-
-

landing page
-

custom accent selector
-
-
-

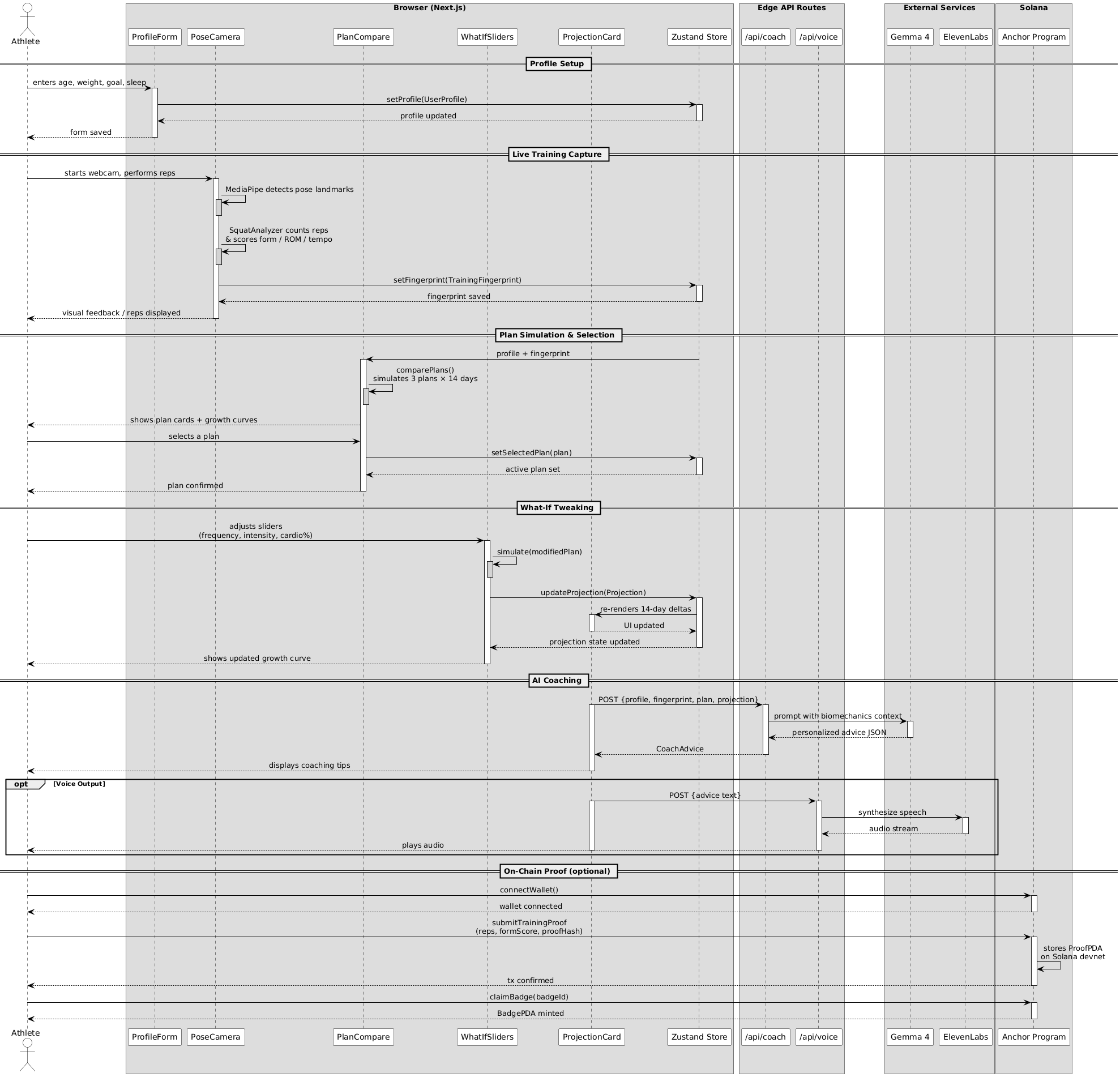
architecture diagram (click for better resolution)


doppel, train smarter by testing your future first
inspiration
most fitness apps report what you did. none tell you what will happen. two athletes can do the same workouts and end up in different places because reps don't capture how you move. we wanted a flight simulator for performance. a digital twin that watches you train, learns your fingerprint, and forecasts weeks ahead before you commit to a plan.
what it does
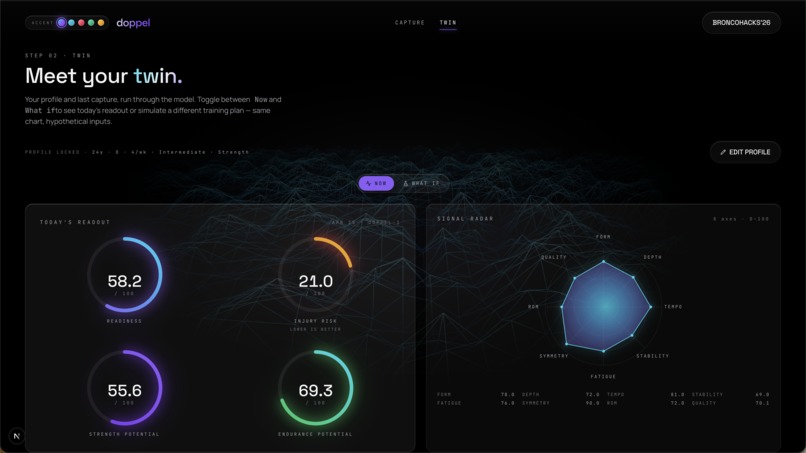
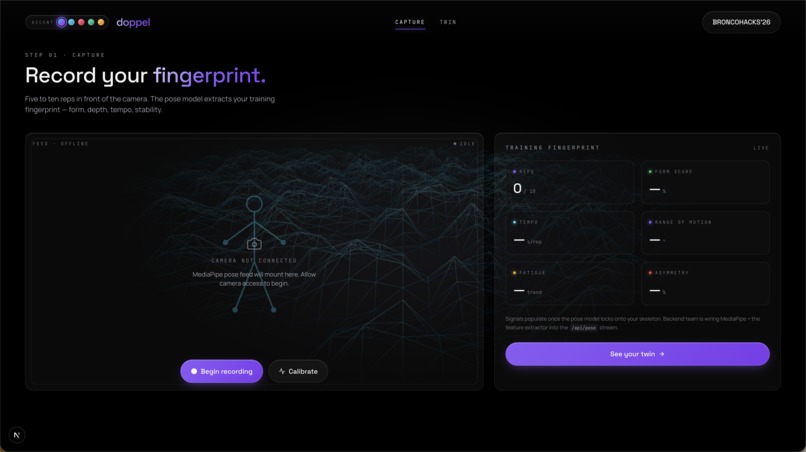
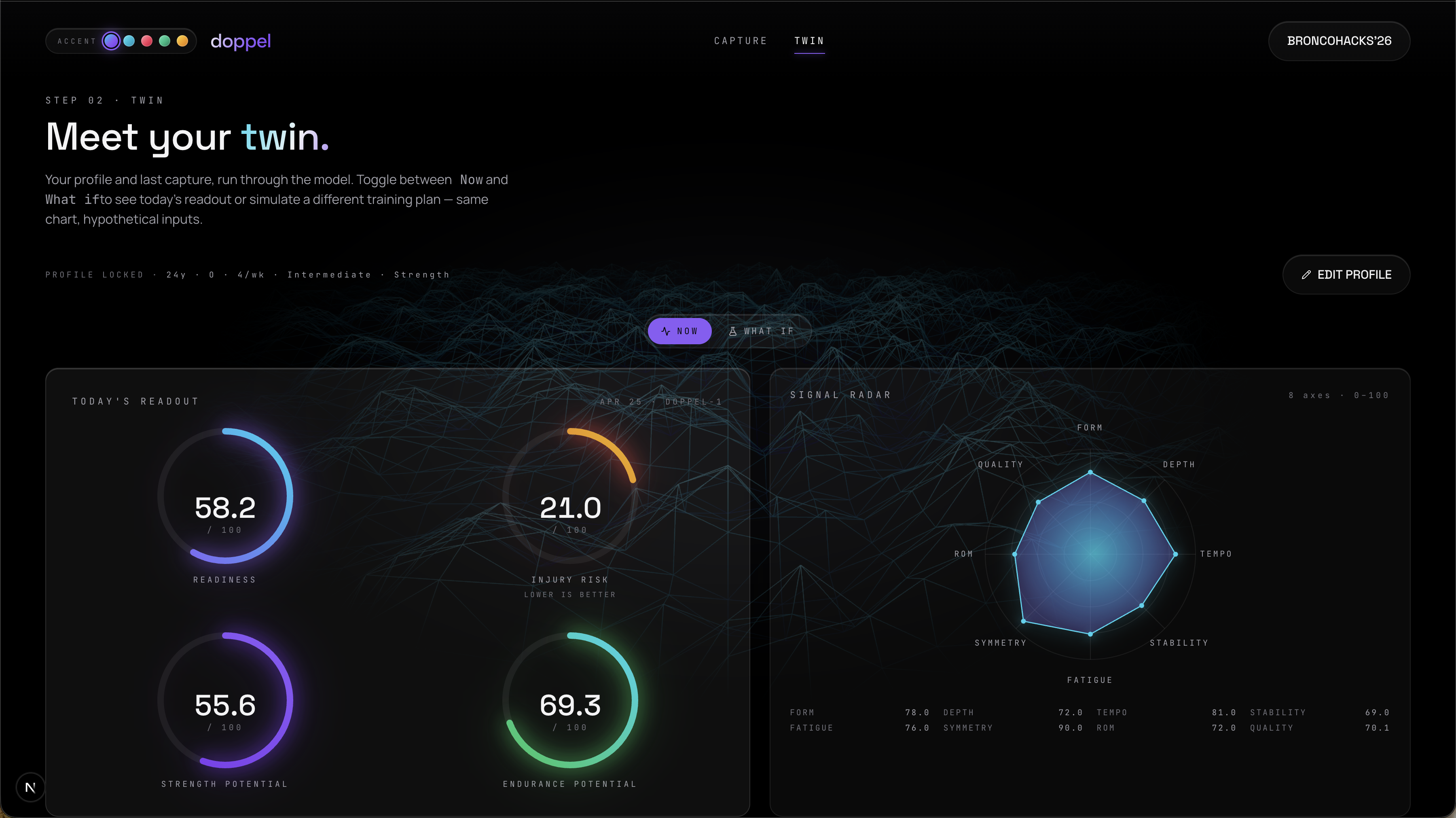
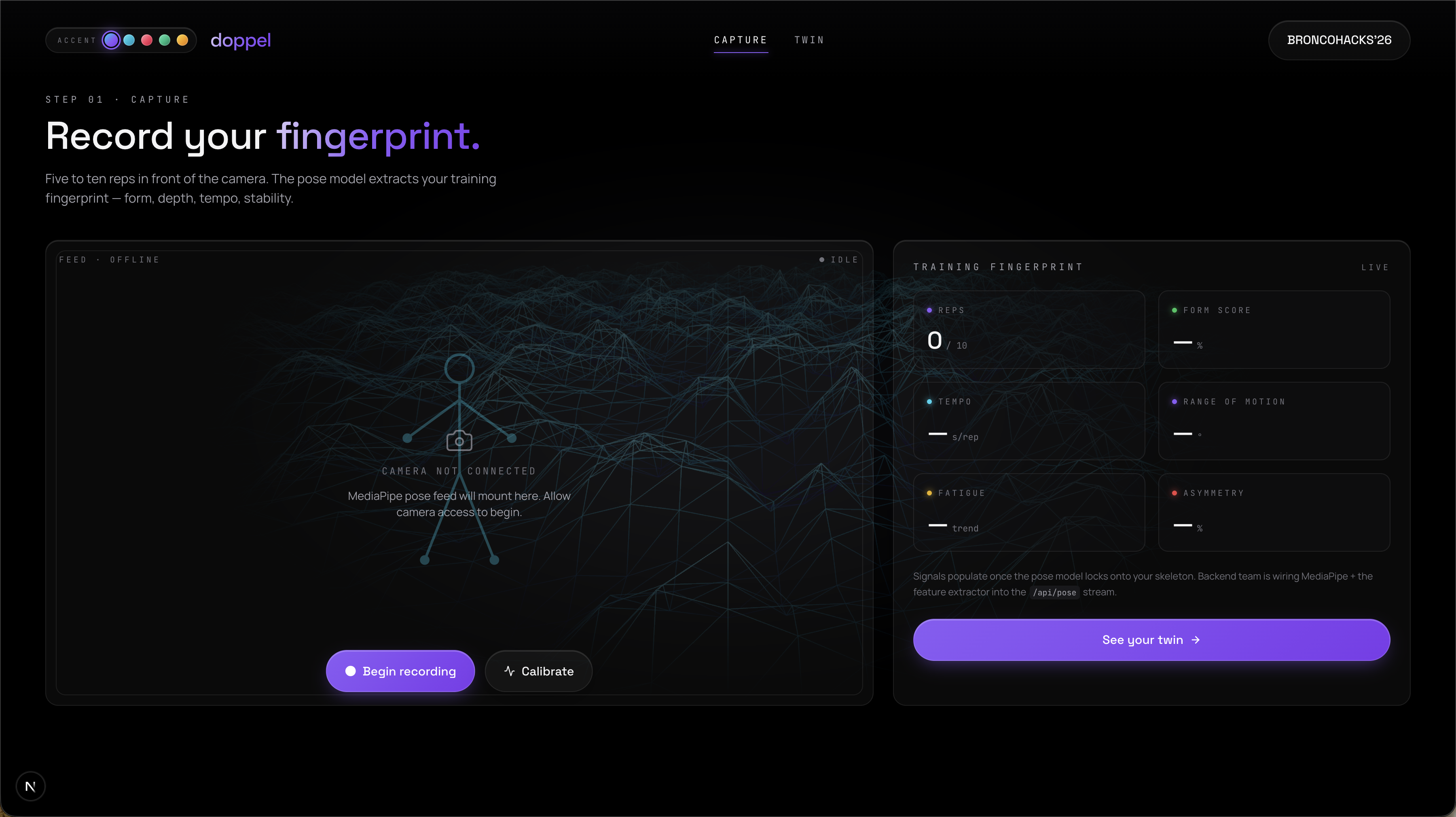
doppel turns a webcam and a few squats into a future forecast.
- capture. do five-to-ten reps in front of your laptop. mediapipe pose estimation extracts a training fingerprint: rep count, range of motion, tempo, form, stability, asymmetry, fatigue, and injury-risk signals like knee valgus.
- forecast. a multi-output random forest takes that fingerprint plus your profile (age, height, weight, frequency, experience) and outputs four scores on a \(0\text{ to }100\) scale.
- coach. a gemini-powered llm proposes three plans for the future (progressive overload, intensity-focused, balanced hybrid) and explains why each fits.
- simulate. a what-if panel lets you slide sessions per week and intensity and re-score in real time.
how we built it
- frontend: next.js 16, react 19, typescript, tailwind v4. a 3d hero with three.js (react-three-fiber, drei, postprocessing) renders a wireframe twin and topographic field. gsap and anime.js handle the wordmark.
- backend: fastapi serves the random forest. an adapter normalizes frontend aliases (
reps -> rep_count, etc.) into canonical model input. - cv: mediapipe landmarks → biomechanical features → fingerprint.
- llm: Gemma 4 via next.js api routes, with strict JSON-schema output enforced via responseMimeType: application/json plus a schema appended to the user message
the model
we had no labeled cv outcomes so we built a synthetic pipeline:
generate_cv_features.pystarts from real tabular fitness data and synthesizes cv style features (form, depth, fatigue, asymmetry, rom, knee back risk).generate_labels.pyadds four target columns using hand-written formulas.train_model.pyfits a multi-output random forest:
RandomForestRegressor(n_estimators=200, max_depth=10, random_state=42)
auto-derived features include BMI:
$$ \text{BMI} = \frac{\text{weight}}{\text{height}^2} $$
with cm-to-m normalization when \(\text{height} > 3\). clamping is \(\text{clamp}(x) = \max(0, \min(1, x))\). composite signals such as range_of_motion, knee_valgus_risk, and back_angle_risk are weighted blends of form, depth, stability, asymmetry, and fatigue. movement quality:
$$ \text{MQ} = 0.28f + 0.20d + 0.18\tau + 0.18s + 0.12\,\text{rom} - 0.06a - 0.05u $$
clamped to \([0, 1]\).
the four targets (readiness, injury_risk, strength, endurance) are similar weighted blends of form, depth, tempo, stability, asymmetry, fatigue, recovery, experience, movement quality, frequency, duration, and cardio.
learning the mappin:
the model takes a training fingerprint and predicts four future outcomes:
$$ x = [\text{form}, \text{depth}, \tau, \text{stability}, \text{asymmetry}, \text{fatigue}, \dots] $$
$$ y = [\text{readiness}, \text{injury_risk}, \text{strength}, \text{endurance}] \in [0,100]^4 $$
the random forest aggregates across trees:
$$ \hat{y}(x) = \frac{1}{T} \sum_{t=1}^{T} f_t(x) $$
the model takes a training fingerprint and predicts four future outcomes:
inference. predict.py applies aliases, normalizes units, fills defaults, computes BMI and MQ if missing, vectorizes predictions, clamps to \([0, 1]\), and returns percentages plus explanations.
results on an 80/20 split:
| target | \(R^2\) |
|---|---|
readiness |
0.9544 |
injury_risk |
0.9444 |
strength |
0.9801 |
endurance |
0.8327 |
these numbers are high because targets are deterministic formulas and train/test come from the same synthetic process. this shows the forest imitates the rules faithfully. it does not prove real-world generalization, and we do not claim it does.
top feature importances:
| feature | importance |
|---|---|
movement_quality_score |
0.8276 |
session_duration |
0.0629 |
fatigue_slope |
0.0222 |
workout_frequency |
0.0168 |
knee_valgus_risk |
0.0167 |
movement_quality_score dominates because it pre-encodes most of the signal in the target formulas. exactly the kind of distortion to flag honestly.
llm safety contract
a separate tabular model is the sole source of every numeric prediction. the llm only describes philosophy, structure, exercises, and trade-offs, and returns strict schema-validated json.
challenges
- splitting llm and ml. our first version let gemini score plans, and it fabricated numbers. we rewrote so the forest owns every score and the llm only proposes and explains. this saved the project's credibility.
- no labeled cv dataset exists. we built a synthetic but honest pipeline and documented the limitation rather than papering over it.
- schema-constrained generation. getting gemini to reliably emit nested json took prompt iteration, mime-type tuning, code-fence stripping, and
thinkingBudget: 0for latency. - field drift. cv pipeline, model, and ui spoke different dialects, so we built an alias adapter.
- hero performance. the 3d stack is expensive, so we tuned point counts and capped effects below a frame budget.
- time. hackathon.
accomplishments
- clean separation of concerns: deterministic ml for numbers, generative ai for language, with a contract neither side can violate.
- an honest model story documenting where every signal comes from.
- a real demo loop: squats → fingerprint → three plans → what-if updates the forecast live.
- a landing page that doesn't feel like a hackathon project.
- strict llm json output that validates and degrades gracefully.
what we learned
- llms tell stories. they don't do math. treat them like a press secretary for your real model.
- a small well-named feature vector beats a pile of raw sensor data.
- without ground truth labels you can still ship a meaningful model by being explicit about what it is learning.
- feature importance lies.
movement_quality_scorelooks dominant only because it's a hand engineered shortcut. - browser pose estimation is good enough to drive a real product.
what's next
- real labels from longitudinal athlete data.
- wearable integration (apple health, garmin, whoop).
- multi exercise fingerprints (deadlifts, presses, running gait).
- rl coach to personalize plans over time.
- long horizons (full mesocycles).
- mobile capture for the gym.
- coach-in-the-loop edits feeding back into the model.
doppel, train smarter by testing your future first.
Built With
- anime-js
- clsx
- eslint
- gemma
- google-gemini
- gsap
- hugging-face
- kaggle
- lucide-react
- mediapipe
- next-js
- node.js
- ollama
- pnpm
- python
- random-forest
- react
- react-dom
- react-three-drei
- react-three-fiber
- react-three-postprocessing
- tailwind-css
- tailwind-merge
- three-js
- typescript
- xgboost







Log in or sign up for Devpost to join the conversation.