-
-
Brain is still downloading...
-
Plan
-
At the end
-

Thanks!

Concept
Every machine learning starts from downloading...
Inspiration
- We are young, dumb, and free, so we want to get ourself busy.
- We are a group of students who are interested in applying Machine Learning into what we are studying (Material Sciences and Chemistry). This year, TMLCC is focused on predicting CO2 absorption by Metal Organic Frameworks (MOFs) .
- It was a good chance to apply chemical intuition into determining the CO2 capture capability of MOF-based materials
- It gonna be fun.
How we built it
The approach taken in our group can be divided into 2 parts: Features Extraction and Modeling
Features Extraction
There are feature extraction based on CIFs and machine learning model predicting the CO2 working capacity of Metal-Organic Frameworks (MOFs)
- Original - volume [A^3], weight [u], void_volume [cm^3/g], CO2/N2_selectivity, heat_adsorption_CO2_P0.15bar_T298K [kcal/mol], all Linkers
- From .cif file - Canonical SMILES, Surface Area, VSA, Topology, Pore Area, Void Fraction, Overlapping sphere, Grid point approach, Pore size distribution (These were calculate by supercomputer from the National Supercomputing Centre, Singapore)
- From Coulomb Matrix - Functional group 1 eigen 1-3, Functional group 2 eigen 1-3, Metal linkers 1 eigen 1-10, Organic linkers 1 eigen 1-10, Organic linkers 1 eigen 1-10.
Models
The most exciting part, maybe?
Big thanks to these libraries
from lightgbm import LGBMRegressor
from catboost import CatBoostRegressor
# Find the imposter
import torch
import tensorflow as tf
import torch.nn as nn
import torch.nn.functional as F
from sklearn.preprocessing import MinMaxScaler
from torch.utils.data import DataLoader, TensorDataset
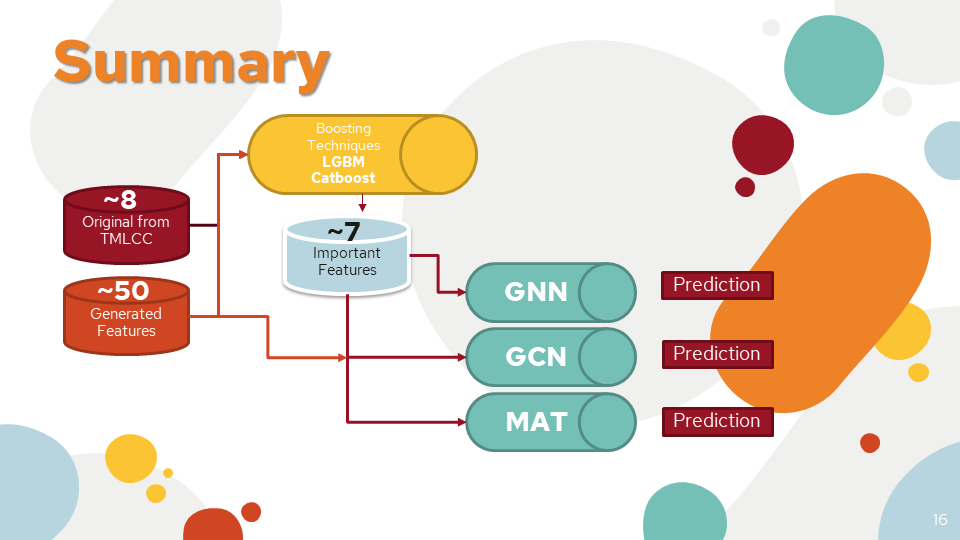
Used a tool called lazy prediction to save time while experimenting with various regression techniques. We also tried to perform the regression using a neural network. As a result, LightGBM and Catboost offered the most accurate prediction.
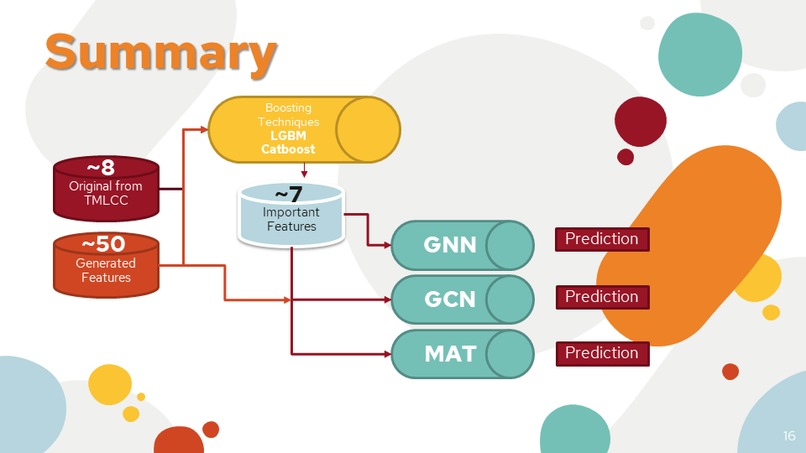
Found the most important feature out of all of them. We discovered 8 more features that have an influence on our regression model.
Some delicious codes
train_data['poreV_OSEp2'] = train_data['poreV_OSE']**2
train_data['head_selectivity'] = train_data['CO2/N2_selectivity'] / train_data['heat_adsorption_CO2_P0.15bar_T298K [kcal/mol]']
train_data['inverse_heat_adsorption'] = 1 / train_data['heat_adsorption_CO2_P0.15bar_T298K [kcal/mol]']
train_data['specific_vol'] = 1 / train_data["density"]
train_data['mof_vol'] = train_data['specific_vol'] / train_data['void_volume [cm^3/g]']
train_data['selectivity_heat'] = train_data['heat_adsorption_CO2_P0.15bar_T298K [kcal/mol]'] / train_data['CO2/N2_selectivity']
train_data['sum_mo2'] = train_data['metal_e1'] + train_data['orlink1_e1'] + train_data['orlink2_e1']
Another technique that was inspired from the form of the molecules. As we can see, the molecule can be seen as node and edge. From our original data, it was not reasonable to use a 2D convolutional network without extracting the 2D data. So, we used the canonical smiles to find the molecular fingerprint, adjacency matrix, and molecular size. And train the Graph Neural Network model or GNN.
Graph Convolutional Networks or GCN. Like GNN, we extracted the features out of canonical smiles and used the Convolutional Neural Networks to train to model inorder to receive the information about neighborhood relationship.
Molecular Attention Transformers or MAT, which were inspired by the previous two approaches, were also tested in the data. Because this model includes an attention layer that captures the locational region and uses position-wise feed forward to highlight the area of the molecule that is critical to the prediction.
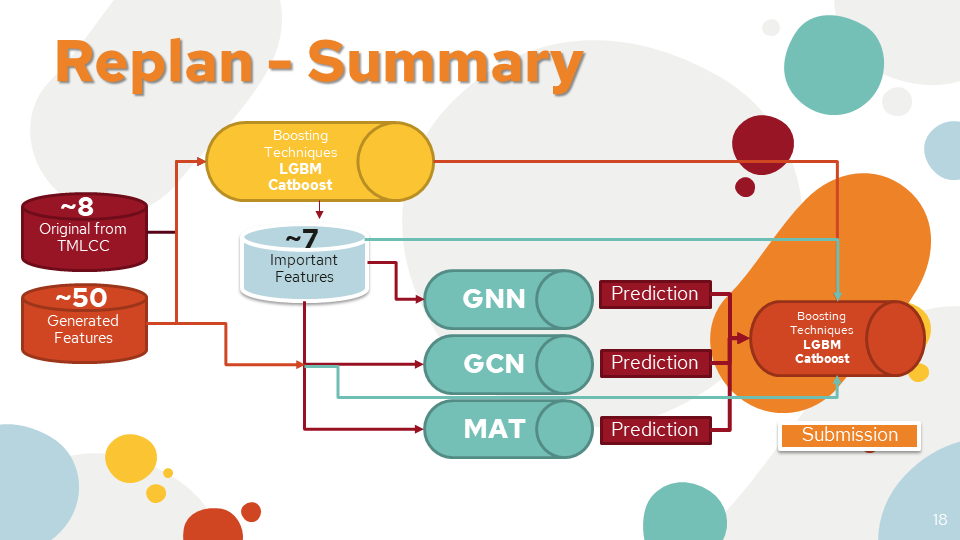
Summary We use both original and generated features to the boosting technique for finding the important features. And then recode the GNN, GCN, and MAT from scratch with multiple network inputs of extracted smiles (2D, 3D features) and our features. And train in both Colab Pro + and Deepnote Pro Machine.
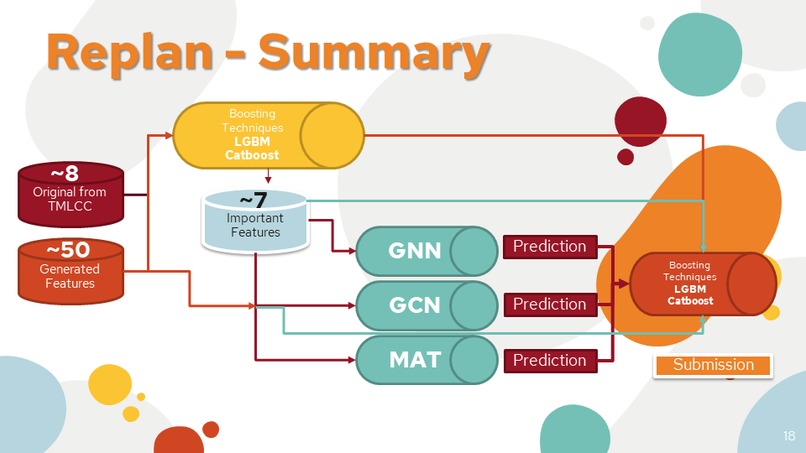
We hope these models will make good results. But everything wasn't gone as plan...
But at least we have tried!
- At that time the model is already learned. Use the output of the training models as one of the features in LightGBM and CatBoost.
Challenges we ran into
Laziness- Features extraction is too long to be done serially with provided resources.
- On this note, we faced an issue implementing multiprocessing modules in parallelization as few samples are skipped with no error given and thus resulting in missing points once the result is exported. We applied a band-aid solution to this issue by recalculating missing points serially.
- The calculation of dipole moments and polarizability, hypothetically relates to van der Waals binding between surface and nonpolar molecules such as CO2, is based on DFT, which are too computationally expensive to be done, and thus are dropped from our project.
ท้อแท้ ทำไม่ได้- Deepnote cut out the run time, so... sad, and go back to above bullet point. Moving on in circles.
Accomplishments that we're proud of
- Everything
- You know, the moment when your codes were all working. One step accomplishment was there.
What we learned
- Everything about this competition was new. So that's what we learned.
What's next for downloading...
- Good sleep
- Write the medium in order to be some knowledge to the world. (Woah!)
Miscellaneous
References
Bucior, B. J.; Rosen, A. S.; Haranczyk, M.; Yao, Z.; Ziebel, M. E.; Farha, O. K.; Hupp, J. T.; Siepmann, J. I.; Aspuru-Guzik, A.; Snurr, R. Q., Identification Schemes for Metal–Organic Frameworks To Enable Rapid Search and Cheminformatics Analysis. Crystal Growth & Design 2019, 19 (11), 6682-6697.
Trepte, K.; Schwalbe, S., porE: A code for deterministic and systematic analyses of porosities. Journal of Computational Chemistry 2021, 42 (9), 630-643.
My everything
The medium
- https://link.medium.com/4GwJ7dBfXjb
- https://link.medium.com/eUF7679eXjb
- https://link.medium.com/qSnpMe3eXjb
- https://www.nature.com/articles/s41524-021-00554-0.pdf
- https://chemintelligence.com/blog/machine-learning-descriptors-molecules
Github link
GNN, GCN, Several MOFS
- https://github.com/thunlp/GNNPapers
- https://github.com/masashitsubaki/molecularGNN_3Dstructure
- https://github.com/divelab/MoleculeX/blob/molx/Molecule3D/build_yours.ipynb
- https://github.com/deepchem/deepchem/blob/master/deepchem/models/torch_models/gcn.py
- https://github.com/scidatasoft/mof/blob/master/matfeaturizers.py
- https://github.com/arosen93/QMOF
Transformers
- https://github.com/ardigen/MAT
- https://arxiv.org/abs/2002.08264
- https://pubs.acs.org/doi/10.1021/acscentsci.9b00576
Acknowledgements
- The computational work for this article was partially performed on resources of the National Supercomputing Centre, Singapore (https://www.nscc.sg)
- Google Colab Pro +
- Deepnote Pro Machine
More details
In the video with our text-to-speech friend! Enjoy!

Log in or sign up for Devpost to join the conversation.