-
-
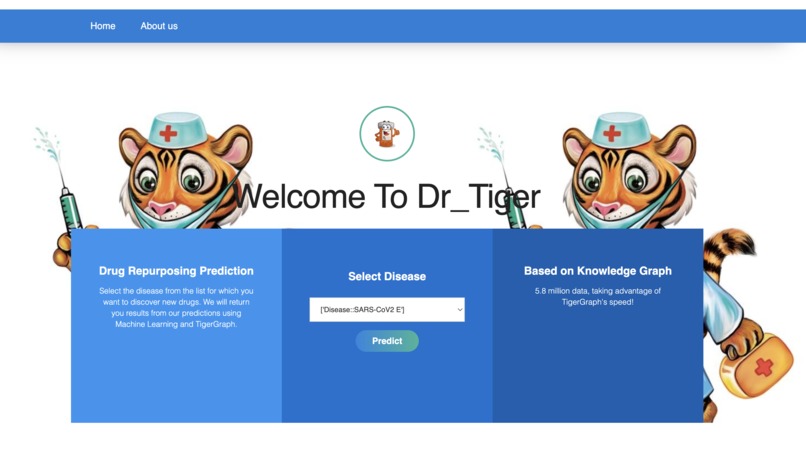
Main Page
-
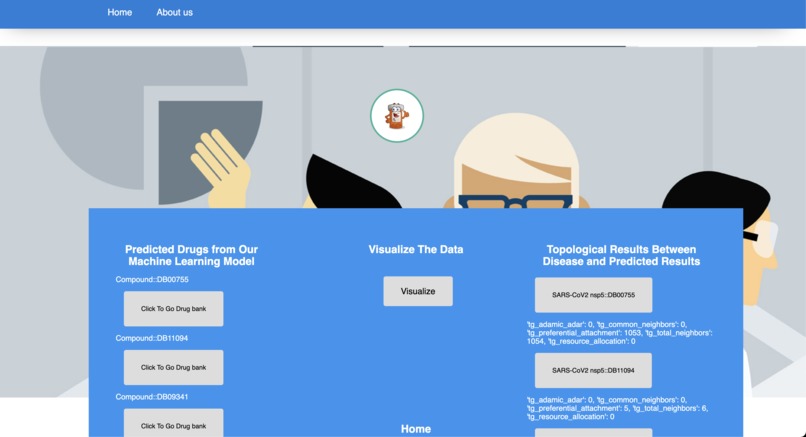
repurposing drugs and topological parameters.
-
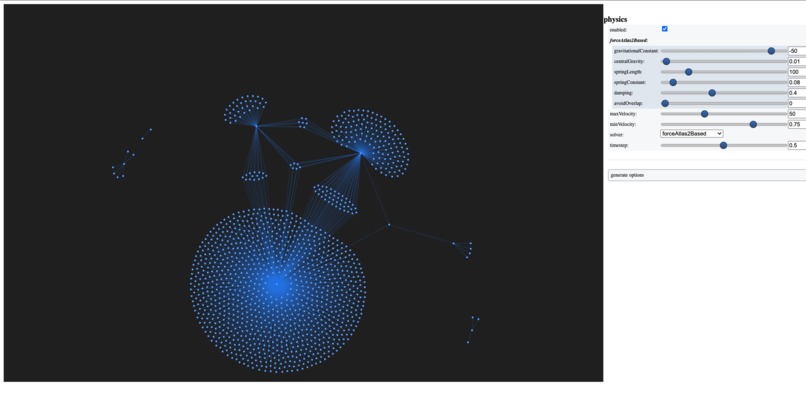
graph structure
-

graph structure


Inspiration
Diseases are a complex set of phenomena that have various relationships with drugs, cells, and organisms. Each of these relationships creates more complexity to find the proper drug for the disease. Finding proper drugs for the diseases, designing and developing it is an expensive process.
As we know, drugs can cure a variety of diseases but usually, they use just for one or two diseases. People are inclined to use drugs not according to the prospectus to solve their diseases. Unapproved use of an approved drug is often called “off-label” use. Off-label usage of drugs has increased dramatically in the last ten years.
With advanced machine learning techniques, we are able to do drug repurposing for different diseases. These can solve the issues related to off-label usage and reproducing drugs that cost billions of dollars.
What it does
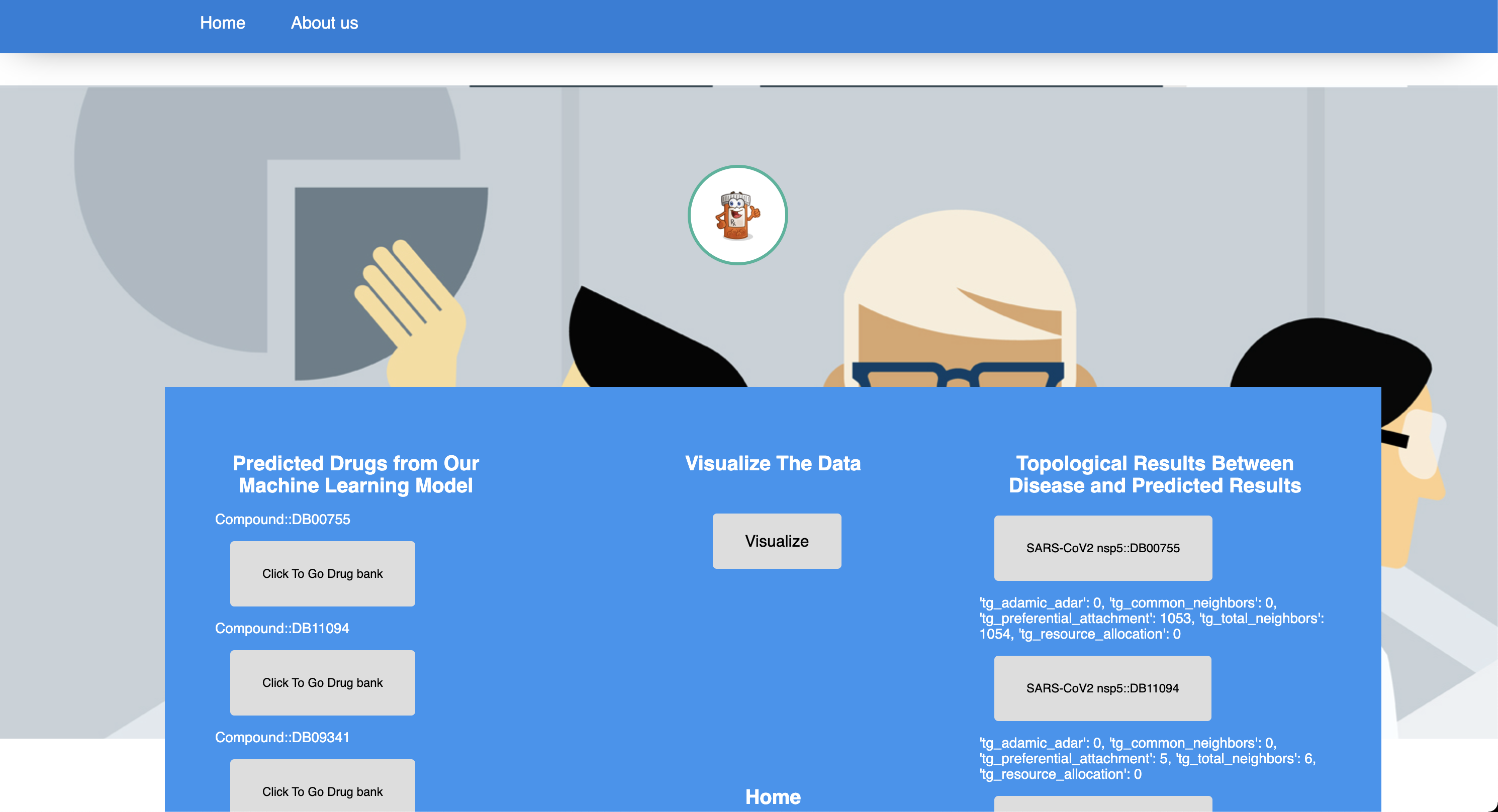
Drug repurposing is one of the biggest issues in the drug pharmaceutical industry. It costs a lot and involves many steps related to the FDA and other healthcare organizations. Our application offers to solve this issue using advanced machine learning techniques and TigerGraph. Our application is called Dr_Tiger and it is a recommender system for drug repurposing.
Users need to select one of the 5103 diseases, then the application uses advanced machine learning techniques with TigerGraph functionalities offered by the graph data science library to find the related drugs. After the related drugs are found among 5.8 million edges, the application offers to see these drugs in the DrugBank. Also, graph structures are fascinating in a visual way so the application creates a virtual form of the graph that the user can see and it is interactive!. Furthermore, the parameters like topological link prediction ,Adamic Adar and others are shown by the application to the user.
How we built it
We built the application using the latest technologies. The application uses the Flask microframework for back-end services. The time to train the model is very long for our data because it consists of 5.8 million rows. Because of that, we used pre-trained vectors to solve this issue. Our solution uses topological link prediction parameters that offered by the graph data science library by TigerGraph in the training step. Also, our solution uses different libraries to visualize the graph and some of them are networkx and pyvis.
Challenges we ran into
The data that we used consists of 5.8 million edges and it is hard to make operations on these kinds of big data. The first challenge that we faced was the load the data to the cloud. It was a hard process because the data consists of a lot of loops. We solved the problem using the pyTigerGraph library functions and the loading process of the data cost about 3 days. After we solved the loading issue, we had to train the model to get proper drugs for particular diseases. The way we solved the issue was by using the pre-trained vectors that come with the Torch library. Then, we moved one step forward and wanted to make a interactive visualization of the graph data. We used different libraries to visualize the graph structure efficiently.
Accomplishments that we're proud of
We are proud that the platform we offer can be used easily by individuals who are doctors or pharmaceutical industry workers. Anyone wishing to study drug repurposing will get benefits from this work, regardless of its approach to machine learning and graph terms. Users who want to do clinical studies can use our solution as an additional resource. Also, as a team we are proud of that our solution is ready for the production environment and can be used in the real world with just small adjustments.
What we learned
Using a graph database is more efficient than the using traditional database when it comes to the graph-structured data. We deployed almost 5.8 million rows by using TigerGraph to the limited cloud very easily and we learned how to use database functionalities offered by TigerGraph. During our research, we learned a lot of things about graph convolutional networks, graph attention networks, etc. Also, we learned how to use topological link prediction parameters offered by the TigerGraph data science library.
What's next for Dr_Tiger
Dr_Tiger uses now just 5.8 million rows and 5103 diseases. We plan to use more relations and more diseases to increase the platform's ability. Also, we plan to use different types of link prediction techniques on the data that will increase the accuracy of the drug repurposing.
The application that we prepared can be used in the real world. It uses small resources from the local system, relies on the TigerGraph cloud power, and offers a different type of experience to the pharmaceutical industry.
The innovations that we will make with this application may change the way of the pharmaceutical industry and may create big differences.
Built With
- flask
- javascript
- matplotlib
- pandas
- pvis
- python
- pytigergraph
- pytoch
- torch
- torchdrug
- uvicorn











Log in or sign up for Devpost to join the conversation.