


Donna
Problem Statement
I'm a junior doing a double major, juggling 19 credits a semester plus ML research, 3 jobs, the internship hunt, and cooking. A normal week has more moving parts than I can hold in my head. I tracked it badly, planned late at night, and missed deadlines.
I tried using an LLM to plan my week. It felt smart for a day. Then I noticed the schedules were wrong: two things in the same hour, work scheduled after its deadline. It wasn't thinking about my week. It was generating text that looked like a plan. An LLM doesn't know whether a schedule is feasible. It just writes one that sounds plausible.
That's why Donna exists. Planning a semester isn't a language problem, it's a constraint problem. Real students need a planner that actually works, not one that sounds like it does.
Solution Overview
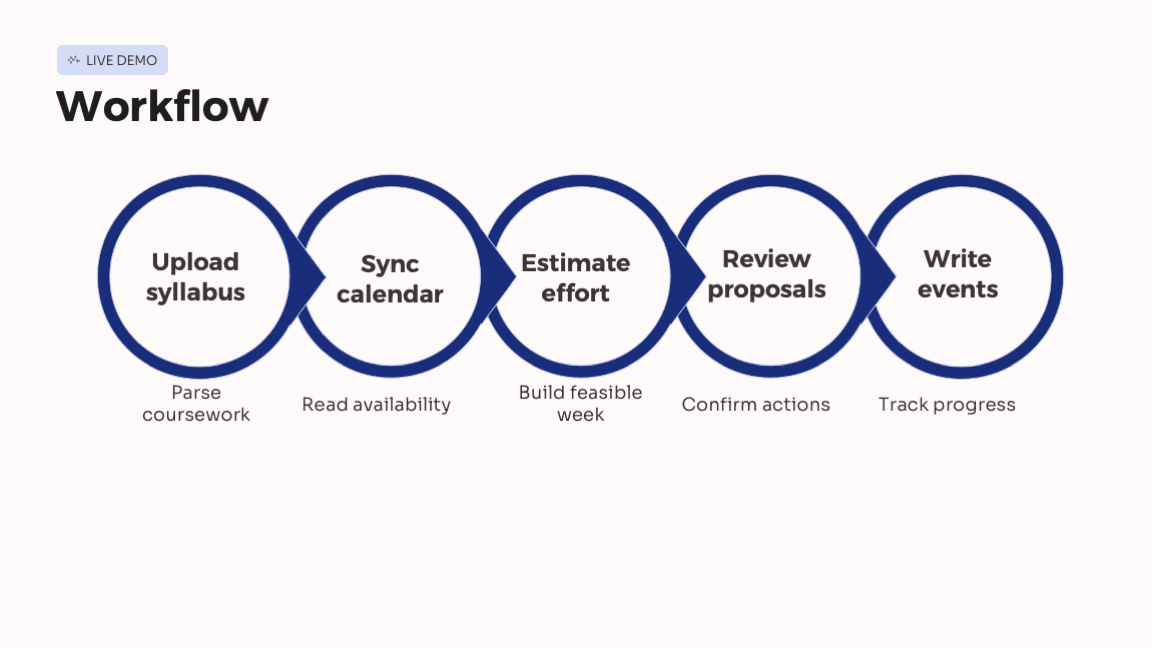
Donna is an academic planner for college students. You upload your syllabi, Donna extracts every deadline, learns how long each kind of assignment takes you, and builds a weekly schedule that fits around classes, sleep, and the things you won't give up. Ask it "can I take Friday night off?" and instead of guessing, it re-solves and tells you exactly what would break. Approved blocks become real Google Calendar events.
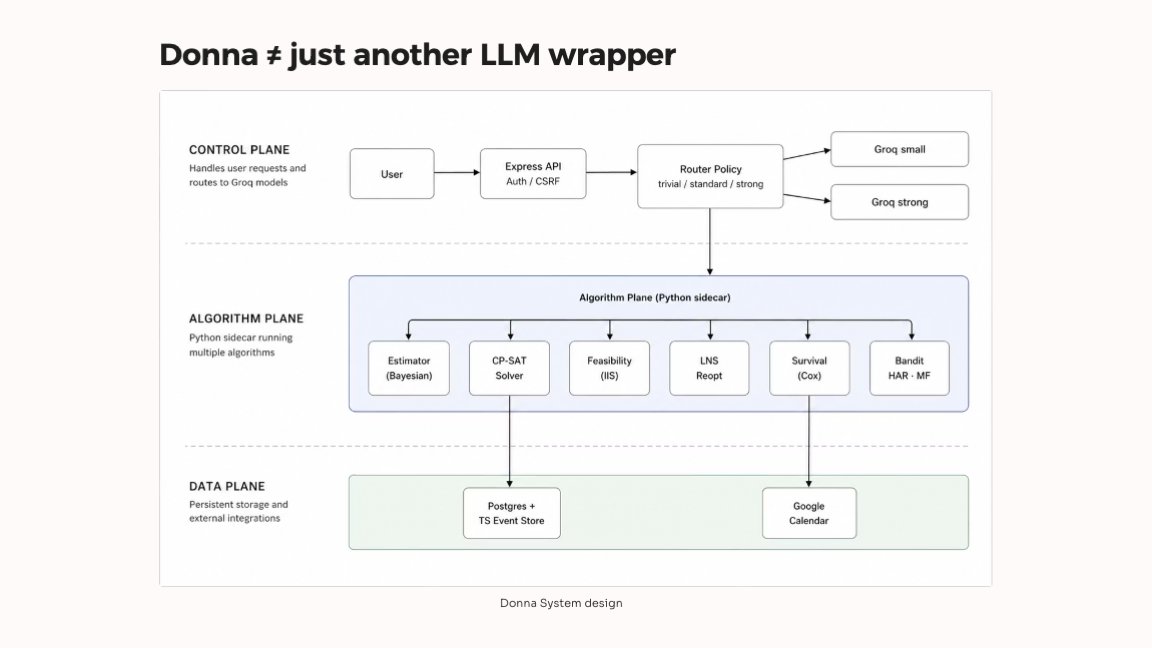
The LLM is still there, but it only translates: it turns your sentence into a structured request and explains the result back. Every actual decision is made by classical algorithms running in a Python sidecar under the React + Express app.
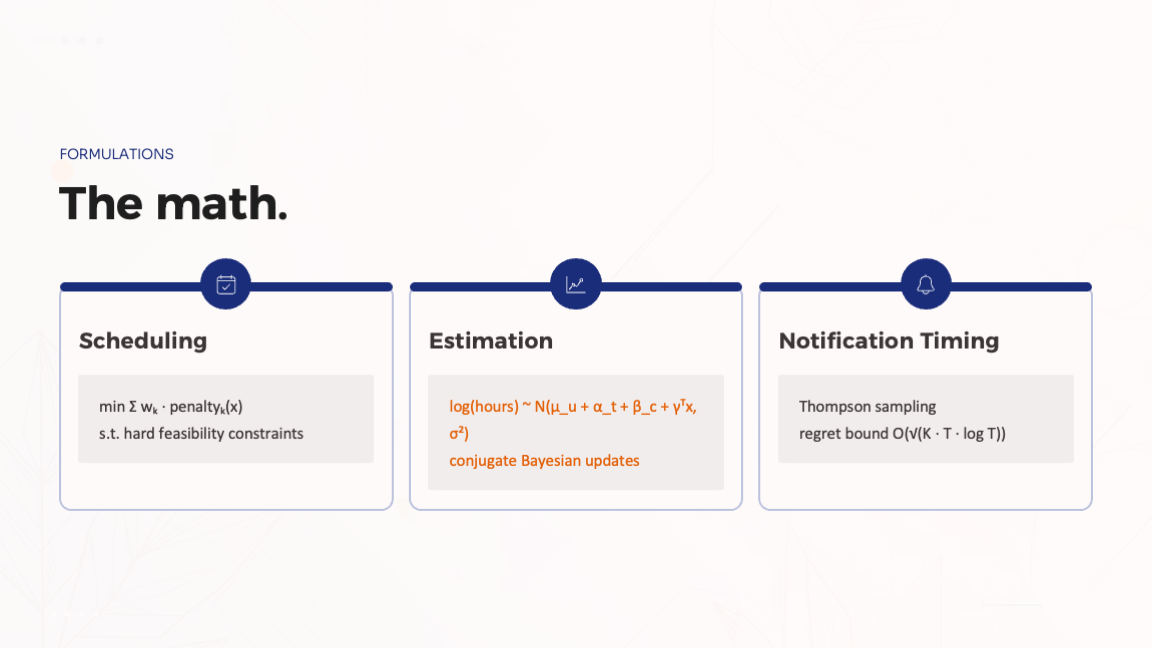
Scheduling is a mixed-integer program solved with CP-SAT:
$$\min \sum_k w_k \cdot \text{penalty}_k(x) \quad \text{s.t. hard feasibility constraints}$$
Time estimation is a hierarchical Bayesian model that personalizes as completion data arrives:
$$\log(\text{hours}) \sim \mathcal{N}(\mu_u + \alpha_t + \beta_c + \gamma^\top x,\ \sigma^2)$$
When a request is infeasible, Donna runs an IIS-style search to return the minimal set of conflicting constraints, so you know exactly what to move. Eight algorithms total; the LLM does three narrow language jobs.
Key Features
- Syllabus ingestion. Upload PDF syllabi; Donna extracts every deadline, assignment type, and weight automatically.
- Personalized time estimates. A Bayesian model learns how long each kind of work takes you, with uncertainty bands instead of single guesses.
- Provably feasible scheduling. A CP-SAT solver builds a weekly plan that respects every deadline, class time, and sleep window.
- Feasibility queries. Ask "can I take Friday off?" and get back exactly what would break, with the minimal conflict set.
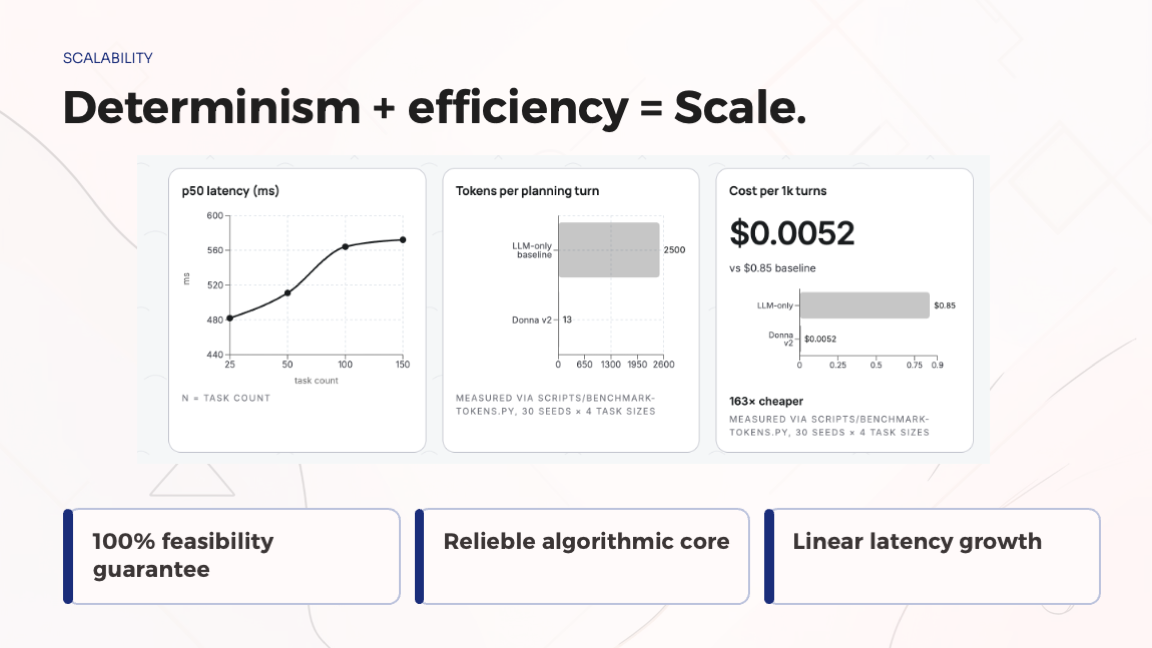
- Real-time rescheduling. Change one task and the schedule patches locally in under 100ms.
- Google Calendar integration. Approved plans become real events on your calendar.
- Progress tracking. Long-term goals and aspirations live alongside daily plans.
- Approval-first execution. Donna proposes; you approve before anything is written to your calendar.
Technologies Used
- Languages: JavaScript, Python, SQL
- Frontend: React, Vite, Tailwind CSS, Recharts
- Backend: Node.js, Express, FastAPI
- Algorithms & ML: OR-Tools (CP-SAT), PyMC, lifelines, scikit-learn, NumPy
- Database: PostgreSQL, Redis
- APIs: Groq API, Google Calendar API, Google OAuth
- Infra: Docker, Docker Compose, Vercel
Target Users
College students with heavy, varied workloads. The kind of student balancing multiple majors, jobs, research, clubs, and internship applications all at once. The kind of student I am.
Donna is built for someone who has more deadlines than they can mentally track, who's tired of re-planning their week every Sunday night, and who wants a planner that can actually answer "is this even possible?" instead of just generating another to-do list.
It's especially useful for:
- Students juggling 5+ courses with overlapping deadlines
- Anyone with research, internship, or job-hunt commitments on top of class
- Students with ADHD or attention challenges who need external structure
- Anyone who's tried a generic AI planner and watched it confidently schedule something at 2am or past a deadline
Built With
- docker
- express.js
- fastapi
- groq
- javascript
- node.js
- numpy
- oauth
- postgresql
- pymc
- python
- react
- recharts
- redis
- scikit-learn
- sql
- timescaledb
- vite

Log in or sign up for Devpost to join the conversation.