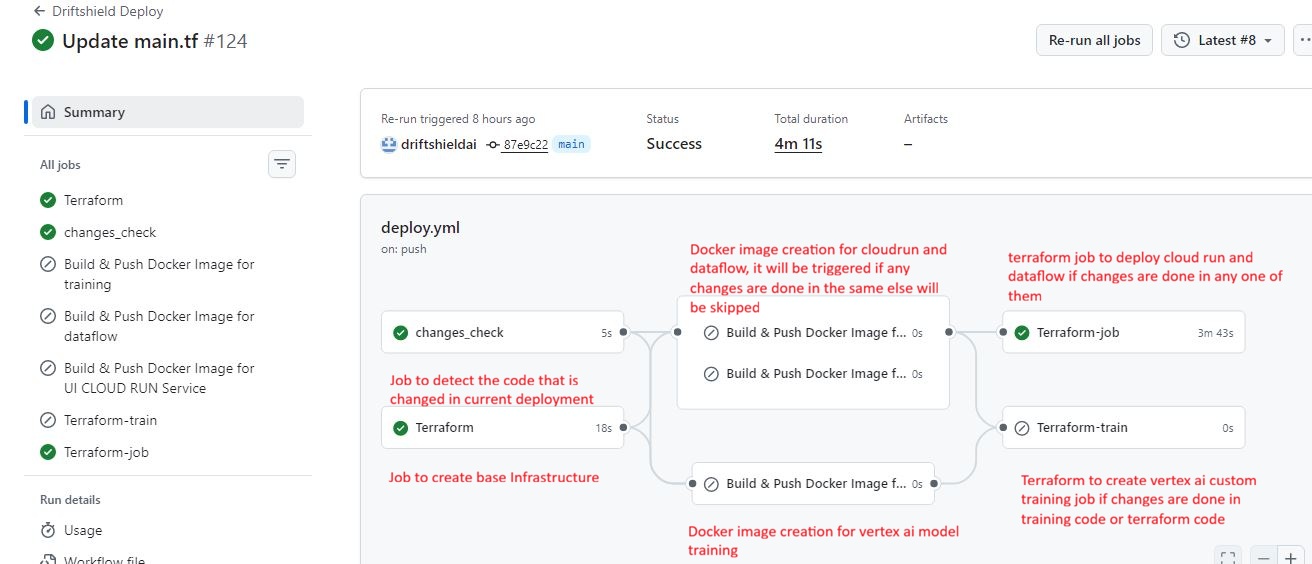
GitHub Actions workflow: Automating CI/CD for the GCP base infra, Dataflow pipeline, Vertex AI training, and Cloud Run dashboard deployments

DriftShield AI brings observability to data in motion. Using Confluent Kafka and Vertex AI, it learns normal streaming behaviour and detects data quality anomalies in real time, alert for bad data before it breaks analytics or ML pipelines.
Inspiration
We are in an era of real-time data and AI-driven decision making, where streaming platforms power analytics, automation, and intelligent systems. As decisions move faster, trust in data becomes critical at the moment it is used, not after it is processed. This shift inspired the idea behind DriftShield AI—to apply AI not just to consume data, but to continuously understand and protect data quality as it flows. By bringing intelligence directly into streaming pipelines, DriftShield AI aims to make real-time decisions both faster and more reliable.
What it does
DriftShield AI provides real-time anomaly detection and drift monitoring for streaming data pipelines.
It predicts and detects:
- New vendor IDs that have never appeared before
- Abnormal record counts per vendor in a rolling 5-minute window
- Missing data events:
- No data for 10 minutes → Medium
- No data for 60 minutes → High
- No data for 180 minutes → Critical
- Sudden global spikes in null values for key columns
Every minute:
- The last 5 minutes of streaming data are analysed
- Detected anomalies based on ML models predictions:
- Stored in BigQuery
- Displayed on a real-time dashboard
- Sent to Gemini API for intelligent summarization
- Delivered as email alerts
- Persisted back into BigQuery for auditing and analytics
How we built it
Architecture Overview
DriftShield AI works as a real-time data quality guardrail in a streaming analytics pipeline:
[ Confluent ]
|
▼
[ Cloud Dataflow ] <───> [ Gemini AI (Vertex AI) ]
|──────────┐ (Prediction and Insight Generation)
| [ Mail Alert ]
▼
[ BigQuery Storage ]
|
├──────────────┐
▼ ▼
[ Cloud Run UI ] [ Vertex AI Training ]
(Live Dashboard) (Model Re-tuning)
Detected anomalies are:
- Stored in BigQuery
- Showing on Realtime dashboard
- Summarized using Gemini API
- Sent as email alerts
- Persisted for auditing and trend analysis
Key Components
Streaming Ingestion
- Data flows from Confluent Kafka into BigQuery using Apache Beam on Dataflow
- Optimized for low-latency
Anomaly Detection Engine
- Historical data used to train a Vertex AI custom model
- Features include:
- Vendor frequency patterns
- Time-based arrival gaps
- Rolling window aggregates
- Null ratio distributions
ML Anomaly Detection
- ML-based anomaly scoring for distribution shifts
- Deterministic rules (missing data thresholds)
Real-Time Dashboard
- Built using Cloud Run
- Displays:
- Live anomaly feed
- Severity levels
- Vendor-level impact
AI-Powered Summaries
- Raw anomalies are sent to Gemini API
- Gemini generates:
- Human-readable summaries
- Impact explanations
Alerting & Storage
- Summaries emailed to stakeholders
- Both raw and summarized anomalies stored in BigQuery
Challenges we ran into
Balancing sensitivity vs noise
Too many alerts reduce trust; too few miss real issues. We had to carefully tune thresholds and ML confidence levels.Real-time processing at minute granularity
Ensuring Dataflow jobs completed consistently within tight SLAs was challenging.Handling streaming edge cases
Late-arriving events, partial windows, and temporary vendor outages required careful windowing logic.Designing meaningful AI summaries
Turning raw anomaly metrics into concise, actionable insights using Gemini required prompt engineering and iteration.Schema and scale evolution
Ensuring the system remained resilient as vendors, schemas, and data volume evolved.
Accomplishments that we're proud of
- 🚀 End-to-end real-time data quality defence system
- 🧠 Successfully combined ML + rules + LLMs
- 📊 Built a live operational dashboard for anomalies
- ✉️ Delivered AI-generated alert summaries, not just raw metrics
- 🔁 Designed a system that learns from historical behaviour, not static thresholds
What we learned
- Data quality issues are often temporal, not static
- ML models perform best when paired with domain-driven rules
- Streaming systems demand observability at the data level, not just infrastructure
- LLMs like Gemini are powerful for contextualizing technical signals into business-friendly insights
- Designing for trust in alerts is as important as detection accuracy
What's next for DriftShield AI
- 🔮 Predictive drift detection before anomalies fully manifest
- 📈 Adaptive thresholds that self-tune over time
- 🔍 Column-level root cause analysis
- 🧩 Schema drift and data type change detection
- 🧠 Feedback loop where user actions improve the model
- 🌍 Multi-pipeline and cross-dataset correlation

Log in or sign up for Devpost to join the conversation.