Overview
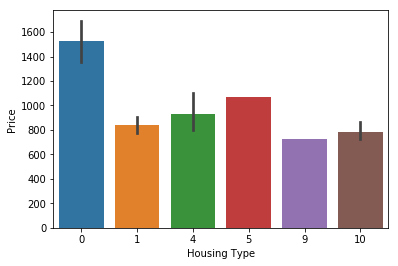
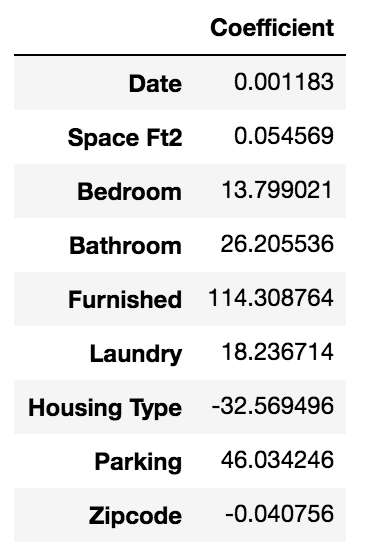
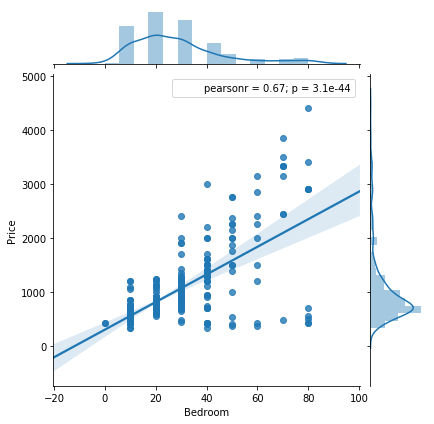
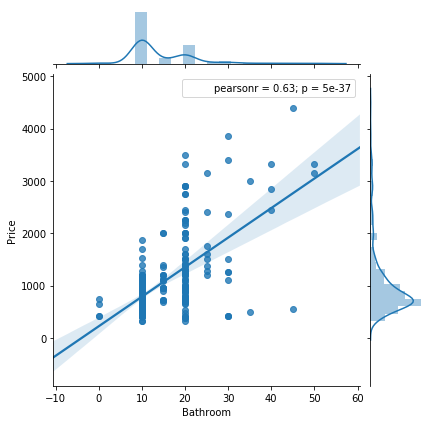
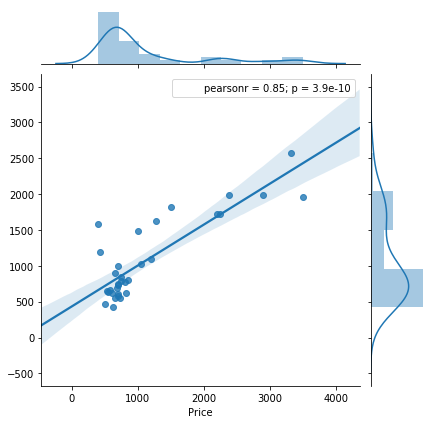
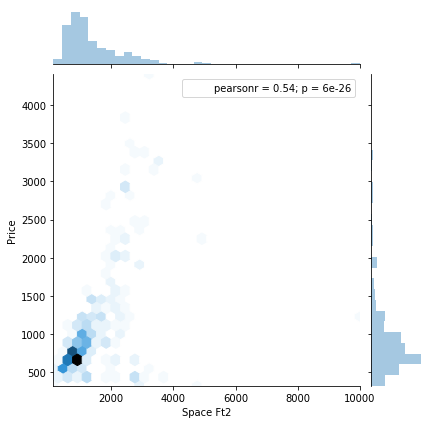
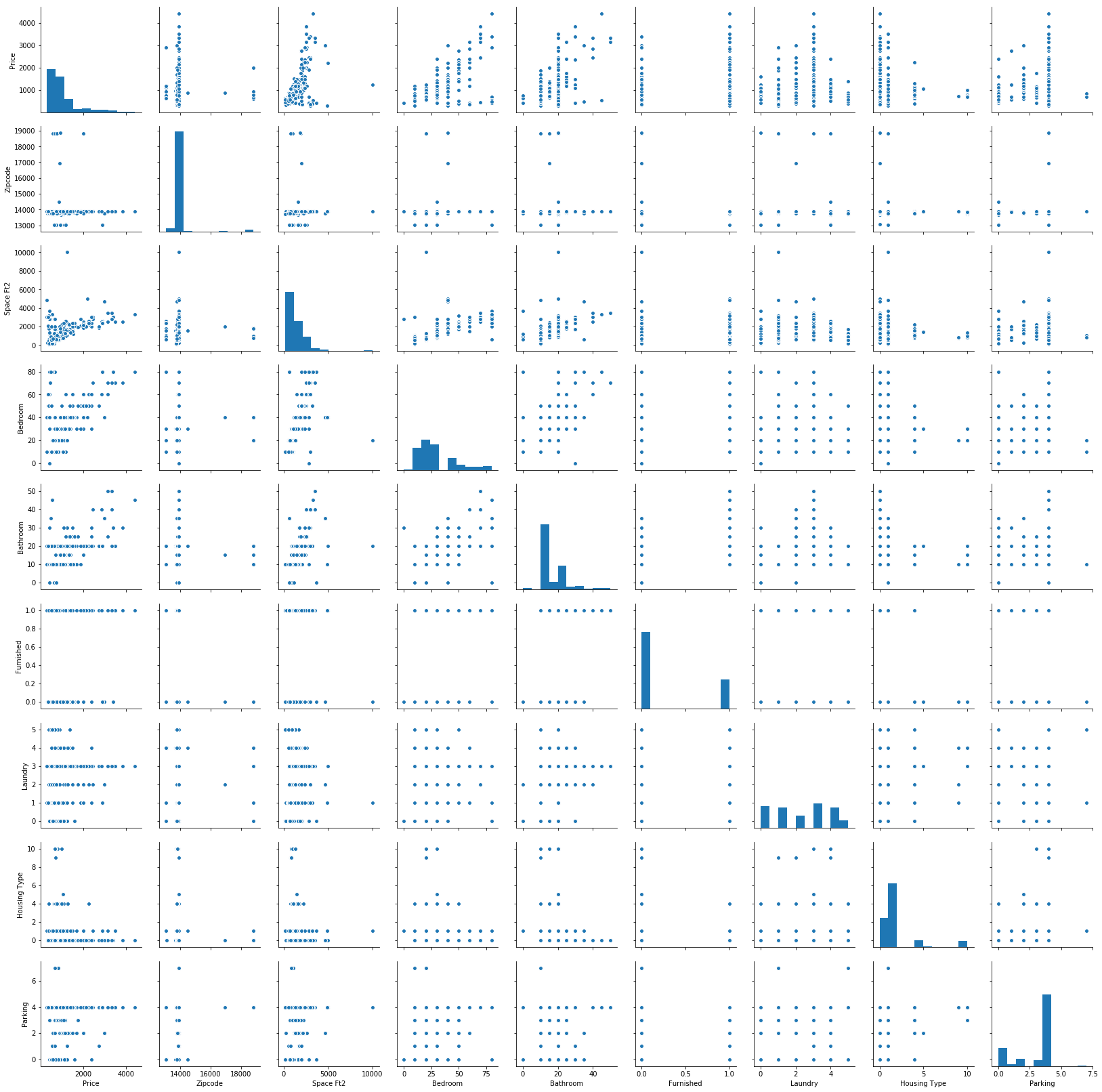
We studied the datasets provided by organizor, which represent the housing situations in Binghamton. After analysis, we have two research achievements: 1) has trained and devleoped the prediction model successfully; 2) Space doesn't influence the price, however, furnished situation, parking and bathroom are the top three factors.
Process
We mainly used jupyter notebook to deal with the datasets.
Data cleanning: Complete the incomplete file, espeacially writing code to replace all the addresses by Zipcode, since machine learning algorithm cannot recgonize string type.
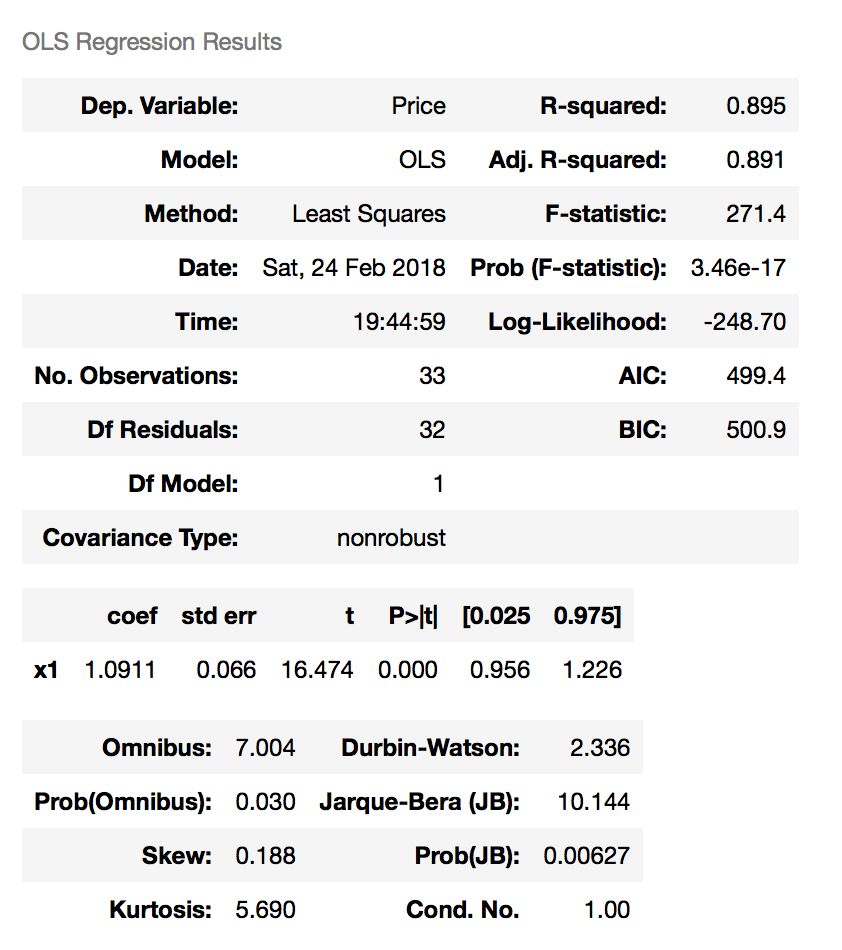
Data analysis: We invoke "Hedonic" model to get the analyzing logics, then use linear regression to get the results. Have to mention that, we develop the "random tree" algorithm by ourselves.
Data correction: Our R-square value reached 0.895.
Highlight
1) We designed "Random Tree" Machine Learning Algorithm by ourselves;
2) We combined economic knowledge and coding skills, studied "Hedonic" model, used linear regression to get the results;
3) We used "Cross Validation" to do correction, making sure the result is believable.

Log in or sign up for Devpost to join the conversation.