-
-

3D Gaussian splatting scene, demonstrating web-based world visualization as part of an AI-native cinematic production pipeline.
-
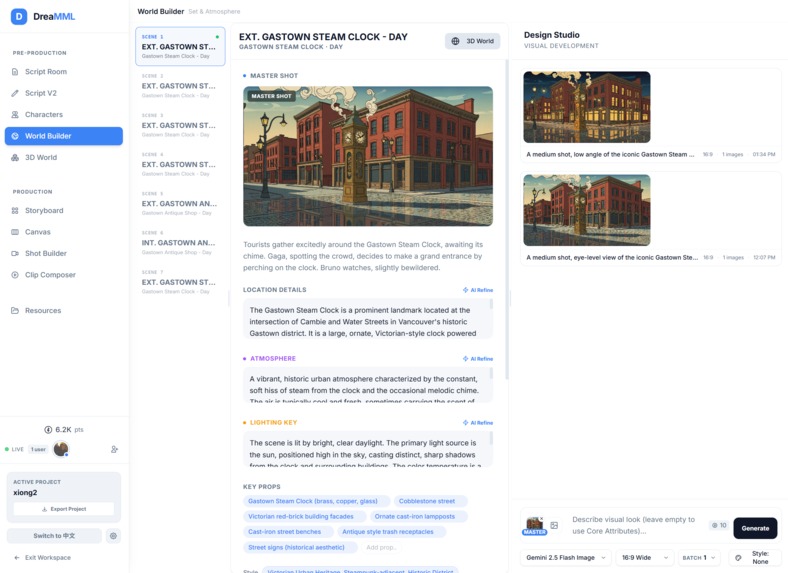
Inside DreamML’s creative workspace — AI-driven reference generation and scene exploration.
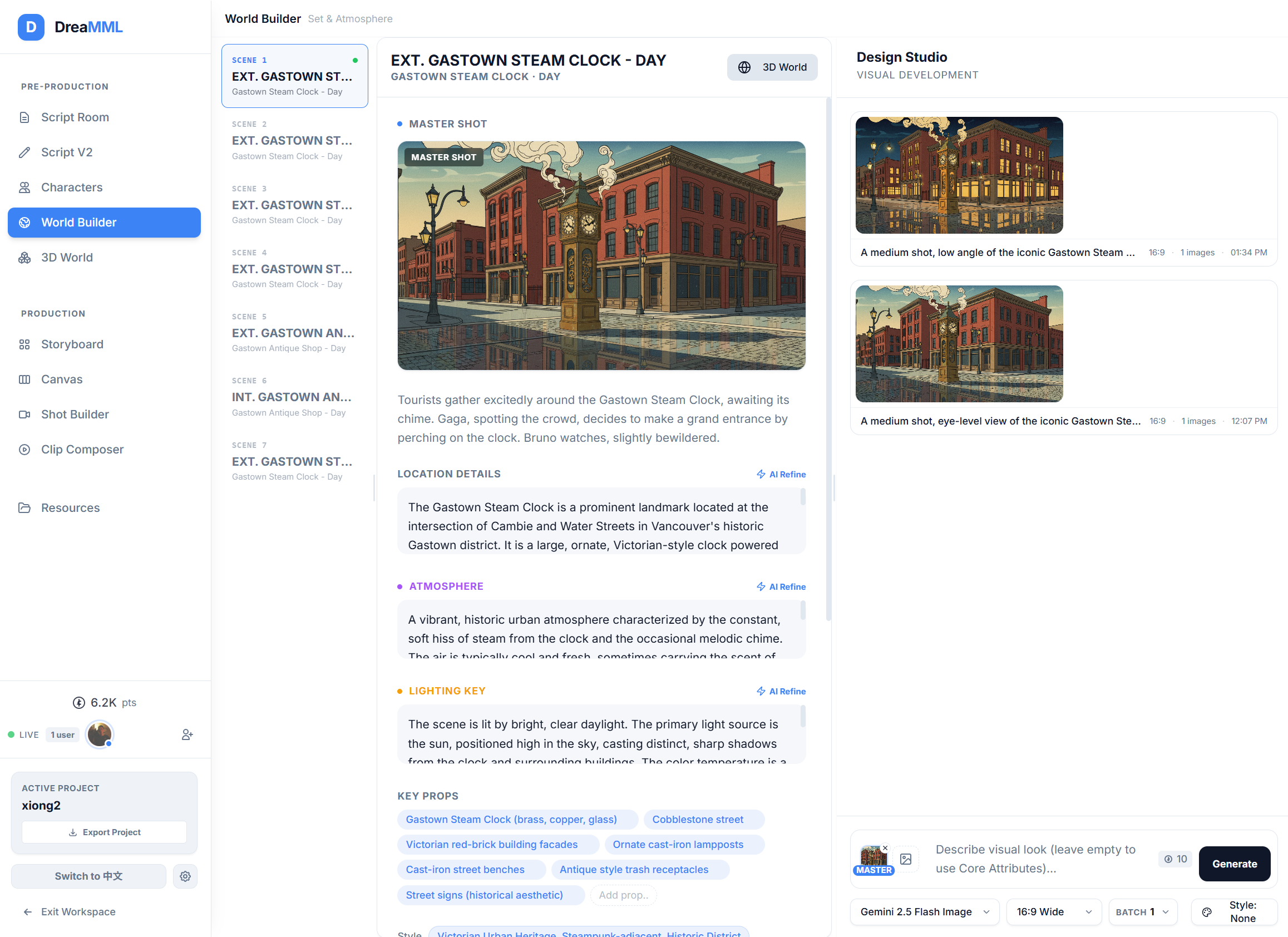
DreaMML — AI-Native “full pipeline” Cinematic Production Platform
Turn a story idea into a cinematic video — from screenplay to characters, worlds, and final shots — powered by Google Gemini, Veo, NanoBanana, and world models from World Labs.
Inspiration
Creating cinematic content has traditionally required large teams, specialized expertise, and significant production time. While recent advances in generative AI have made it easier to produce images and short videos, the filmmaking workflow itself remains fragmented. Creators still move between disconnected tools to write scripts, design characters, visualize scenes, and assemble footage.
We saw an opportunity to rethink this process.
Instead of treating AI as a collection of isolated generators, we asked:
What would filmmaking look like if AI supported the entire creative pipeline?
DreaMML began as an exploration of that question — connecting multimodal models into a cohesive system that helps creators move from concept to cinematic output with far less friction.
Recent progress in world models also made spatially-aware storytelling workflows newly possible, allowing scenes to be explored rather than merely generated.
What it does
DreaMML is an AI filmmaking workspace designed to support major stages of production within a single environment.
Creators can:
- Write screenplays with real-time AI assistance
- Generate structured character profiles and concept art
- Build visually consistent scenes
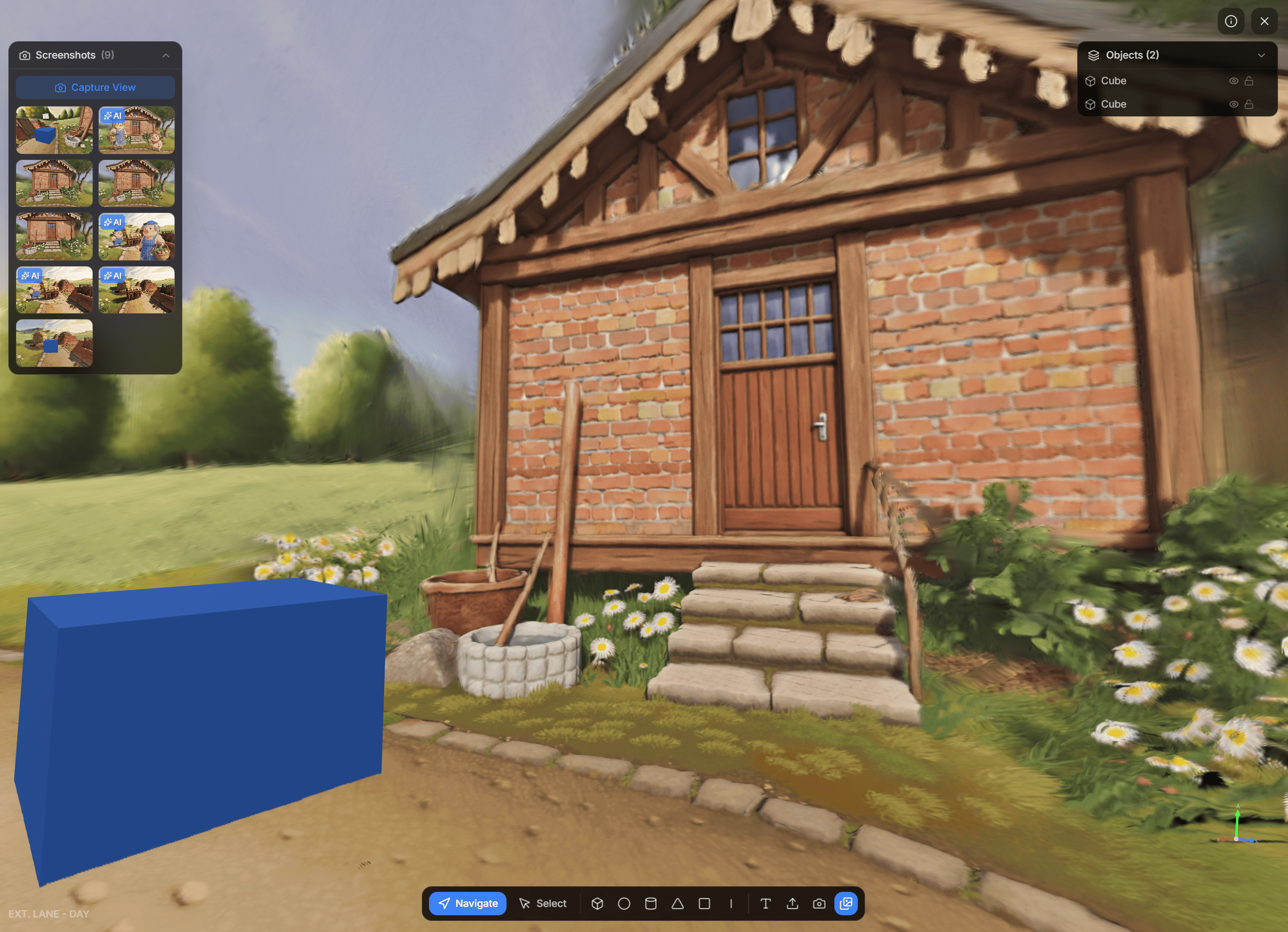
- Generate navigable 3D environments using world models from World Labs
- Compose cinematic shots using keyframe-guided video generation
- Assemble sequences into a final timeline
Rather than repeatedly rewriting prompts, users define creative intent once and allow that context to guide downstream generation.
The goal is not to automate creativity — but to remove the operational complexity surrounding it.
How we built it
We built DreaMML by orchestrating multiple multimodal models into a coordinated production workflow.
- Gemini structures scripts, analyzes characters, and helps maintain narrative consistency
- NanoBanana produces concept art and visual references
- Veo enables cinematic video creation through keyframe-based motion
- World models from World Labs generate navigable 3D environments, allowing scenes to be explored spatially for shot planning and visual continuity
A central design priority was maintaining shared context across each generation step so that characters, environments, and visual style remain coherent.
We also shifted from open-ended prompting toward structured visual prompts, decomposing scenes into elements such as subject, composition, lighting, and spatial layers. This approach significantly improved stability during multi-shot generation.
The resulting system behaves less like a single AI tool and more like a coordinated creative workflow.
Challenges we ran into
Maintaining visual consistency Generative models are inherently probabilistic. Ensuring that a character designed during concept art appears consistent in generated video required propagating reference images and descriptive anchors throughout the pipeline.
Prompt sensitivity in video generation Small wording changes could produce drastically different cinematic results. Structured prompts helped enforce spatial depth and character constraints.
Real-time collaboration alongside AI generation Combining live multi-user editing with asynchronous AI suggestions required careful separation so that AI could assist without interrupting active creative work.
Bridging 2D and spatial workflows Connecting concept imagery to navigable 3D environments introduced technical complexity but proved important for preserving scene continuity.
Accomplishments that we're proud of
- Built a working end-to-end prototype connecting screenplay → visual design → spatial scenes → video
- Demonstrated that multimodal AI systems can function as a coordinated production workflow
- Improved generation consistency through structured prompting
- Enabled filmmakers to guide motion using keyframe intent rather than purely text-based descriptions
- Designed the platform to remain adaptable as newer models emerge
Most importantly, we validated that orchestration — not just generation — is a critical layer in AI media creation.
What we learned
AI orchestration is harder than AI integration. Calling a model is straightforward; designing a system where multiple models reinforce each other is the real challenge.
Structure unlocks creative speed. When context persists across steps, creators spend less time rewriting prompts and more time directing.
Creators want control, not automation. The strongest results came when AI acted as a collaborator rather than a replacement.
This project strengthened our belief that the future of creative tooling lies in intelligent workflows rather than standalone generators.
What's next for DreaMML
We see DreaMML as an early step toward AI-native production infrastructure.
Next directions include:
- Stronger multi-shot continuity
- Integrated audio generation
- Director-style visual controls
- Interactive 3D pre-visualization
- direct pipeline into multimodal and multisensory immersive experiences
- Faster iteration loops as model latency improves
Our long-term vision is to make cinematic storytelling dramatically more accessible — enabling small teams, and even solo creators, to produce work that once required full studios.
Try now at https://dreammlai.com/
Built With
- antigravity
- convex
- gemini
- opencut
- react
- seedance
- three.js
- typescript
- veo
- worldlabs

 Zhao")

Log in or sign up for Devpost to join the conversation.