
Inspiration
We waste hours digging through PDFs, docs, notes, and images to find a single fact. Keyword search (on Mac spotlight search, file explorer, etc.) breaks on phrasing, synonyms, and context, forcing manual scanning. We wanted search that understands meaning, not just strings, and scales to messy, large folders. It also had to feel instant and work privately on a personal device, without sending data to the cloud. Those constraints led us to build Donna, a local RAG system that turns files into an always-on, semantic knowledge base.
What it does
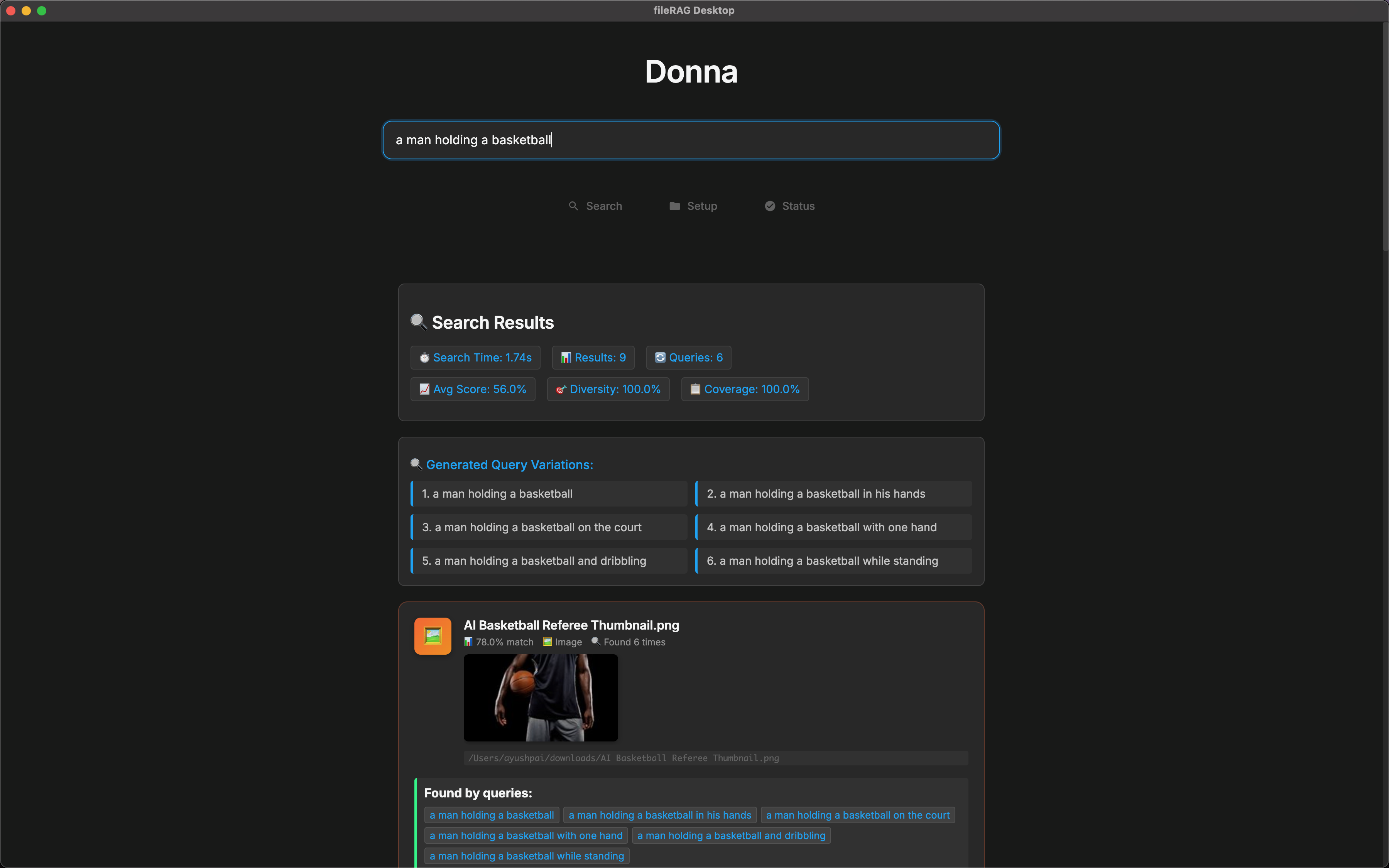
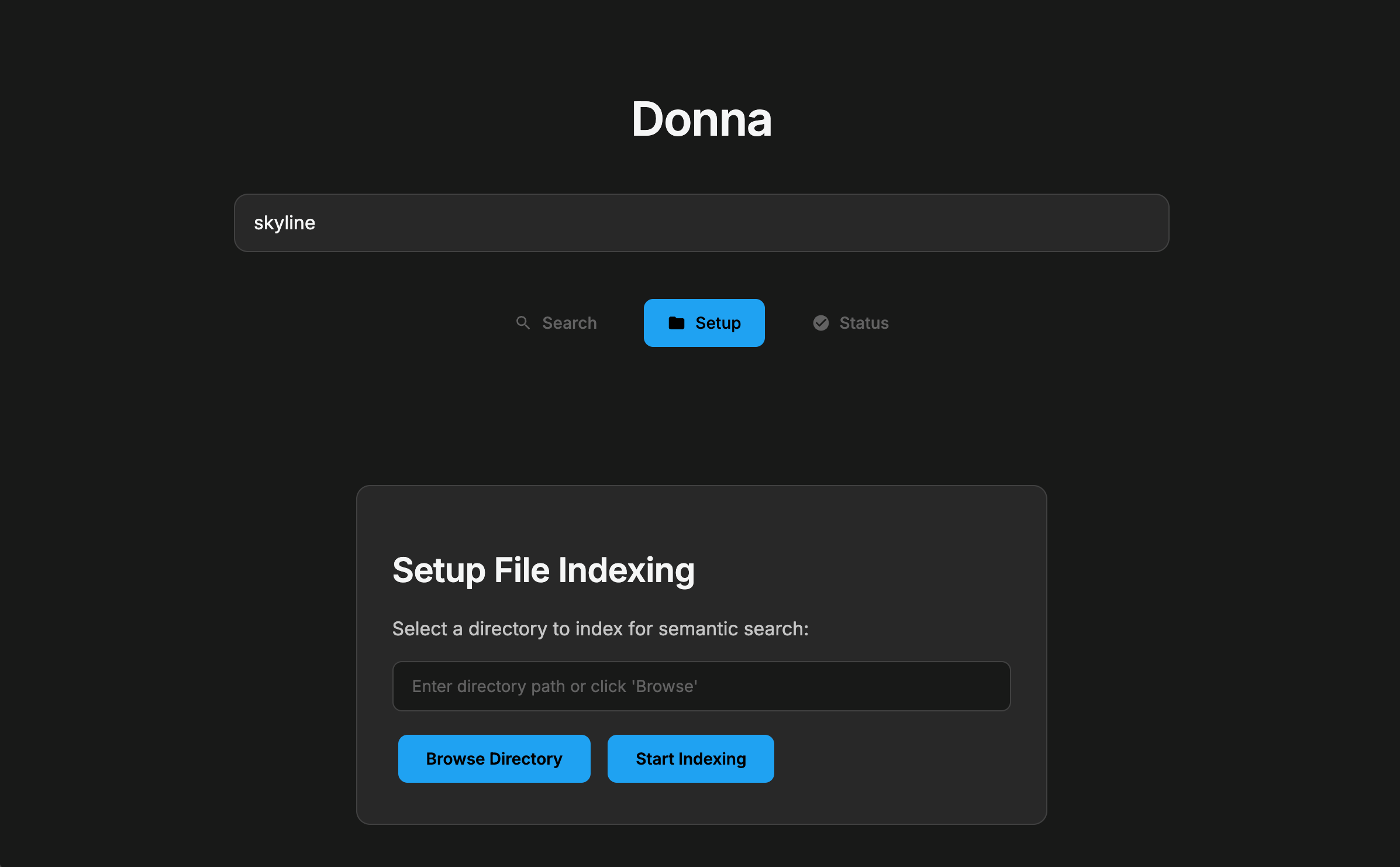
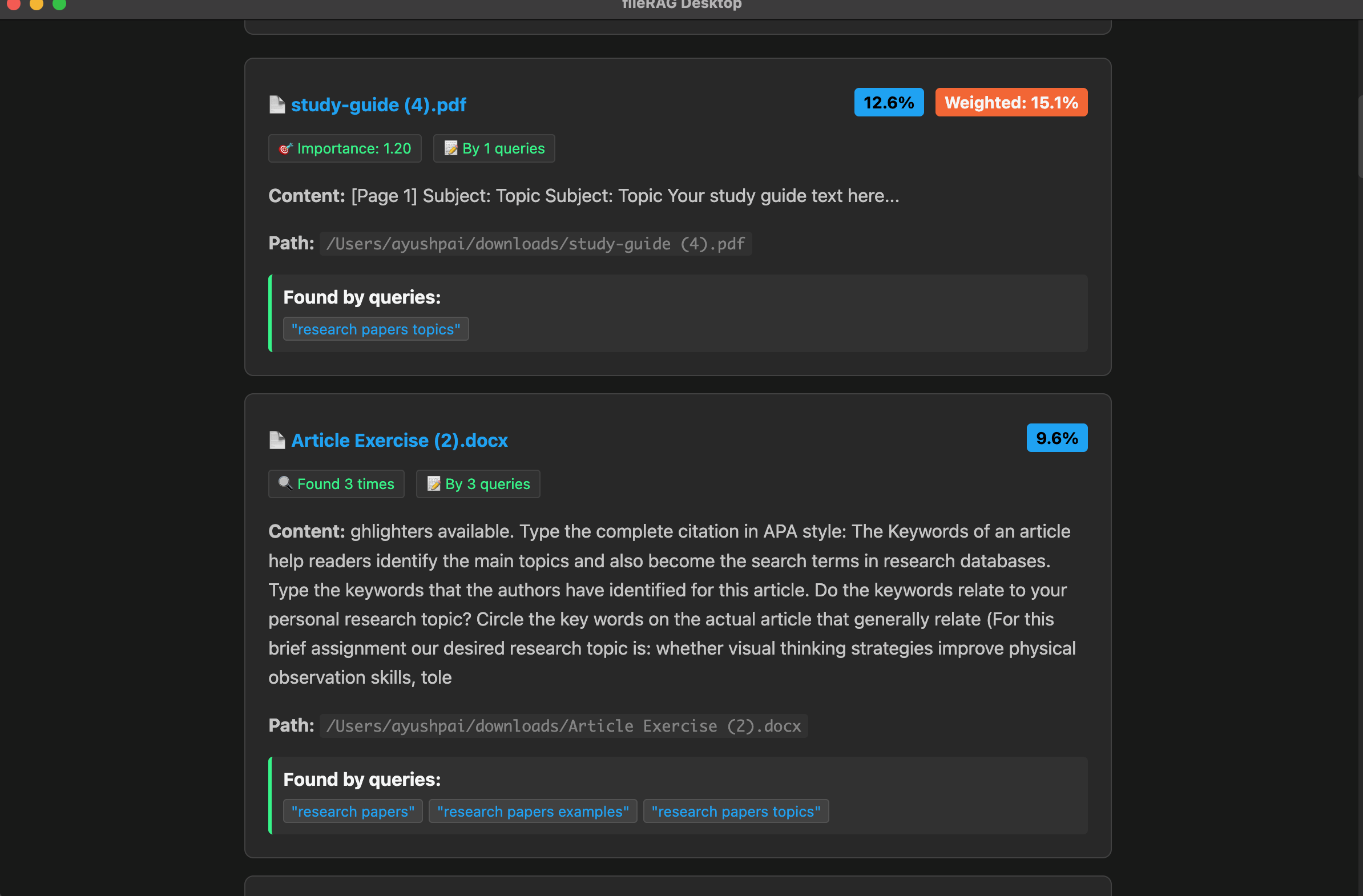
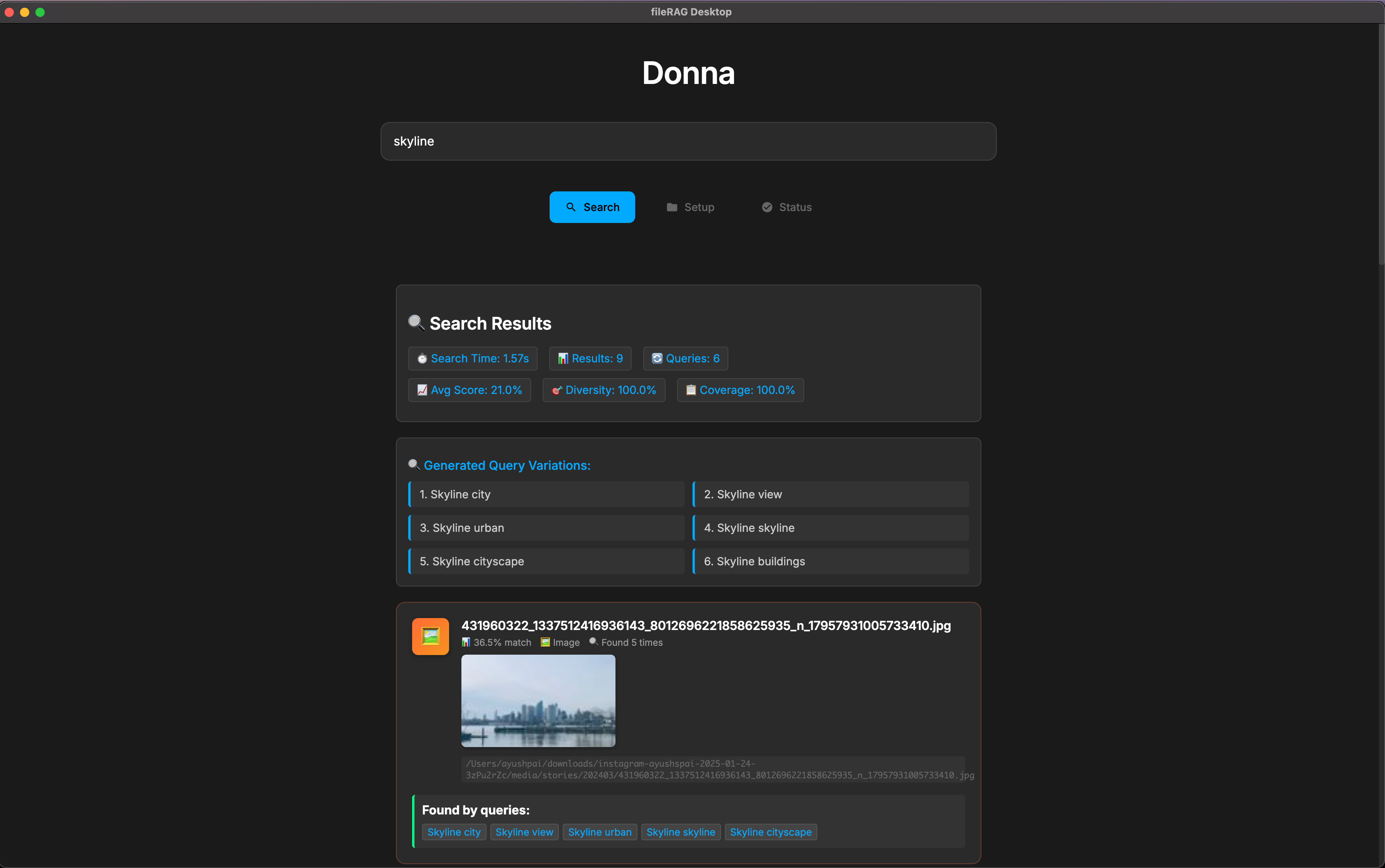
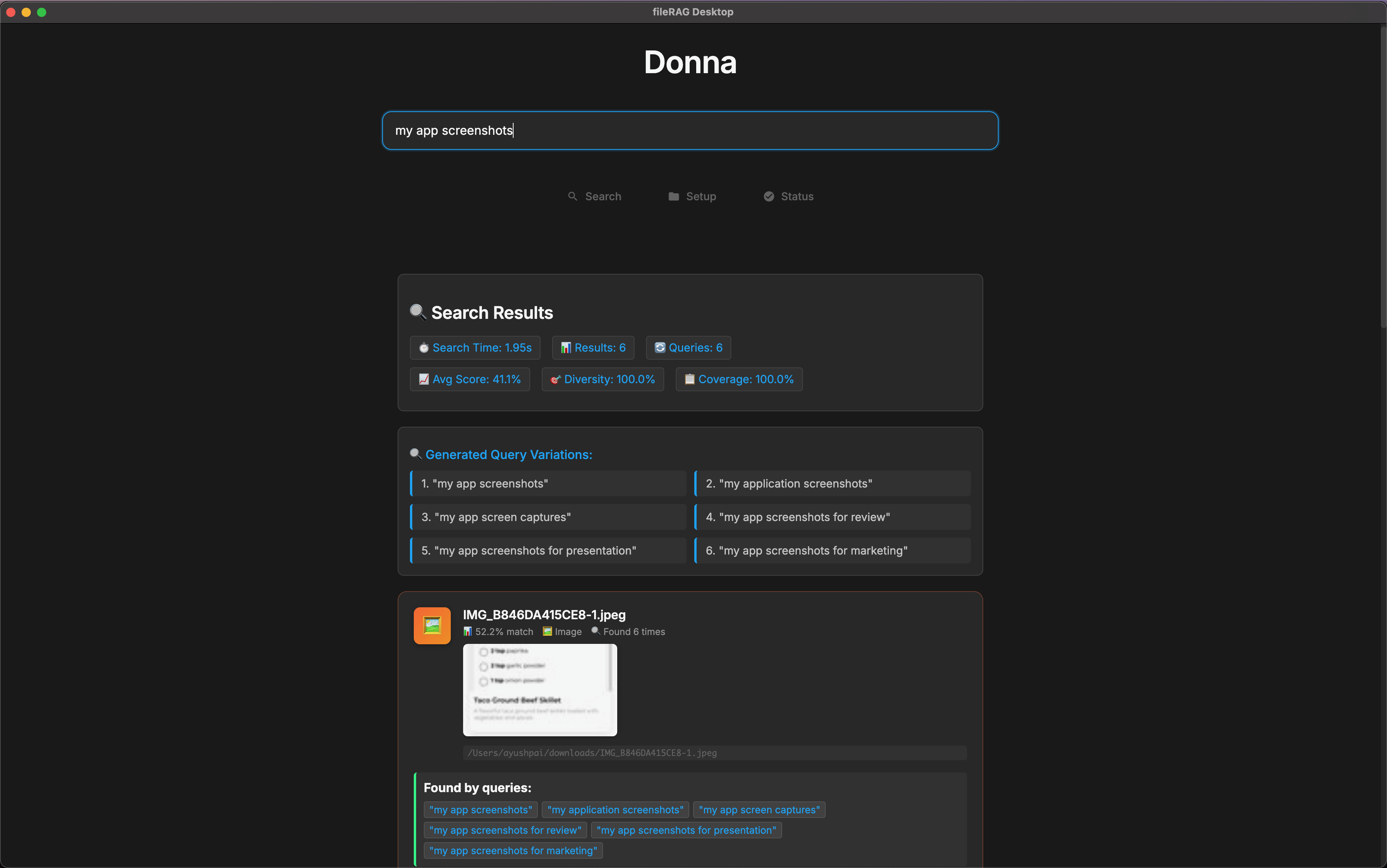
Donna ingests folders, crawls subdirectories, and parses PDFs, DOCX, Markdown, text, and images into clean chunks. It generates vector embeddings for each chunk (using smart chunking techniques), stores them in a local vector database, and keeps them in sync as files change. At query time, it expands your question into related sub-queries, retrieves the most relevant chunks, and finds the most relevant files. The UI streams results as they arrive, so you get instant search results and can drill into files without losing context. Everything runs locally for low latency and privacy.
How we built it
- Backend pipeline (on-device): Lightweight API orchestrates crawling, parsing, chunking, text/image embeddings, retrieval, and answer synthesis locally.
- Models: Uses a local GME-Qwen2-VL-2B for text embeddings and a compact BLIP SLM to interrogate images after OCR.
- Parsers & chunking: Normalizes PDFs, DOCX, Markdown, and images; smart chunker preserves semantic boundaries and rich metadata for robust retrieval.
- Vector store: Persists embeddings in a fast local store optimized for low-latency nearest-neighbor search and quick index updates.
- Search: Multi-query expansion and weighted aggregation. For query variations \(q_i\) with importance weights \(w_i\) and per-result scores \(s_i\), we compute: $$[ \text{weighted_score} = \sum_i w_i \cdot s_i ]$$
- Frontend: Electron app streams results in real time, supports instant search, and is optimized for keyboard-first navigation.
- Performance: Batching, caching, and parallel workers with quantized models deliver sub‑second responses on laptop CPU/GPU.
- Hardware fit: Runs exceptionally well on Apple Silicon (M‑series), staying responsive and energy‑efficient without cloud dependency.
- Privacy: Entire workflow is local-first—no data leaves the device, enabling offline, private semantic search.
Challenges we ran into
Getting sub-second latency with large folders required careful batching, prefetching, and aggressive caching. Balancing chunk size and context windows was tricky: too small harms recall, too large hurts precision and speed. Image understanding needed a reliable OCR pass and a compact vision SLM to extract meaningful text and captions from varied formats. Keeping the index consistent during file churn demanded robust file watching, debounced updates, and safe re-indexing. Ensuring everything stayed fully local while remaining memory-efficient forced us to tune quantization, IO, and concurrency limits.
Accomplishments that we're proud of
Donna runs entirely on a personal device: ingestion, embeddings, retrieval, and generation happen with zero cloud calls. We use a local Qwen embedding model for text and pair it with a compact SLM that interrogates images after OCR to pull out context. The pipeline indexes large folders quickly and maintains freshness in the background without interrupting your workflow. Search feels instant; results stream in with sub-second response times on typical laptops thanks to quantized models and a tuned vector store. Privacy and portability come for free, because your data never leaves your machine and the system works offline.
What we learned
Building a super low latency local RAG system is as much about systems engineering as it is about models. Good chunking, metadata, and prompt templates often matter more than squeezing out another point on a benchmark. Simple heuristics and cache design can beat complex pipelines when the goal is fast, predictable UX. Multimodal retrieval benefits from clear handoffs between OCR, vision SLMs, and text embeddings with consistent normalization. Developer ergonomics—observability, hot reload, and testable components—make iteration dramatically faster than tweaking model weights.
What's next for Donna
Add deeper multimodal support for audio and video, including speech-to-text and frame-level captioning. Introduce learning-to-rank and feedback loops to personalize retrieval while remaining fully local-first. Support encrypted, peer-to-peer sync across devices so your index travels with you without relying on cloud services. Expand connectors for email, notes, and browsers, and expose a simple API for automations and agents. Invest in a richer UI with timelines, saved searches, and inline editing, while keeping latency in the “instant” range.









Log in or sign up for Devpost to join the conversation.