Inspiration
Both the founders are uncles and looking for gifts for our nephews and nieces.
Bedtime stories are one of the most intimate rituals between a parent and child — but life gets in the way. Late nights at work, travel, exhaustion. The guilt of saying "not tonight" is real.
I wanted to build something that never replaces that bond, but extends it. What if a parent could record their voice once, and their child could hear them — warm, present, reading a story — even when they're not in the room?
The deeper inspiration came from watching my own niece fall asleep to the same three picture books, night after night, because her parents were too tired to improvise. Children deserve infinite stories — ones that know their name, their favourite characters, their age, their language. That's the gap Dreamtales fills.
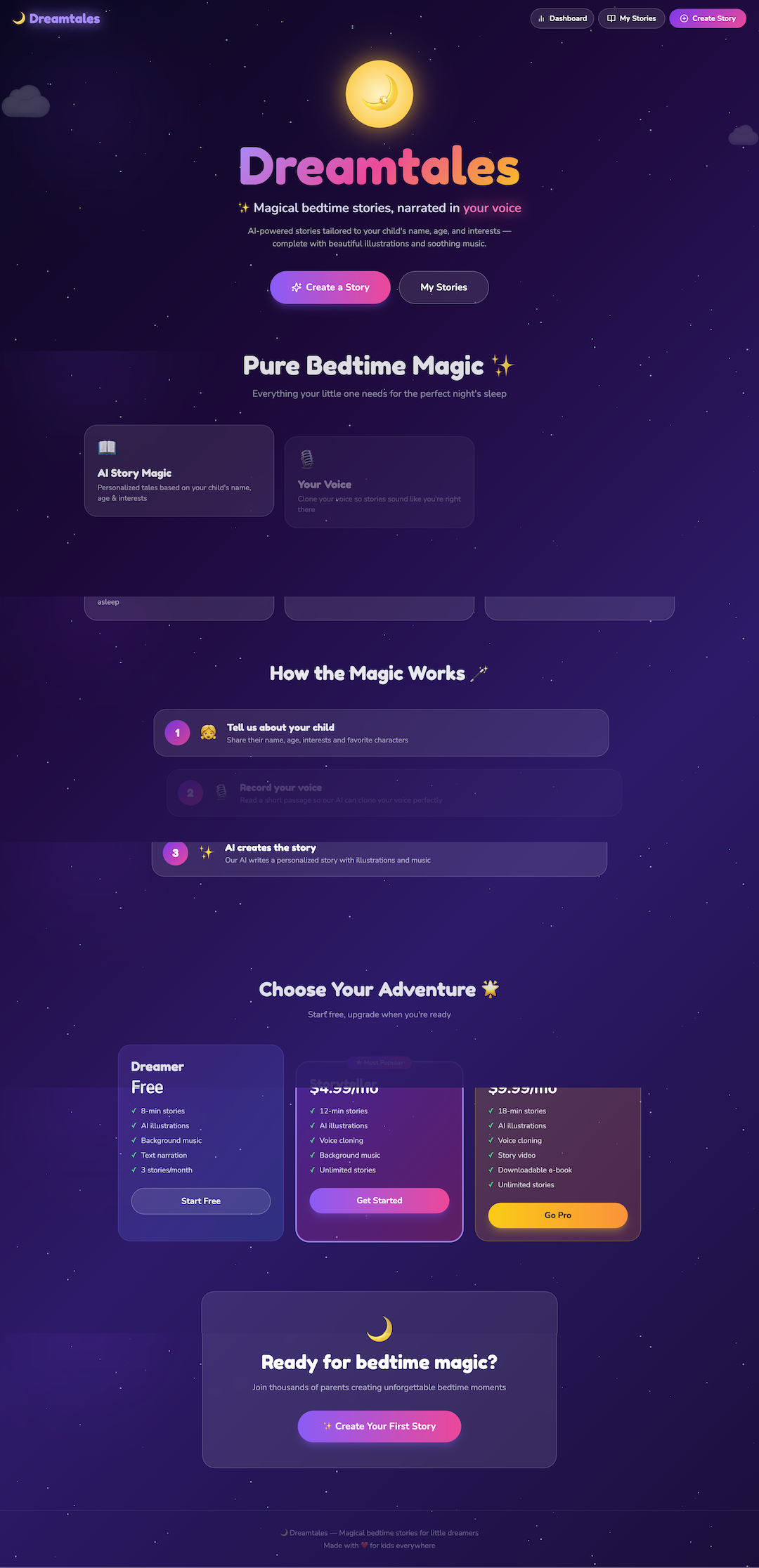
What it does
Dreamtales is a full-stack AI bedtime story platform with five core pillars:
Personalized Story Generation Parents configure a 5-step wizard — child profile, interests, story theme, voice casting, and extras. A single prompt to qwen3-235b-instruct (via Eigen AI's 256K-context endpoint) generates a complete multi-scene story with structured JSON output including dialogue, image prompts, scene mood descriptors, and interactive branching choices.
Voice Cloning & Multi-Character TTS Using Eigen AI's chatterbox model, parents record ~30 seconds of their voice. That recording becomes the narrator's voice — cloned and used to read every scene. Other characters (Child Hero, Companion, Wise Elder) are assigned celebrity-style AI voices (Morgan Freeman, David Attenborough, etc.) rendered with descriptive scene_prompt style strings. Each character's dialogue segment is generated separately, then WAV buffers are concatenated in pure Node.js — no ffmpeg required.
AI Scene Illustrations Every scene gets a unique 1024×1024 illustration via DALL·E 3, styled by the parent's chosen animation style — Watercolor, Anime, Pixar 3D, Oil Painting, Storybook, and more.
Cinematic Story Player A full-screen immersive player with Ken Burns parallax on images, synchronized narration, background music, ambient soundscapes, sleep timer, scene bookmarks, speed control, bilingual text overlay, and auto-play. Stories stream scene-by-scene via SSE so the first scene plays while the rest are still generating.
Interactive Branching At story end, children pick from two choices ("Follow the dragon!" / "Find the hidden door!") and the AI generates 4 new branch scenes on the fly — creating infinite replayability.
How we built it
We built it using Claude Code
Challenges we ran into
JSON Reliability at Scale Getting a 256K-context model to output valid, escaped JSON with 108 scenes is harder than it sounds. Inline TTS expressiveness tags like and inside JSON strings constantly broke the parser. The fix was a multi-pass extractJSON function that strips reasoning blocks, handles partial truncation by scanning from the last } backwards, and falls back gracefully without crashing generation.
WAV Concatenation Without ffmpeg Serverless and containerized environments often lack native binaries. I implemented pure-JS WAV binary manipulation — walking RIFF chunk headers, extracting PCM data, concatenating buffers, and rewriting size fields — so multi-voice audio merges with zero native dependencies.
SSE Streaming + Race Conditions Scenes generate in parallel (images + audio simultaneously, 2 at a time). The SSE stream had to handle out-of-order completions gracefully and maintain scene index integrity while the frontend began playback of scene 1 before scene 16 was even started.
Voice Preview UX Users needed to hear a voice before committing it to a character. Generating previews on-demand via the TTS API takes ~10–30 seconds. The solution: a disk-based cache at uploads/voice_previews/preview_{voiceId}.wav — first click generates and caches, every subsequent click serves instantly from disk.
Pacing for Sleepy Kids Getting AI narration to feel cozy rather than clinical was a subtle prompt engineering challenge. The breakthrough was adding explicit bedtime pacing instructions — short sentences, ellipsis pauses (…), direct address ("Can you imagine that?"), and sensory grounding ("warm light," "soft grass") — alongside inline TTS tags that signal the model to whisper or slow down at the right moments.
Accomplishments that we're proud of
What we learned
Streaming UX transforms perceived performance. Showing scene 1 while generating scene 108 makes a 3-minute wait feel instant. Binary protocols are not scary. Parsing WAV RIFF headers in pure JavaScript is ~50 lines and eliminates an entire class of deployment dependencies. Prompt structure matters more than model size. Explicit JSON schema examples in the system prompt reduced parse failures by ~80% compared to free-form instructions. Voice is deeply emotional. Even an AI approximation of a parent's voice, playing a personalised story, is surprisingly moving. That's the product insight at the heart of Dreamtales.
What's next for Dreamtales AI
Real-time video generation — animated story scenes, not just static images Offline mode — download stories for aeroplanes and camping trips Sibling profiles — one family, multiple children, each with their own story history Educator mode — teachers generate classroom stories tied to curriculum themes
Built With
- claude
- claudecode

Log in or sign up for Devpost to join the conversation.