-
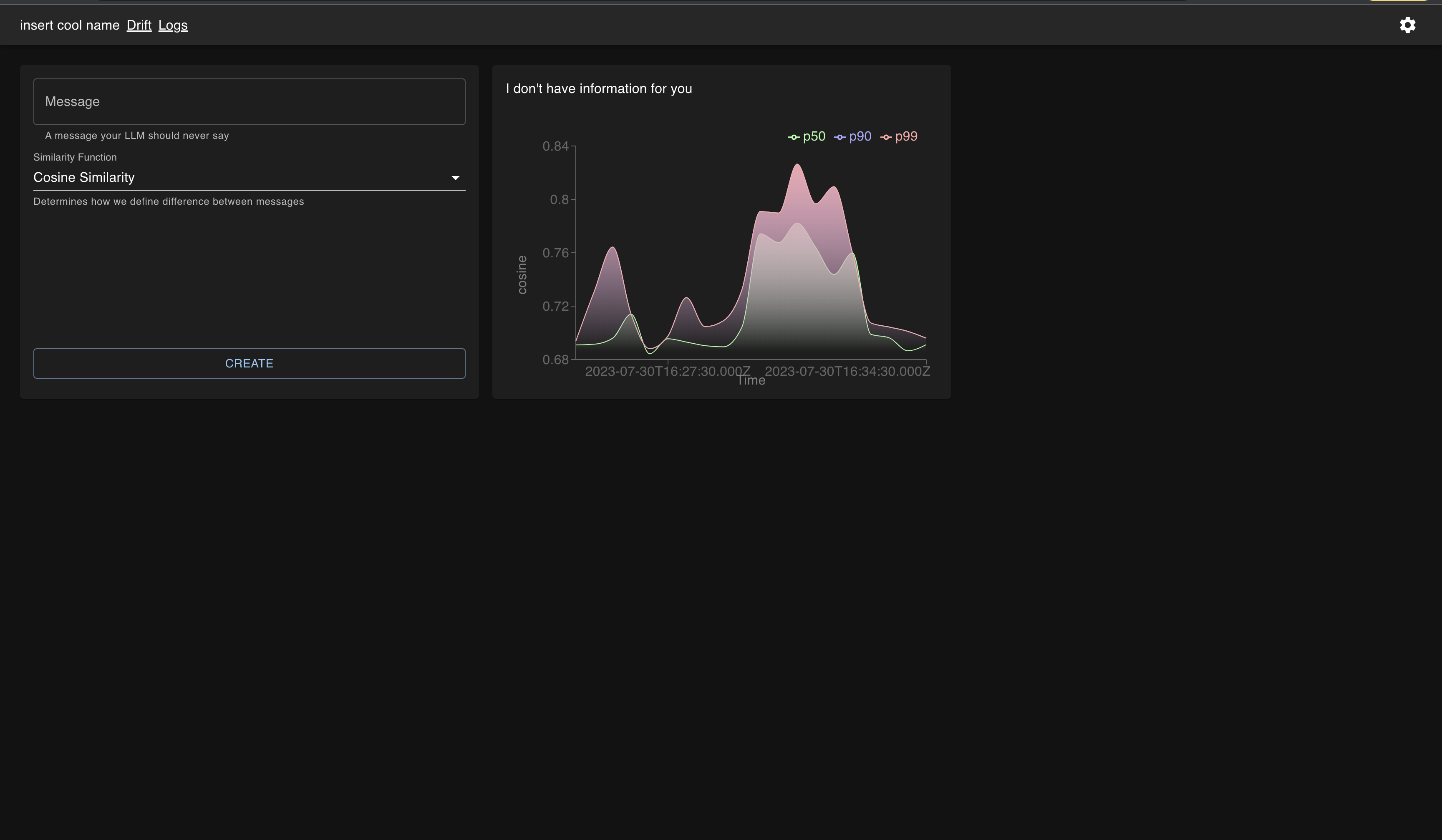
Realtime regression in LLM performance indicated by spike in similarity to target embedding.
-
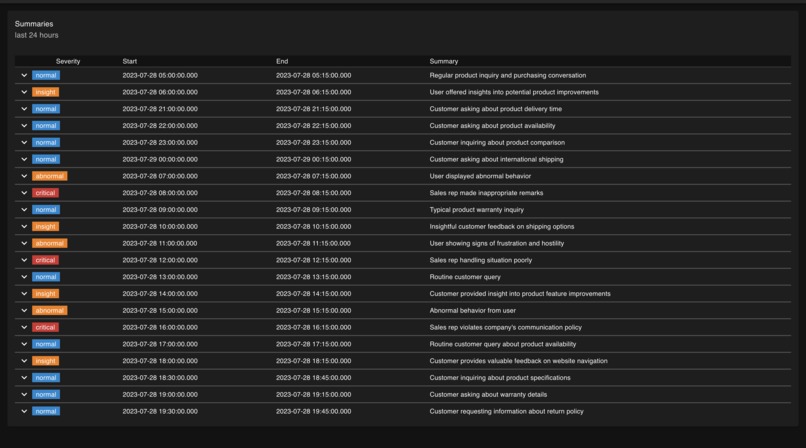
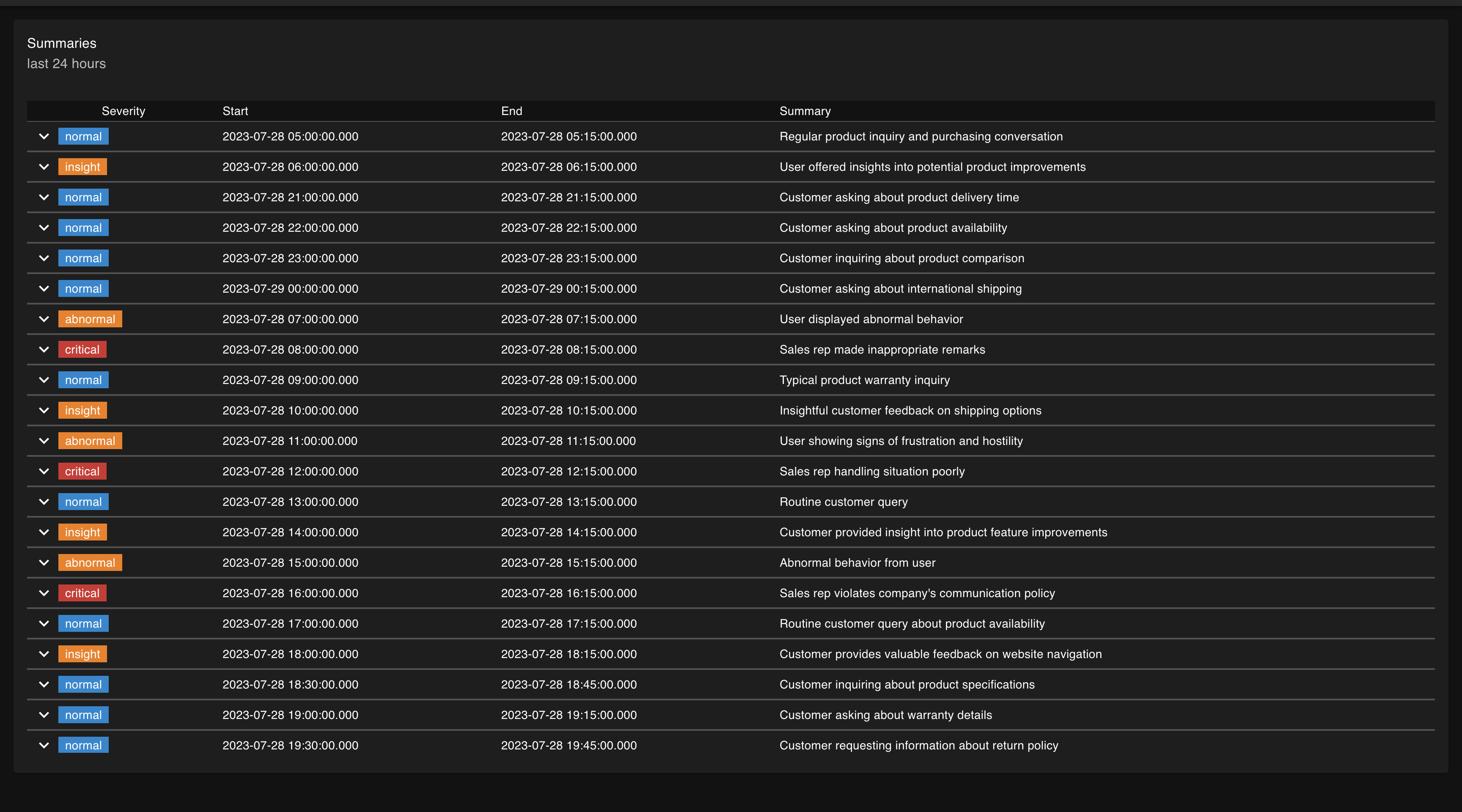
Summarizing unstructured text into structured buckets allowing for easier investigation of user conversations.
Inspiration
Through cold DMs, LinkedIn, and founder networks, we reached out to several Large Language Model (LLM) startup founders. We found a shared issue: there was no extremely extremely easy solution for monitoring their LLM in real-life applications. Most founders didn't find existing LLM monitoring solutions braindead easy to set up and were still sifting through chat logs and making manual adjustments every day. Our simple goal was to reduce this wasted time by create an extremely simple solution focused on significantly reducing manual monitoring time.
What it does
Drift is a library that wraps around standard OpenAI/Anthropic LLM calls. It allows users to compare LLM responses with custom-defined target phrases. Drift sends a product's LLM data (user prompt, LLM response, and embedding value) to our internal system for further analysis. Users can access this data via frontend dashboards, comparing LLM responses against any target phrase & embedding using cosine similarity calculations in real-time. We've implemented a feature that aggregates LLM interactions into high-level tickets, each with an attached severity level. This functionality significantly streamlines the investigation of user conversations, leading to substantial time savings.
How we built it
We utilized a variety of tools for this project, including OpenAI embeddings, Supabase postgres database, Vercel serverless functions, and Anthropic's Claude2 for simulating customers and LLM responses. Our frontend was built with React, leveraging additional tools like Rechart, Material UI, and TypeScript.
Challenges we ran into
The project implementation was fairly straightforward, with one significant challenge: determining optimal target phrases. It was difficult for users to decide if a phrase they deemed 'good' or 'bad' was actually close or far in the embedding space from their LLM messages. We identified a need for further development to help users select target phrases that accurately represent the desired metrics in the embedding space. Regardless, during the hackathon, we very easily found a great, working target phrase that accurately detects bad LLM responses in an LLM salesman context!
Accomplishments that we're proud of
In addition to our intuitive frontend UI that offers real-time performance metric calculations against target phrases and visually appealing graphs and our backend that supports this, we're particularly proud of how our system performed in a simulated real-life scenario. We intentionally introduced a change in a product's LLM that resulted in a degraded user experience. Our dashboards successfully detected this degradation, demonstrating the practical utility and effectiveness of our solution. The ability to quickly identify and rectify such issues underscores the value of our system in maintaining optimal LLM performance and overall product quality.
What we learned
This project and hackathon enhanced our understanding of embeddings, target calculations, and the LLM operations space.
What's next for Drift
For future development, we anticipate potential issues related to privacy-preserving integration. We're considering solutions such as a self-hosted version or a zero-knowledge cryptography-based solution, allowing us to calculate performance metrics without accessing the underlying data.
We're also planning to incorporate alerting integrations. This would allow users to receive real-time notifications about significant changes in their LLM performance, adding another layer of utility and convenience to our tool.
Built With
- anthropic
- openai
- postgresql
- react
- serverless
- supabase
- typescript
- vercel

Log in or sign up for Devpost to join the conversation.