Project Detailed: DreamOps
DreamOps: Your AI-Powered On-Call Hero
💡 Inspiration
On-call engineering is a relentless, exhausting ordeal. Engineers are constantly interrupted, suffer from severe sleep deprivation, and battle alert fatigue while managing production incidents 24/7. The current incident response paradigm is heavily reliant on manual intervention:
- Waking up at 3 AM to critical alerts.
- Manually sifting through logs across disparate systems (Kubernetes, Grafana, custom logs).
- Diagnosing complex issues under immense pressure.
- Executing remediation steps, often repetitive and prone to human error.
This leads to burnout, inconsistent response quality, and prolonged downtime, directly impacting business continuity and team morale. We were inspired to build DreamOps to fundamentally transform this broken system, giving engineers their sleep and peace of mind back.
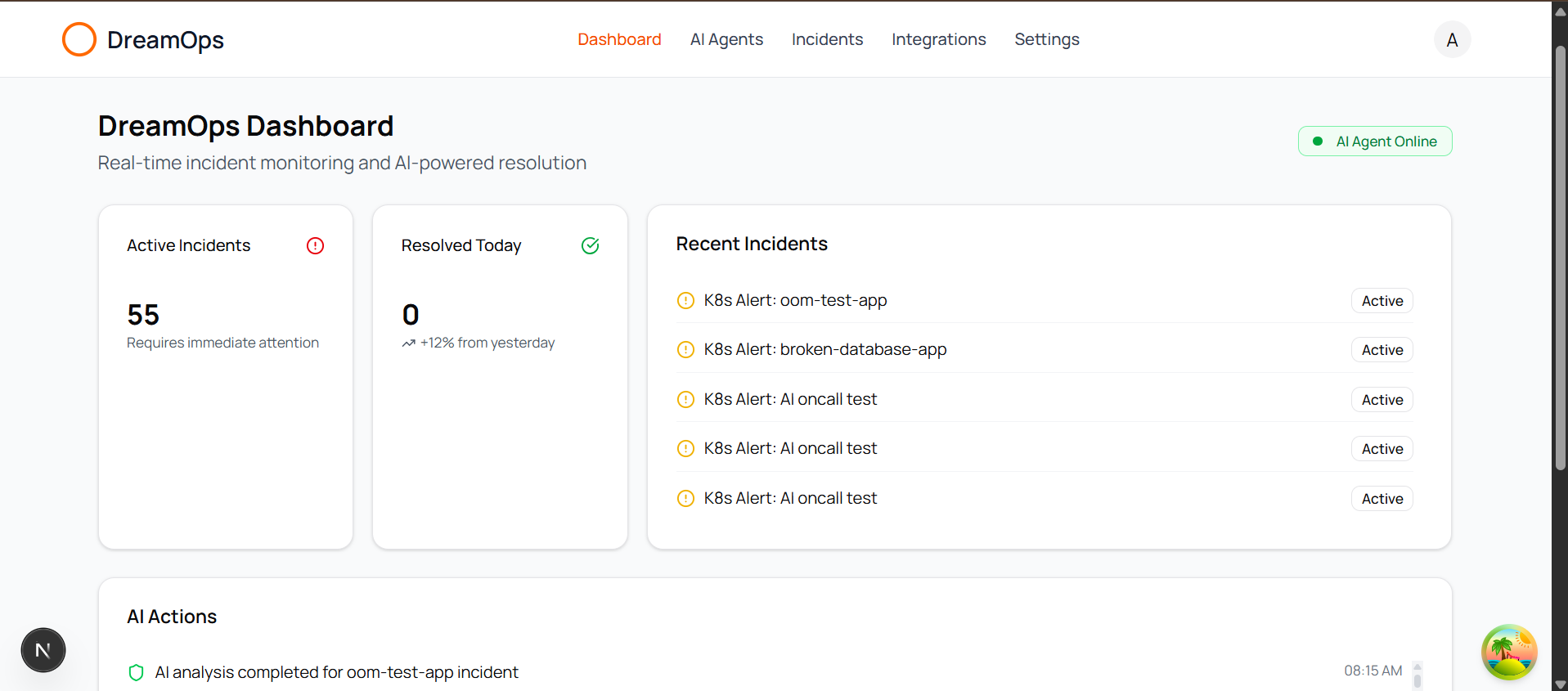
🚀 What it does
DreamOps is an intelligent AI-powered incident response and infrastructure management platform that aims to automate the entire incident lifecycle, from detection to resolution. It acts as an "AI agent" that intelligently triages, analyzes, and resolves common production incidents without human intervention, ensuring engineers can actually rest.
Core Capabilities:
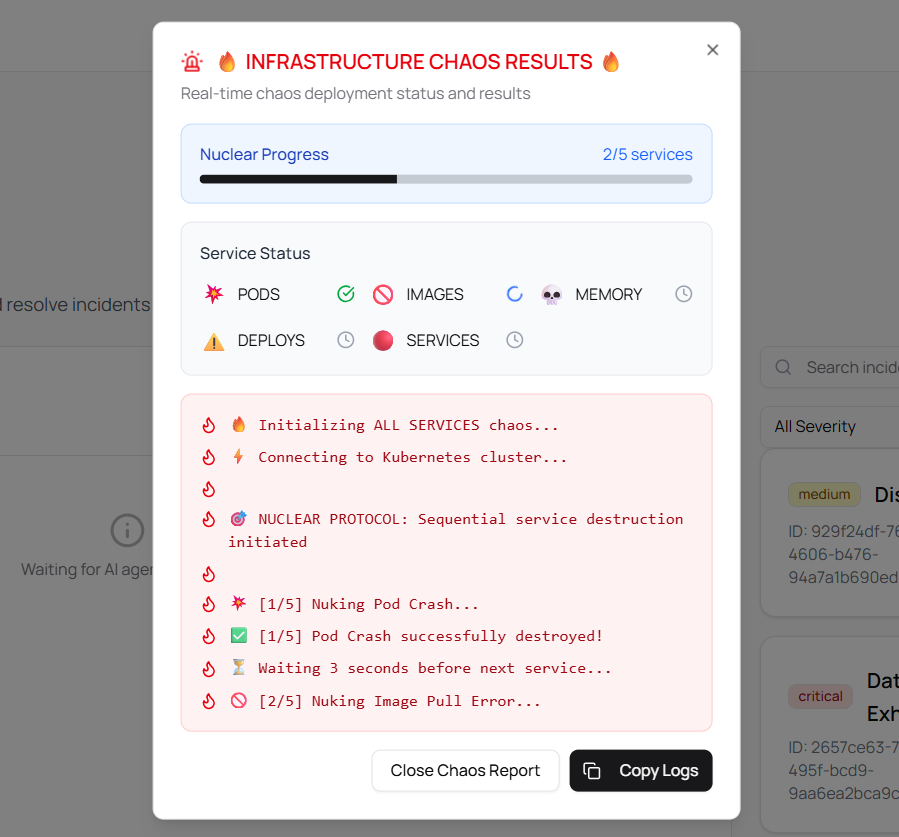
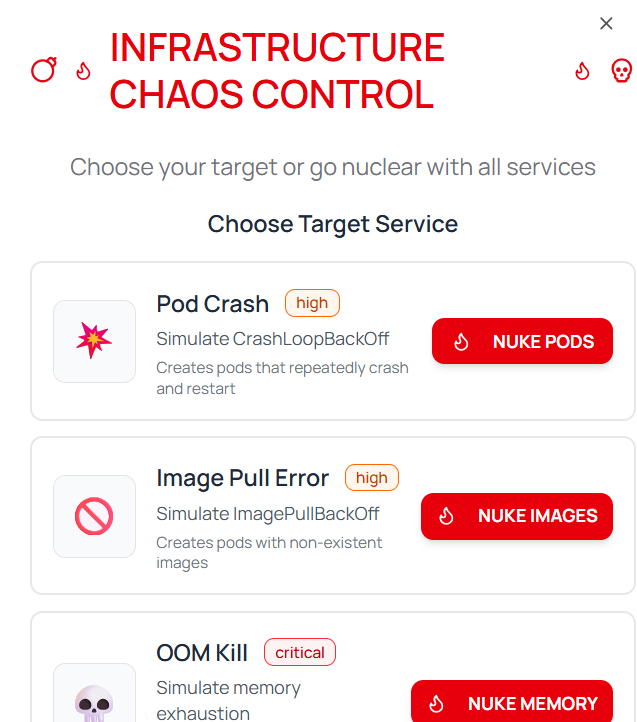
- Automated Incident Response: Automatically triages and resolves common incidents like pod crashes, Out-of-Memory (OOM) kills, and configuration issues, reducing the need for manual intervention.
- Intelligent Root Cause Analysis (RCA): Leverages Claude AI to perform deep analysis of alerts by integrating full context from Kubernetes, logs, metrics (Grafana), documentation (Notion), and codebase (GitHub).
- Reduced MTTR (Mean Time To Resolution): What typically takes 30-60 minutes of manual debugging can be resolved in 2-5 minutes automatically.
- Context-Aware Decisions: Integrates with your specific infrastructure and runbooks to make informed, context-rich remediation decisions.
- Sleep Protection: Handles routine incidents autonomously, escalating only the most complex, novel issues to on-call engineers.
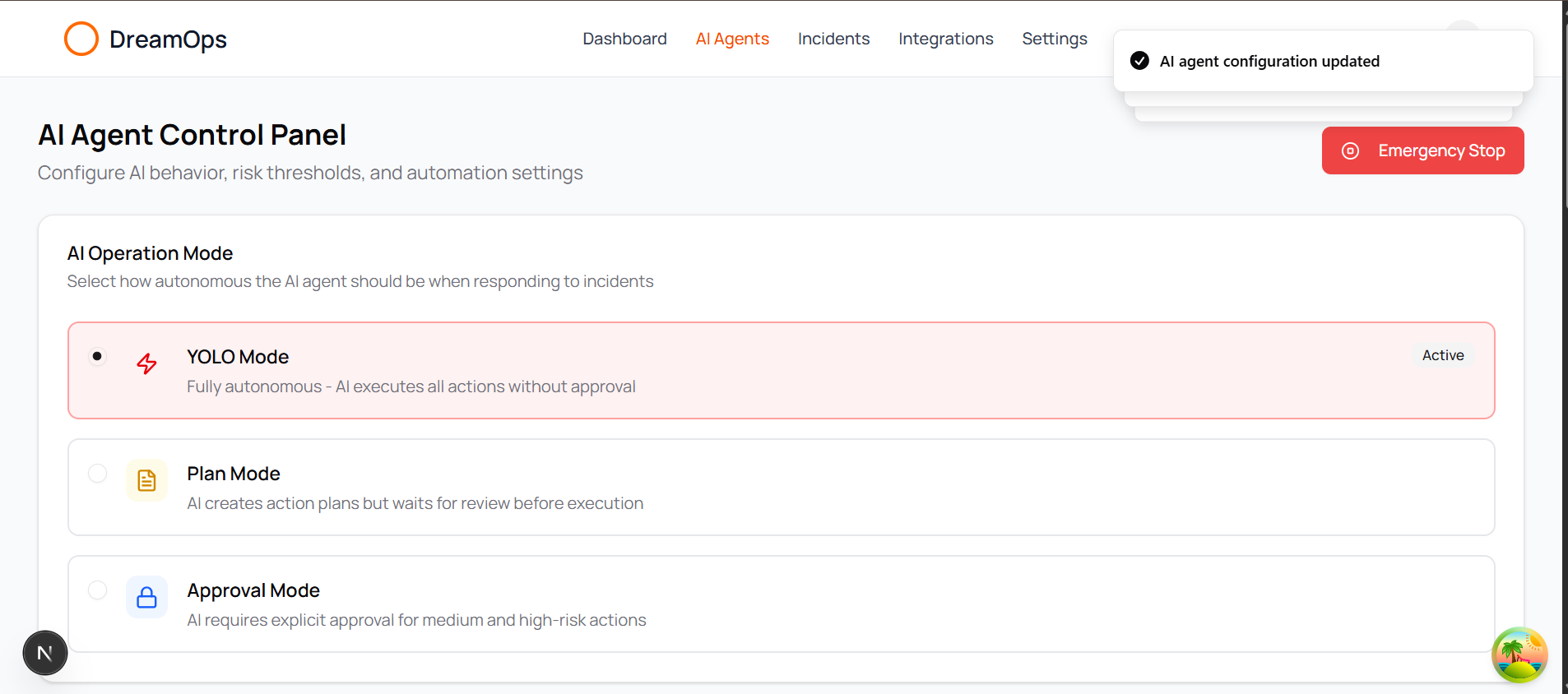
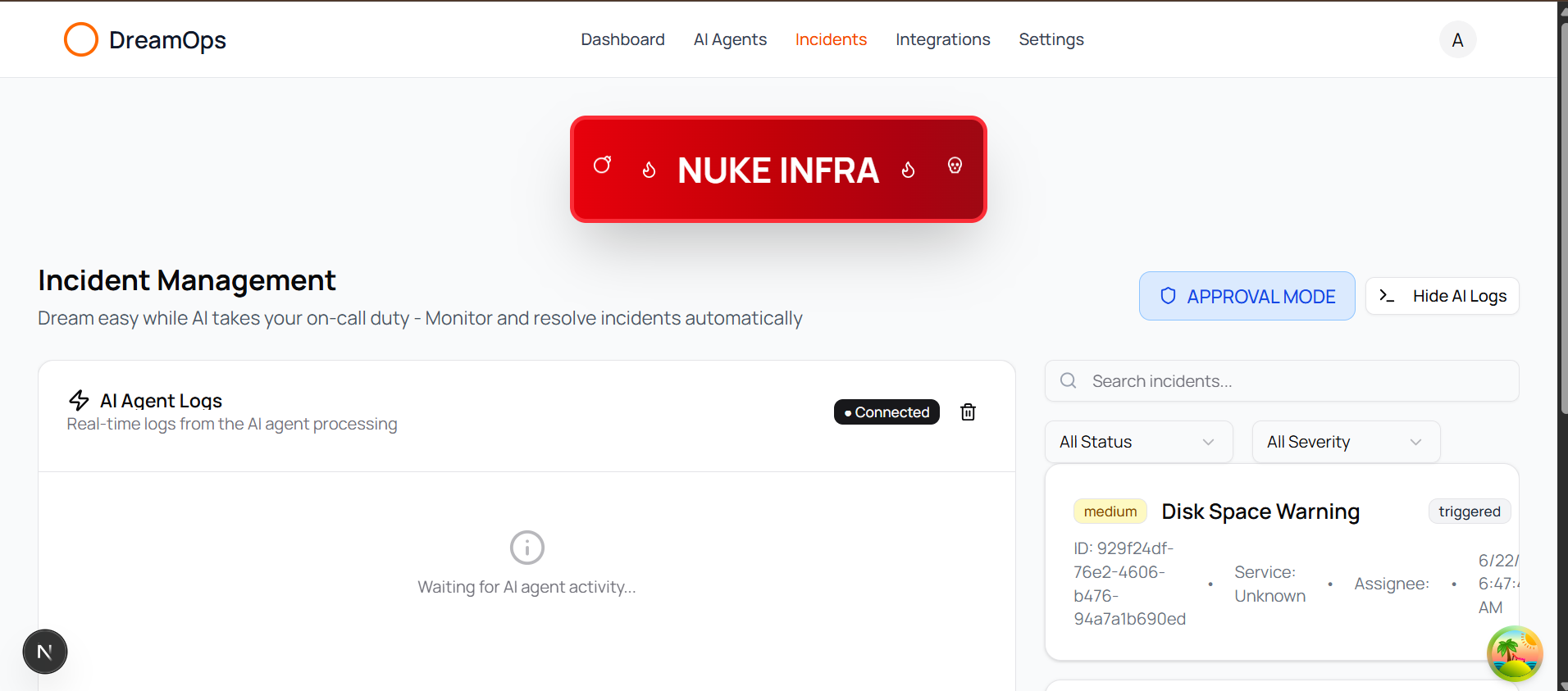
- Confidence-Based Automation (YOLO Mode): Dynamically executes remediation steps based on AI confidence scores (e.g., auto-executes with ≥0.8 confidence) rather than rigid, rule-based systems, ensuring safety and effectiveness.
- Unified AI Brain: Unlike existing solutions that address only specific parts (alerting, runbook automation, correlation), DreamOps provides a single, cohesive AI agent for end-to-end incident management.
Real-World Impact:
- Saves 2-4 hours per on-call shift, freeing up valuable engineering time.
- Reduces incident resolution time by 80% for common issues.
- Prevents engineer burnout from repetitive, late-night tasks.
- Maintains consistent remediation quality, even at 3 AM.
🛠️ How we built it
DreamOps is built on a robust, extensible architecture designed for real-time performance and deep contextual understanding.
Key Technologies & Architecture:
- AI Core: Powered by Claude AI for intelligent analysis, root cause identification, and remediation command generation.
- Backend: Developed in Python using FastAPI for a high-performance REST API with automatic documentation.
- Frontend: A modern Next.js web interface with real-time dashboard capabilities via WebSocket support.
- Model Context Protocol (MCP) Architecture: A foundational decision to build an extensible integration system. We created a
MCPIntegrationbase class to standardize communication with various "MCP servers" (e.g.,kubernetes-mcp-server,grafana-mcp-server,github-mcp-server,notion-mcp-server). This allows for comprehensive context gathering and action execution across diverse tools. - Asynchronous Processing: Implemented async processing with immediate webhook acknowledgment for real-time alert sources (like PagerDuty), allowing background analysis without blocking the main thread.
- Deployment: Containerized with Docker and deployed on AWS using Terraform. Our infrastructure leverages ECS Fargate for the backend, S3 + CloudFront for frontend hosting, ECR for image storage, and CloudWatch for monitoring and alarms. We also set up EKS clusters for robust testing.
- Safety Mechanisms: Incorporated a comprehensive risk assessment system for Kubernetes commands, categorizing them (low/medium/high risk) and enabling "YOLO mode" (autonomous execution) only with high confidence scores and for lower-risk operations. "Approval Mode" and "Plan Mode" provide additional safety layers.
- Testing Infrastructure: Developed
fuck_kubernetes.sh, a custom script to simulate various failure modes (CrashLoopBackOff, OOMKills, etc.) in isolated Kubernetes namespaces, enabling realistic testing. - CI/CD: Utilized GitHub Actions for automated deployment workflows.
🚧 Challenges we ran into
Building an autonomous incident response system presented several significant hurdles:
MCP Integration Complexity:
- Problem: Integrating multiple Model Context Protocol servers (Kubernetes, GitHub, Grafana) proved challenging due to differing authentication methods and response formats for each.
- Solution: We designed and built a robust abstraction layer, epitomized by a unified
MCPIntegrationbase class, to normalize interactions.
Safety vs. Automation Balance (YOLO Mode):
- Problem: Implementing "YOLO mode," which allows automatic execution of
kubectlcommands, carried inherent risks, as destructive operations could lead to outages. - Solution: We developed a sophisticated risk assessment system that categorizes commands (low/medium/high risk) and only auto-executes them when coupled with a high AI confidence score (≥0.8), along with user-configurable approval and plan modes.
- Problem: Implementing "YOLO mode," which allows automatic execution of
Real-time Webhook Processing:
- Problem: PagerDuty webhooks required sub-second acknowledgment, but Claude API calls for analysis typically take 2-4 seconds, creating a potential bottleneck.
- Solution: We implemented an asynchronous processing architecture with immediate webhook acknowledgment and moved the time-consuming AI analysis into a background process.
Context Window Management:
- Problem: With multiple integrations providing rich data (logs, metrics, code, docs), we frequently hit Claude's token limits for context during analysis.
- Solution: We developed intelligent context prioritization strategies, fetching and providing only the most relevant logs and metrics based on the specific alert type and incident context, to stay within token limits without sacrificing detail.
Testing Kubernetes Failures:
- Problem: Creating realistic and repeatable test scenarios for various Kubernetes failure modes was challenging, as real-world incidents are complex and difficult to replicate.
- Solution: We built the custom
fuck_kubernetes.shscript, which systematically simulates a wide range of failure modes (CrashLoopBackOff, OOMKills, etc.) in isolated namespaces, allowing for robust and controlled testing of the agent's response.
✨ Accomplishments that we're proud of
We are incredibly proud of the significant progress and innovations achieved with DreamOps:
- Pioneering MCP Integration: Being one of the first solutions to fully leverage Anthropic's Model Context Protocol (MCP) for comprehensive context gathering across diverse systems.
- Confidence-Based Autonomous Remediation: Successfully implementing "YOLO Mode" with a robust risk assessment system, demonstrating the feasibility of safe, AI-driven auto-remediation in production environments.
- Tangible Time Savings: Delivering a solution capable of saving 2-4 hours per on-call shift and reducing incident resolution time by 80% for common issues.
- Preventing Burnout: Creating a tool that directly addresses a major pain point for engineers by automating repetitive tasks and protecting their sleep.
- Unified AI Brain: Integrating alert processing, analysis, and remediation into one cohesive AI agent, providing an end-to-end solution that existing products lack.
- Developer-First Design: Building a system that works out-of-the-box with standard Kubernetes setups and is designed for startups and small teams, unlike complex enterprise-focused AIOps platforms.
- Robust Test Infrastructure: Developing the
fuck_kubernetes.shscript, a crucial tool that allowed us to thoroughly test and validate the agent's behavior against realistic failure scenarios. - Resolving Complex Conflicts: Successfully resolving extensive merge conflicts across critical configuration and code files, ensuring a clean, functional, and production-ready codebase.
- Comprehensive API: Developing a rich FastAPI backend with a wide array of endpoints for incident management, dashboard analytics, AI agent control, integrations, security, monitoring, and settings.
📚 What we learned
Through the development of DreamOps, we gained invaluable insights:
- The Power of Abstraction: Building a robust abstraction layer (like
MCPIntegration) is crucial when dealing with heterogeneous external systems, simplifying complex integrations. - Balancing Autonomy and Safety: Implementing AI-driven automation in production environments requires a meticulous approach to safety, involving clear risk assessments, confidence thresholds, and human-in-the-loop options.
- Asynchronous Design is Key: For real-time, event-driven systems interacting with slow external APIs (like LLMs), an asynchronous architecture is indispensable for maintaining responsiveness and performance.
- Context is King for LLMs: Effectively managing and prioritizing context for large language models within token limits is vital for accurate and relevant analysis. Trimming irrelevant data is as important as providing relevant data.
- Creative Testing is Essential: Traditional unit and integration tests are not enough for complex, reactive systems. Simulating real-world failure modes (e.g., with
fuck_kubernetes.sh) is critical for validating system resilience. - Impact of Collaboration & Conflict Resolution: Learning to navigate and systematically resolve complex merge conflicts is a vital skill in collaborative development, ensuring project continuity and code stability.
- The Value of Clear Documentation: The extensive documentation for setup, configuration, usage, and troubleshooting proved invaluable for both development and potential users.
🔮 What's next for DreamOps
DreamOps has a vast potential to further revolutionize incident response. Our future plans include:
- Expanded MCP Ecosystem: Integrating with more MCP servers, such as Datadog, and expanding to cover other infrastructure components like databases (e.g., PostgreSQL MCP server) and network devices.
- Proactive Issue Prediction: Leveraging historical incident data and machine learning to predict potential outages before they occur, triggering preventative measures.
- Enhanced Self-Healing Capabilities: Expanding autonomous remediation beyond Kubernetes to other infrastructure types and more complex, multi-service incidents.
- Advanced Root Cause Correlation: Further improving AI's ability to correlate seemingly disparate events across systems to pinpoint the true root cause faster.
- Interactive AI Agent: Implementing more sophisticated conversational interfaces (e.g., via Slack or Discord MCP servers) for engineers to query the AI, ask for analysis, or approve actions directly.
- Custom Runbook Integration: Allowing users to define custom, AI-executable runbooks based on their specific operational procedures.
- Learning & Adaptation: Implementing feedback loops where engineers can provide input on AI-generated remediations, allowing the AI to continuously learn and improve its accuracy over time.
- Comprehensive Audit & Compliance: Building out more robust audit trails, compliance reporting, and security features for enterprise adoption.
- Community and Open Source: Exploring opportunities to open-source parts of the MCP integration layer or contribute back to the broader MCP ecosystem.
Built With
- agents
- amazon-web-services
- api
- css
- html
- mcp
- nextjs
- node.js
- python
- slack
- websockets

Log in or sign up for Devpost to join the conversation.