-
-
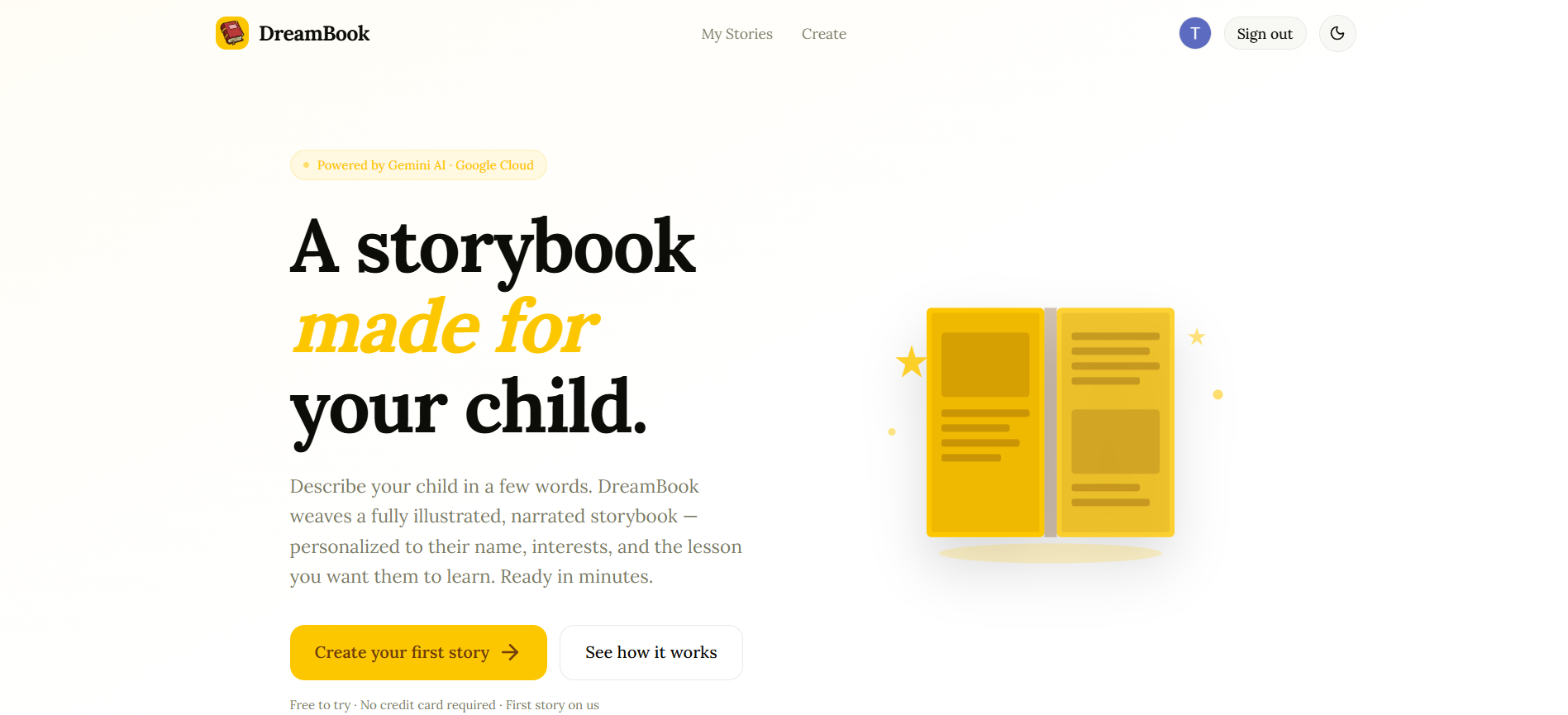
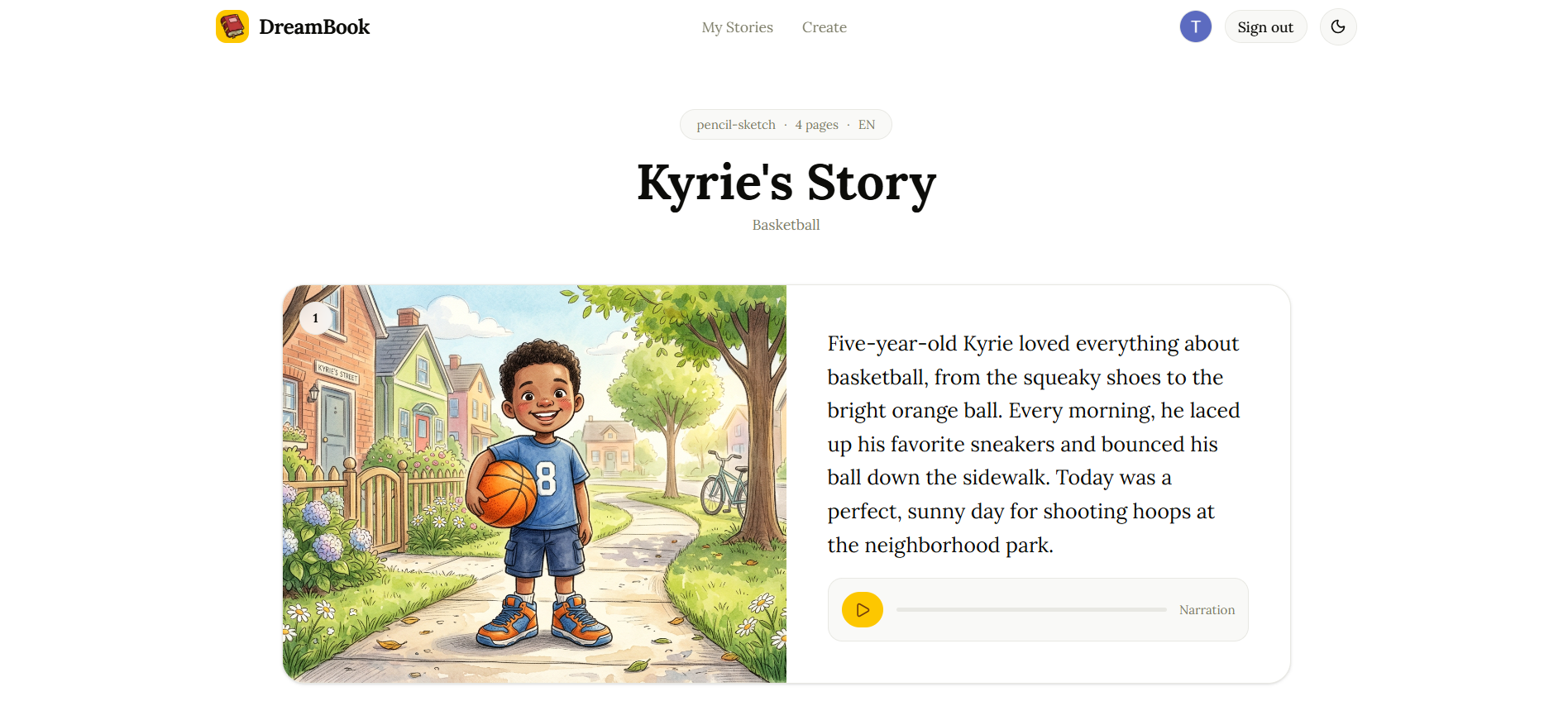
Landing Page
-
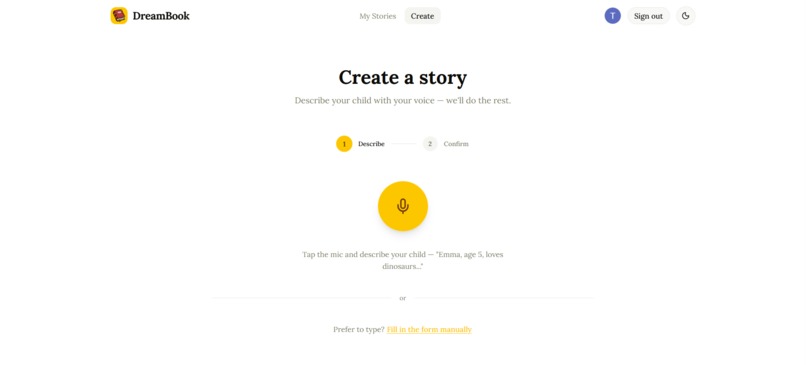
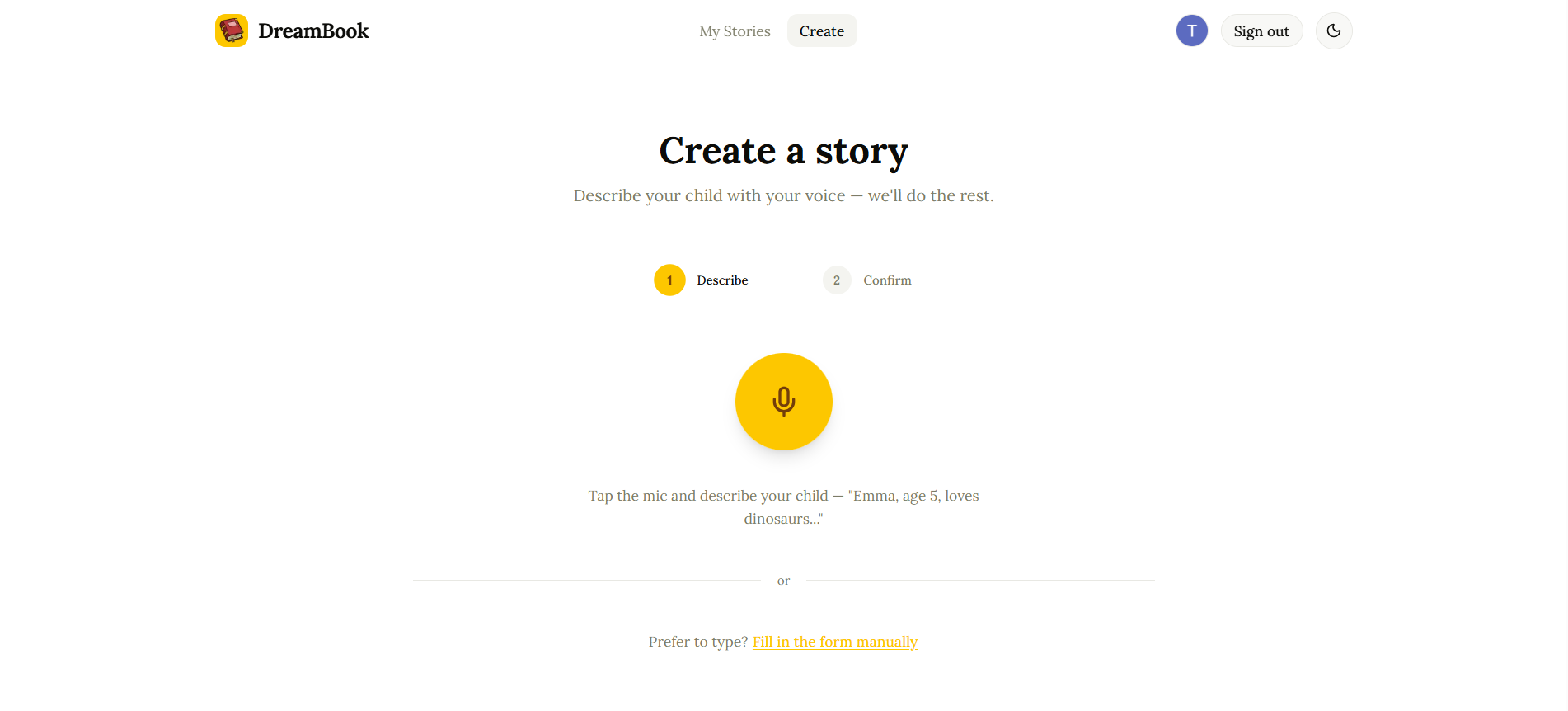
Story Creation via Gemini LIVE API
-
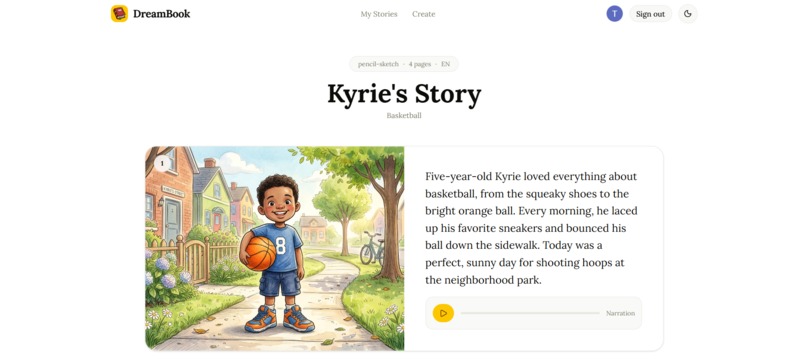
Story Generation
-
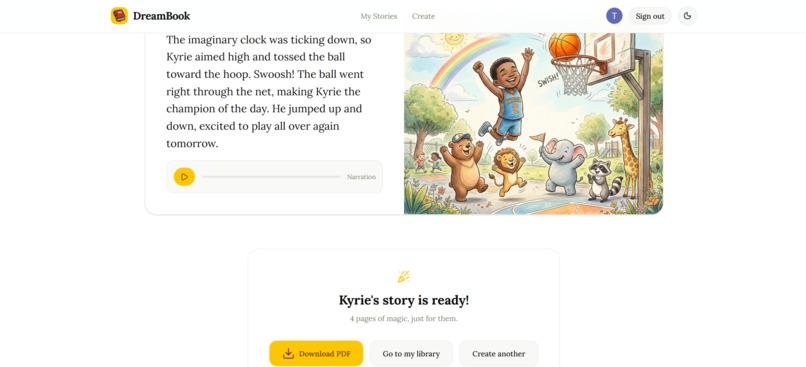
Story Status
-
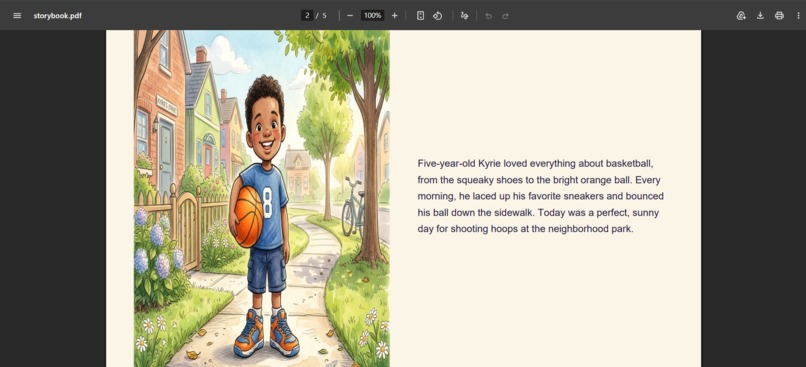
PDF Export using GCS Signed URL
-
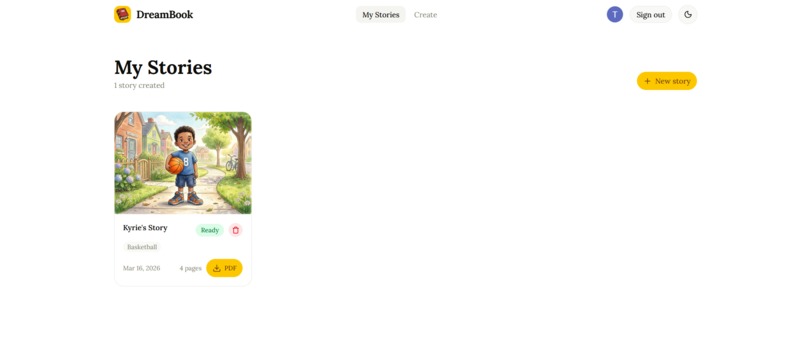
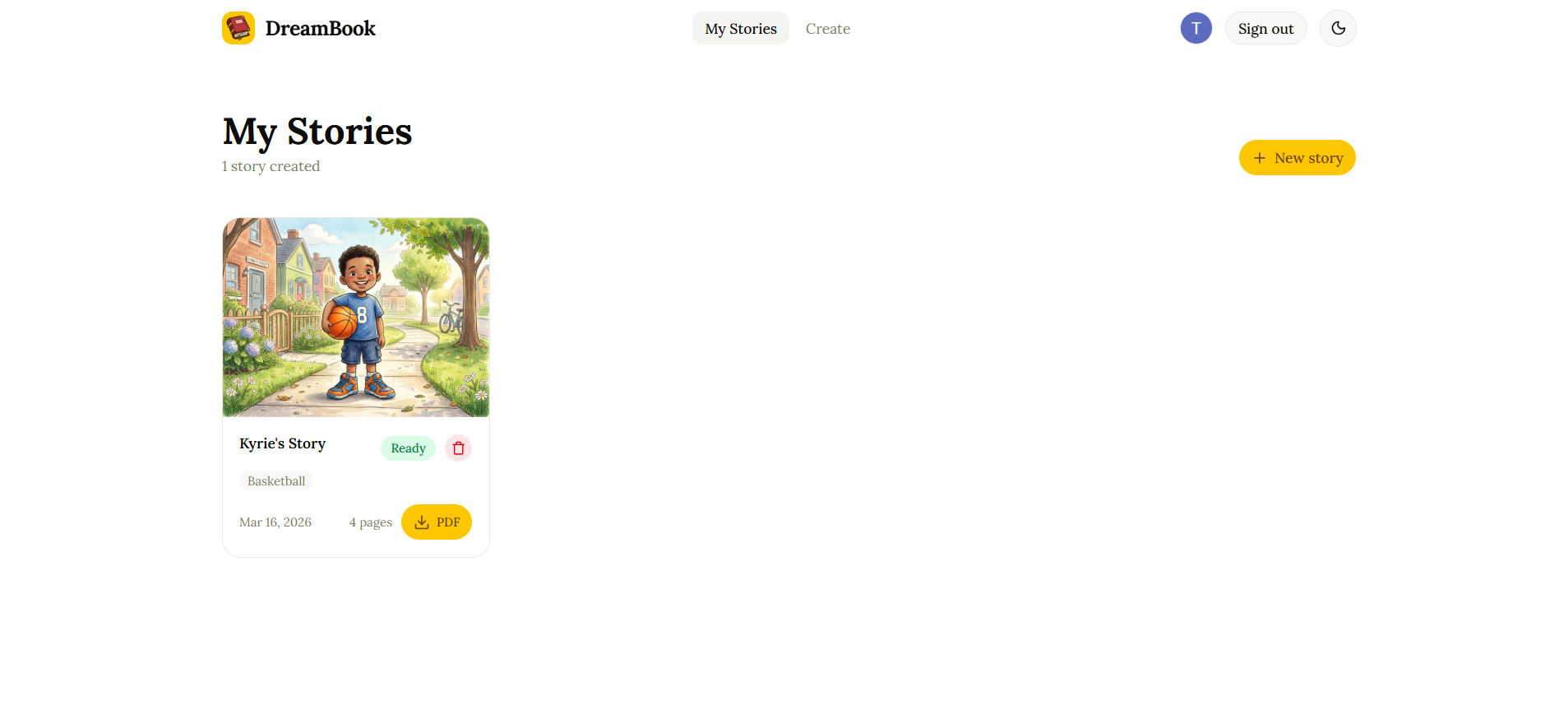
List of Generated Stories
Inspiration
Every child goes through phases — dinosaurs one month, space the next, superheroes after that. As a parent, you want to meet them exactly where they are. Generic storybooks can't do that. A book about Emma specifically, who is five years old, loves painting dinosaurs, and is afraid of thunder? That doesn't exist in any bookstore.
We were also struck by how much AI has advanced in multimodal understanding and generation, yet most AI tools still feel transactional — type something, get something back. The Gemini Live Agent Hackathon challenged us to build something that moves beyond text-in/text-out, and we asked ourselves: what's the most human thing we could make? A bedtime story felt like the answer. It's one of the oldest forms of connection between a parent and child, and we wanted to rebuild it with AI at its core — not replacing the parent, but giving them a magical new tool.
The idea of a parent simply speaking naturally — "my daughter Layla, she's six, obsessed with space, scared of dogs" — and watching a fully illustrated, narrated book assemble itself in real time felt genuinely new. That was the spark.
What it does
DreamBook is a personalized AI storybook generator. A parent describes their child by voice or text — their name, age, interests, fears, and a lesson they want to teach — and DreamBook generates a complete illustrated, narrated storybook in real time, right in the browser.
Here's the full experience:
1. Voice-first input using Gemini Live API
The parent taps a microphone button and speaks naturally. Gemini Live API (gemini-2.5-flash-native-audio-preview) transcribes their speech in real time using built-in Voice Activity Detection. When they stop speaking, a second Gemini call extracts a structured story request — child name, age, interests, lesson, fears — from the transcript. The parent reviews and adjusts the extracted details before generating.
2. Live story generation with interleaved output
The story begins generating immediately using gemini-3.1-pro-preview. The model streams the narrative text alongside [IMAGE: ...] directives — one per page — in a single interleaved output stream. As each page of text arrives, it appears on screen instantly. This is the core multimodal interleaved output the hackathon category requires.
3. Parallel illustration generation
Each [IMAGE:] prompt triggers a Nano Banana (gemini-3.1-flash-image-preview) illustration call concurrently. Illustrations fade in as they complete — the book literally builds itself live in front of you.
4. Audio narration per page
Every page is narrated using gemini-2.5-flash-preview-tts with the warm "Kore" voice, generating a WAV file per page. A play button appears on each page as narration becomes available.
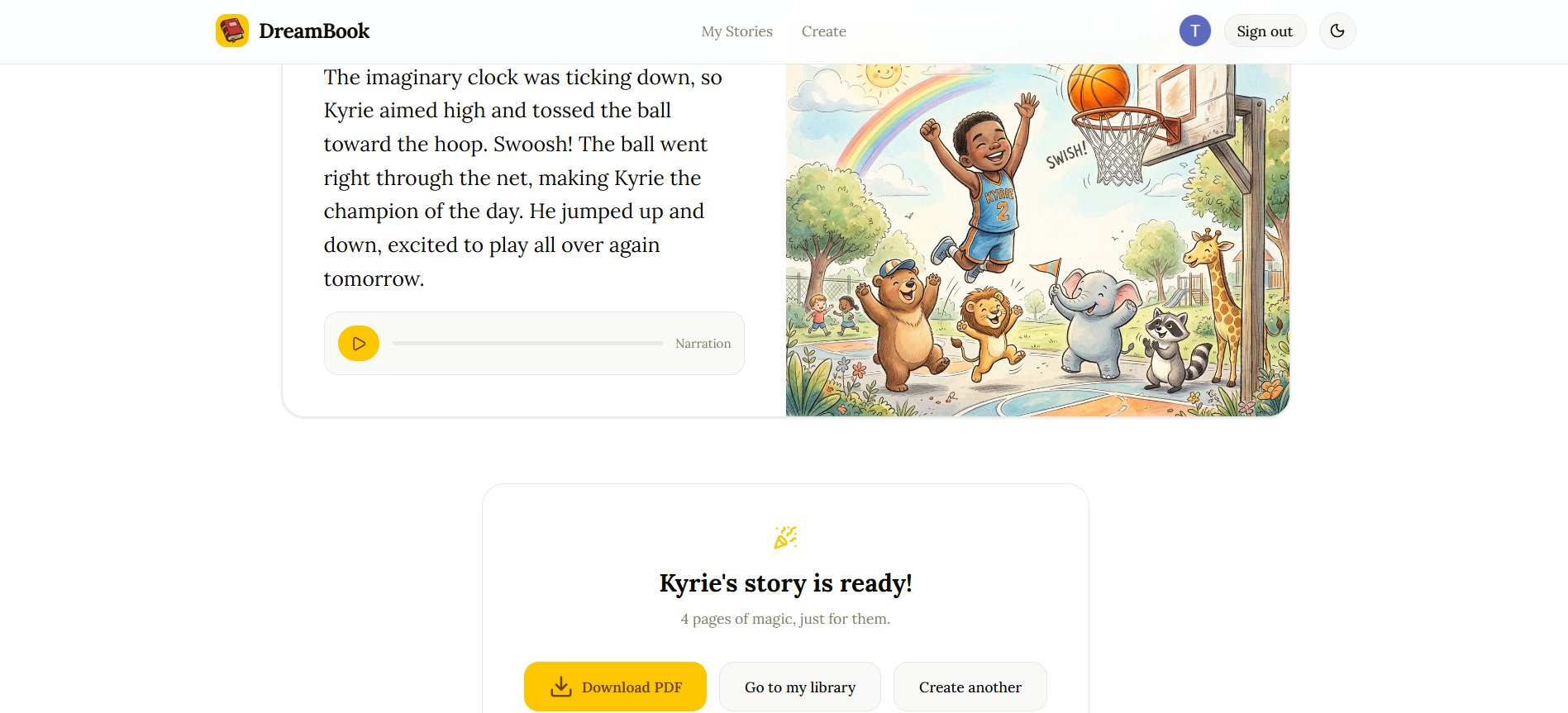
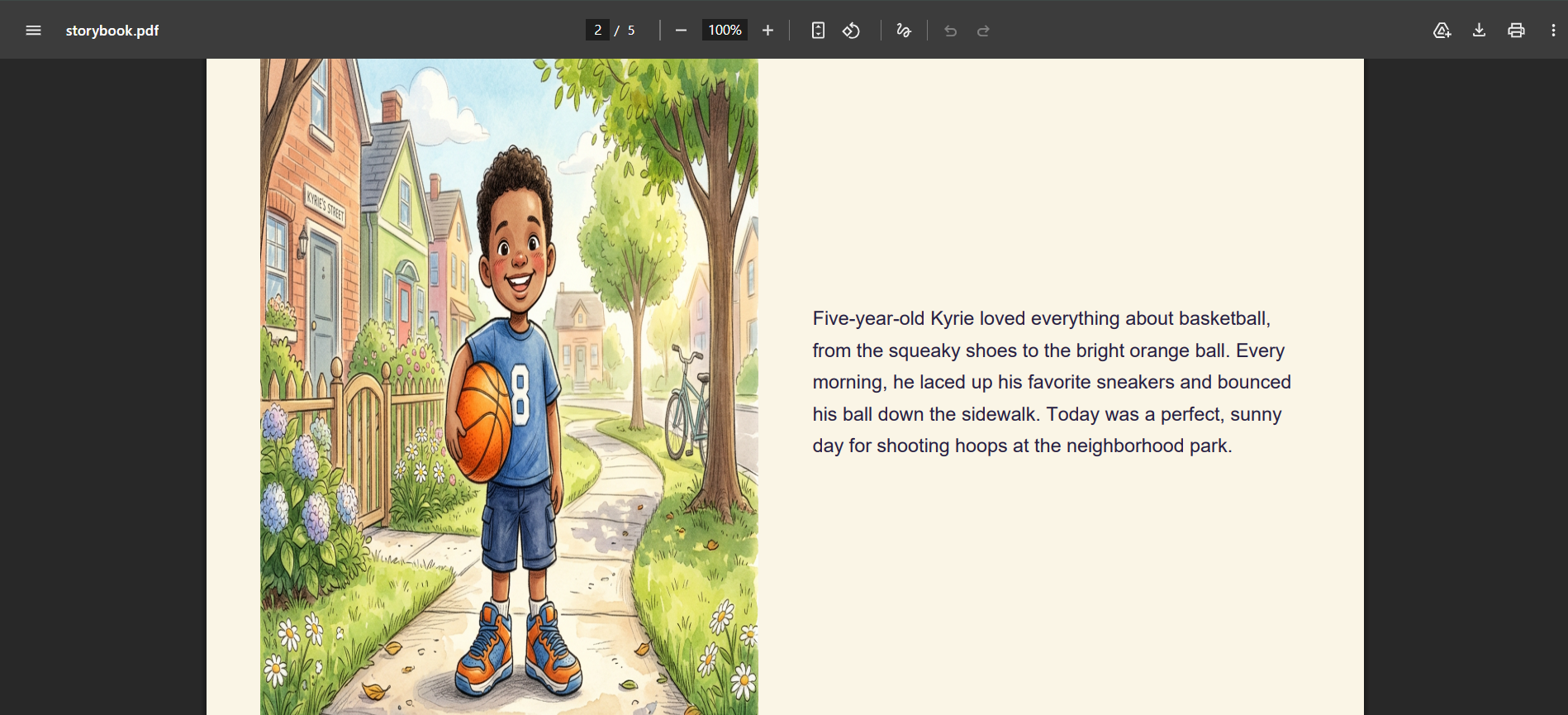
5. PDF export
Once the story is complete, a beautifully formatted landscape PDF storybook is assembled using pdf-lib — illustration on the left, text on the right — and made available for download and printing.
6. Persistent story library All generated stories are saved to the user's account via Firestore and accessible in a personal library. Stories can be revisited, replayed, and deleted.
The entire experience — from speaking the child's description to a complete illustrated, narrated, downloadable storybook — takes roughly 90 seconds.
How we built it
DreamBook is a full-stack TypeScript application split across two repositories.
Backend — NestJS on Google Cloud Run
The API is a NestJS application deployed on Cloud Run with continuous deployment via Cloud Build triggered by GitHub pushes.
AI pipeline (all via @google/genai SDK):
GeminiService— callsgemini-3.1-pro-previewwithgenerateContentStream(), parsing the streamed output for text segments and[IMAGE:]directives as they arriveImagenService— calls Nano Banana (gemini-3.1-flash-image-preview) withresponseModalities: ['TEXT', 'IMAGE']for illustration generationTtsService— callsgemini-2.5-flash-preview-ttswithresponseModalities: ['AUDIO']andspeechConfig, then wraps the returned raw PCM bytes in a WAV header for browser playbackVoiceGateway— a Socket.io WebSocket gateway that opens aGemini Live APIsession per user, streams PCM audio chunks from the browser, accumulates real-timeinputTranscriptionevents, and on stop runs a structured extraction call to parse the transcript into aStoryRequest
Streaming architecture:
Story generation uses Server-Sent Events (SSE) via a raw fetch() stream on the frontend (native EventSource doesn't support auth headers). The NestJS controller uses res.write() with explicit res.flush() after every event and Content-Encoding: identity to prevent Cloud Run's load balancer from buffering the stream.
GCP services:
- Firestore — story metadata and page content
- Cloud Storage — illustrations, audio files, and PDFs, served via signed URLs (requiring
roles/iam.serviceAccountTokenCreatorfor GCS signing on Cloud Run) - Cloud Run — containerized NestJS app, 2 GiB RAM, 2 CPU, 3600s timeout, session affinity for WebSocket stability
- Cloud Build — CI/CD pipeline from GitHub
- Secret Manager — API keys and credentials
- Artifact Registry — Docker image storage
Frontend — Next.js on Vercel
The frontend is a Next.js 15 app with the App Router, styled with Tailwind CSS and Shadcn UI, with Framer Motion for animations.
Key hooks:
useVoiceInput— manages the AudioWorklet PCM capture pipeline, Socket.io connection, and Live API session lifecycleuseStoryStream— manages the SSE async iterator, page state upserts, and post-stream polling for async illustration URLs
Authentication uses Firebase Google OAuth. Every API call attaches a fresh Firebase ID token via a waitForAuth() wrapper that correctly handles Firebase's async session rehydration on page load.
Challenges we ran into
Getting SSE to actually stream through Cloud Run
This was the most frustrating challenge. The story generation pipeline worked perfectly locally but on Cloud Run the frontend would receive pings but no page events. The root cause was Cloud Run's Google load balancer buffering the HTTP/2 response. The fix required three things together: Content-Encoding: identity to disable compression, explicit res.flush() after every res.write(), and listen('0.0.0.0') in main.ts. Any one of these alone wasn't enough.
GCS signed URLs failing on Cloud Run
Every upload attempt threw Permission 'iam.serviceAccounts.signBlob' denied. Unlike local development where the service account JSON provides signing credentials, Cloud Run requires the service account to have roles/iam.serviceAccountTokenCreator explicitly granted, and the GCS client needs to be told the service account email (auto-fetched from the GCP metadata server at metadata.google.internal).
Firebase token verification with newline-contaminated secrets
After deploying, every authenticated request returned 401 with the message "aud" claim expected "live-agent-challenge-489310\n" but got "live-agent-challenge-489310". The secret had been created with a trailing newline. The fix was recreating the secret with echo -n (no newline flag) and adding the new version.
@google/genai vs @google/generative-ai SDK migration
The project started with the deprecated @google/generative-ai SDK. Migrating to @google/genai involved discovering that streaming chunks no longer have a .text property — text must be extracted from candidates[0].content.parts[].text. This caused a subtle bug where the streaming pipeline received chunks but extracted empty strings, producing no pages.
Gemini Live API onopen race condition in TTS
When using the Live API for TTS, onopen fires synchronously during WebSocket connection — before the .then() callback that resolves the session reference. Calling session.sendClientContent() in onopen always threw "cannot read properties of undefined". The fix was to await ai.live.connect() fully before sending, using the session reference from the resolved promise.
React StrictMode double-firing the story pipeline
In development, React StrictMode mounts components twice, causing startStream() to fire twice and two competing Gemini generation pipelines to run simultaneously. Both pipelines called Imagen for the same pages concurrently, hitting rate limits and returning empty image data. Fixed with a useRef guard on the frontend (refs survive StrictMode remounts) and a server-side activePipelines Set to deduplicate by storyId.
Firebase auth race condition on Vercel
On production, Firebase emits null from onAuthStateChanged before rehydrating the persisted session from localStorage — causing every API call to throw "Not authenticated" on first page load. Fixed by rewriting waitForAuth() to ignore the initial null emission and wait for a definitive user state.
Accomplishments that we're proud of
True multimodal interleaved output — The story text, illustration prompts, audio narration, and PDF generation all flow from a single Gemini generation call. We're not calling separate APIs in sequence; the model streams narrative and image directives interwoven in one output, which is exactly what the Creative Storyteller category asks for.
Real-time book assembly — Watching a storybook build itself page by page — text appearing, illustration fading in, narration player appearing — is genuinely magical. It's not a loading screen followed by a result. The experience is the feature.
Full end-to-end voice pipeline — From raw PCM audio captured by an AudioWorklet in the browser, streamed over Socket.io to NestJS, forwarded to Gemini Live API for transcription, then parsed into a structured StoryRequest by a second model call — the entire voice flow works without the user touching a keyboard.
Production deployment — DreamBook is fully deployed and publicly accessible. The backend runs on Cloud Run with automatic CI/CD, the frontend on Vercel, authentication through Firebase, assets in GCS. It's not a demo — it's a working product.
Personalization that actually works — When you generate a story for "Layla, age 6, loves space, scared of dogs, should learn that being kind to animals helps everyone" — the story is genuinely about Layla, in space, with a dog character, with that exact moral arc. The model follows the brief faithfully.
What we learned
The @google/genai SDK is meaningfully different from its predecessor — not just a rename. The streaming API, response shape, and Live API integration all changed substantially. Reading the actual SDK source and documentation rather than assuming parity with the old SDK would have saved significant debugging time.
Cloud Run is not a simple Node.js host — it's a containerized environment sitting behind a Google load balancer with HTTP/2, compression, and connection management that all interact with streaming in non-obvious ways. SSE streaming in particular requires deliberate configuration to work correctly.
Signed URLs on Cloud Run require explicit IAM setup — local development using a service account JSON file masks several permissions that Cloud Run's default compute service account doesn't have. The signBlob permission required by GCS for signed URL generation is not granted by default and is easy to miss.
The Gemini Live API is genuinely impressive for real-time transcription — it handles natural speech, filler words, and non-English input (we tested Urdu and Hindi mid-session) remarkably well. The inputTranscription events stream in fast enough to feel like real-time feedback to the user.
React StrictMode is a great bug finder — the double-mount behavior that caused our pipeline duplication bug exists precisely to catch side effects that aren't properly cleaned up. The correct fix (a ref guard, not suppressing StrictMode) made the production code more robust.
Debugging cloud deployments requires good logging — adding structured log output with specific identifiers to every service method turned multi-hour debugging sessions into single-log-search fixes. Cloud Logging is a genuinely powerful tool when the code is instrumented well.
What's next for Dream Book
Story editing — Let parents regenerate individual pages, swap illustration styles, or adjust the lesson after seeing the first draft. The pipeline is already page-aware; editing is a natural extension.
Multi-child households — Save child profiles so returning parents don't have to describe their children every time. "Generate a new story for Emma" becomes a one-tap action.
Print-on-demand integration — Partner with a print service to let parents order a physical hardcover version of their generated storybook. The PDF we already generate is print-ready.
Bilingual stories — Generate the same story in two languages side by side — English and Urdu, English and Spanish — for bilingual families. The TTS already supports 15+ languages; the story generation just needs a dual-language prompt.
Educator mode — Teachers describe a classroom scenario or social situation, and DreamBook generates a story addressing it — a child being left out at recess, sharing, dealing with a new sibling. Already works; needs a dedicated UI flow.
Story series — Generate connected multi-book series with consistent characters and a running arc. Chapter 2 picks up where Chapter 1 left off.
Native mobile app — The voice input experience in particular would be significantly better as a native iOS/Android app with direct microphone access and push notifications when the story is ready.
Gift mode — A shareable link that lets grandparents, aunts, and uncles describe a child and generate a story as a gift, without needing an account. Stories make the most personal, memorable gifts.
Built With
- docker
- firebaseauth
- firestore
- gemini-3
- googlecloudrun
- googlecloudstorage
- googlecloudtasks
- googlevertexai
- nano-banana
- nestjs
- nextjs
- typescript


Log in or sign up for Devpost to join the conversation.