-
-
Home
-
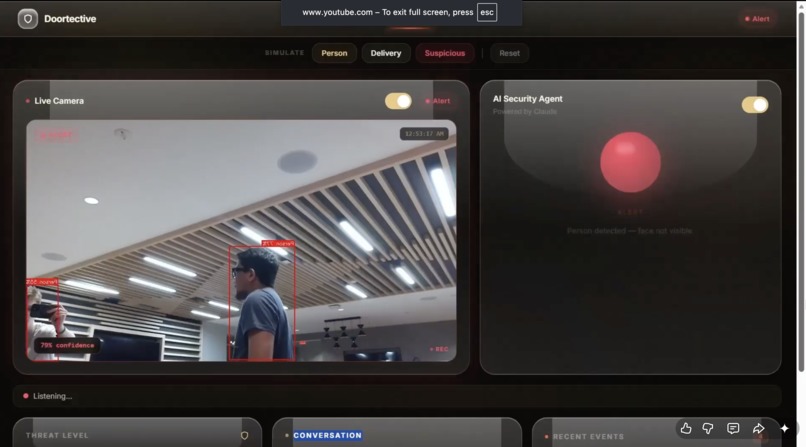
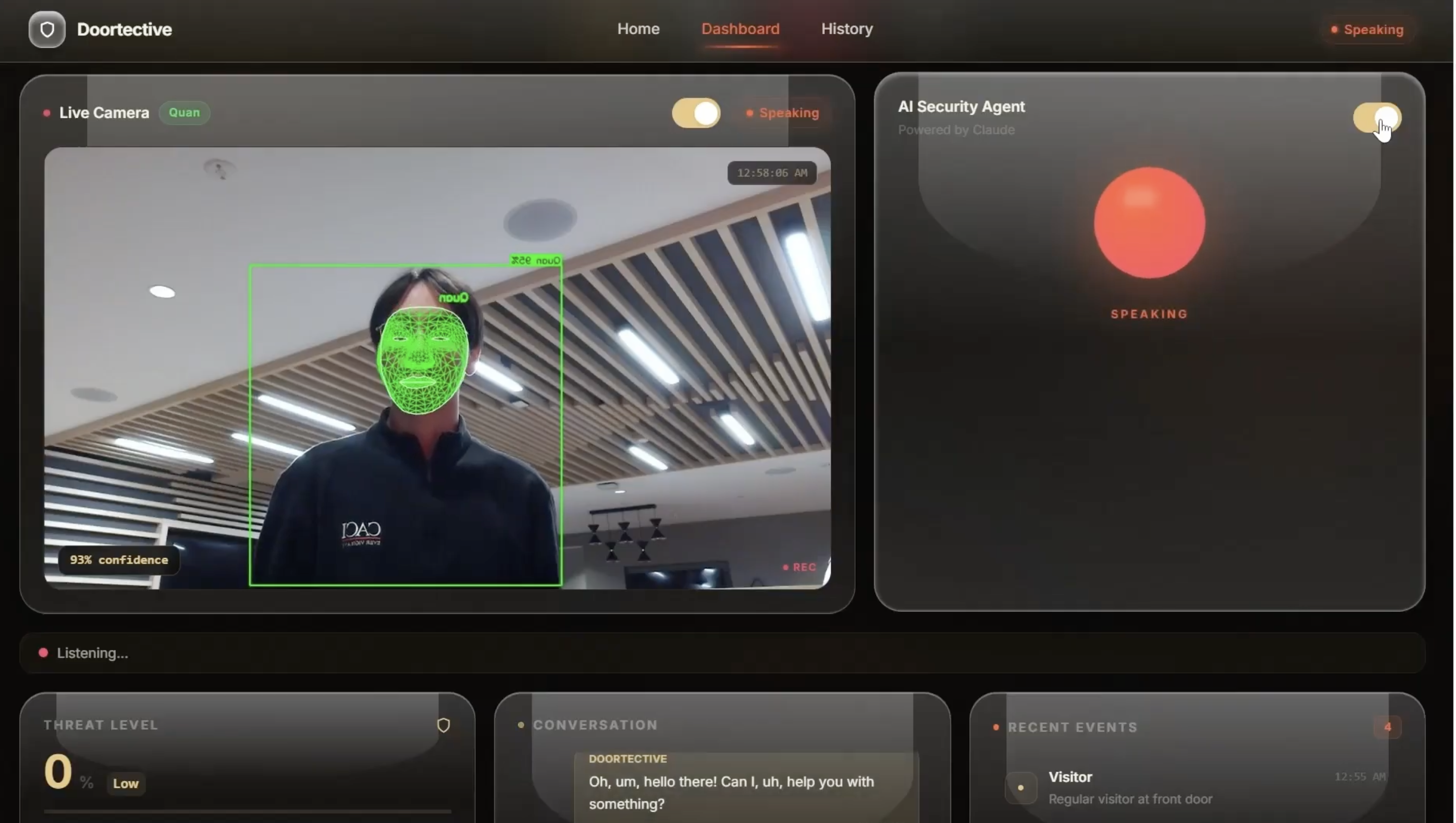
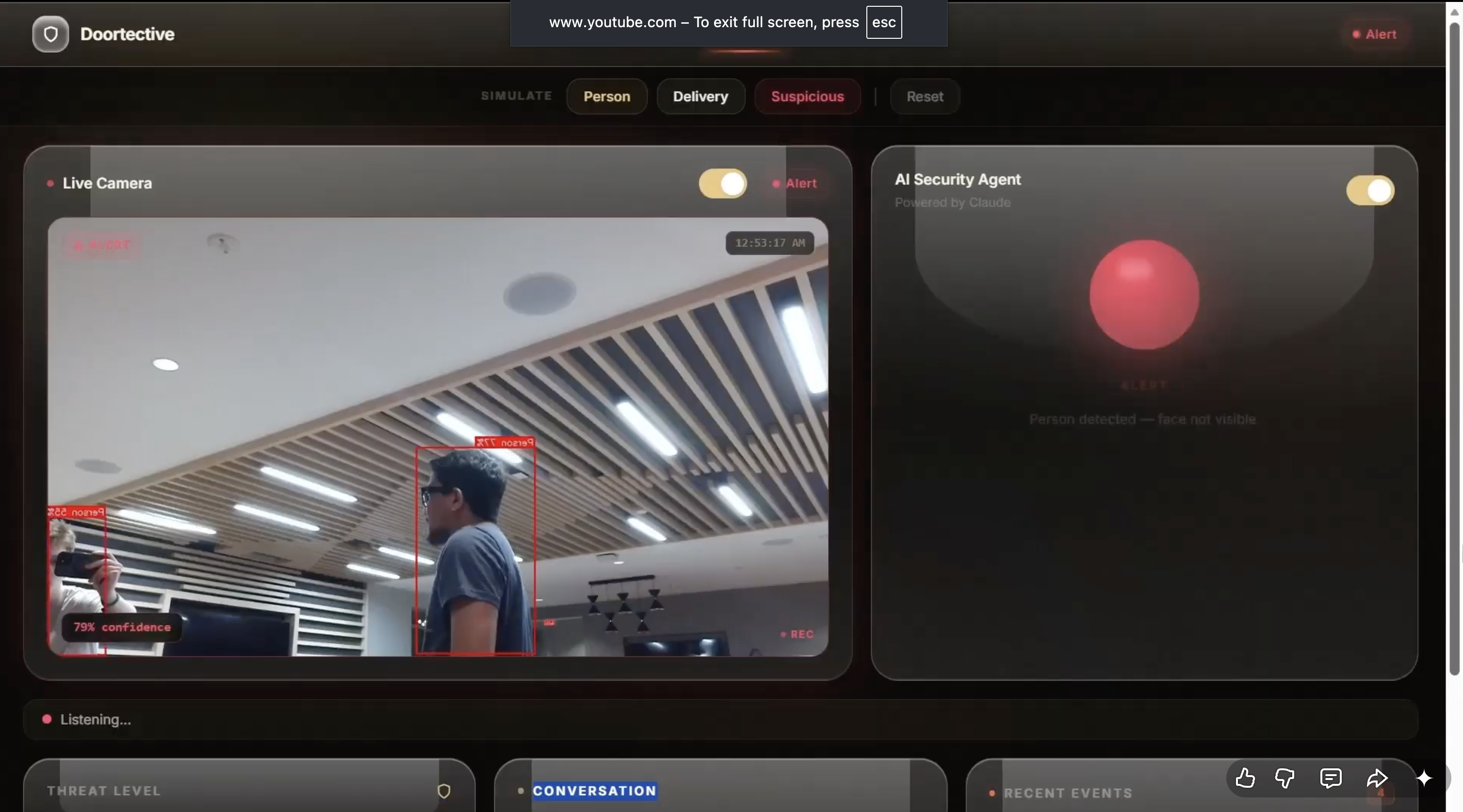
dashboard (unknown person detected)
-
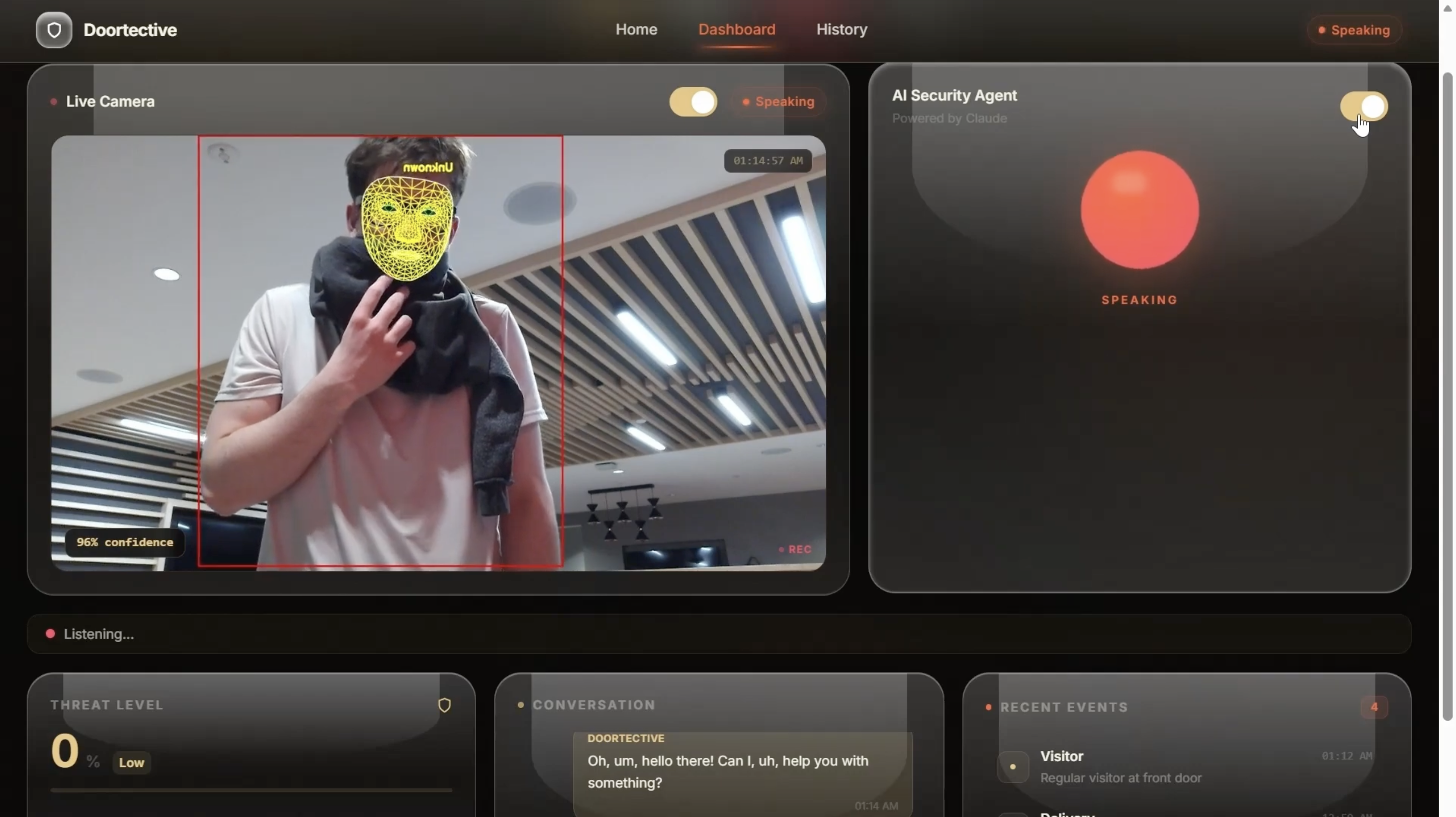
dashboard (known person detected)
-
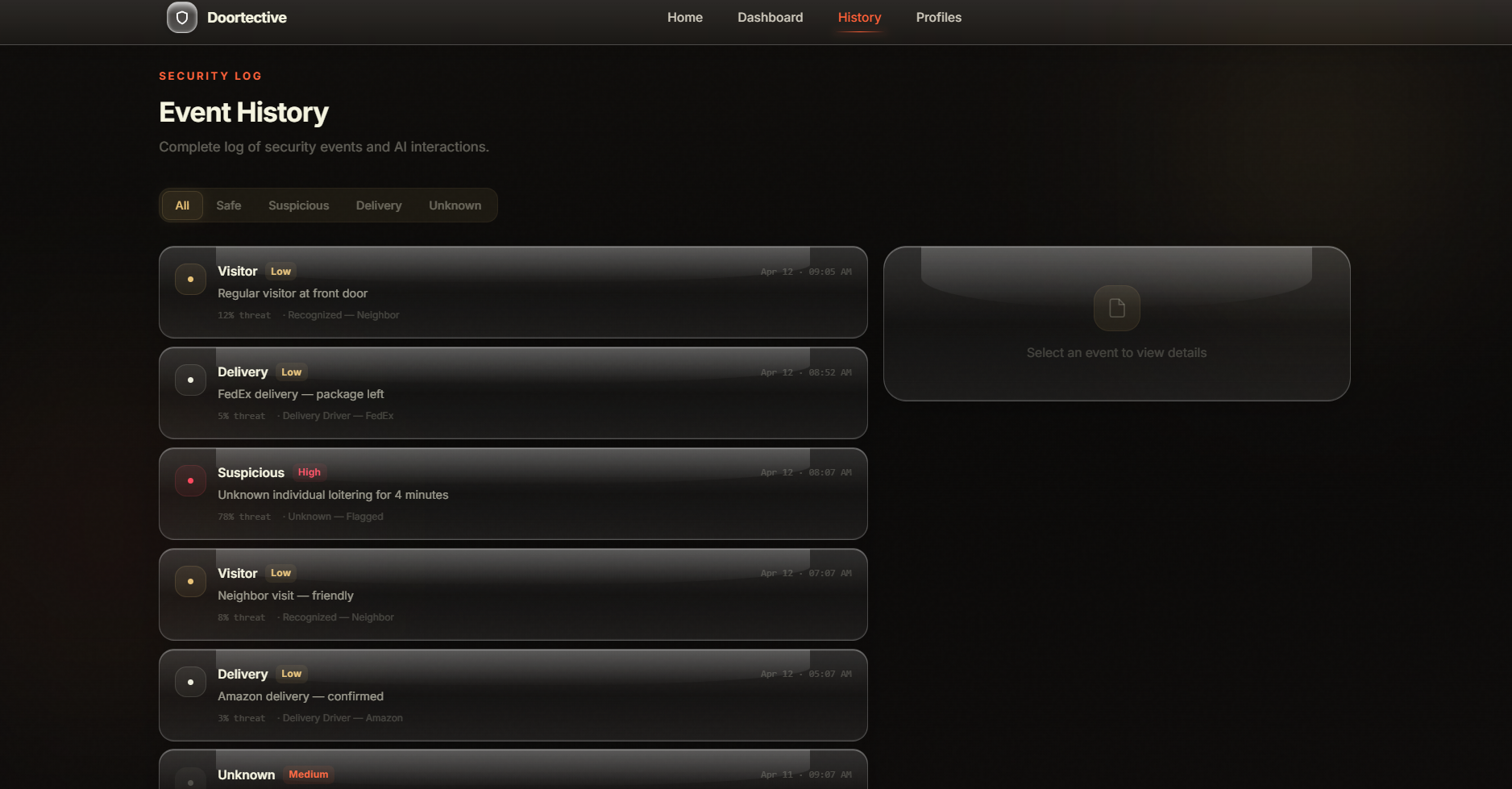
history
-
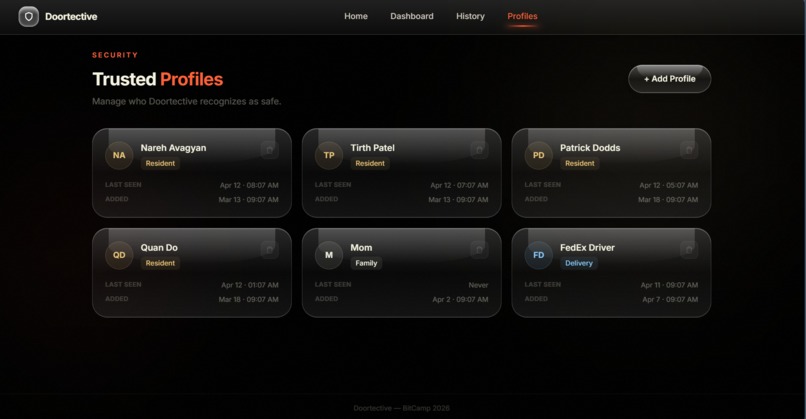
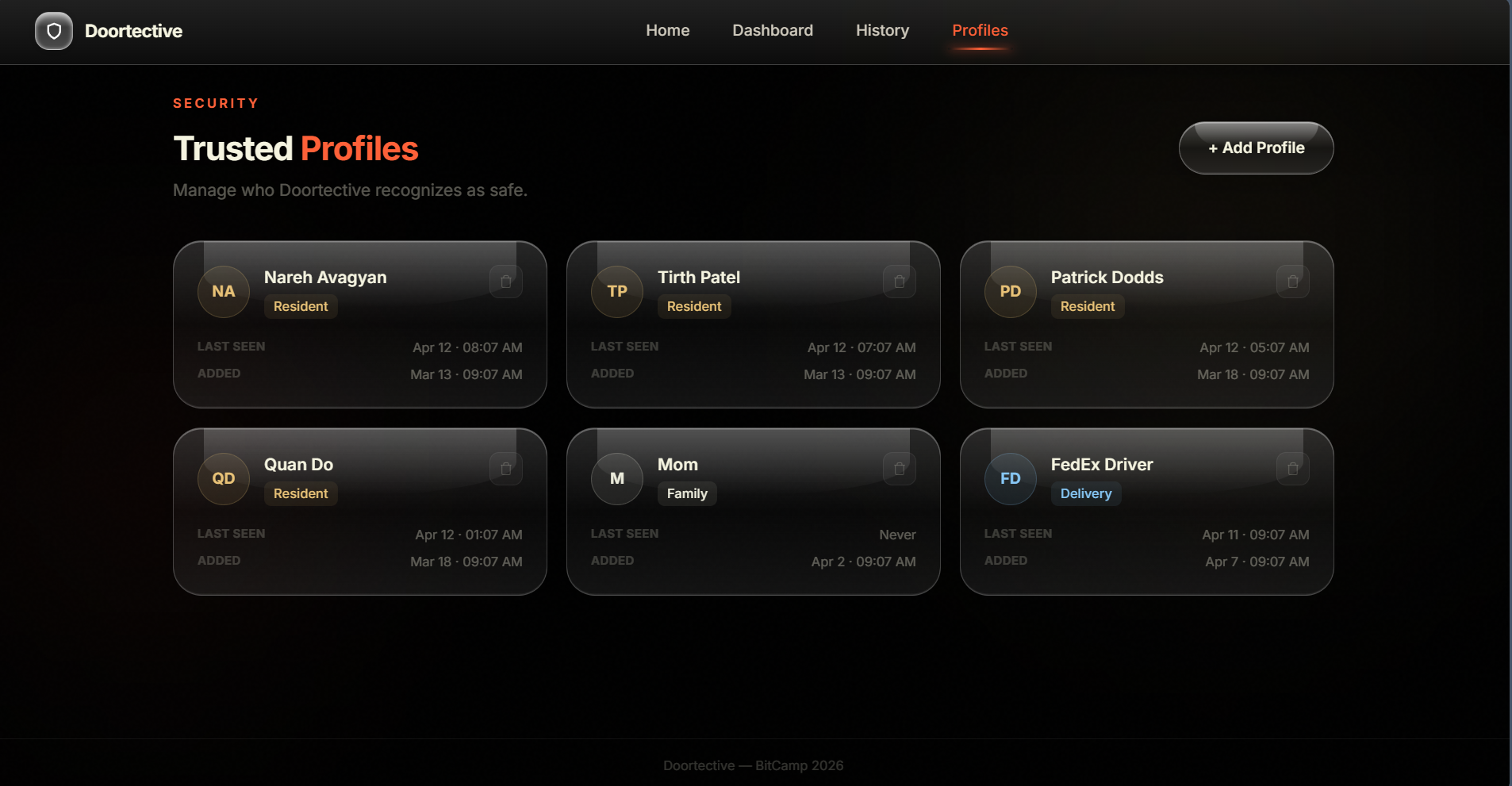
profiles
-

hardware setup
-

Inspiration
Home security systems today are mostly passive, they record footage and notify you after something has already happened. In the U.S., there are over 1 million burglaries reported each year, and most systems fail to actively prevent them.
We wanted to build something smarter, a system that doesn’t just watch, but actually interacts, verifies, and reacts in real-time like a human security guard.
What it does
Doortective is an AI-powered smart door security assistant that can see, hear, and respond in real-time.
It:
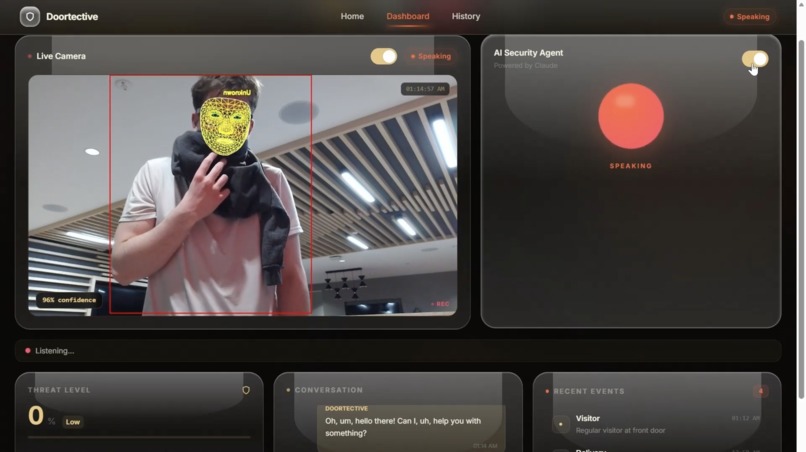
- Detects and analyzes visitors using a live camera
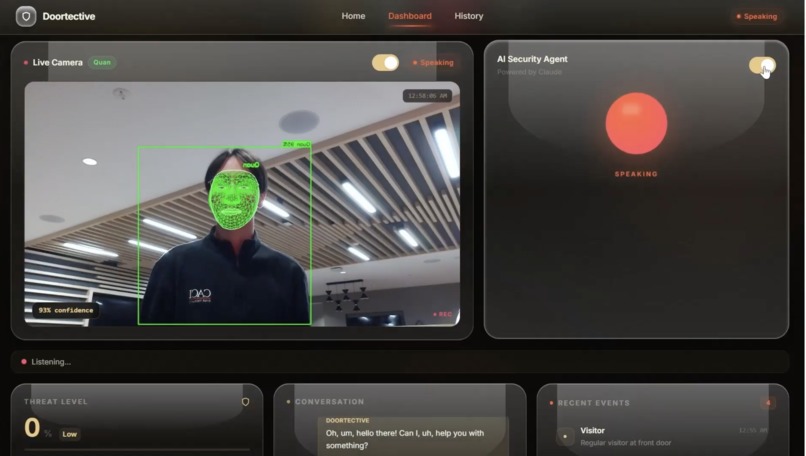
- Recognizes known faces and interacts naturally
- Verifies guests using secure code-based authentication
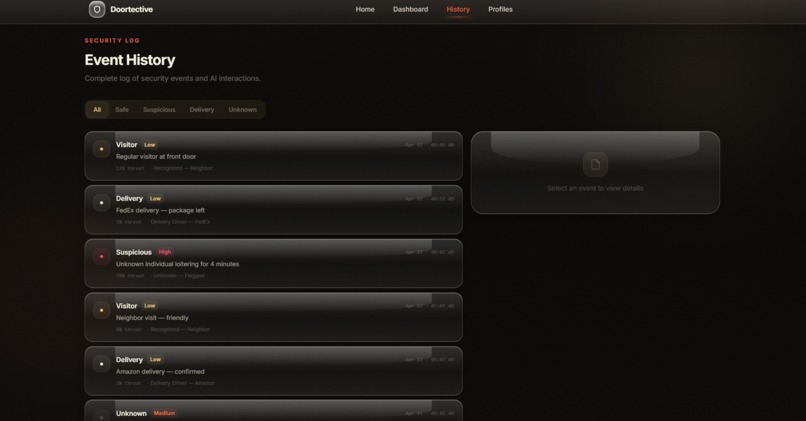
- Handles normal scenarios like deliveries and visitors smoothly
- Detects suspicious or threatening behavior
- Escalates emergencies by calling the homeowner
- Supports multiple languages for accessibility
Unlike traditional systems, it doesn’t just notify. It actively responds and protects.
How we built it
We built Doortective as a full-stack, low-latency AI system combining edge hardware, computer vision, voice AI, and real-time decision-making.
Hardware + Edge Layer
We used a Raspberry Pi connected to a camera and microphone as the edge device. The Pi continuously streams video frames and audio input, acting as the first layer of perception. Lightweight preprocessing (frame resizing, filtering) is done locally to reduce bandwidth and latency.
Vision Pipeline (OpenCV)
Using OpenCV and YoloV8n, we process video frames in real-time (~10–15 FPS) to:
- Detect human presence using motion + face detection
- Extract facial regions for recognition
- Track multiple individuals in frame
Frames are passed into a recognition pipeline where known faces are matched against stored embeddings. If no match is found, the system labels the visitor as unknown and increases suspicion scoring.
AI Reasoning Layer (LLM)
We use the Gemini 3.1 API to interpret context and decide how the system should respond. Inputs include:
- Vision signals (recognized / unknown / multiple people)
- Visitor speech transcription
- Behavior patterns (time, movement, tone)
The LLM determines whether the situation is normal, suspicious, or a threat, and dynamically selects tone and response strategy.
Voice Interaction (ElevenLabs)
We integrated ElevenLabs conversational agents to generate low-latency, natural voice responses. The system streams responses back in near real-time (~300–700ms generation latency), enabling fluid, human-like interaction.
Different tone modes (normal, suspicious, threat) are dynamically applied based on AI reasoning, allowing the assistant to sound friendly, skeptical, or firm when needed.
Backend + Orchestration
- Backend: Python + FastAPI for handling API calls and orchestration
- The backend acts as the central pipeline connecting:
- Vision (OpenCV)
- AI reasoning (Gemini)
- Voice synthesis (ElevenLabs)
- Communication triggers (Twilio)
Communication / Escalation
For high-risk scenarios, we integrated Twilio to trigger real-time phone calls to the homeowner. The system summarizes the situation and delivers it via an AI-generated voice call.
Latency & Performance
We optimized the system to operate in near real-time:
- Vision detection: ~50–100ms per frame
- AI reasoning: ~300–800ms
- Voice generation: ~300–700ms
- End-to-end response time: ~1 seconds
This allows Doortective to react almost instantly to visitor actions.
System Integration
All components are event-driven and work together in a continuous loop:
- Camera detects presence
- OpenCV processes and classifies visitor
- Audio input is transcribed
- Gemini determines intent and response
- ElevenLabs generates voice reply
- Twilio triggers escalation if needed
This pipeline enables Doortective to process visual + audio input, interpret context, and respond naturally with minimal delay.
Challenges we ran into
One of the hardest challenges was integrating multiple systems across hardware and cloud into a single real-time pipeline.
We had a Raspberry Pi handling live camera and microphone input, OpenCV processing frames for detection, Gemini API handling reasoning, ElevenLabs generating voice responses, and LED indicators reacting to system state, all needing to stay synchronized.
Coordinating this pipeline introduced issues like:
- latency between vision → reasoning → voice response
- inconsistent state updates between hardware (LEDs) and AI decisions
- handling multiple inputs (video, audio, context) simultaneously
- ensuring reliable communication between edge device (Raspberry Pi) and backend APIs
We solved this by designing an event-driven architecture, where each component (vision, LLM, voice, hardware) communicates through structured state updates instead of blocking calls. We also optimized frame processing, reduced unnecessary API calls, and parallelized tasks where possible.
This allowed us to bring end-to-end latency down to ~1–2 seconds while maintaining a smooth, real-time experience.
Accomplishments that we're proud of
- Built a real-time AI system that can see, think, and speak simultaneously
- Created dynamic, personality-driven voice agents (not robotic responses)
- Successfully implemented secure access verification logic
- Designed intelligent threat detection with automated escalation
- Enabled multi-language support for seamless interaction with diverse users
- Delivered a working prototype that feels interactive and human-like
What we learned
- How to design and debug complex multimodal AI pipelines combining computer vision, LLM reasoning, and real-time voice synthesis
- Building edge + cloud hybrid systems using Raspberry Pi for input capture and cloud APIs for intelligence
- Managing asynchronous workflows and event-driven architectures to reduce latency and avoid blocking operations
- Handling state synchronization across distributed components (hardware signals, AI decisions, and user interaction)
- Optimizing real-time performance, including frame processing, API latency, and response generation
- Integrating multiple advanced systems (OpenCV, Gemini API, ElevenLabs, Twilio) into a single seamless user experience
- The importance of balancing technical performance with natural, human-like interaction design
What's next for Doortective
- Improve facial recognition accuracy and reliability
- Build a mobile app for real-time alerts and monitoring
- Integrate with smart home systems (Alexa, Google Home)
- Add cloud-based dashboards for analytics and logs
- Expand AI to predict suspicious behavior before it escalates
Built With
- elevenlabs
- fastapi
- gemini
- multimap
- next.js
- opencv
- python
- raspberry-pi
- wbp-systems-torch
- yolo











Log in or sign up for Devpost to join the conversation.