Inspiration
It is 11 PM the night before an exam. The textbook is open. The problem is unsolved. The teacher is unreachable. Every result online either gives the final answer with no explanation, or redirects to a subscription paywall.
This is not an edge case. This is the default experience for students who study outside of school hours.
The gap is not a lack of information — the internet has more information than any student could process. The gap is the absence of explanation. The difference between an answer and understanding is a patient, step-by-step breakdown of why something is true. That kind of explanation has historically required a human tutor, which costs money, or luck, which cannot be relied upon.
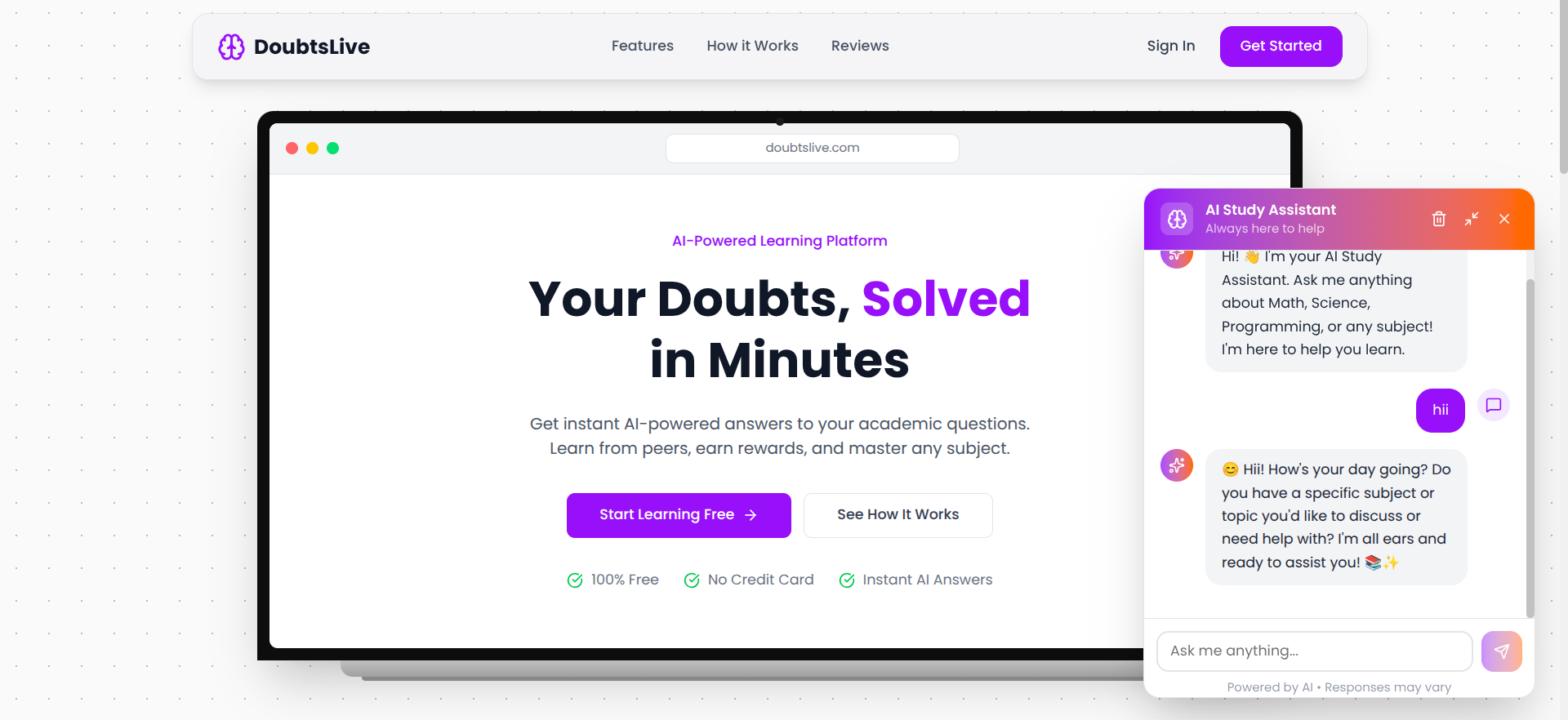
DoubtsLive was built to make that explanation available to every student, at any hour, regardless of what they can afford.
What it does
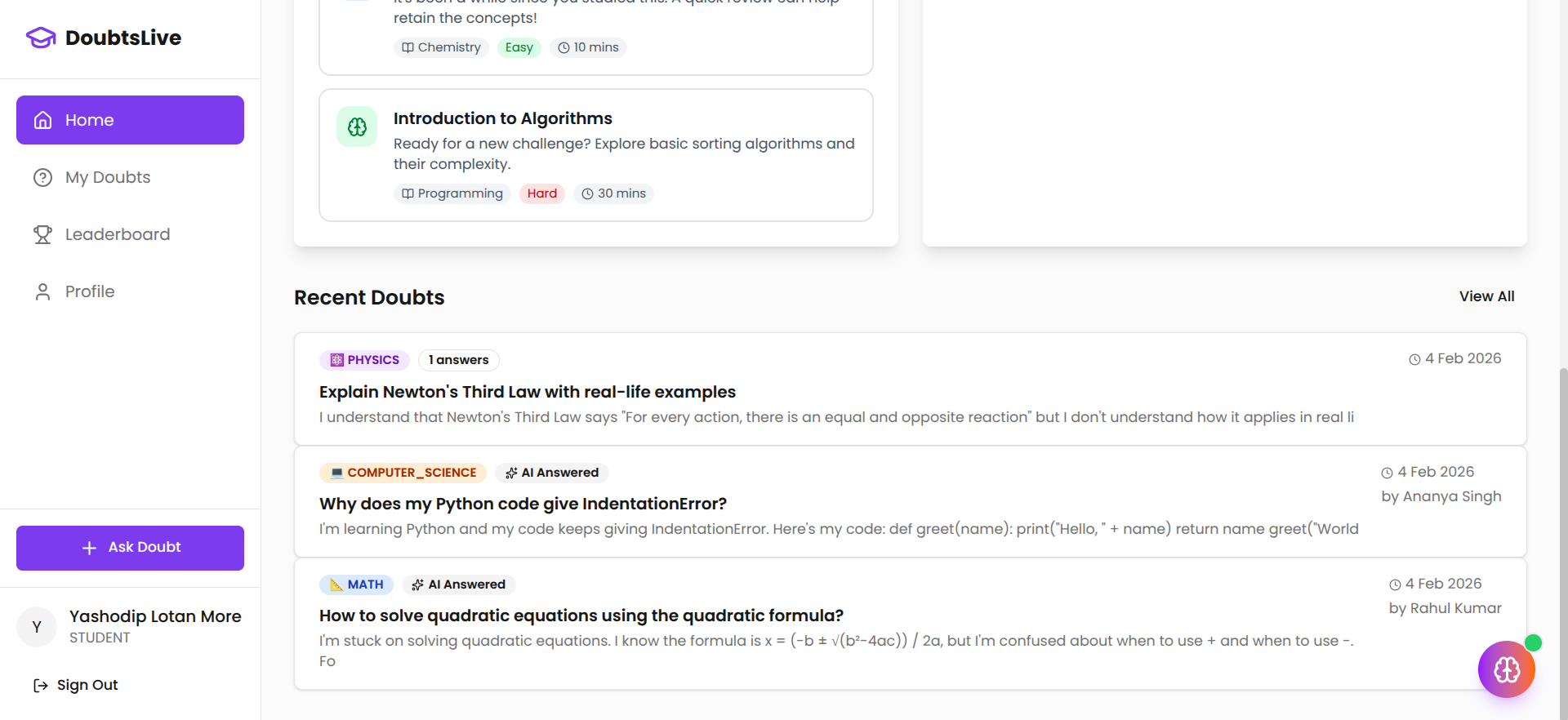
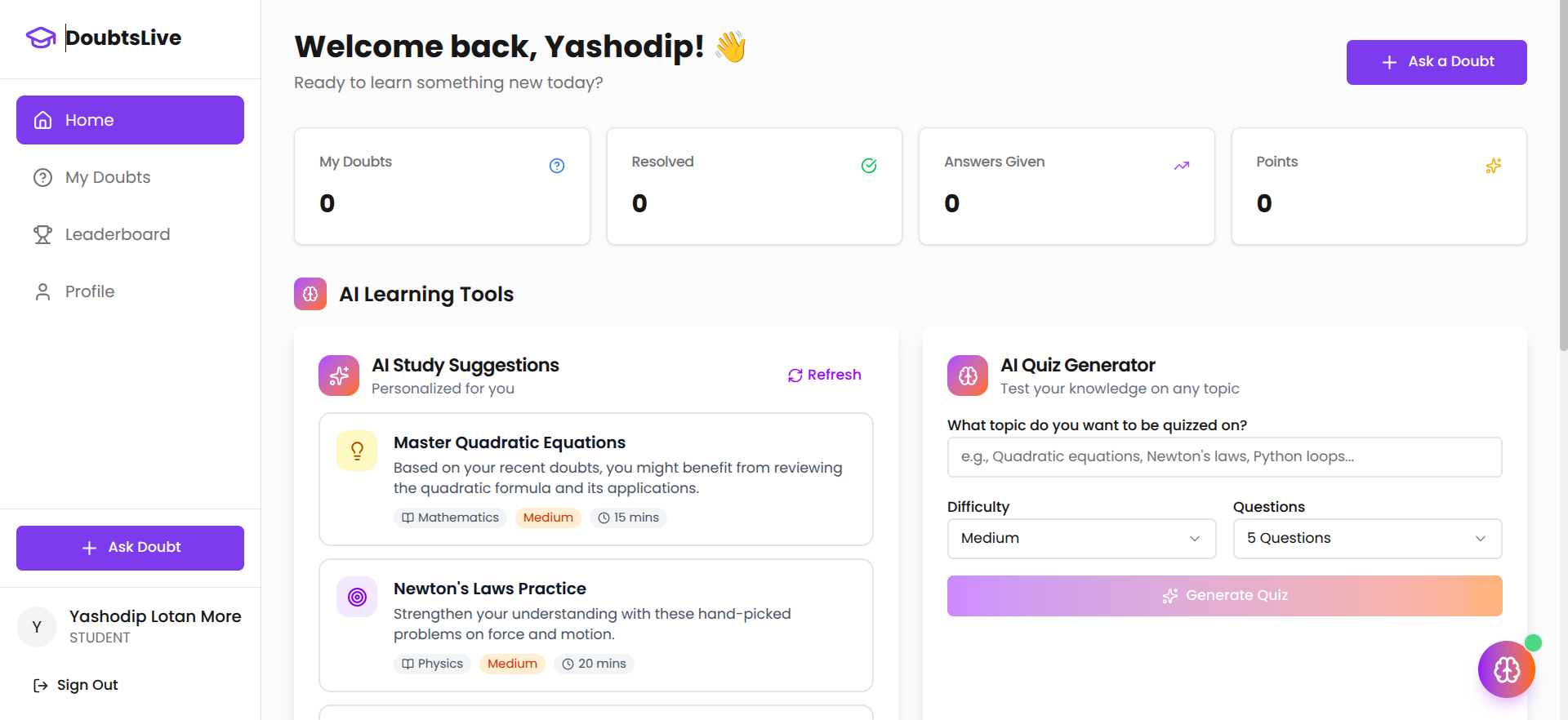
DoubtsLive is a doubt-solving platform for students that combines three layers of support: instant AI explanation, peer collaboration, and teacher-verified quality assurance.
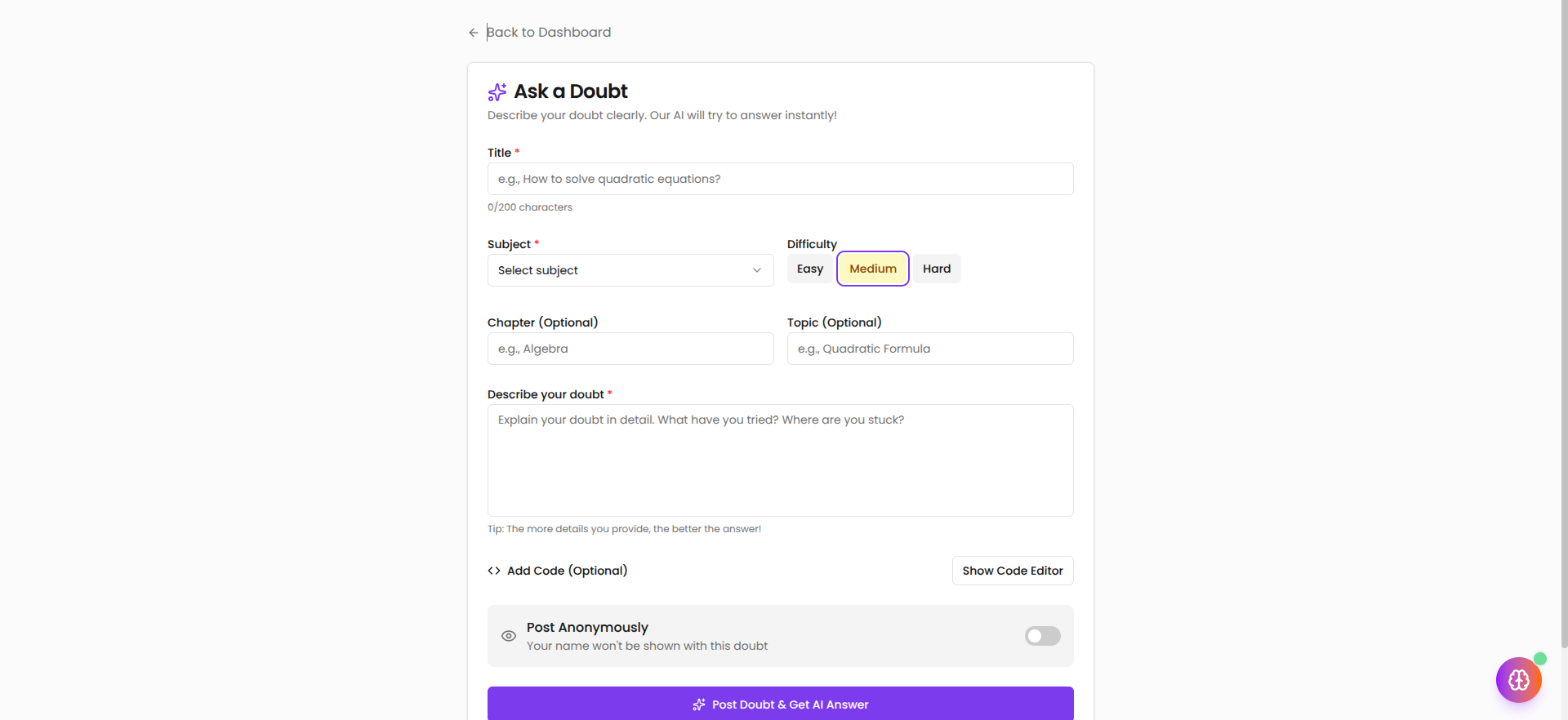
A student posts a doubt — in text, an image, or a code snippet. The AI engine responds in under two seconds with a structured, step-by-step explanation tailored to the subject. The doubt is simultaneously visible to peers and verified teachers, who can contribute their own answers. Every answer can be upvoted. Teachers can formally mark answers as verified, creating a trust signal for students who need to know which explanation to rely on.
Subject-aware AI is a core part of the system. A calculus question is handled with formal notation and proof structure. A computer science question gets code output and error tracing. A chemistry question gets reaction mechanisms. The model is not given a single generic prompt — it receives a subject-specific system context that changes how it structures its response.
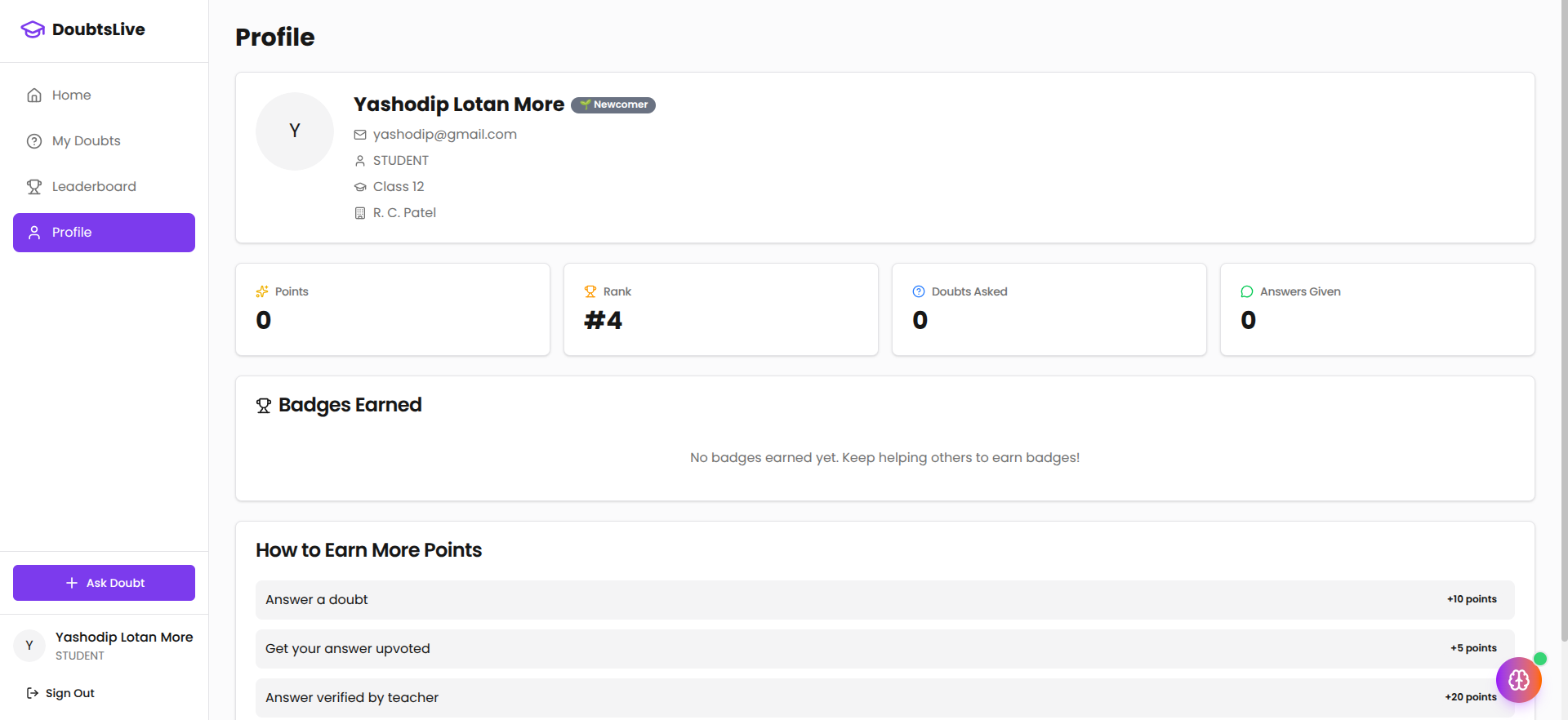
The platform includes a gamification layer designed to sustain participation without rewarding low-effort behavior:
| Action | Points |
|---|---|
| Posting a doubt | 1 |
| Answering a doubt | 3 |
| Answer accepted | 10 |
| Answer verified by teacher | 15 |
| Receiving an upvote | 2 |
Teacher verification carries the highest reward deliberately. A student who earns 15 points for one verified answer has more incentive to write one high-quality response than to post five low-effort ones for 15 points total — with far more risk of getting nothing.
A badge system creates identity around contribution: First Answer, Problem Solver, Verified Expert. Badges are not decorative. They change how users are perceived on the leaderboard and anchor repeat behavior.
How we built it
The stack was chosen to move fast without accumulating technical debt that would prevent the platform from scaling.
Next.js 16 (App Router) Frontend and API layer
TypeScript Full type safety across client and server
PostgreSQL via Neon.tech Serverless relational database
Prisma ORM Schema-first, type-safe database queries
NextAuth.js Authentication with role-based session handling
Groq — Llama 3.3 70B LLM inference for AI answers
Tailwind CSS + shadcn/ui Component library and styling
Uploadthing Image attachment uploads
Vercel Deployment and edge functions
The AI pipeline in lib/ai.ts follows four sequential steps for every doubt submitted:
- Domain classification — the model identifies the subject area from the text
- System prompt construction — a subject-specific prompt is assembled that sets the expected response format, depth, and notation
- Streaming inference — Groq streams tokens back in real time, making the response feel instantaneous even before it completes
- Confidence signal — the response includes a confidence estimate; when confidence is below threshold, the UI surfaces a prompt to also post the doubt for peer review
The database schema is deliberately flat. Doubt, Answer, User, Badge, and Upvote are separate models with clean foreign key relationships. Teacher verification is a boolean on the Answer model rather than a separate verification table — this keeps read queries simple and avoids joins that would slow down the feed.
The gamification engine is event-driven. Point updates and badge eligibility checks are triggered as side effects of write operations. Badge logic in lib/badges.ts is a pure function that takes a user's action history and returns a list of newly earned badges — no database reads required at evaluation time.
Role-based access is enforced at the middleware layer. Teacher routes and verification endpoints check session role before the request reaches the handler. There is no client-side gate that could be bypassed.
Challenges we ran into
Prompt engineering is a design problem, not a technical one
The first version of the AI integration produced correct answers that students found useless. A student stuck on a limits problem does not need to be told the answer is 1. They need to understand what a limit is asking, why the standard form matters, and what technique applies. The answer without that scaffolding teaches nothing.
We rewrote the system prompt four times. Each iteration added more structure to the required output format: a concept explanation, a worked step sequence, a note on prerequisite knowledge, and a suggestion for related topics. By the final version, the AI response read like a tutor — not a calculator. The content of the model did not change. Only the instructions changed.
Preventing gamification abuse
An early test session showed users posting one-sentence answers repeatedly to accumulate points. The system was being gamed in exactly the way a poorly designed incentive structure invites.
The fix was structural, not technical. We weighted the reward curve so that the highest-value actions — accepted answers and teacher verification — require genuine quality. Rate limiting prevents submission floods. Minimum length validation blocks one-liners. The point structure now makes the rational strategy identical to the desired behavior: write answers worth verifying.
Session and role management across an async app
NextAuth sessions in a Next.js 16 App Router project require careful handling. Middleware runs at the edge before rendering, which means role checks must be synchronous and cannot depend on database reads. We extracted role information into the JWT at sign-in and validated it in middleware, avoiding database round-trips on every protected route.
Accomplishments that we are proud of
The platform is live at doubts-live.vercel.app — not a mockup or a demo environment, but a working product any student can use right now.
Authentication, AI inference, gamification, file uploads, teacher verification, and a role-based dashboard were all built and deployed within the hackathon window. Every feature works. The system handles the full flow from doubt submission to AI answer to peer response to teacher verification without breaking.
The subject-aware prompt system produces explanations that are meaningfully different across domains. A trigonometry question and a Python debugging question receive structurally different responses — not the same template with different nouns.
The gamification layer survived adversarial testing without collapsing. The incentive structure holds.
What we learned
The prompt is the product. When building with a language model, the single highest-leverage variable is not the model, the infrastructure, or the interface. It is the system prompt. Two applications using the same model and the same hardware can produce outputs that feel completely different based solely on how the task is framed. Prompt engineering is not a workaround — it is a core engineering discipline.
Incentive design requires adversarial thinking. Any system that rewards behavior will attract users who optimize for the reward rather than the intent. The only reliable defense is making the reward structure align the two — so that the rational path and the desired path are the same path. We learned this by watching it fail and fixing it.
Working software beats polished demos. The live deployment is the most persuasive argument for the platform's viability. A functioning product that real users can interact with communicates more than any description of what it would do if it existed.
What's next for DoubtsLive
Multimodal input is the immediate next step. Most students work on paper. A student should be able to photograph a handwritten problem and receive an explanation without retyping anything. The model supports image input. The upload pipeline already exists. This is buildable.
Personalized weak-area detection is the medium-term goal. Every doubt a student posts is a data point about what they do not yet understand. Over time, the platform accumulates a map of gaps for each user. That map should drive proactive recommendations — if a student has asked three questions about differentiation in a week, the platform should surface related concept modules without being asked.
Multilingual support is necessary for meaningful reach. The students who most lack access to quality tutoring are often not learning in English. The model handles Hindi, Tamil, Bengali, and Spanish. The interface does not yet. That is a gap we intend to close.
Institutional deployment — private instances for schools and coaching centers, with their own verified teacher pools and subject configurations — is the path toward sustainable impact at scale.
The problem is real. The students exist. The platform works. The question is how far it can go.
$$ \text{Learning Outcome} = \frac{\text{Explanation Quality} \times \text{Accessibility}}{\text{Time to Answer}} $$
Every architectural decision in DoubtsLive is an attempt to make that ratio larger.
Built With
- groq
- next.js
- postgresql
- prisma
- tailwind
- typescript
- uploladthing

Log in or sign up for Devpost to join the conversation.