-
-
Voice AI Rating System
Inspiration
Deepfake-related losses hit $1.56 billion globally in 2025 - 3x the previous year - and Deloitte projects $40 billion by 2027. Voice cloning is the fastest-growing attack vector: a 3-second sample is enough to clone any voice. Banks are primary targets - impersonators call loan underwriting hotlines, bypass OTP and manual checks, and authorize fraudulent transactions before a human agent notices.
We saw three compounding problems:
- AI-generated content is indistinguishable to the human eye (and ear) - cloned voices, face-swapped photos, machine-written articles, synthetic videos. People cannot tell anymore.
- Online fraud scales faster than enforcement - millions of phishing domains, spoofed phone numbers, fake crypto wallets. Only 32% of victims even report it.
- No single product covers all modalities - existing tools detect one thing. GPTZero does text. Hive does images. Pindrop does voice. Nobody combines multi-modal AI detection with threat intelligence and voice + face biometrics in one platform.
DOSafe combines all of the above - and for Shinhan's SB8 challenge, it directly addresses their need: real-time caller identity verification using voice biometric AI. Existing solutions like Pindrop handle voice biometrics but lack multi-modal AI detection and threat intelligence integration.
What it does
DOSafe is a multi-modal AI detection and online safety platform - detecting AI-generated content across text, image, video, and audio, backed by a 3.93M+ entry threat intelligence database from 19 global sources.
AI Detection runs four parallel pipelines:
| Modality | What it detects | Key metrics |
|---|---|---|
| Text | ChatGPT, Gemini, Claude, 79+ LLMs | AUROC 0.99 - ModernBERT + E5-small/DivEye ensemble + Qwen LLM rubric judge |
| Image | DALL-E, Midjourney, Flux, SD3, 20+ generators | AUROC 0.99 - C2PA/SynthID + EXIF/DCT forensics + DINOv3/SPAI/CommFor ensemble |
| Video | Sora, Kling, Runway, synthetic video | 7-layer pipeline - frame ensemble + BEATs/mHuBERT audio + Qwen visual judge |
| Audio | Cloned voices, TTS systems, 79 speech synthesizers | AUROC 0.97 - BEATs + mHuBERT + SSLAM + EAT ensemble, 100% on Kling 3.0 |
Shinhan Use Case Coverage
DOSafe addresses 5 Shinhan use cases across 3 entities:
| Track | Use Case | DOSafe Solution | Coverage |
|---|---|---|---|
| SB8 | AI Voice Biometrics for Fraud Prevention | Voice enroll → real-time streaming verify → deepfake detect → threat intel check | Primary - Full |
| SF3 | Video Call eKYC Enhancement | Face enroll → liveness detection → deepfake detect → 1:N dedup matching | Full |
| SF7 | AI for ICT Cyber Security | Threat intel (3.93M+ entries) + AI detection across all 4 modalities | Full |
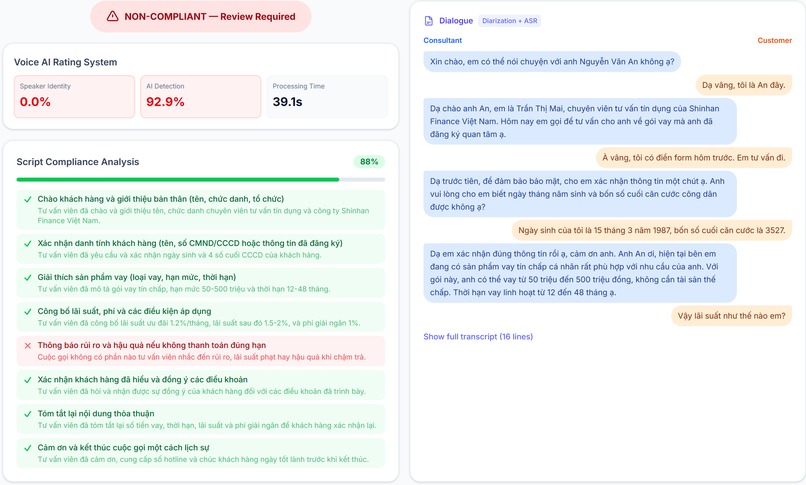
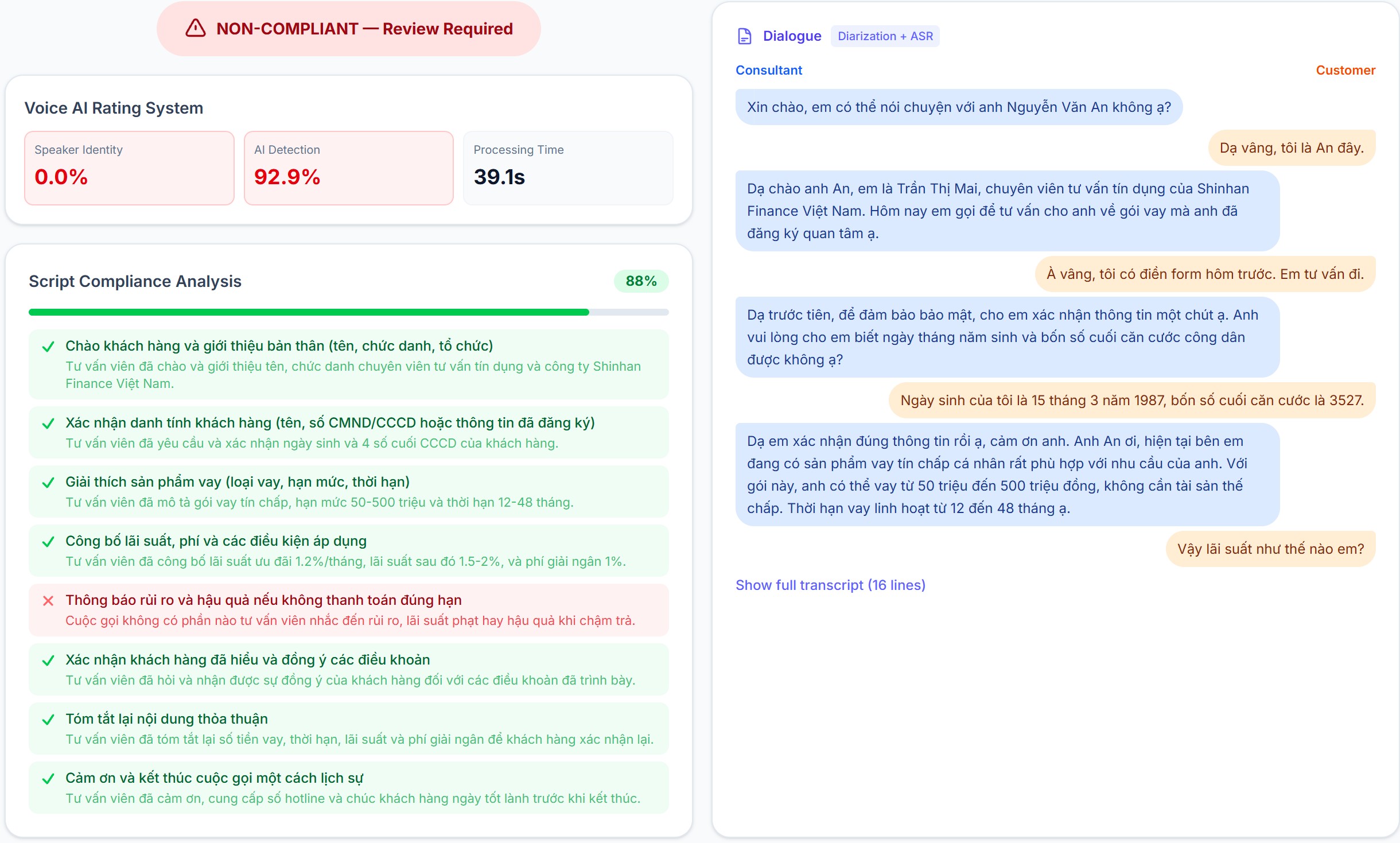
| SL2 | Voice AI Rating System | Upload recording → SSE streaming: speaker verify + AI detection + Qwen3-ASR transcription + speaker diarization + Qwen 3.5 script compliance with per-step LLM notes. Progressive rendering — verify scores appear in ~15s, compliance analysis follows ~9s later | Full |
| SF2 | Falsified Document Detection | Image AI detection pipeline (extensible to document forensics) | Extensible |
Call ID for Banking (SB8) - our audio + video pipeline extended with speaker and face verification for real-time call screening. This directly addresses Shinhan's SB8 use case: "Verify caller identity in real time during loan underwriting calls and hotline interactions using voice biometric AI."
| Layer | What it does |
|---|---|
| Voice Enrollment | Bind a customer's voiceprint to their identity during onboarding. Anti-spoofing runs in parallel - AI-generated or cloned voices are rejected before enrollment. |
| Speaker Verification | Verify caller identity by matching live audio against enrolled 768-dimensional voiceprint (ERes2Net 512d + w2v-BERT 256d). Individual model similarities displayed for transparency. |
| Face Enrollment | Bind a customer's faceprint using Alibaba Tongyi Lab's TransFace ViT (512-dim embeddings). DamoFD detects the face, FLRGB checks liveness from a single RGB frame (99% interception rate, no IR camera needed). |
| Face Verification | Verify caller identity during video calls by matching live camera frame against enrolled 512-dimensional faceprint. Anti-spoof rejects photos, screens, and masks. |
| Alibaba Cloud eKYC Fallback | When self-hosted face verification is unavailable, the system auto-switches to Alibaba Cloud eKYC API (CompareFaces, DetectLivingFace) - zero downtime for banking operations. |
| Live Video Mode | Camera captures frame every 3 seconds → face detection → anti-spoof → similarity match → real-time overlay with match status |
| Real-time Voice Streaming | WebSocket-based continuous verification - browser streams audio chunks every 2s, sequential verify loop prevents request pileup. First cycle runs full ensemble + LLM analysis, subsequent cycles deliver scores only for minimal latency. |
| Progressive Verification | Scores arrive in under 3 seconds; Qwen 3.5 security narrative follows asynchronously. Users see results immediately without waiting for LLM. |
| 1:N Face Dedup | Every enrollment triggers a cosine similarity search against all existing faceprints (pgvector HNSW index). Flags potential multi-account fraud when the same face enrolls under different identities. |
| Audio Anti-Spoofing | Detect AI-cloned or synthetic voices using MMS-300M-NDA (NII Yamagishi, 1107-language multilingual wav2vec2 backbone). Rejects if spoofing probability > 50% |
| Threat Intel Check | Cross-reference caller phone against 3.93M+ threat intel entries (scam, phishing, spam, fraud, malware) in real time |
| Compliance Check (SL2) | Upload call recording → SSE streaming with progressive rendering: partial results (~15s) show speaker verify + AI detection + transcript, complete results (~9s later) show diarized dialogue (Tư vấn viên / Khách hàng Telegram-style bubbles) + Qwen 3.5 script compliance analysis with per-step LLM notes → COMPLIANT/NON-COMPLIANT verdict (requires both script compliance AND speaker match) |
| Identity Binding | Voiceprint/faceprint linked to DOS.Me identity via biometric stamps - increases user trust score |
No OTP. No security questions. Voice and face are the credentials - verified in real time, protected against deepfakes.
Why Alibaba Tongyi Lab models? The voice and face biometric models all come from Alibaba's research labs, available on ModelScope under MIT/Apache 2.0 licenses. The 3D-Speaker project (ERes2Net, w2v-BERT) provides state-of-the-art speaker verification. DamoFD (ICLR 2023), TransFace (ICCV 2023), and FLRGB provide a complete face verification pipeline with built-in liveness detection - no IR camera required, ideal for browser-based video calls.
Threat Intelligence aggregates 3.93M+ entries from 19 sources, scoring entities with a weighted multi-source model that considers source reliability, data freshness, and corroboration across independent sources. No single source can override the verdict.
Available everywhere: web app (dosafe.io), Chrome extension, Telegram bot (@DOSafeBot), mobile app with call screening, and a Partner API for banks and fintech platforms.
Pre-existing vs. hackathon-built
Pre-existing components (built before April 11):
- Threat intelligence pipeline - 3.93M+ entries from 19 sources, auto-sync infrastructure
- Self-hosted Qwen 3.5-35B inference via vLLM on dedicated GPU
- AI detection microservices - text, image, video, audio deepfake detection ensembles
- Web platform skeleton (dosafe.io) and Go API gateway
Built during the hackathon (April 11–17):
- Voice enrollment and speaker verification pipeline (ERes2Net + w2v-BERT ensemble, pgvector storage)
- Face enrollment and verification pipeline (DamoFD + TransFace + FLRGB liveness)
- Real-time WebSocket voice streaming with sequential verify loop
- Progressive verification - fast scores first, async Qwen 3.5 analysis follows
- 1:N face dedup matching (pgvector HNSW cosine search across all faceprints)
- Anti-spoofing at enrollment - reject AI voices and spoofed faces before biometric registration
- Qwen 3.5 real-time call analysis integration (first cycle LLM, subsequent scores-only)
- Live video call mode with face verification overlay
- Call ID banking UI (enroll, verify, live call, video call, compliance check)
- Individual model score display (ERes2Net + w2v-BERT shown separately)
- Alibaba Cloud eKYC fallback for face verification
- Compliance check pipeline - Qwen3-ASR transcription + speaker diarization + Qwen 3.5 script compliance analysis (6 criteria) with per-step LLM notes
- Compliance SSE streaming - progressive rendering: partial results (~15s) then complete results (~9s later), diarized dialogue as Telegram-style chat bubbles
- Compliance 4-box grid UI - upload recording + script template on top row, voice scores + script compliance checklist below after check
- Kling 3.0 audio detection fix (retrained classifiers after accuracy dropped)
How we built it
| Layer | Technology |
|---|---|
| Web app | Next.js 16 + React 19 + TypeScript, deployed on Vercel |
| API Gateway | Go on Google Cloud Run |
| Database | Supabase PostgreSQL with pgvector for voiceprint/faceprint storage + HNSW index for 1:N dedup search |
| AI Inference | Self-hosted Qwen3.5-35B via vLLM |
| Detection | FastAPI microservices for each modality |
| Speaker Verification | ERes2Net-large (512d, 0.52% EER) + w2v-BERT-2.0_SV (256d, 0.14% EER) - 768d ensemble, weighted cosine similarity, voiceprints stored in pgvector. Models from Alibaba Tongyi Lab / 3D-Speaker (ModelScope, Apache 2.0) |
| Face Verification | DamoFD (ICLR 2023, face detection) + TransFace ViT (ICCV 2023, 512d recognition) + FLRGB (anti-spoof, 99% interception). All from Alibaba Tongyi Lab (ModelScope, MIT). Faceprints stored in pgvector. Alibaba Cloud eKYC as automatic fallback |
| Bot platform | Supabase Edge Functions (Deno) |
| Mobile | Flutter + native call screening (Android/iOS) |
Qwen is core to the solution:
LLM Meta-Judge - Qwen3.5-35B acts as a final judge after neural ensembles produce scores, catching edge cases with structured reasoning.
Real-time Call Analysis - during live voice/video calls, Qwen3.5-35B generates security assessments asynchronously after each verification cycle. Scores arrive instantly; AI narrative follows seconds later - no blocking.
Compliance Transcription + Diarization - Qwen3-ASR (DashScope) transcribes call recordings with speaker diarization (Tư vấn viên / Khách hàng), then Qwen3.5-35B analyzes transcript against 6 compliance criteria with per-step LLM notes. SSE streaming delivers results progressively — verify scores in ~15s, compliance analysis ~9s later.
Threat Intelligence Summarization - synthesizes multi-source threat reports into concise risk summaries for agents and end users.
Open-weight, on-premise ready. All models are MIT/Apache 2.0 (Qwen, Alibaba Tongyi Lab). The full inference stack deploys on a bank's own GPU servers - no data leaves the network, no vendor lock-in. Vietnamese banking regulation requires biometric data stays on-premise; DOSafe is built for this.
Why Qwen? Open weights, sub-second latency for real-time calls, zero per-query cost at scale, deployable anywhere. Alibaba Cloud Model Studio as optional fallback for zero downtime.
Challenges we ran into
- Kling 3.0 broke our audio detection - accuracy dropped from 95% to 30%. Retrained classifiers, redesigned heuristic. Result: 100% on Kling 3.0.
- Real-time streaming without request pileup - each verify takes 2-3s on GPU. Solved with sequential verify loop: first cycle full LLM analysis, subsequent cycles scores-only.
- Image false positives on compressed photos - recalibrated thresholds and added forensic pre-filters.
- Threat intel at scale - 3.93M entries from 19 sources with different formats required custom ETL with dedup, cluster linking, and corroboration-based scoring.
Accomplishments that we're proud of
- Four-modality AI detection - text, image, video, audio (AUROC 0.97–0.99). 100% Kling 3.0 detection - fixed from 30% in under a week.
- Real-time voice + face biometrics - WebSocket streaming verification during live calls, RGB-only anti-spoof (no IR camera), 1:N face dedup catches multi-account fraud, anti-spoofing blocks deepfakes at enrollment.
- Compliance SSE streaming with speaker diarization - progressive rendering shows verify scores in ~15s, then diarized dialogue (Telegram-style bubbles) + per-step LLM compliance notes ~9s later. No blocking — users see results as they arrive.
- 3.93M+ threat intel entries from 19 sources, auto-synced every 6 hours.
- Fully open-weight, on-premise ready - all models are MIT/Apache 2.0. Self-hosted inference = near-zero per-query cost and full banking regulation compliance.
- Six channels live - web app, Chrome extension, Telegram bot, mobile app, Partner API, DOS.Me identity.
What we learned
Ensemble diversity beats individual accuracy. No single model catches everything. Combining models that analyze different dimensions (temporal, spectral, semantic) creates robustness no single model achieves alone.
Open-weight models are non-negotiable for banking. Vietnamese financial regulation requires biometric data to stay on-premise. By using open-weight models (Qwen, ERes2Net, w2v-BERT, DamoFD, TransFace, FLRGB - all MIT/Apache 2.0), the inference stack deploys inside the bank's own infrastructure. No cloud API dependency, no data leaving the network, full regulatory compliance.
Freshness decay is essential for threat intel. A phone number reported 2 years ago is not the same threat as one reported yesterday by 3 sources. Time-weighted scoring turns a noisy blacklist into a calibrated risk engine.
New generators break old detectors. Every major model release can crater accuracy. Modular architecture where models can be swapped without rebuilding the system is essential.
Voice is the most natural biometric for banking. Customers already call - using their voice as the credential removes friction (no OTP, no security questions) while adding a layer that's harder to fake than knowledge-based authentication.
What's next for DOSafe
- Speaker diarization in live calls - extend diarization from compliance (done) to real-time streaming calls, detect mid-call speaker handoff attacks
- Upgraded face models - ArcFace/AdaFace recognition + multi-frame anti-spoof ensemble for production accuracy
- Scam message classifier - paste SMS/Zalo/Facebook messages → AI classifies scam type + auto-checks entities
- Multimodal scam detection - unified risk score combining image + text + entity signals in one analysis
- On-premise deployment - Helm + Docker Compose package for banks to run the full inference stack on their own GPU servers
- Bank integration SDK - drop-in library wrapping WebSocket streaming API with session management and compliance logging
Try it yourself
Web App - dosafe.io
Call ID (SB8 demo) - dosafe.io/call-id
- Sign in with a DOS.Me account (free)
- Voice Enroll - record 3+ seconds of speech → voiceprint created (768d embedding)
- Voice Verify - record again → similarity score + anti-spoofing + Qwen 3.5 analysis
- Live Call - start streaming → real-time scores update every 2-3s, LLM analysis on first cycle
- Face Enroll - allow camera → liveness check → faceprint stored. Try enrolling a second account with the same face to see 1:N dedup alert
- Video Call - live face verification with real-time overlay (VERIFIED / NOT MATCHED)
- Compliance Check (SL2 tab) - upload a call recording (or use Sample A) → SSE streaming shows verify scores first (~15s), then diarized dialogue + script compliance checklist with per-step LLM notes (~9s later). 4-box grid: upload + script template on top, voice scores + compliance results below
AI Detection - dosafe.io
- Text - paste any ChatGPT/Claude output → AI probability score + Qwen rubric analysis
- Image - upload a Midjourney/DALL-E image → forensic + neural ensemble verdict
- Audio - upload an AI-cloned voice sample → 4-model ensemble score
- Video - upload a synthetic video → frame + audio analysis
Entity Check - dosafe.io/check
- Enter a phone number, URL, email, or crypto wallet → multi-source risk score from 3.93M+ threat intel entries
Telegram Bot - @DOSafeBot
Open t.me/DOSafeBot and try:
/callid- open Call ID menu → voice enroll, voice verify, face enroll, face verify (send voice note or photo when prompted)/callreset- reset your enrolled voiceprint/faceprint/check +84xxxxxxxxx- check a phone number against threat intel/check https://example.com- check a URL for phishing/scam reports- Send any text message → AI-generated text detection
- Send an image → AI-generated image detection
- Send a voice message → AI-generated audio detection
Partner API
POST https://api.dos.ai/v1/dosafe/voice/verify
Headers: X-Api-Key: dsk_xxx
Body: FormData { file: audio.wav, user_id: "customer_id" }
Response: { verified, similarity, spoofing_risk, threat_score, analysis }
API documentation and key provisioning at app.dosafe.io.
Built With
- cloud-run
- cloudflare
- deno
- dinov3
- docker
- fastapi
- flutter
- go
- nestjs
- nextjs
- pgvector
- postgresql
- python
- pytorch
- qwen
- spai
- supabase
- typescript
- vercel
- vllm
- websocket


Log in or sign up for Devpost to join the conversation.