-
-
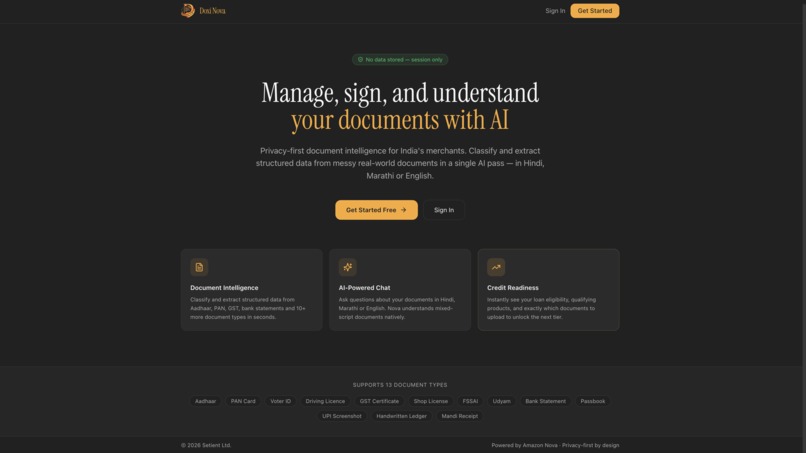
Landing Page
-
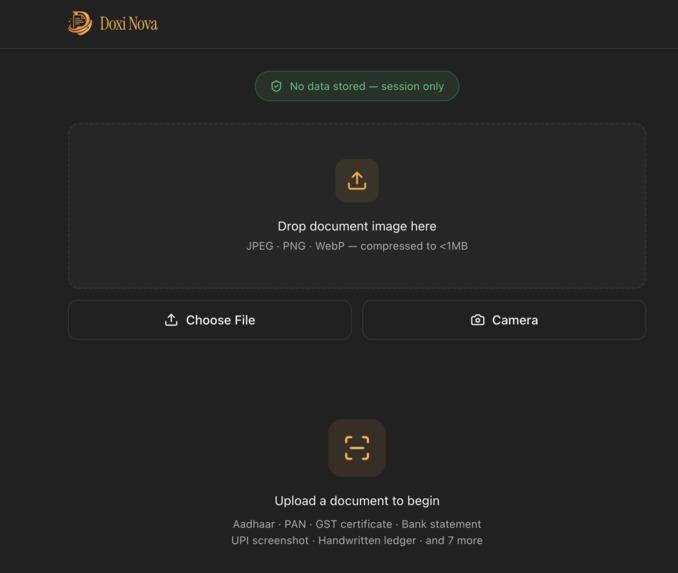
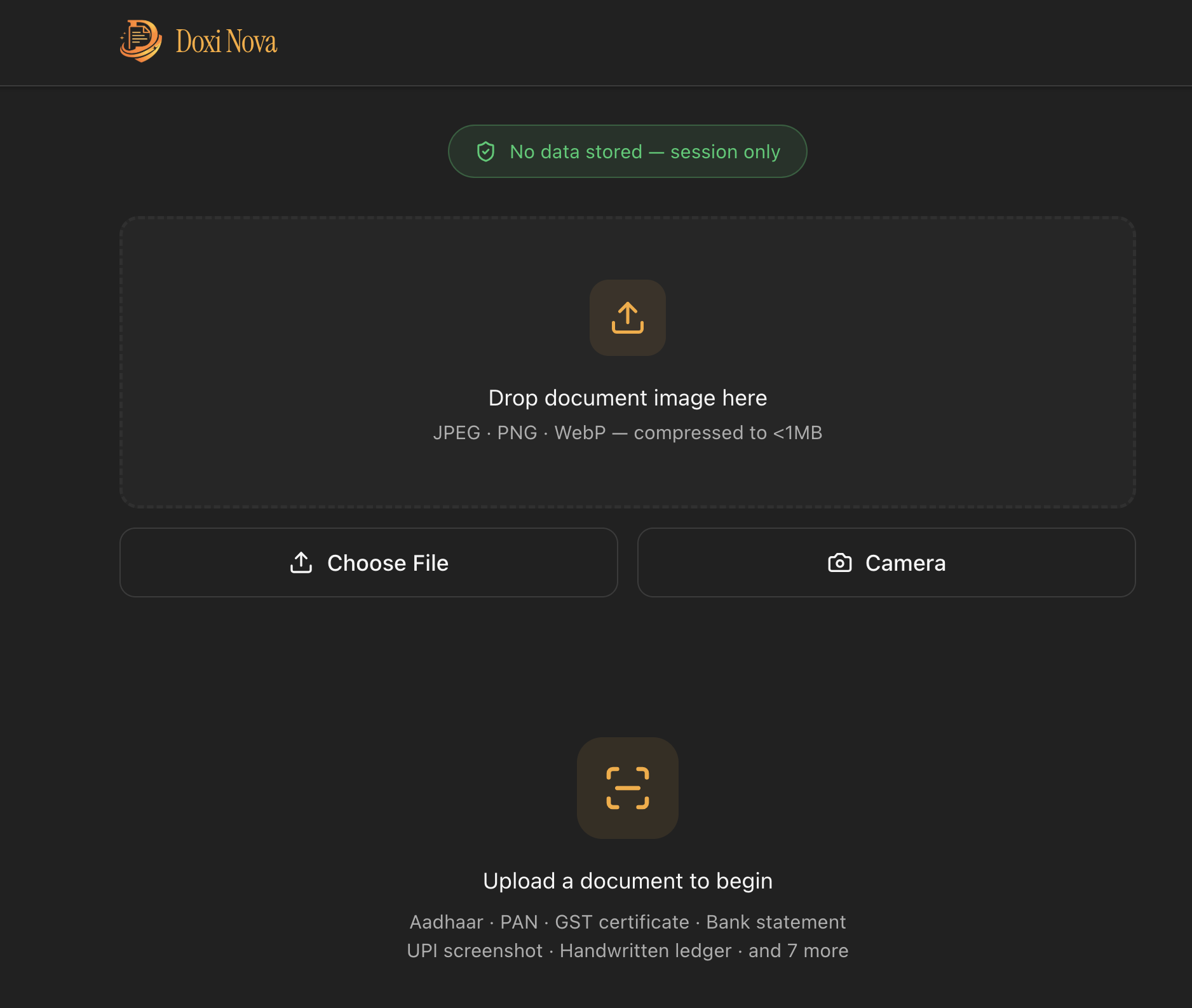
Document Upload
-
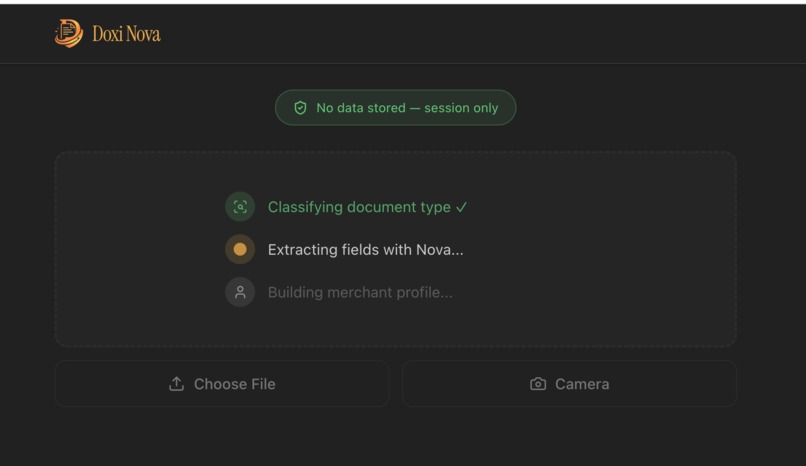
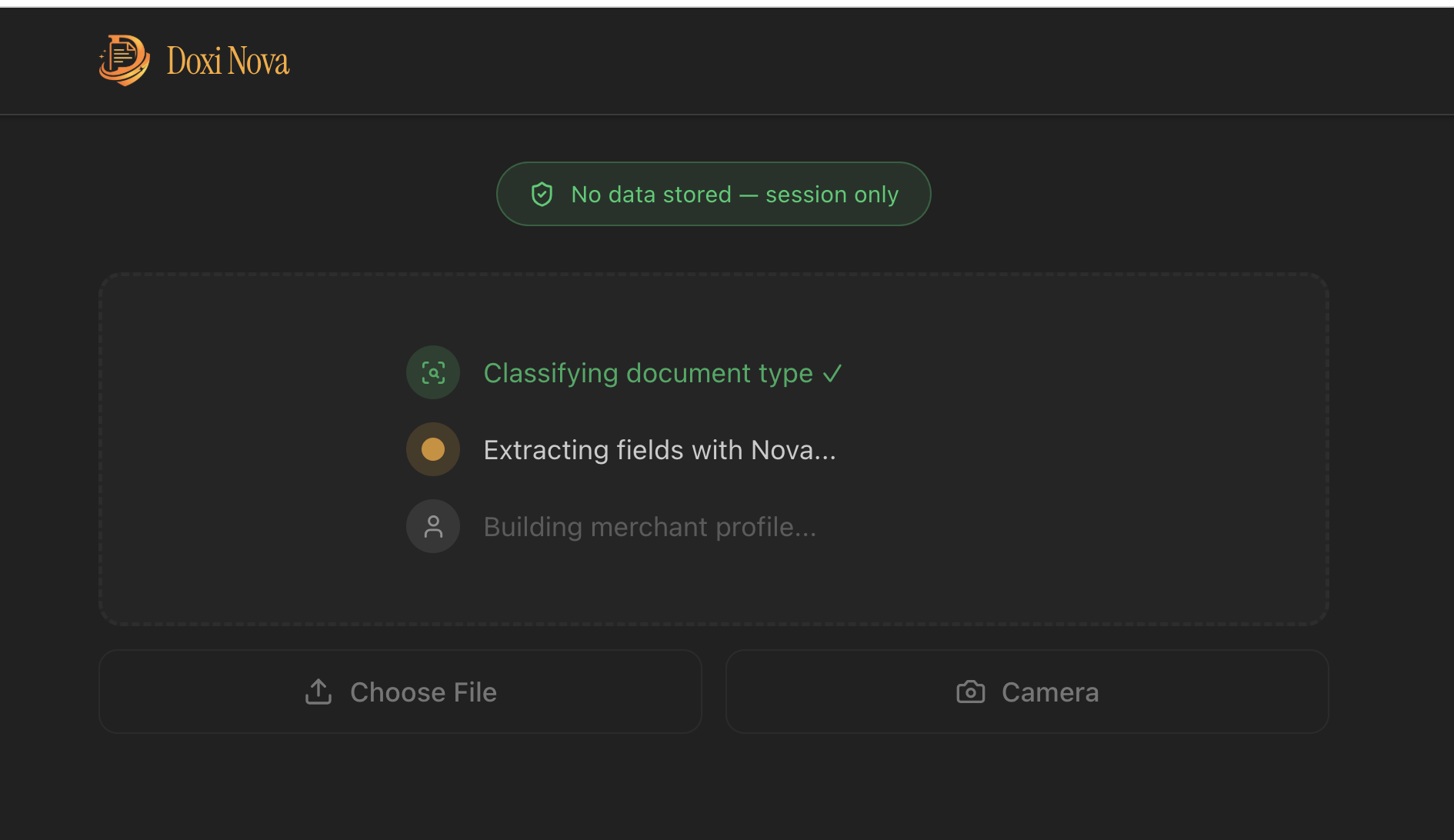
Extraction Pipeline 1
-
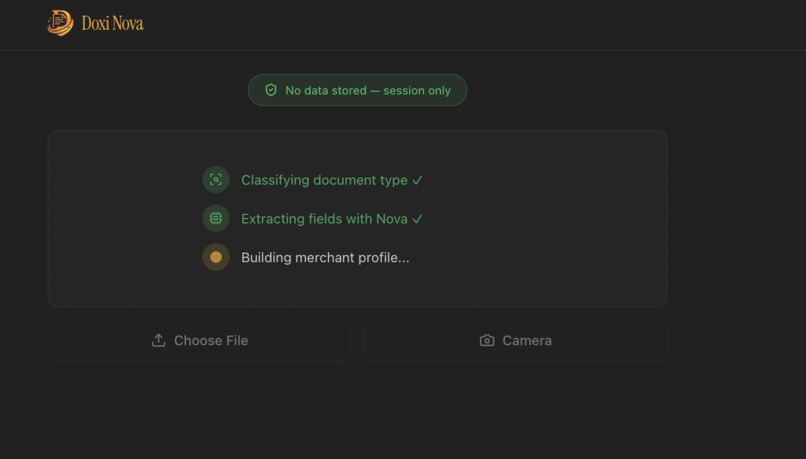
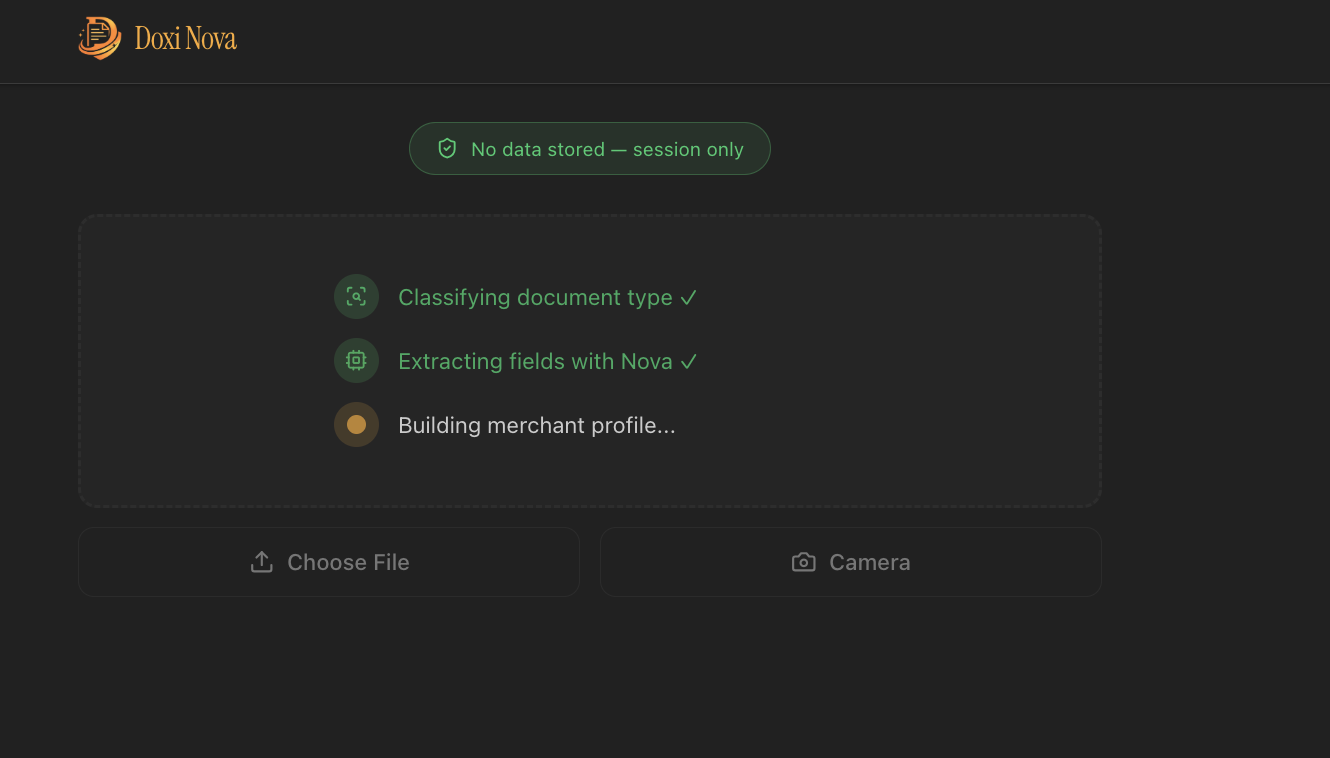
Extraction Pipeline 2
-
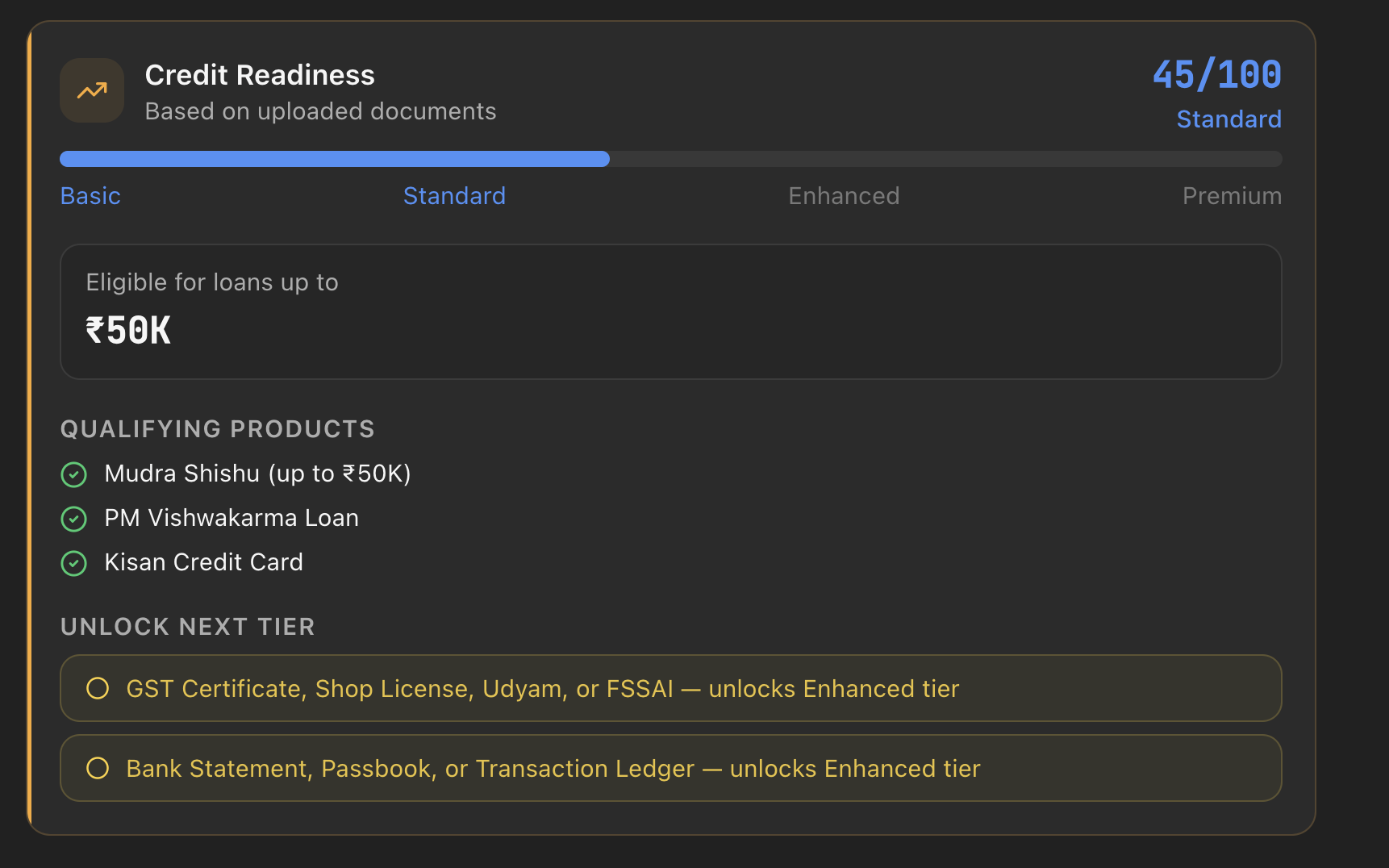
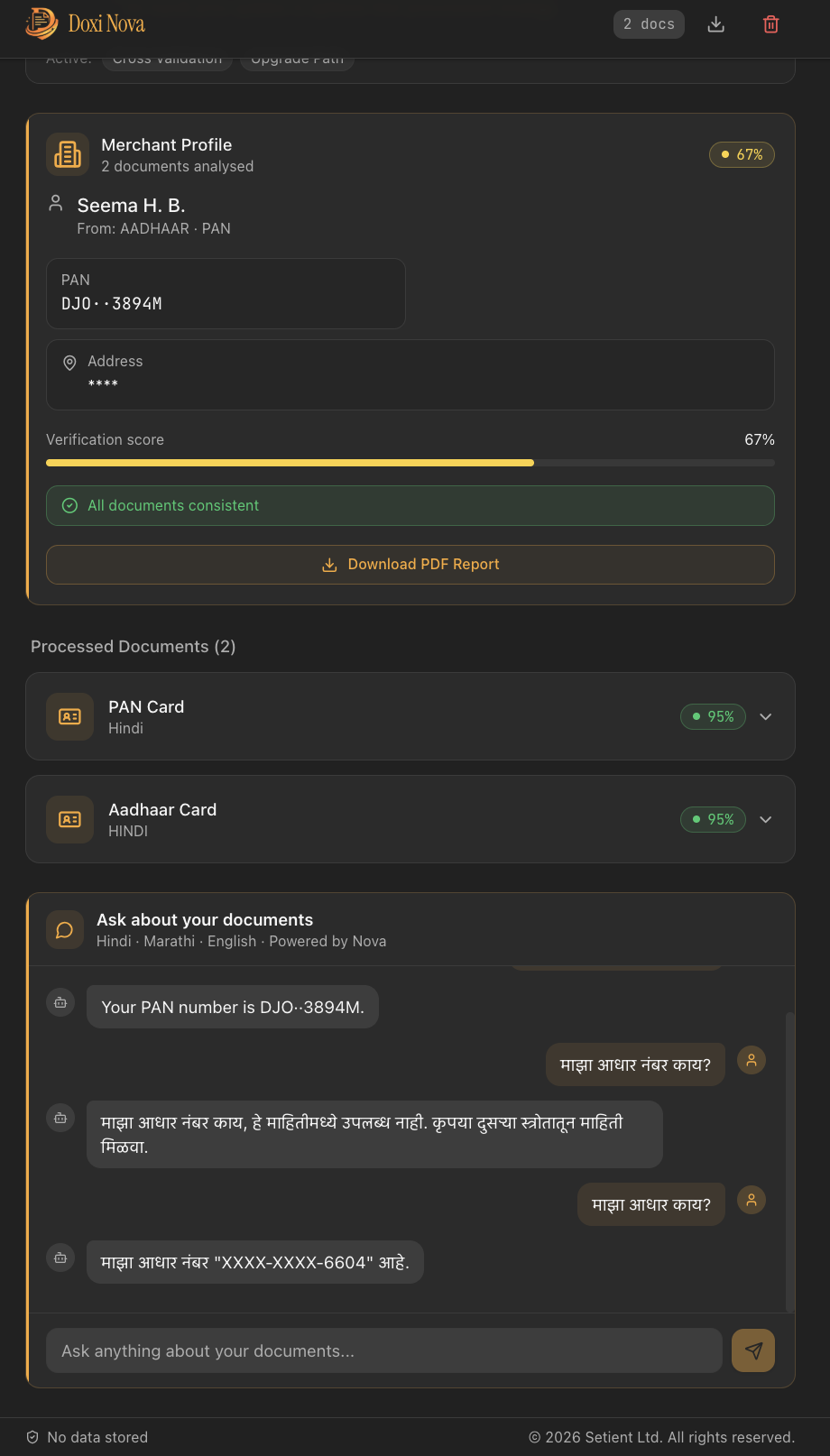
Credit Readiness Card
-
Merchant Card with Chat
-
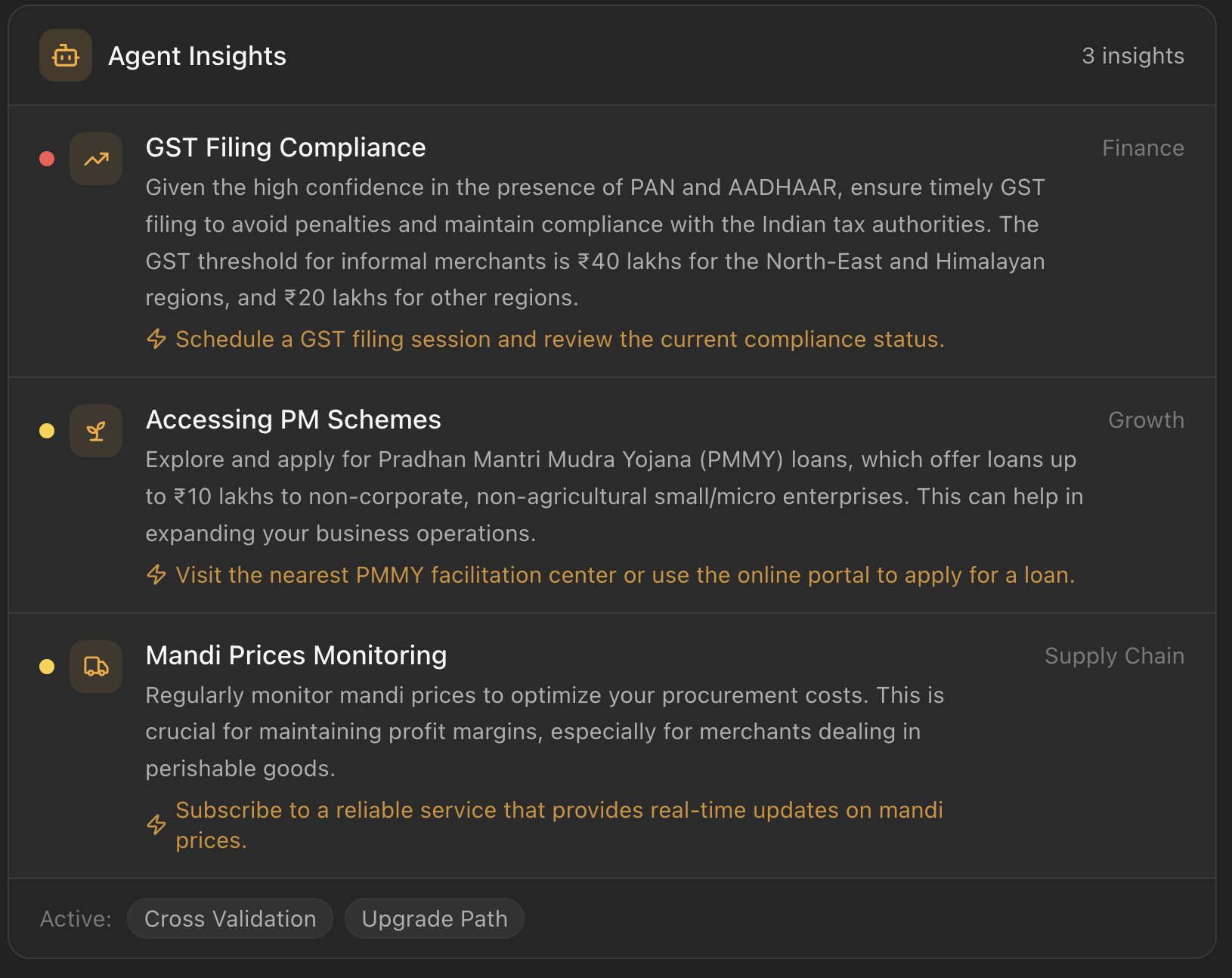
Agent Insights
Inspiration
India has 190 million+ micro-merchants, street vendors, kirana shop owners, farmers, who handle identity and business documents daily but have no digital tools to process them. When a microfinance/co-operative credit institution asks a street vendor for an Aadhaar card, PAN card, a GST certificate, or a bank statement, the vendor photographs them on a ₹15,000 phone and WhatsApps the images. What happens next is manual: a loan officer squints at blurry JPEGs, types out numbers by hand, and cross-checks fields across documents one by one. This process takes days, introduces errors, and excludes millions of creditworthy people, simply because the document manageemnt isn't efficient. Then there is no track of what happens to these shared documents.
We asked: what if the document intelligence came to them — privately, in their language, without requiring a bank account, a laptop, or a stable internet connection?
Doxi Nova was born from that question. It is the document ingestion layer for Open Credit Initiative, our open-source credit scoring initiative for India's informal economy. Verified document data flows directly into merchant profiles that enable fair, transparent credit access — without traditional banking infrastructure.
What It Does
Doxi Nova is a privacy-first document intelligence pipeline. A merchant photographs any document on a phone. Within seconds, Doxi Nova:
- Classifies the document — Aadhaar, PAN, GST certificate, bank statement, handwritten ledger, mandi receipt, or any of 15 supported types
- Extracts every structured field — names, numbers, dates, addresses, transaction entries, line items — with a per-field confidence score on each value
- Masks PII before any response leaves the server — Aadhaar to
XXXX-XXXX-NNNN, bank accounts toXXXX-NNNN, PAN toABC··1234F, names to first name + initials, addresses to city and state only, dates of birth with day masked - Validates across documents — fuzzy name matching across Aadhaar, PAN, and Voter ID; GSTIN and PAN format verification; cross-document consistency scoring
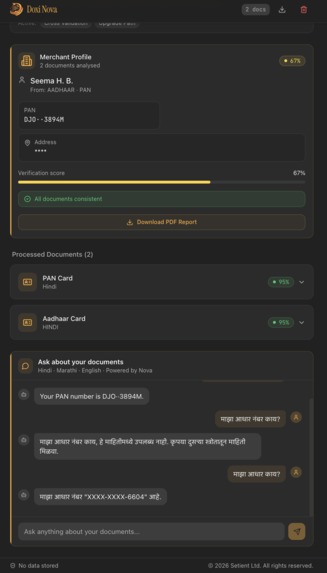
- Builds a merchant profile — a single structured view aggregating name, Aadhar, GSTIN, PAN, and address from all session documents, with a weighted verification score
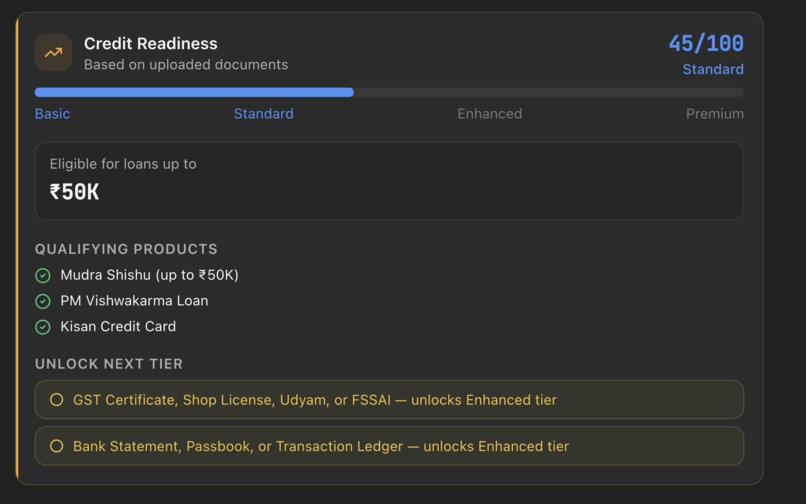
- Scores credit readiness — a 0–100 score across four tiers (Basic → Standard → Enhanced → Premium) mapped to real Indian government credit schemes: PM SVANidhi, Mudra Shishu/Kishore/Tarun, PM Vishwakarma, CGTMSE, Kisan Credit Card. The system tells the merchant exactly which document to upload next to unlock the next tier.
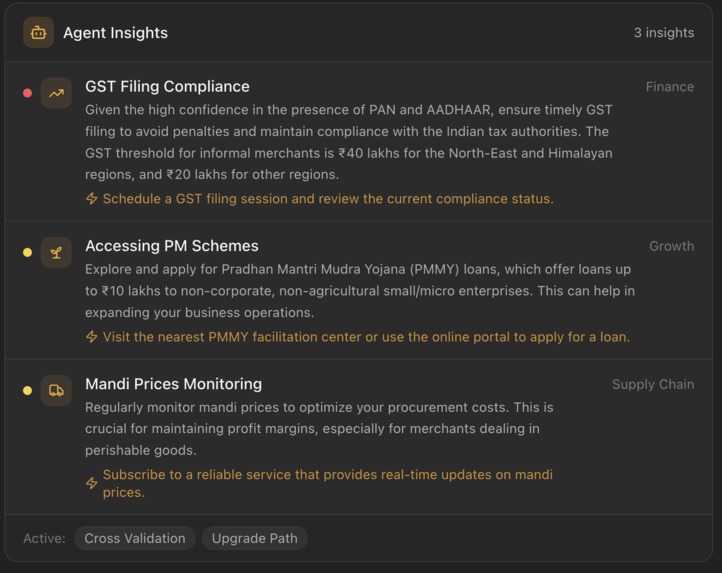
- Surfaces actionable insights — a proactive agentic loop analyses the session documents across five analytical dimensions (cash flow, price trends, government scheme eligibility, cross-validation gaps, credit upgrade path) and generates specific, India-context recommendations: PM scheme applications, GST filing deadlines, mandi price benchmarks, MSME benefit thresholds
- Answers questions about the documents — a multilingual chat interface lets merchants ask questions like "When does my shop license expire?" or "मेरी कुल क्रेडिट राशि क्या है?" and get answers sourced directly from the extracted data, never from model hallucination
All of this runs on a single model: Amazon Nova Lite (amazon.nova-lite-v1:0). No OCR pipeline, no NLP post-processing, no third-party APIs.
The model choice is deliberate. We are building for people who earn ₹300–₹800 a day. The cost of processing a document cannot exceed what makes economic sense for a micro-loan. Nova Lite processes a full document — classify + extract + insights — for under $0.001. That is not a performance compromise; it is a design constraint derived directly from the users we serve. Using a more expensive model when Lite solves the problem would price this solution out of the market it exists to help.
Document Coverage
| Category | Types |
|---|---|
| Identity | Aadhaar, PAN, Voter ID (EPIC), Driving Licence |
| Business | GST Certificate, Shop License, FSSAI, Udyam Registration |
| Financial | Bank Statement, Passbook Page, UPI Screenshot |
| Informal/Agricultural | Handwritten Ledger, Mandi Receipt, Kaccha Bill |
How We Built It
Core AI Pipeline — Amazon Nova Lite (Multimodal)
Nova Lite is the single reasoning engine for everything. We use its native multimodal input to pass documents as images alongside text prompts, avoiding a separate OCR stage entirely.
Merchant photographs document
↓
Image + classification prompt → Nova Lite → { doc_type, confidence, language }
↓
Image + extraction prompt → Nova Lite → { fields, per-field confidence }
↓
Context + insight prompt → Nova Lite (text-only) → { insights[] }
↓
Structured JSON → masked → session store → API response
Every prompt is written to a strict token budget : classification prompts ≤150 tokens, extraction prompts ≤300 tokens. Schemas are embedded inline — no separate system prompt that Nova would need to hold in context.
Architecture
- Backend: Python 3.11 + FastAPI. Though our open credit engine is built using spring framework, the document interface we chose python to integrate, deploy, maintain efficiently. All Bedrock calls are synchronous boto3 wrapped in
asyncio.to_thread()to stay non-blocking at the API layer. - Frontend: React 18 + Vite + TypeScript + Tailwind + shadcn/ui. Mobile-first at 375px minimum. Client-side image compression to <1MB before upload using
browser-image-compression. - Session layer: UUID-keyed in-memory store with 1-hour TTL and lazy eviction. No database, no disk writes for document data.
- Masking layer: Applied in
masking.pybefore any extraction result leaves the server — Aadhaar, PAN, account numbers, names, addresses, dates of birth, UPI IDs each have purpose-built masking functions.
Trilingual Extraction
Every extraction prompt explicitly handles Marathi, Hindi and English mixed-script, the real-world default for Indian merchant documents, not an edge case. A single Aadhaar card may have the address in Devanagari, the name in English, and the header in both. Nova handles this natively; we structured the prompts to expect and preserve it.
Graceful Degradation
Bad Nova output — truncated JSON, malformed response, Bedrock timeout — triggers exactly one retry with a simplified prompt targeting only the minimum viable fields. The retry result is returned with partial: true and error_flag: "simplified_prompt_used". The system never returns a 500 on model failure.
Agentic Insights Engine
The insights pipeline uses a two-stage design to avoid wasting Nova tokens on routing decisions:
- Python triage — deterministic tool activation based on the document types present in the session. Cash flow analysis activates on bank statements or ledgers. Price trend analysis activates on mandi receipts. Scheme eligibility activates on GST, UDYAM, Shop License, or FSSAI documents. No Nova call needed here.
- Context compression — each document is reduced to a single-line summary with only the fields relevant to the active tools (transaction totals, commodity and price, license expiry dates). This keeps the Nova context window tight.
- One Nova text call generates 3–5 structured insights scoped to the active tools, with category, urgency, and a specific action step calibrated to the Indian informal economy context.
Credit Readiness Scoring
The scoring model (we have complex scoring model, but here we have used a simpler one) reflects how Indian microfinance institutions actually evaluate informal merchants:
| Tier | Score | Max Loan | Qualifying Schemes |
|---|---|---|---|
| Basic | 25–40 | ₹5,000 | PM SVANidhi, SHG Group Loan |
| Standard | 40–65 | ₹50,000 | Mudra Shishu, PM Vishwakarma, Kisan Credit Card |
| Enhanced | 65–85 | ₹5,00,000 | Mudra Kishore, MSME Working Capital, Business LOC |
| Premium | 85+ | ₹10,00,000 | Mudra Tarun, CGTMSE Term Loan, Invoice Discounting |
The system also generates a personalised upgrade path — the specific documents missing to reach the next tier — grounded in what the merchant has already uploaded.
Cross-Document Validation
The profiles service uses Python's difflib.SequenceMatcher to fuzzy-match names across identity documents (Aadhaar, PAN, Voter ID, Driving Licence). A confidence-weighted verification score combines identity document quality, business document presence, and name consistency across sources. GSTIN and PAN are validated against their canonical formats ([0-9]{2}[A-Z]{5}[0-9]{4}[A-Z]{1}[0-9A-Z]{1}Z[0-9A-Z]{1} and [A-Z]{5}[0-9]{4}[A-Z]{1}) with explicit field-level error reporting.
Challenges We Ran Into
Real-world document quality: Indian merchant documents are often crumpled, partially obscured, photographed in dim light, or show mixed scripts within a single field, many times hard to read. We invested the most time here iterating extraction prompts against real document photographs until Nova could reliably extract from documents that a traditional OCR pipeline would reject. The hardest category is handwritten ledgers: column alignment is inconsistent, amounts use regional numeral systems, and entries may be partially illegible. We designed the extraction to return aggregate totals even when individual row coverage is incomplete.
Designing prompts that are both tight and complete: Nova's accuracy on extraction degrades when prompts are verbose. We found that embedding the full JSON schema inline — rather than describing fields in prose, consistently produced better-structured output at lower token cost. Every prompt is the result of several schema iterations.
Separating privacy from functionality: The more context we give Nova, the better it extracts. But sending full document context without masking creates a privacy problem, we are processing documents that carry Aadhaar numbers and bank account details. The masking layer runs server-side before any result is stored in the session or returned in an API response. This forced a clean architectural separation: Nova sees the image, the API response shows only masked data, the session store holds only masked data.
Latency on 3G/4G: Our target users are on budget Android phones on mobile data. Client-side image compression to <1MB before upload was the single biggest latency win, cutting upload time by 60–70% on slow connections. (we need to do the field validations). On the backend, the two Nova calls (classify then extract) run sequentially by design; we return the classification result immediately so the frontend can show the document type while extraction completes.
Multilingual output structure: A document might contain English headers, Hindi body text, and numerical tables with Devanagari digits. Nova handles the reading well; the harder problem was structuring the output consistently across these variations. We resolved this by embedding the JSON schema directly in the prompt and setting temperature to 0.1 for extraction, which strongly biases Nova toward the specified structure.
What We Learned
A single multimodal model eliminates an entire pipeline stage. The traditional approach to document intelligence is OCR → field detection → NLP → extraction, with error accumulating at each handoff. Nova classifies, reads, and reasons about a document in one call. This just doesnt improve the latency, it removes a possiblitiy of many bugs entirely.
Privacy-first architecture is not a constraint; it is a forcing function for cleaner design. Session-scoped processing, no raw document persistence, and masking at the server boundary produce better-separated code with clearer data flow. The DPDP Act (India, 2023) and UIDAI Aadhaar guidelines are not compliance overhead, this align with what ideal architecture looks like for this use case.
Confidence scores change the relationship between the system and its user. Returning a confidence value with every extracted field means downstream consumers, credit evaluators, aggregators, the merchant themselves, can decide what to trust and what to verify. A low-confidence address does not block a loan application; it flags a specific field for manual review. This is in our opinion more honest and more useful output than a binary pass/fail. We would like our user to see, understand and verify themselves and know where they stand and why, if they could improve the result.
Tool activation via deterministic code is more token-efficient than asking the model to decide. For the agentic insights engine, we initially considered prompting Nova to select which analyses were relevant. A simple Python predicate over document types proved faster, cheaper, and more predictable. Nova's value is in reasoning over content, not in routing decisions that can be made from metadata.
Model selection is a user empathy decision, not just a technical one. We chose Nova Lite because we are designing for users earning ₹300–₹800 a day and cannot absorb costs passed down through the stack. The right model is the one that solves the problem at a price the user's world can sustain — not the most capable one available. Nova Lite solves the problem.
Building for the bottom of the pyramid demands harder engineering, not simpler. The edge cases — crumpled documents, mixed scripts, 3G latency, handwritten entries — are the main cases for our users. Every design decision was evaluated against a street vendor on a ₹5,000 phone in poor light, not against a clean scan on a desktop.
What's Next
Doxi Nova is the data acquisition layer for Open Credit — open-source credit scoring for India's informal economy. Verified document intelligence flows into merchant profiles that become the foundation for fair, transparent credit access without traditional banking infrastructure. Our motto is "Democratizing Credit Access".
Our immediate roadmap:
- Expanded document coverage: crop receipts, land records (7/12 utara), micro-insurance papers, ration cards
- Voice-guided document capture: using Nova's audio capabilities to walk low-literacy merchants through the capture process in Hindi, Marathi, or regional languages
- Batch processing API: for aggregators and microfinance institutions processing merchant onboarding at scale
- Pilot with merchant aggregators: targeting kiranatech platforms and MFI field officers across tier-2 and tier-3 Indian cities
The cost model is the mission, building ground up. Nova Lite processes a full document — classify, extract, validate, insights — for under $0.001. At ₹0.08 per document, this pipeline can run inside a microfinance/co-operative/credit society institution's per-application cost envelope without passing any fee to the merchant. Affordability is not a stretch goal we plan to reach with scale; it is a constraint we designed to from the start, because the people this serves cannot absorb cost that gets passed down to them. At 190 million potential merchants, even fractional penetration represents a meaningful reduction in the manual document burden that currently sits between India's informal economy and credit access.
Built With
- 2
- amazon
- amazon-web-services
- bedrock
- boto3
- css
- fastapi
- lite
- nova
- python
- react
- shadcn/ui
- tailwind
- typescript
- vite


Log in or sign up for Devpost to join the conversation.