-
-
Main Landing Page
-
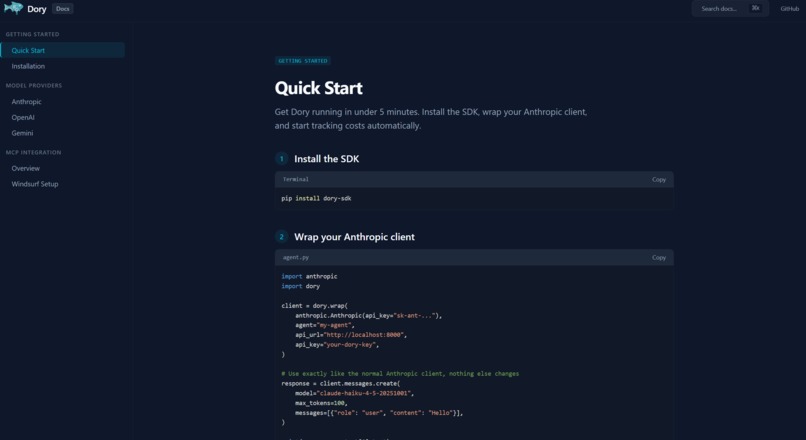
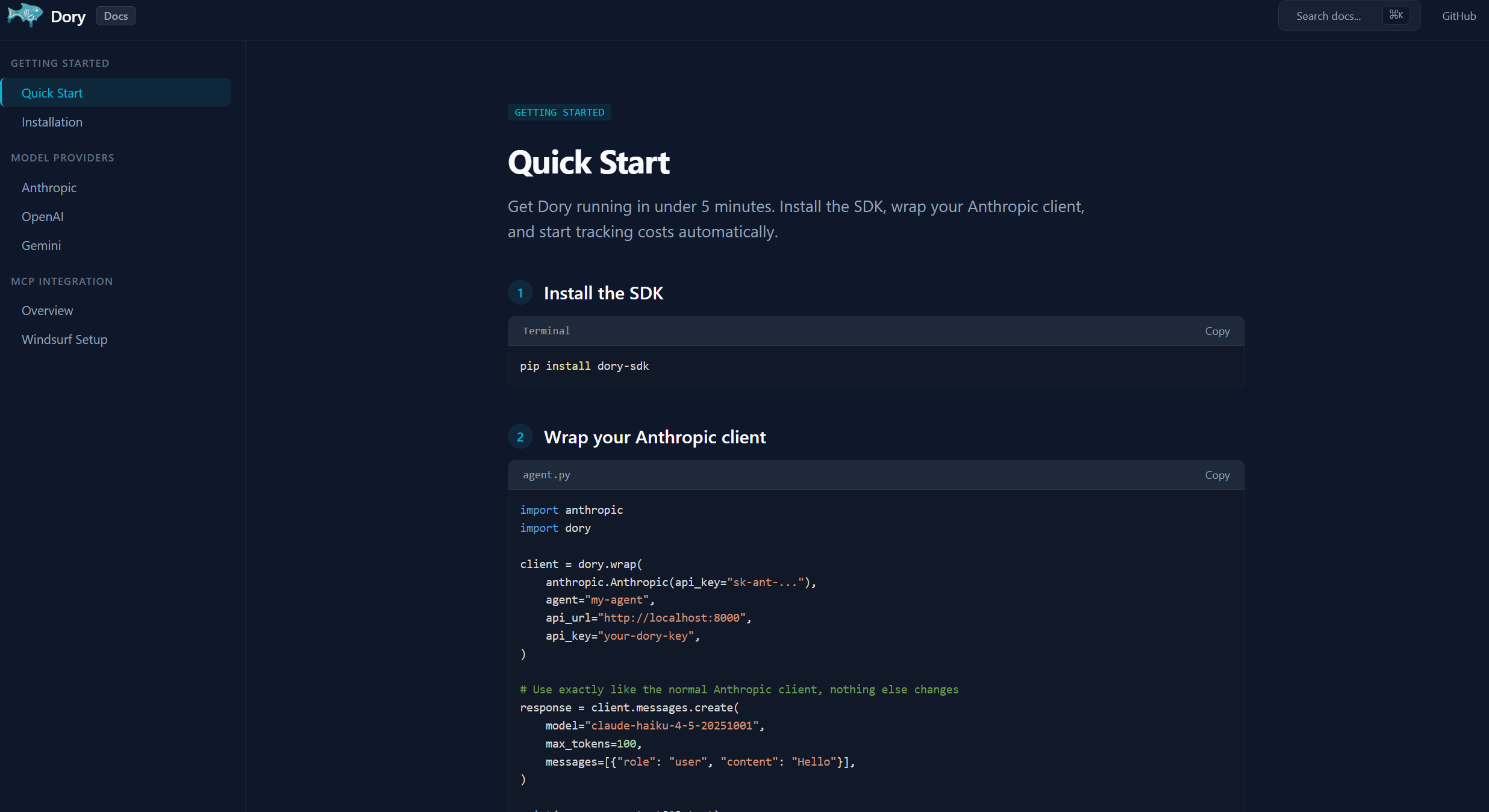
Docs for SDK
-
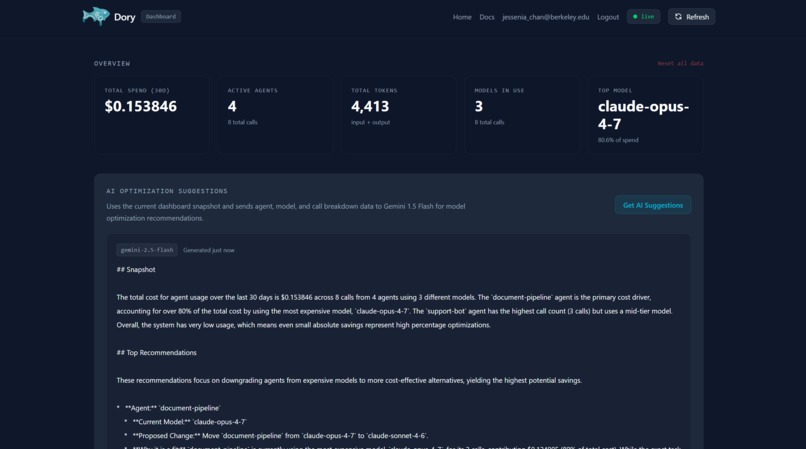
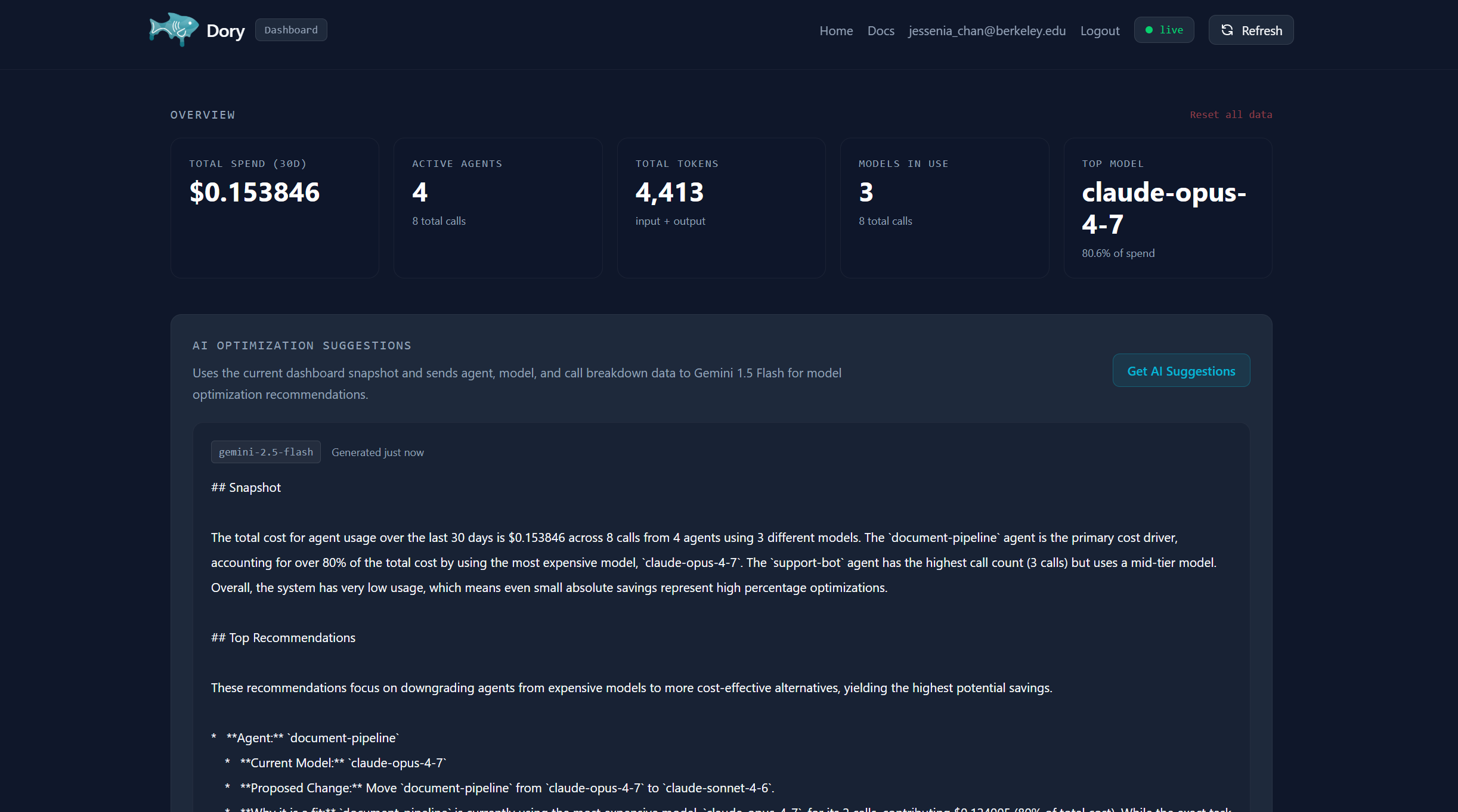
Dashboard with Overall Stats of AI Agent token usage and AI Optimization Suggestions
-
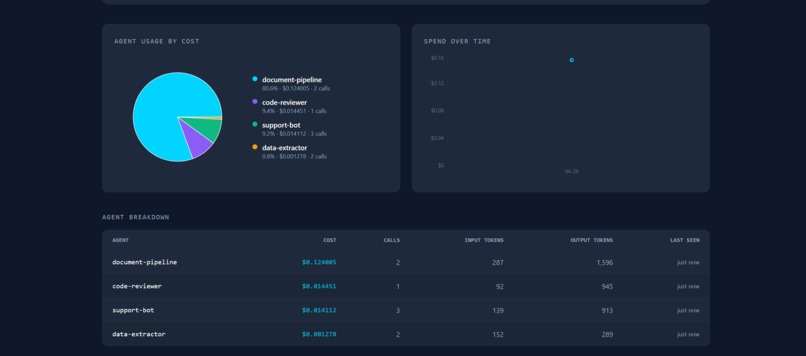
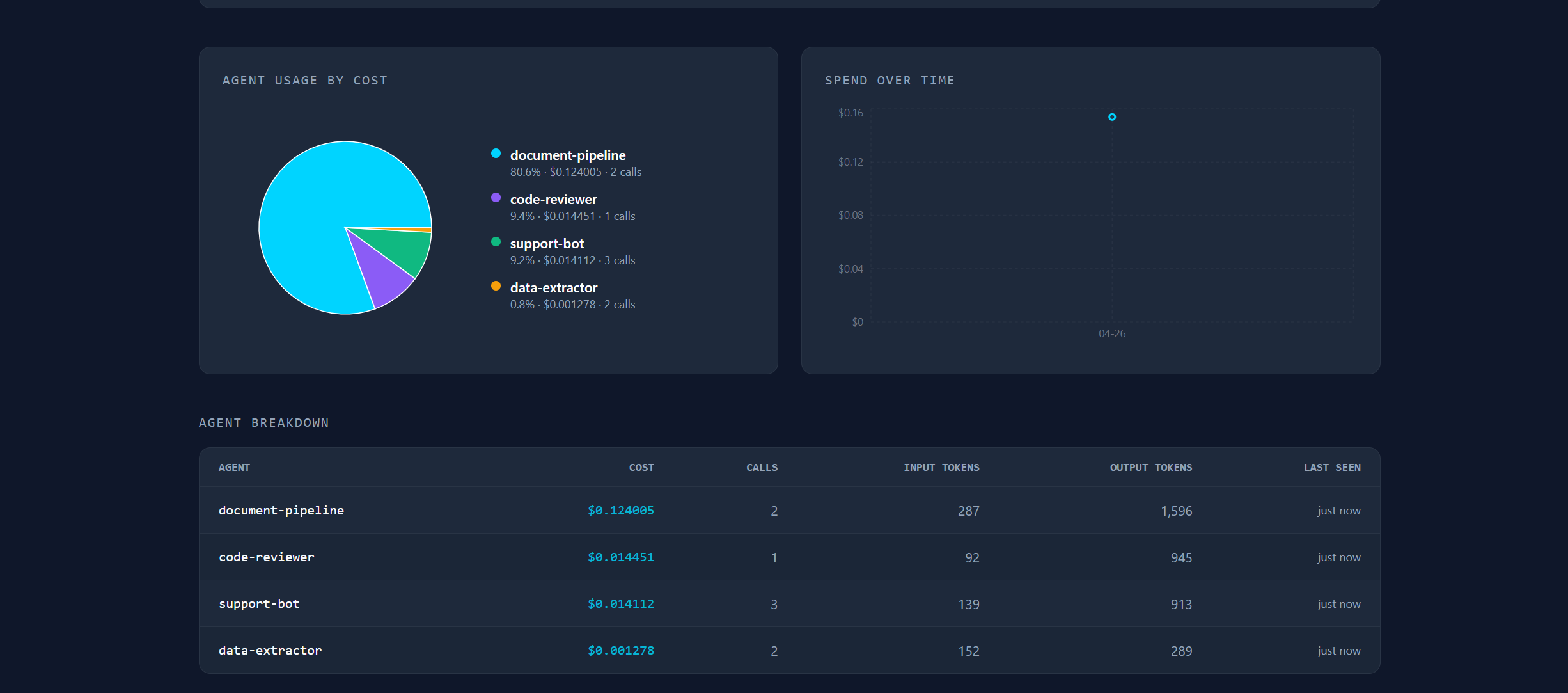
Dashboard Visualizations and Model breakdowns of AI agent usage
-
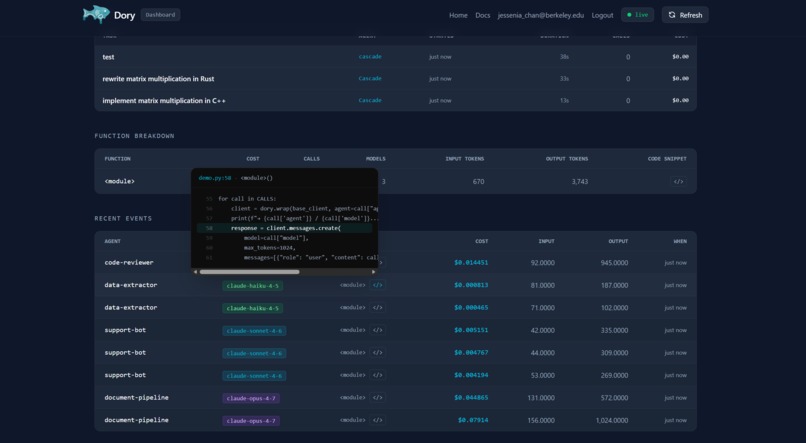
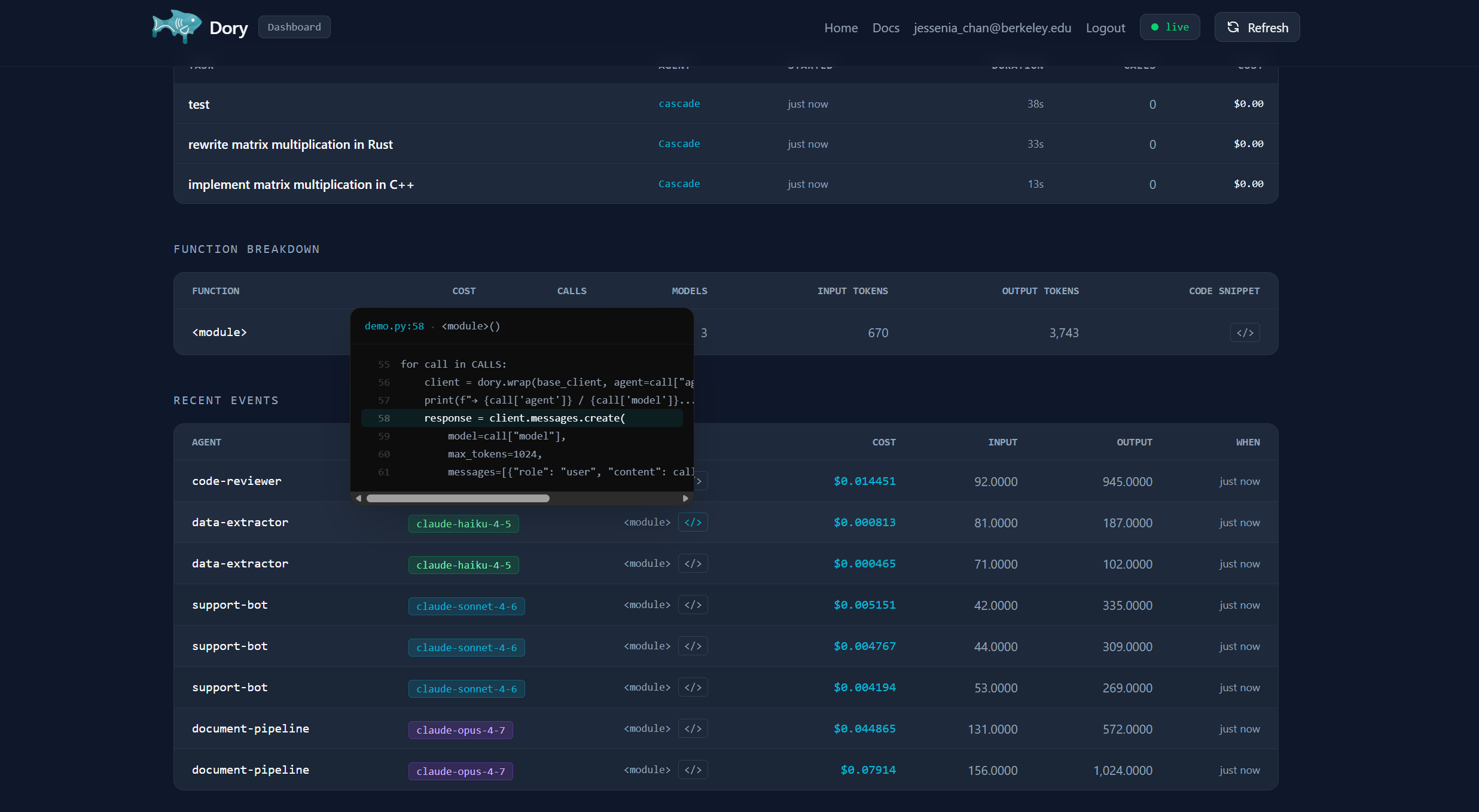
Breakdown of recent AI model usage
Exigence
With many AI agents running in the background all the time, many mystery costs rack up easily. Wanting to mitigate this unclarity, our team was therefore inspired to build a dashboard that shows an analysis of all of the costs broken down by certain parameters: those being agent, model, and function with also a consultant integration on how to best optimally use AI agents and reduce token usage.
Functionality
The SDK wraps your existing LLM client to intercept and record token usage on every call, surfacing that data instantly on the dashboard. The dashboard then shows all of the costs broken down by several categories those being the agent, model, and function, with a time-series trend as well as a per-task tracker. This dashboard also covers AI-powered optimization suggestions from Gemini. We include no polling, and the UI updates via the utilization of MongoDB change streams over SSE the moment a call lands.
An MCP server was also built with five tools so agents can monitor themselves for their analytics: session_spend — how much has been spent this session, by agent, with source locations budget_remaining — check whether an agent is approaching or over its limit before starting expensive work top_expensive_calls — pinpoint the exact file and line driving the most cost start_task / end_task — bracket any named task to see its total cost and call count when done
These parameters are pivotal to creating what our product does in particular.
How we built it
SDK — Python proxy pattern. dory.wrap() returns a thin wrapper around your existing client that intercepts calls, reads token usage from the response, looks up cost from a pricing table, captures the call site via inspect, and fires the event to the backend asynchronously. Zero changes to downstream code.
Backend — FastAPI on Railway, MongoDB Atlas. Events land in a spend_events collection. A change stream feeds a Server-Sent Events endpoint so the frontend gets pushed updates without polling.
Frontend — Next.js + Tailwind deployedon Vercel. Recharts for the time series and breakdowns. Clerk for auth.
MCP Server — studio server using the MCP Python SDK. Talks to the same FastAPI backend via the REST API. Works with any MCP-compatible agent (Claude Code, Cursor, Windsurf, etc.).
AI Suggestions — The dashboard can invoke Gemini
Challenges we ran into
One of the more persistent challenges we faced was keeping the dashboard in sync with the backend during development. Because the system relies on real-time data flowing from the SDK through the backend and into the frontend, any latency or disconnect in that pipeline would cause the dashboard to fall out of sync with what was actually happening. Furthermore, environment configuration became a consistent issue.
Accomplishments that we're proud of
We are most proud of incorporating our UI/UX design. For instance, we designed our own project logo.
What we learned
What was most pivotal is that this one-line integration constraint forced good architecture. If the wrapper required restructuring user code, no one would use it. The proxy pattern kept the API surface identical while making every call an observable call, one that one can analyze.
What's next for Dory
What we want to do next is to be able to integrate a chatbot that has more helpful feedback on optimizing AI agent usage.
Built With
- anthropic
- clerk
- fastapi
- gemini
- mongodb
- next.js
- openai
- python
- recharts
- typescript


Log in or sign up for Devpost to join the conversation.