-
-
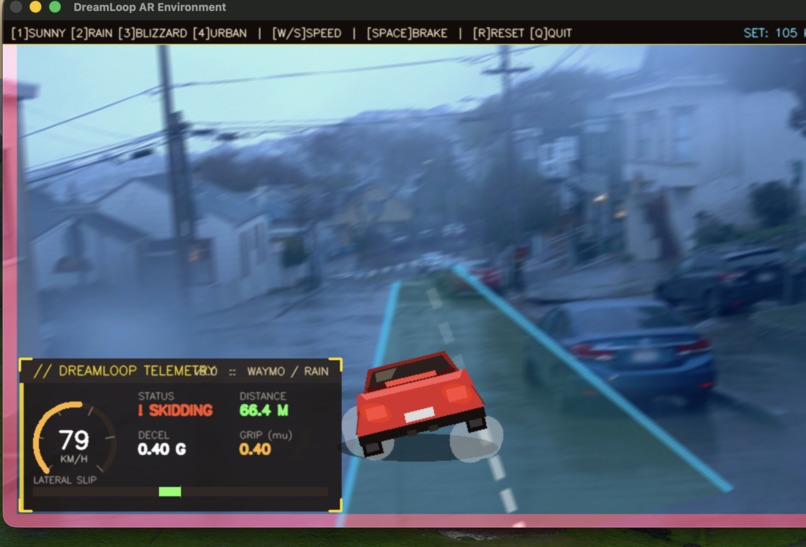
Car skidding in high speed in rainy/wet conditions
-
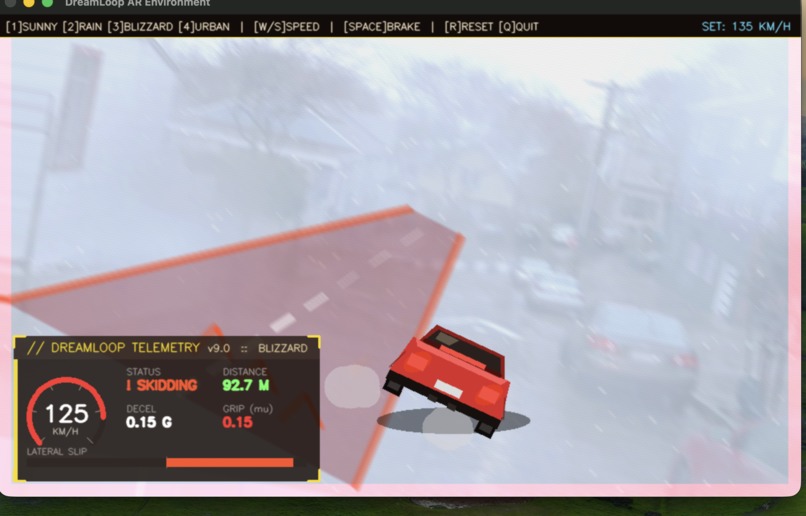
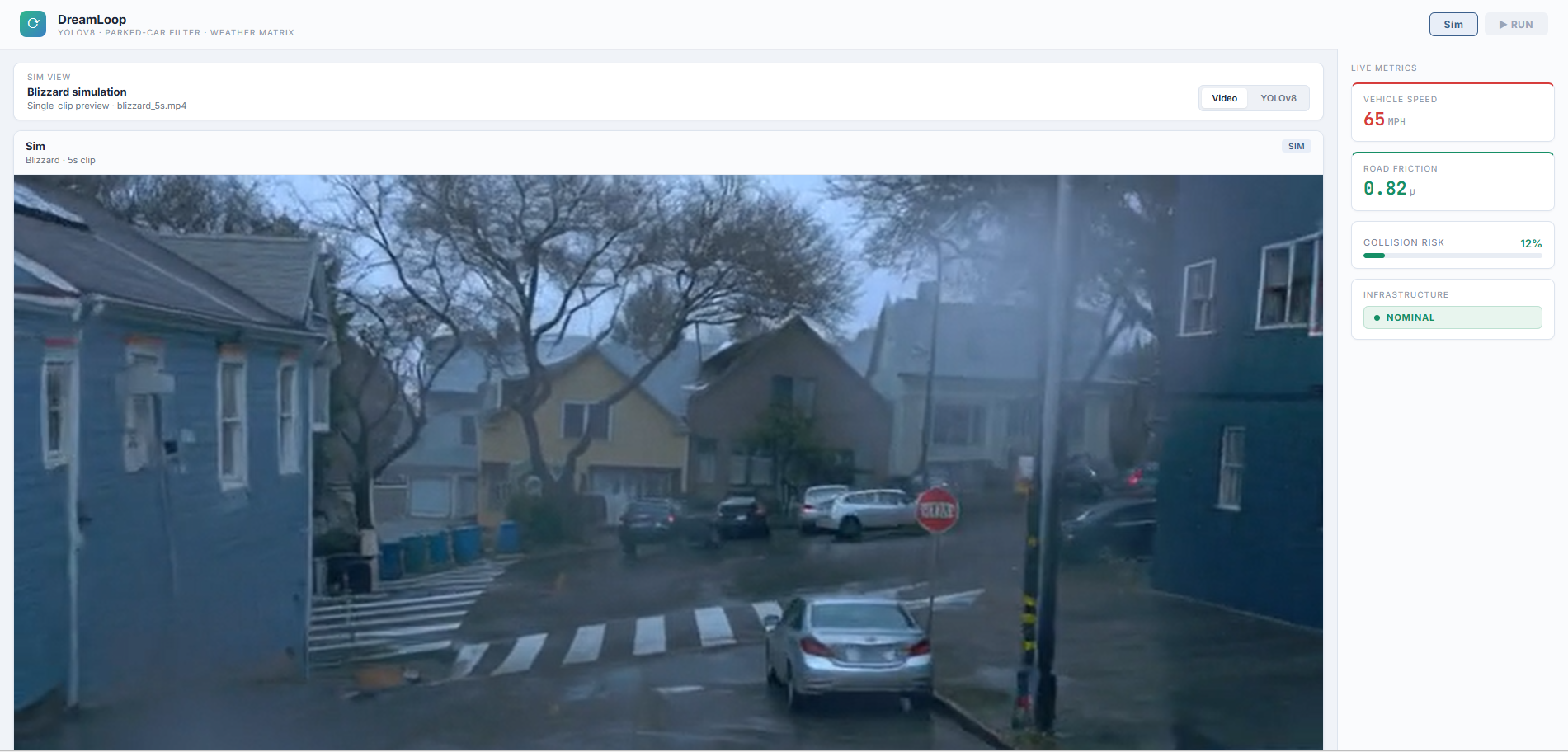
Car skidding in high speed in a blizzard
-
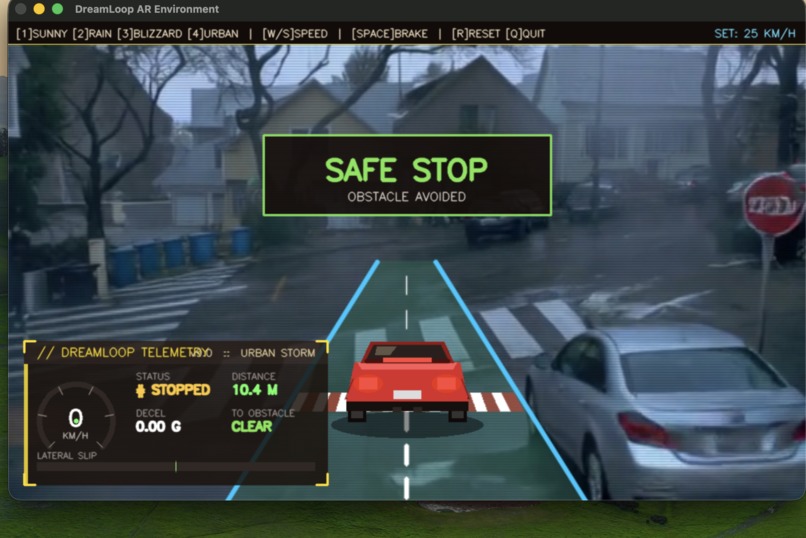
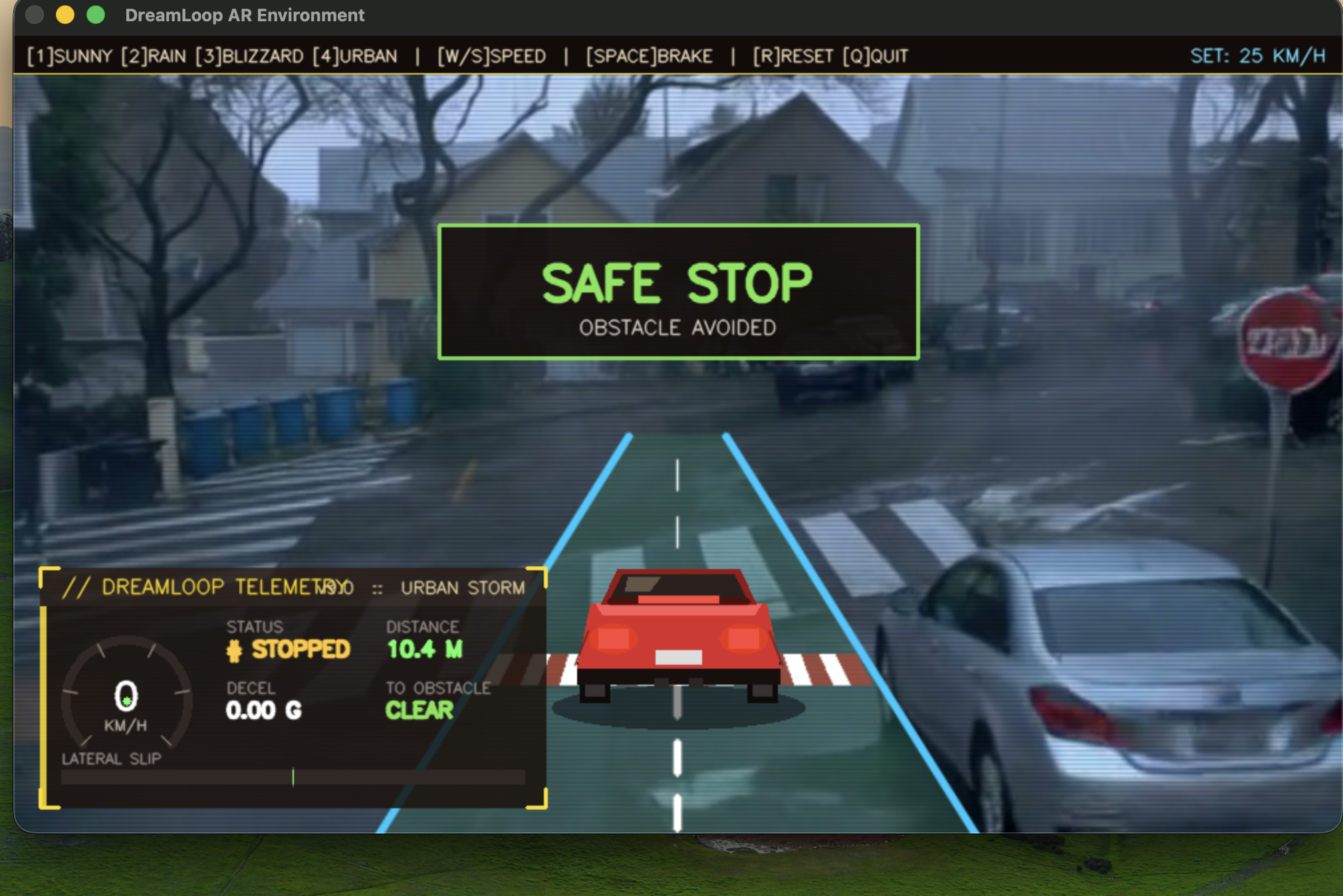
Car making a safe stop and avoiding collision
-
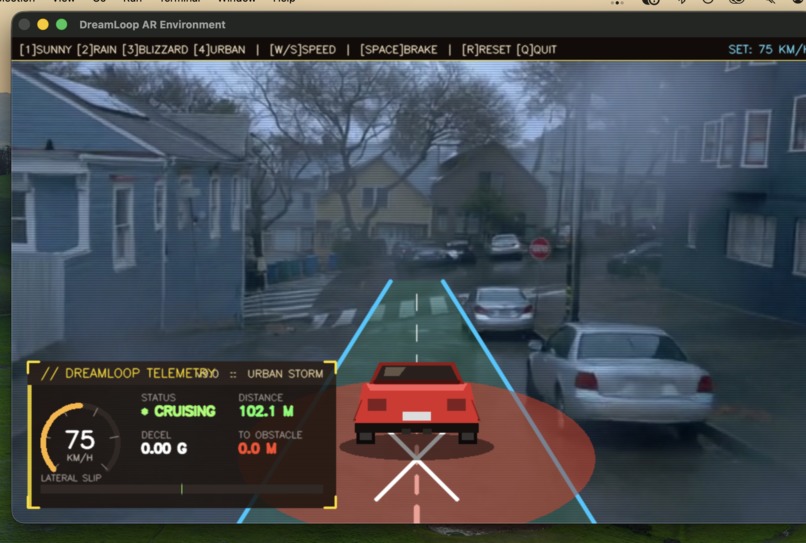
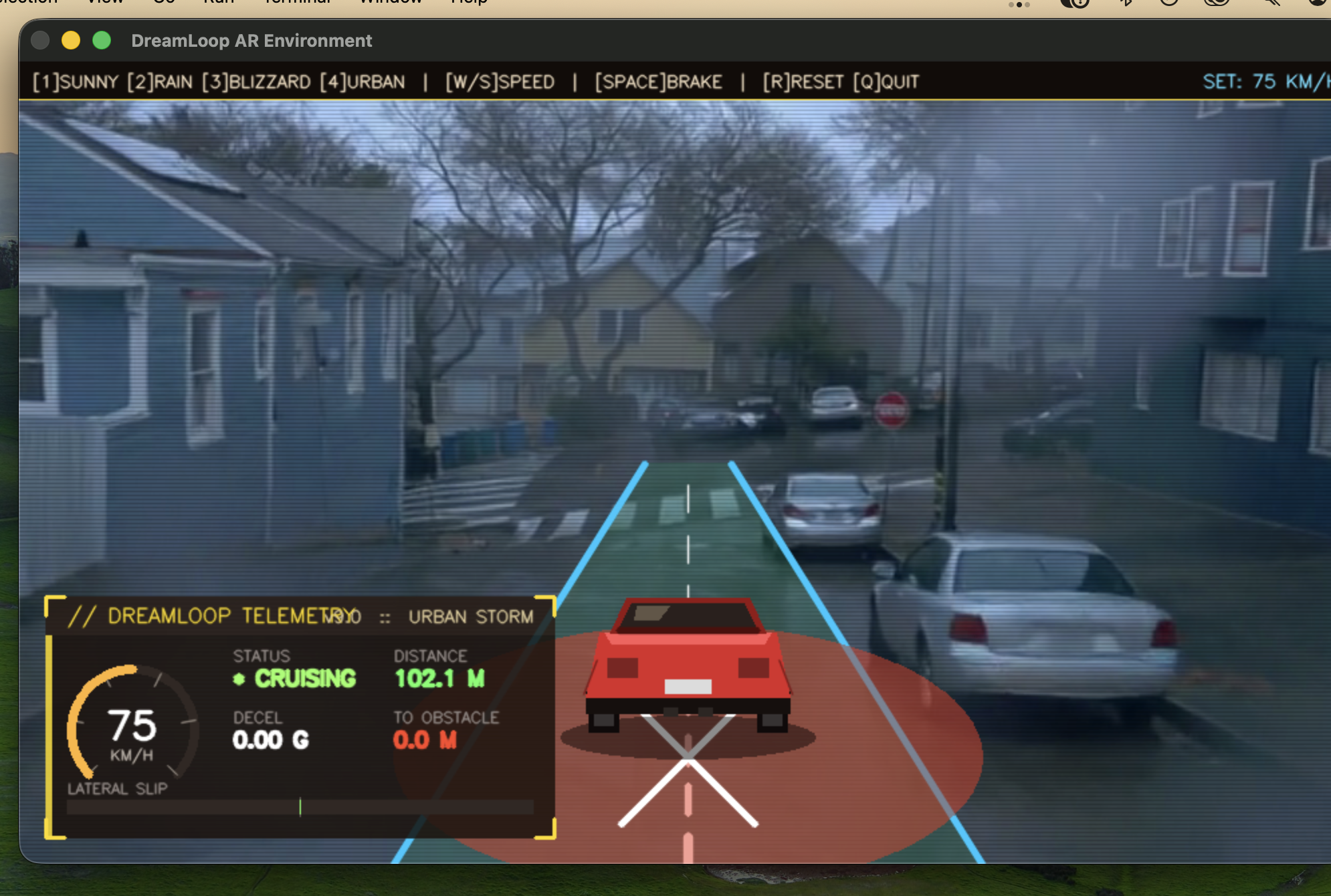
Car stopping late and crashing causing the accident
-
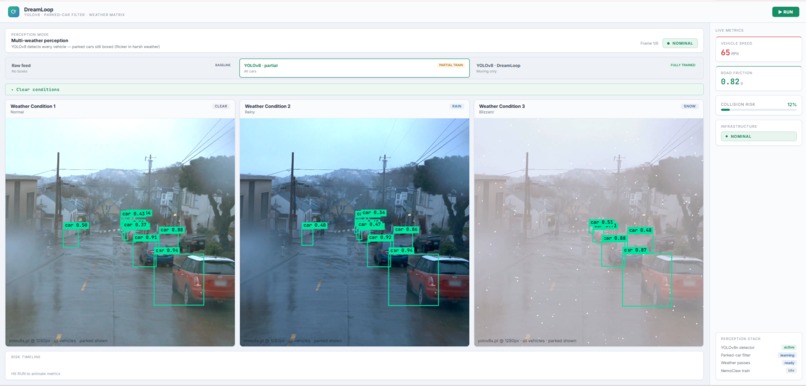
Waymo training video with weather conditions added with Helios
-
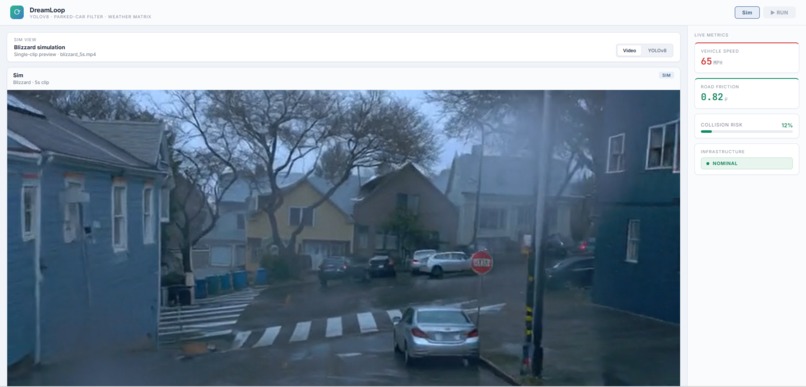
Collision avoidance simulation
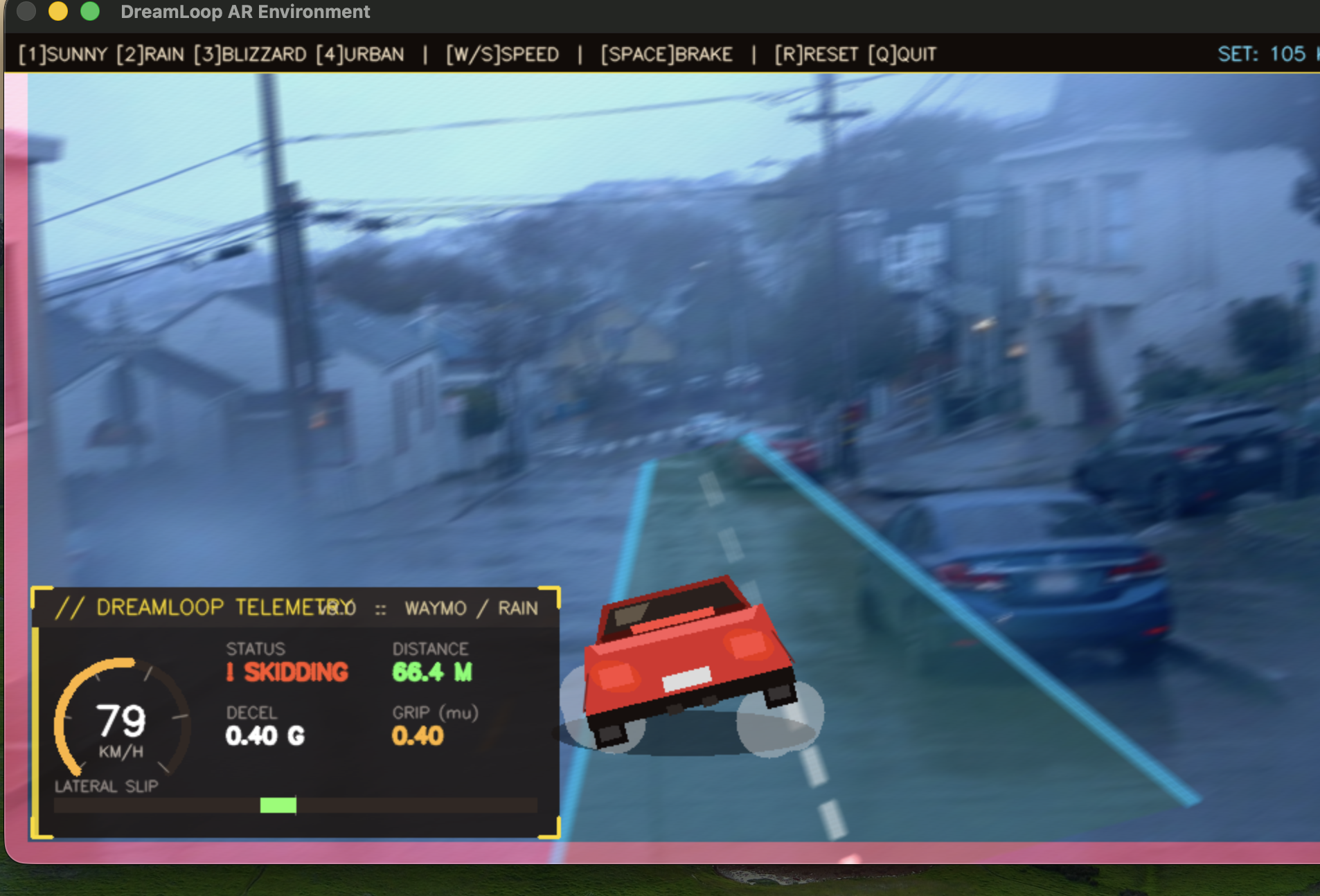
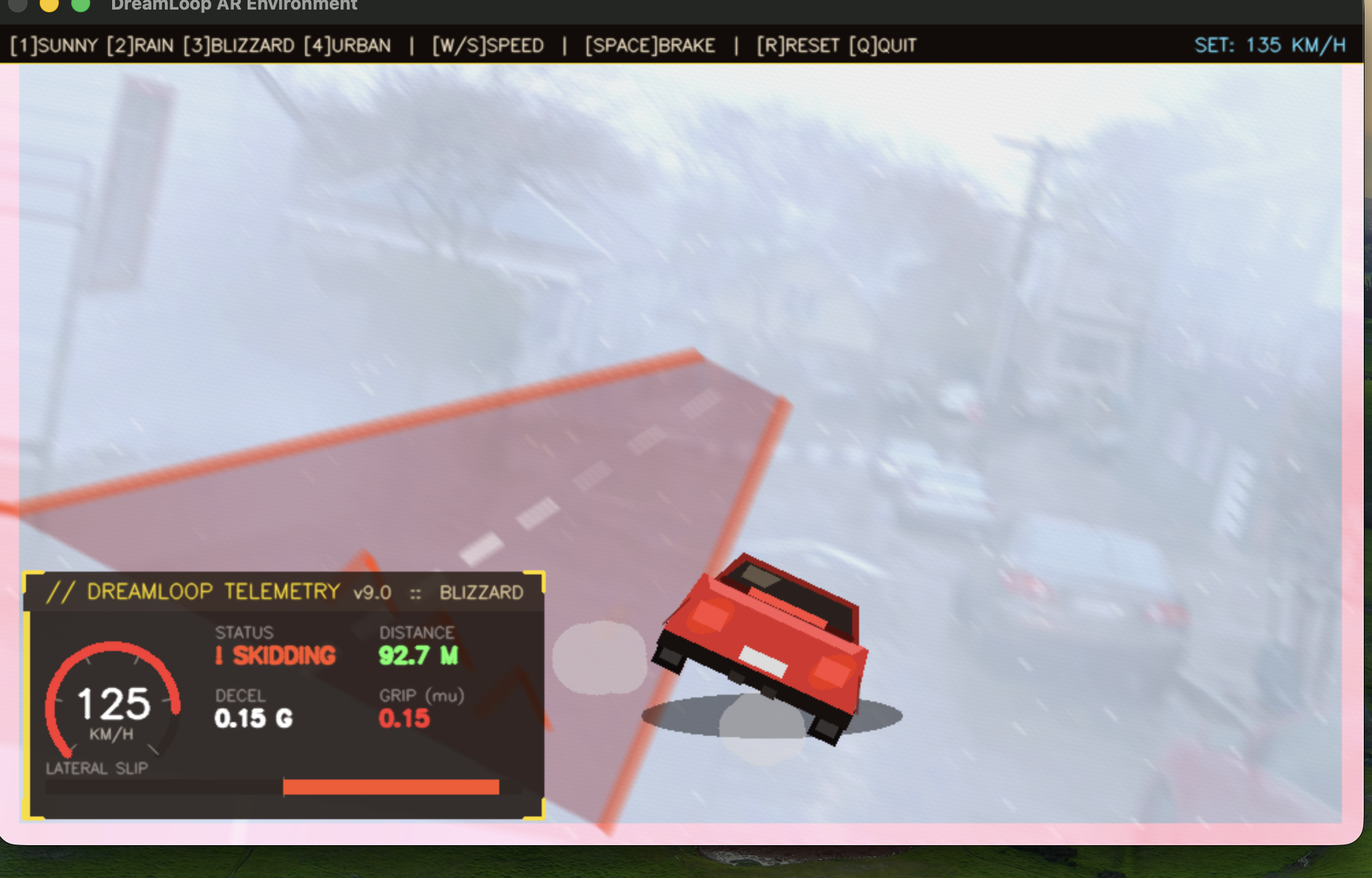
Inspiration
900,000 Americans crash on wet roads every year. 39,000 die. And autonomous vehicles — the technology supposed to fix this — have not been trained enough in flooded environments. They train on millions of miles of clean, sunny highway data because that's what's abundant and safe to collect. When a flash flood hits, the perception model goes blind. Bounding boxes disappear. The car has no idea what to do.
We realized AV safety is fundamentally reactive: someone dies, data gets collected, the model gets patched. We wanted to flip that. What if you could generate every dangerous scenario the real world hasn't thrown at you yet — before anyone gets hurt?
That question became DreamLoop.
What it does
DreamLoop is a synthetic data engine that generates extreme weather driving scenarios and trains AV perception models to survive them.
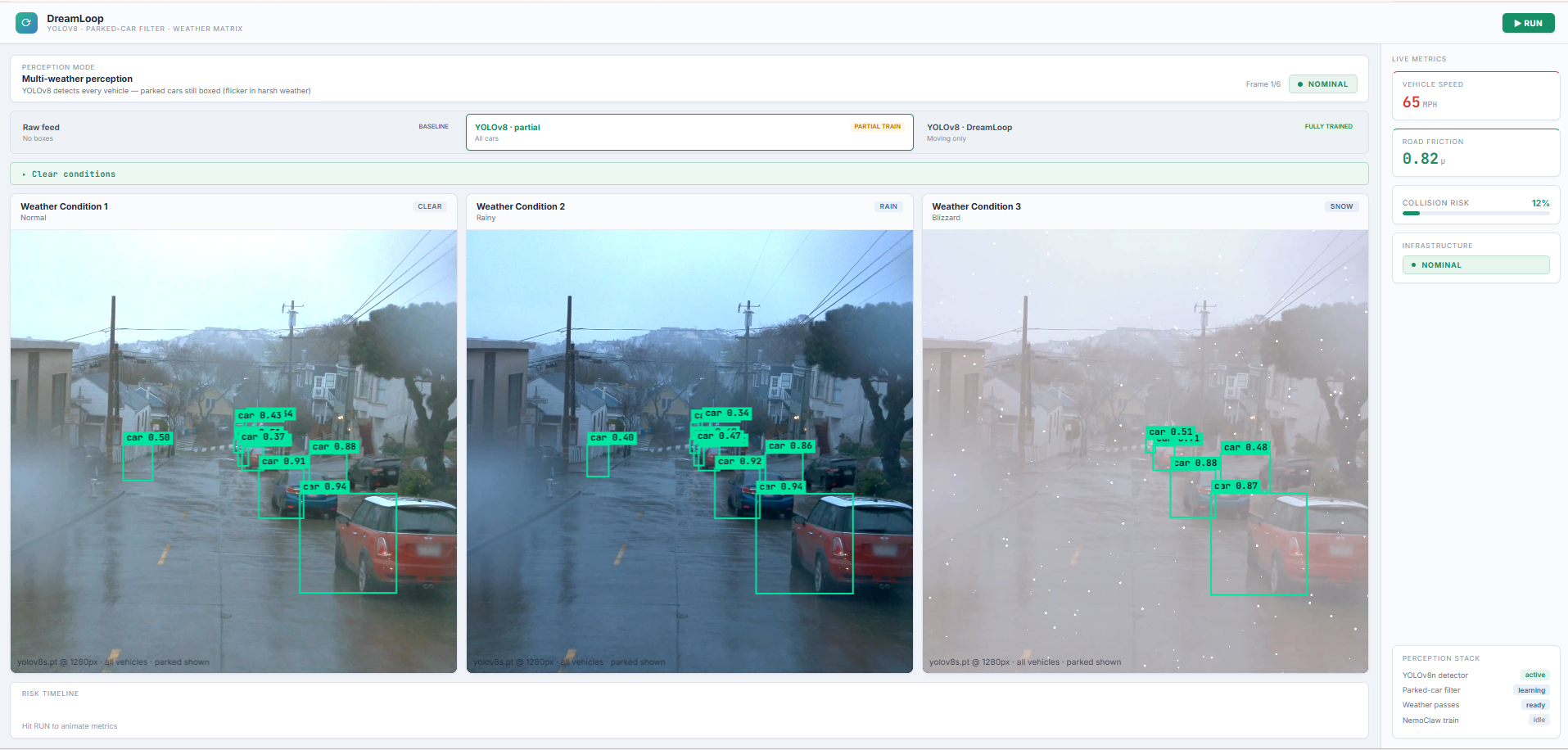
We take a clean Waymo dashcam clip, run it through a dual-model pipeline — NVIDIA Cosmos to lock the 3D scene geometry and bounding boxes, then Helios to render photorealistic flooding on top — and produce annotated training data that doesn't exist anywhere in the real world.
We then attach a loss function to a perception model. At the start, loss is high — the model cannot detect a vehicle that was clearly visible before the flood. We optimize on our synthetic data until that loss drops and the model can detect that same car through standing water, tire spray, and storm glare.
The demo shows this end-to-end on a live dashboard: clean Waymo input → Cosmos geometry → Helios flood render → before/after perception comparison, with live metrics tracking speed, road friction, collision risk, and V2X infrastructure status across two scenarios:
- Scenario A: AV hits the flood zone at 65 MPH with no warning → collision risk peaks at 92%
- Scenario B: Smart road beacon pings the AV via V2X → AV decelerates to 35 MPH → collision risk stays below 18%
How we built it
The pipeline runs on an NVIDIA DGX Spark and chains four components:
Cosmos-Drive-Dreams ingests Waymo driving data and produces a physically accurate base scene — correct road geometry, vehicle positions, and bounding box coordinates locked in 3D space.
Helios (14B Video-to-Video model) takes the Cosmos output and applies extreme flood rendering using a tuned prompt:
"major street flooding, standing water 20–30cm deep, vehicles displacing water with visible wakes, lane lines obscured by mirror-like reflections, dark stormy daylight, photorealistic urban driving scene"
Because Cosmos froze the geometry first, Helios applies weather purely as a visual layer — it cannot hallucinate objects away or move vehicles.
OpenCV overlay pipeline produces two output videos from the same flooded clip:
perception_trained.mp4— clean Cosmos bounding boxes drawn perfectly over the flood sceneperception_untrained.mp4— same boxes with 40% frame dropout, $\pm15$px jitter, ghost boxes, and mislabeling — simulating a model that has never seen rain
The loss function optimization is framed as:
$$\mathcal{L} = \frac{1}{N} \sum_{i=1}^{N} \text{IoU_loss}(b_i^{\text{pred}}, b_i^{\text{gt}}) + \lambda \cdot \text{conf_loss}$$
where $b_i^{\text{gt}}$ comes from Cosmos ground truth and the model is trained until $\mathcal{L}$ converges on the synthetic flood distribution.
NemoClaw runs the infrastructure simulation loop — a state machine writing live metrics to metrics.json every 300ms, consumed by a React dashboard that visualizes the V2X intervention in real time.
Challenges we ran into
Storage on the DGX Spark. Cosmos weights alone exceed 300GB. We couldn't hold Cosmos and Helios on disk simultaneously. Our solution: run Cosmos first, save the output video, delete the weights, then download and run Helios. Sequential, not concurrent.
The hallucination problem. Early tests with Helios prompted directly on raw footage moved cars, erased lane lines, and invented phantom vehicles — making the bounding boxes useless as training labels. Introducing Cosmos as a geometric anchor upstream solved this entirely.
Bounding box alignment. Boxes detected on clean footage need to remain valid after Helios warps the pixel space with water and reflections. Helios is a video-to-video model — it preserves camera perspective and object positions, only altering appearance. Verifying this alignment was critical to the training data being trustworthy.
Integration across four parallel workstreams. Frontend, generative pipeline, simulation backend, and hardware were built simultaneously by four people. The biggest risk was integration boundaries — mismatched file names, schema drift in metrics.json, and port conflicts between the Flask server and Vite dev server all had to be caught and fixed before the demo.
Accomplishments that we're proud of
- Built a working end-to-end synthetic data pipeline — clean video in, flood training data out — in under 14 hours
- Produced a visually compelling before/after perception comparison that makes the value of synthetic training data immediately obvious to a non-technical audience
- Designed a dual-model architecture that provably prevents hallucination in generated training labels — a real problem in the field
- Demonstrated measurable V2X safety impact: Scenario A peaks at 92% collision risk, Scenario B never exceeds 18%
- Shipped a live dashboard that a judge can interact with in real time
What we learned
Generating realistic synthetic data is only half the problem — the labels have to be trustworthy. A flooded driving scene with hallucinated ground truth is worse than no data at all, because it actively corrupts the model. The Cosmos-first architecture wasn't just a visual choice; it was a data integrity decision.
We also learned that the "long tail problem" in AV safety is really a data collection problem. The scenarios that kill people are too rare and too dangerous to capture intentionally. Generative AI doesn't just make simulation faster — it makes certain kinds of safety testing possible for the first time.
What's next for DreamLoop
In one month — expand beyond flooding to blizzard whiteout, black ice, dense fog, and night flooding. Same pipeline, different Helios prompts, same loss optimization framework. Every weather edge case becomes a training problem.
In six months — DreamLoop becomes a synthetic data API. AV companies and perception teams pipe in clean driving footage, specify a weather condition, and receive back annotated training data with perfect ground truth labels. No dangerous real-world collection. No waiting for a flood season.
The bigger picture — NHTSA is actively developing adverse weather certification standards for autonomous vehicles. The first perception stack that can demonstrate verifiable synthetic training data and a loss function that provably improves wet-road detection won't just pass certification — it will shape what the standard looks like.
900,000 wet-road crashes a year is not an act of God. It's a data problem. DreamLoop is the pipeline that starts solving it.

Log in or sign up for Devpost to join the conversation.