-
-
Base Website allowing input of images of prescriptions
-
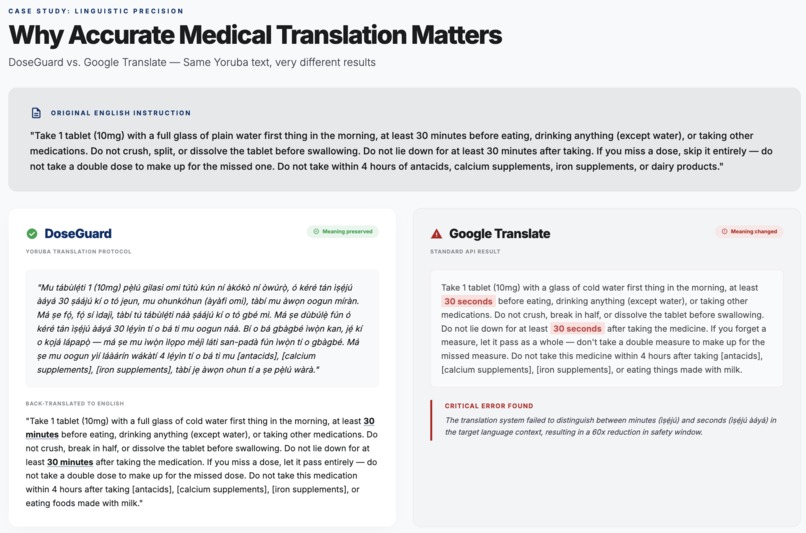
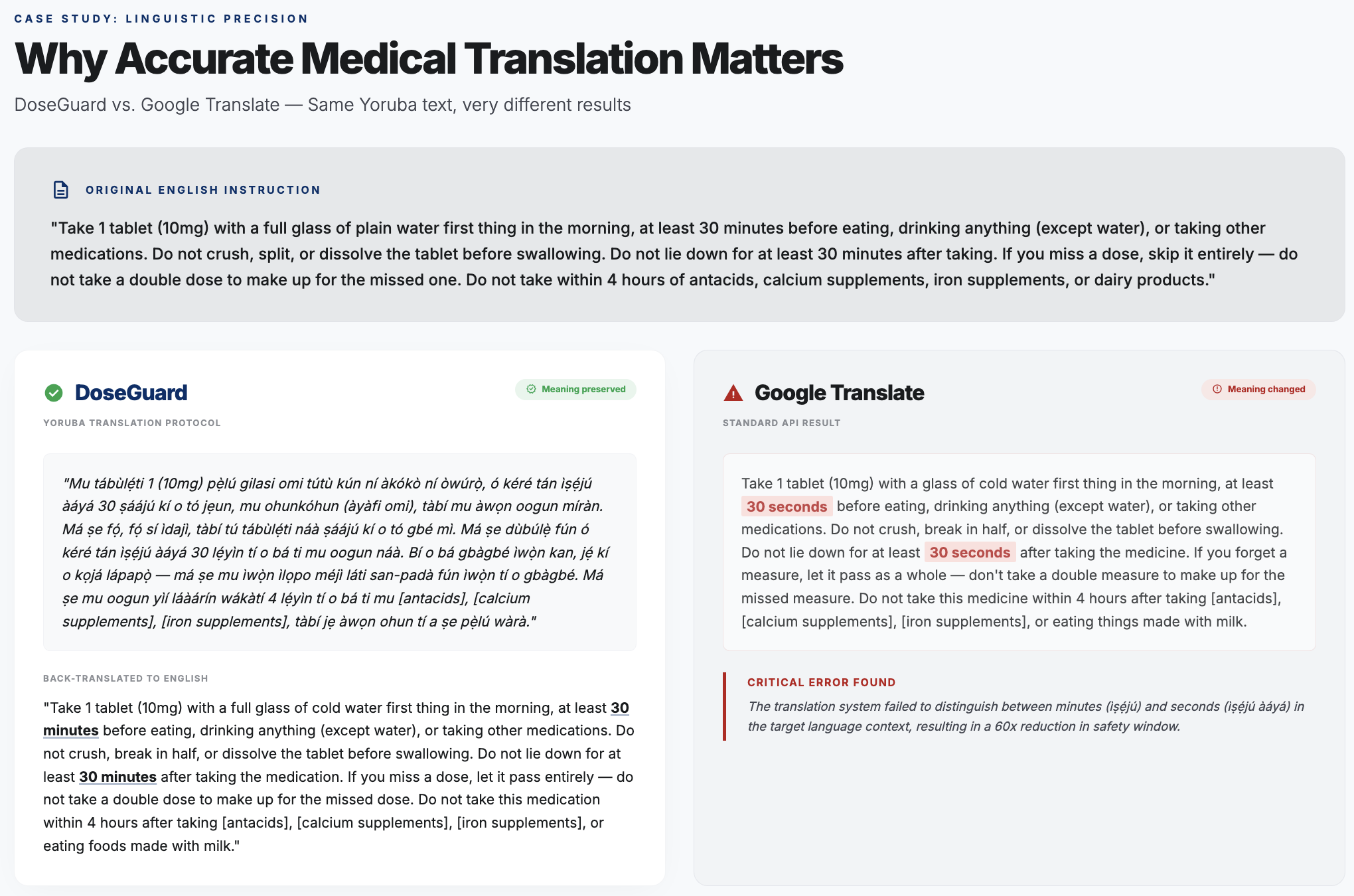
DoseGuard vs. Google Translate
-
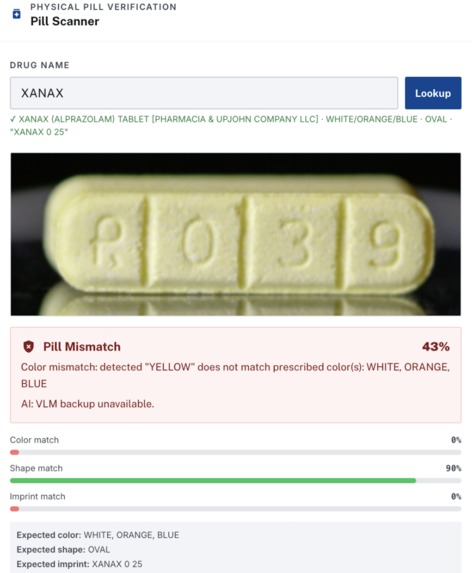
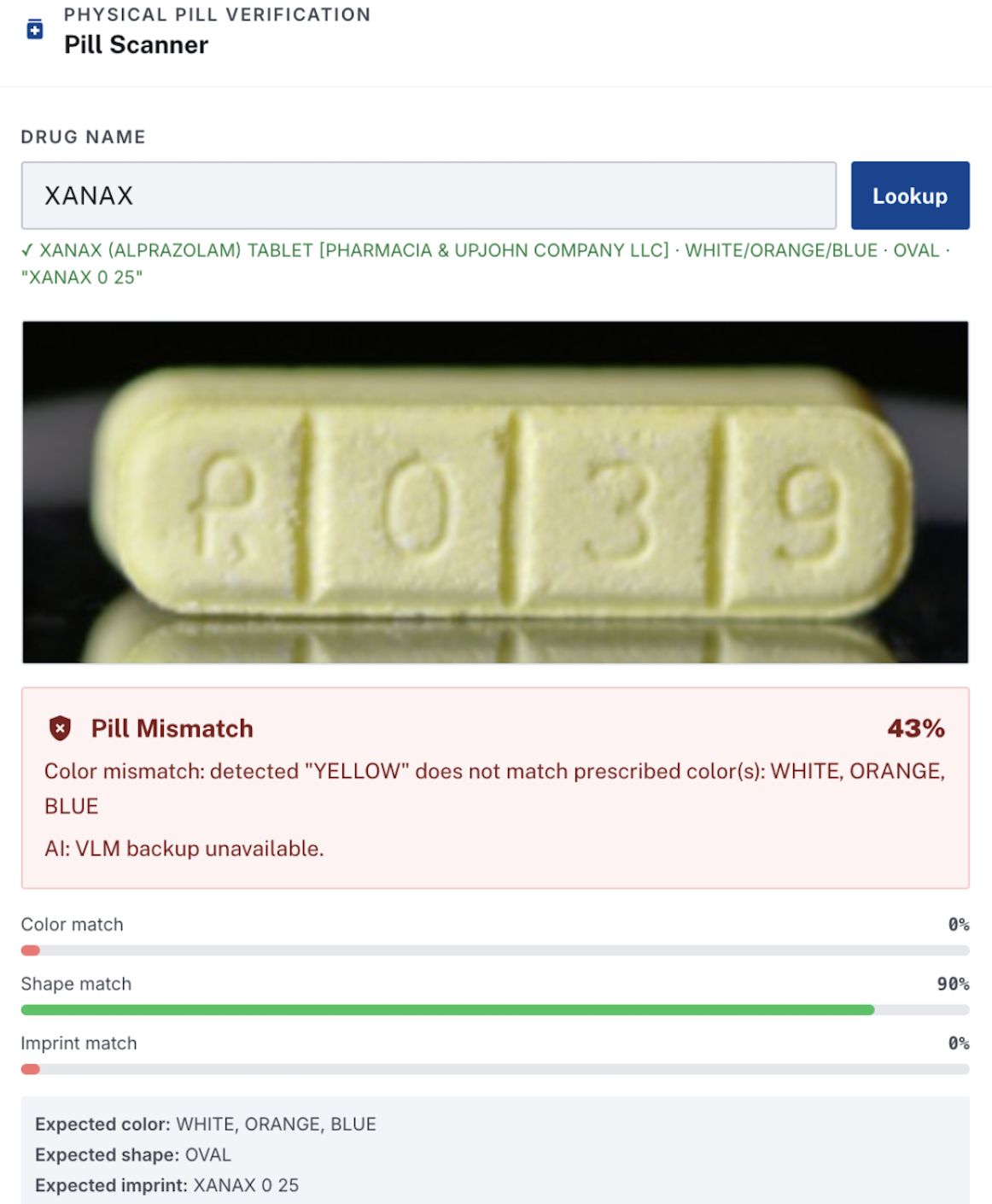
Fake Xanax pill that our pill scanner detected and flagged
-
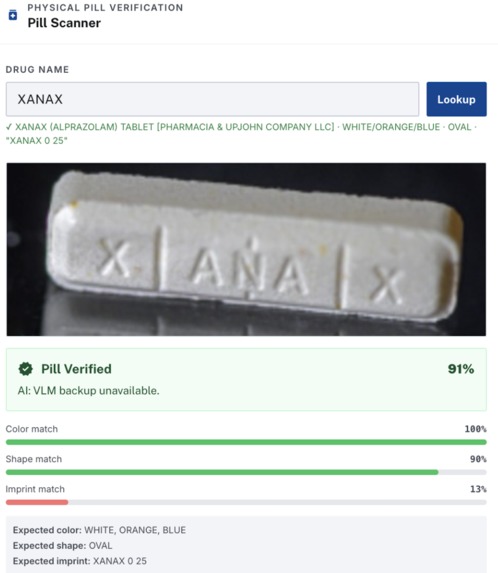
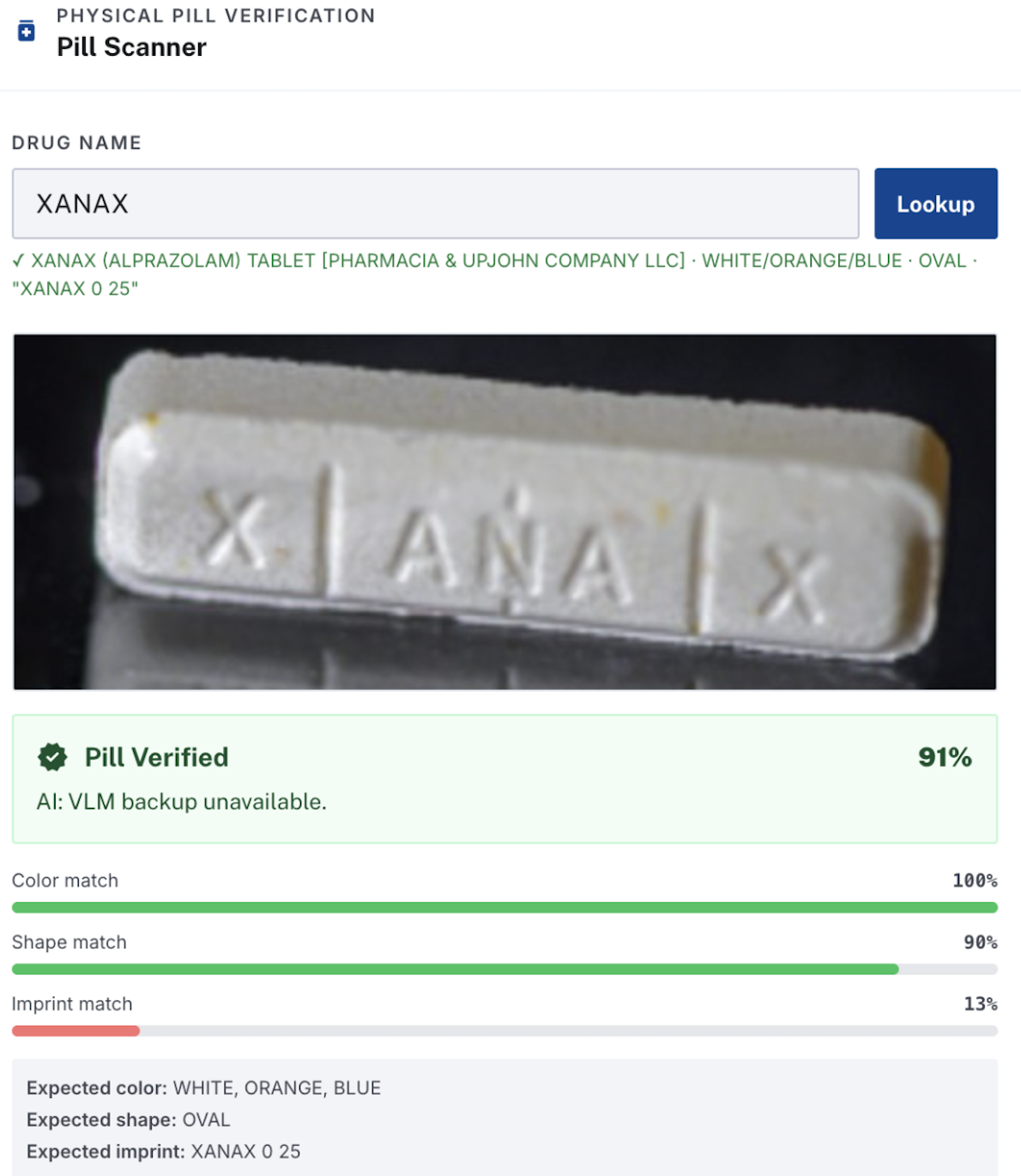
Real Xanax pill that our pill scanner referenced from government dataset to show high confidence
Inspiration
The global crisis of medication mistranslation is a systemic failure of patient safety that disproportionately affects hundreds of millions of people who receive healthcare in a language they do not speak fluently. This group, mainly comprised of migrants, refugees, indigenous community members, and those in post-colonial nations where the healthcare system operates in a "prestige" language like English or French rather than their native tongue, is constantly at risk. When a patient cannot accurately read or interpret a medication label, the line between a therapeutic dose and a fatal one often hinges on a single mistranslated word or a misunderstood frequency. The gravity of this issue is underscored by the devastating impact of pharmaceutical mismanagement in sub-Saharan Africa, where approximately 116,000 additional malaria deaths annually are attributed to substandard or "fake" drugs, a crisis compounded by the inability of patients to verify the legitimacy or correct usage of their medication through official channels.
This danger is most acute for populations speaking "low-resource" languages that are structurally neglected by modern machine translation. Many of these languages, such as Yoruba, which is spoken by over 50 million people across Nigeria, Benin, and Togo, utilize tonal orthographies where meaning is derived from tiny accent marks called diacritics. In Yoruba, a missing sub-dot or a misplaced accent can silently transform a critical clinical instruction; for example, a numeral meaning "three tablets" can be misread by a standard AI as "six tablets," effectively doubling the dose with no visible error message or warning to the user. Similar risks are prevalent in Haitian Creole, Quechua, and dozens of other languages that have small digital footprints and remain chronically underserved by both global healthcare systems and Natural Language Processing (NLP) research. These populations are forced to rely on generic translation tools that were never designed to handle the precision required for medical care, leading to "clinically significant errors" that can cause organ failure, toxicity, or death.
The scale of this problem is staggering yet largely underreported. The World Health Organization (WHO) estimates that medication errors harm 1.3 million people annually in high-income countries alone, where medical infrastructure is robust and translation services are more accessible. In lower- and middle-income countries (LMICs), where translation infrastructure is weak, and literacy rates further complicate the challenge, the true scale of harm is unknown but undoubtedly far larger. Currently, there is no systematic safety layer between a translated discharge instruction and the patient who receives it—no mechanism to ensure that what the doctor intended is what the patient actually does at home. Patients are essentially left to gamble with their health, relying on a fragmented understanding or community members who may also struggle with the source language.
DoseGuard is that safety layer.
Who It's For
DoseGuard is designed for use at the clinical interface: pharmacists preparing discharge instructions, nurses handing off care to a patient's family, community health workers in multilingual clinics, and NGO staff in low-resource settings where a certified medical interpreter isn't available. It's not a consumer product. It's a verification tool for the people who bear professional responsibility for making sure a patient gets the right instruction in a language they can actually understand.
How It Works
DoseGuard analyzes the safety of a translated medication instruction through a multi-layer AI pipeline.
OCR and Source Verification
The process starts with an Ensemble OCR Architecture that runs four distinct engines — Mistral, EasyOCR, Rapid OCR, and Tesseract — to extract text from a physical medication label. Rather than trusting a single model, the system cross-verifies their outputs and assigns a confidence score based on consensus.
That extracted text is then grounded against government-backed databases, primarily the FDA's Structured Product Labeling (SPL). DoseGuard checks that the drug name is legitimate and that the prescribed dosage falls within medically acceptable parameters. This verification happens before any translation or analysis.
Visual Pill Verification
Once the label text is confirmed, DoseGuard adds a physical check. The identified drug name is used to query DailyMed, a government-sanctioned database, which returns the official visual characteristics of that medication: shape, color, imprint, and size. If the user provides a photo of the actual pills, the system compares them against those specs to catch "wrong pill" errors before they reach the patient.
Semantic Extraction and Drift Analysis
Next, the instruction text is broken down into structured fields: drug name, dose, frequency, route of administration, duration, warnings, and contraindications. After translation, those same fields are extracted from the translated version and compared against the originals using canonicalization and numeric normalization.
This step catches things that are easy to miss: "1/2" misread as "1 to 2," a negation that dropped out of a safety warning, a frequency word that shifted meaning under translation pressure.
Diacritic Validation (Yoruba)
Yoruba meaning is carried not just by letters but by tonal accent marks. A missing sub-dot or gravity accent can silently change a numeral, a route of administration, or a frequency word with no visible error in the text. DoseGuard runs a dedicated diacritic validation layer that checks safety-critical terms — including words like gbe (swallow) and lọ (grind) — against a 22-entry checklist of numerals, frequency words, and clinical terms. This layer runs entirely independent of the back-translation pipeline.
AI Semantic Gate
Claude Haiku performs a back-translation check on every run. The translated instruction is independently converted back into the source language by a separate model instance with no knowledge of the original. If the back-translation preserves the clinical meaning, even with different phrasing or number formats, no flag is raised. If a genuine discrepancy surfaces, the instruction is flagged as unsafe.
Risk Scoring
The system aggregates drift across all layers into a weighted 0–100 score and assigns a risk level: low, medium, or high. High-risk results and all low-resource language translations automatically escalate to a clinician review recommendation.
Teach-Back Question
Every pipeline run ends with a plain-language comprehension question targeting the most safety-critical part of the instruction — something like "How many tablets will you take after your evening meal?" The user's response is verified against the extracted medical data, closing the loop between what the translation says and what the patient actually understood.
What Could Go Wrong, and the Safeguards We Built
The AI could hallucinate or mistranslate. Back-translation is designed specifically to catch this. The translated text is independently re-read by a separate model with no knowledge of the original, so any meaning that was lost, changed, or invented in translation shows up as a discrepancy in the comparison.
The safety check itself could produce false positives and erode trust. If clinicians see spurious warnings on every run, they'll start ignoring them. We spent significant effort eliminating noise: numeric normalization ("14 days" = "fourteen days"), frequency synonym collapse ("twice daily" = "two times a day"), medical synonym mapping ("avoid alcohol" = "do not drink alcohol"), and a final Claude Haiku semantic gate that confirms full-sentence equivalence before surfacing any issue. Every flagged issue should represent a genuine clinical concern.
The AI could fail silently, marking a dangerous translation as safe. All high-severity fields (dose, frequency, maximum daily dose) are checked deterministically before the AI gate is reached. Numeric drift and negation changes are caught by rule-based logic that can't be overridden by the semantic check. If the AI gate fails or times out, the fallback preserves any field-level issues already found.
Tonal diacritic errors are invisible to back-translation. A translation can back-translate perfectly in meaning while still being dangerous to read aloud or on paper. For Yoruba, we built a parallel diacritic validation layer that checks the translated text directly against a 22-entry checklist of numerals, frequency words, and clinical terms, entirely independent of the back-translation pipeline.
Low-resource languages have systematically lower translation quality. For Quechua, Haitian Creole, and similar languages, even a "passing" back-translation may not reflect true patient safety. We apply automatic risk escalation for these languages, so a translation with no detected drift is still flagged as requiring clinician review, not cleared as safe.
The system cannot verify what it cannot see. DoseGuard checks the text. It cannot check whether a clinician read the result, whether a patient understood the instruction, or whether the translation was used at all. That's why every result includes a teach-back comprehension question, the patient verification step that DoseGuard itself cannot perform.
Empowerment
DoseGuard is a decision-support tool, not an autonomous decision-maker. Every output is framed as a recommendation for a human to act on.
- Low risk results are marked "Safe to Use," but the disclaimer remains: this tool does not provide medical advice, and clinician judgment takes precedence.
- Medium risk results are marked "Use With Caution" and direct the clinician to review specific flagged fields before proceeding.
- High risk results are marked "Human Review Required." The tool will not clear a high-risk translation without a human in the loop.
The teach-back question at the end of every pipeline run is a deliberate reminder that the last safety check is always a human conversation: asking the patient to repeat the instruction back in their own words.
DoseGuard also preserves the role of certified medical interpreters. For low-resource languages, the tool explicitly recommends qualified interpreter review regardless of the technical risk score, because it acknowledges the limits of what machine translation can reliably achieve.
Ethical Considerations
We do not store patient data. The tool operates entirely in-session. No medication instructions, no translations, and no extracted fields are persisted beyond the current server process. The in-memory audit log resets on server restart.
We designed against automation bias. In safety-critical systems, there's a real risk that users defer to an automated result even when they have reason to doubt it. Every recommendation in DoseGuard is accompanied by a plain-language explanation of why the risk level was assigned and what the reviewer should specifically check, so a clinician is making an informed judgment, not rubber-stamping a score.
We were deliberate about which languages to support first. Rather than prioritizing high-resource languages where translation quality is already good, we focused on Yoruba, Quechua, and Haitian Creole, where mistranslation risk is highest and existing tooling is weakest. The MENYO-20k few-shot integration for Yoruba reflects a specific commitment to language equity: using community-developed linguistic resources to improve outcomes for a population that is systematically underserved by commercial NLP systems.
We do not claim to solve the problem. DoseGuard is one layer of a safety system that doesn't yet exist at scale. It is not a substitute for trained medical interpreters, bilingual clinical staff, or systemic investment in language access in healthcare. We built it to lower the floor on a dangerous gap, not to claim that gap is closed.
What We Learned
- Back-translation is a genuinely powerful safety primitive, but only if the prompt explicitly instructs the model not to correct or improve the translation. A faithful mirror is what you need, not a polished re-render.
- Small models like Haiku are remarkably robust at binary semantic equivalence checks, and far more generalizable than regex for open-ended paraphrase detection across diverse medical phrasing.
- Clinical abbreviation disambiguation matters more than expected. "Take 1 tab TID PRN pain" is nearly uninterpretable to a translation model, and to most patients.
- Tonal diacritics represent an entirely distinct category of translation risk that exists outside the back-translation pipeline. A translation can back-translate perfectly while still being dangerous to read.
- Streaming UX transforms the perceived latency of a 7-step AI pipeline from frustrating to transparent.
What's Next
- Language expansion — Somali, Hausa, Igbo, Amharic, Arabic, Mandarin, Hmong, and other languages with large medically underserved populations
- Tonal language coverage — extend diacritic validation to Hausa, Vietnamese, Thai, and other tone-marked orthographies
- FHIR integration — pull medication instructions directly from EHR systems
- Offline / low-bandwidth mode — for deployment in low-resource clinical settings without reliable internet
- Patient handout export — side-by-side bilingual PDF with both the original and translated instruction
- Aggregate analytics — a clinician dashboard showing drift patterns across a patient population or translation language pair, so teams can systematically identify which drug-language combinations carry the highest mistranslation risk
Built With
- claude
- next.js
- node.js
- react
- tailwind
- typescript

Log in or sign up for Devpost to join the conversation.