-
-
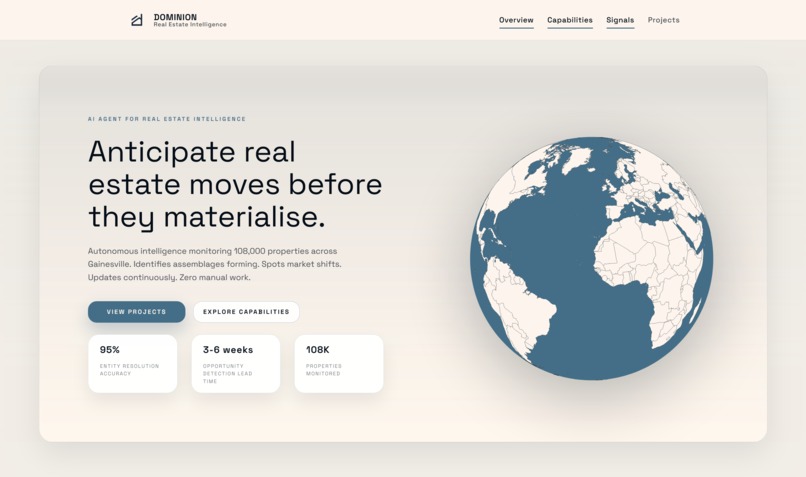
Landing Page
-
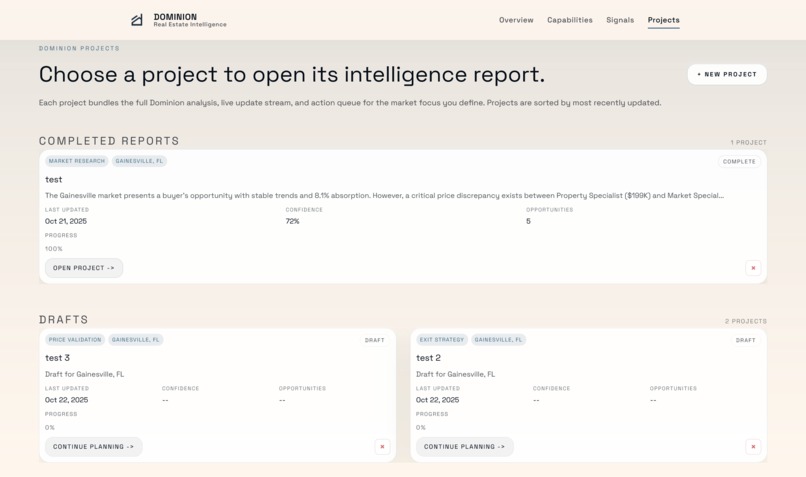
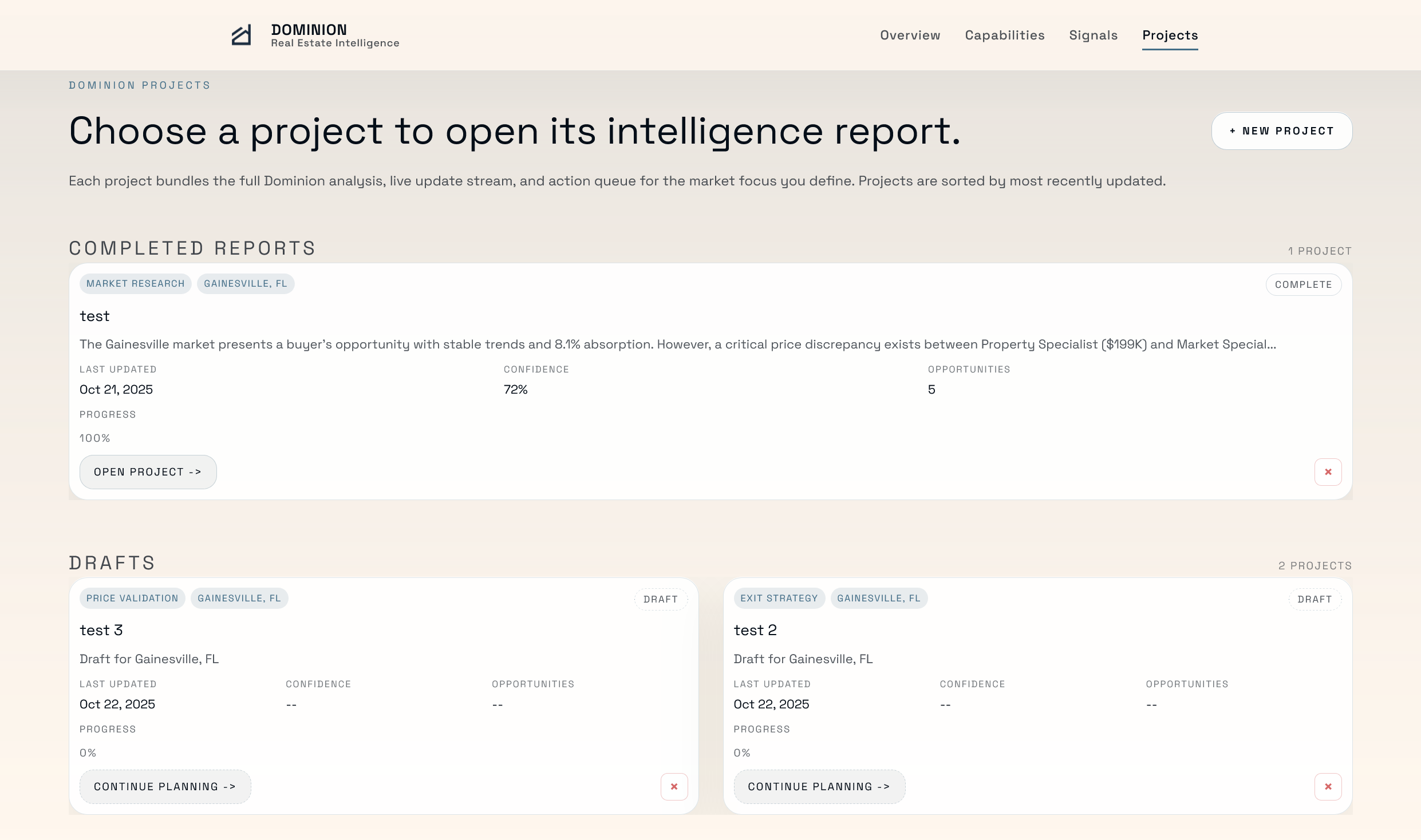
Projects Page
-
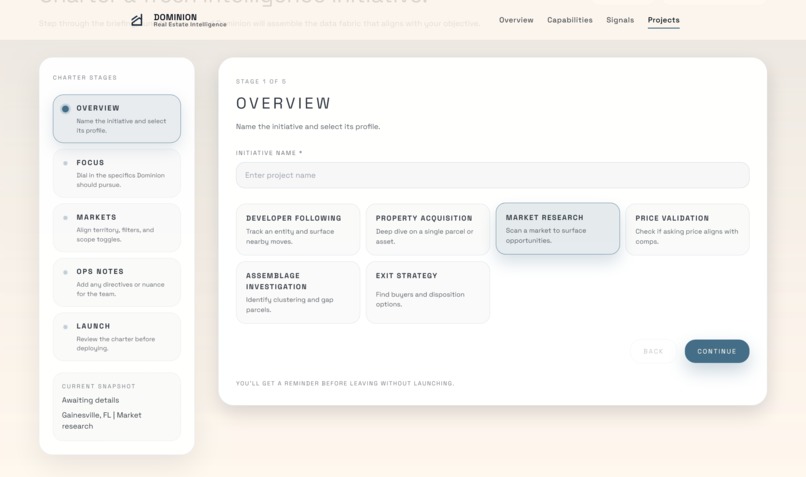
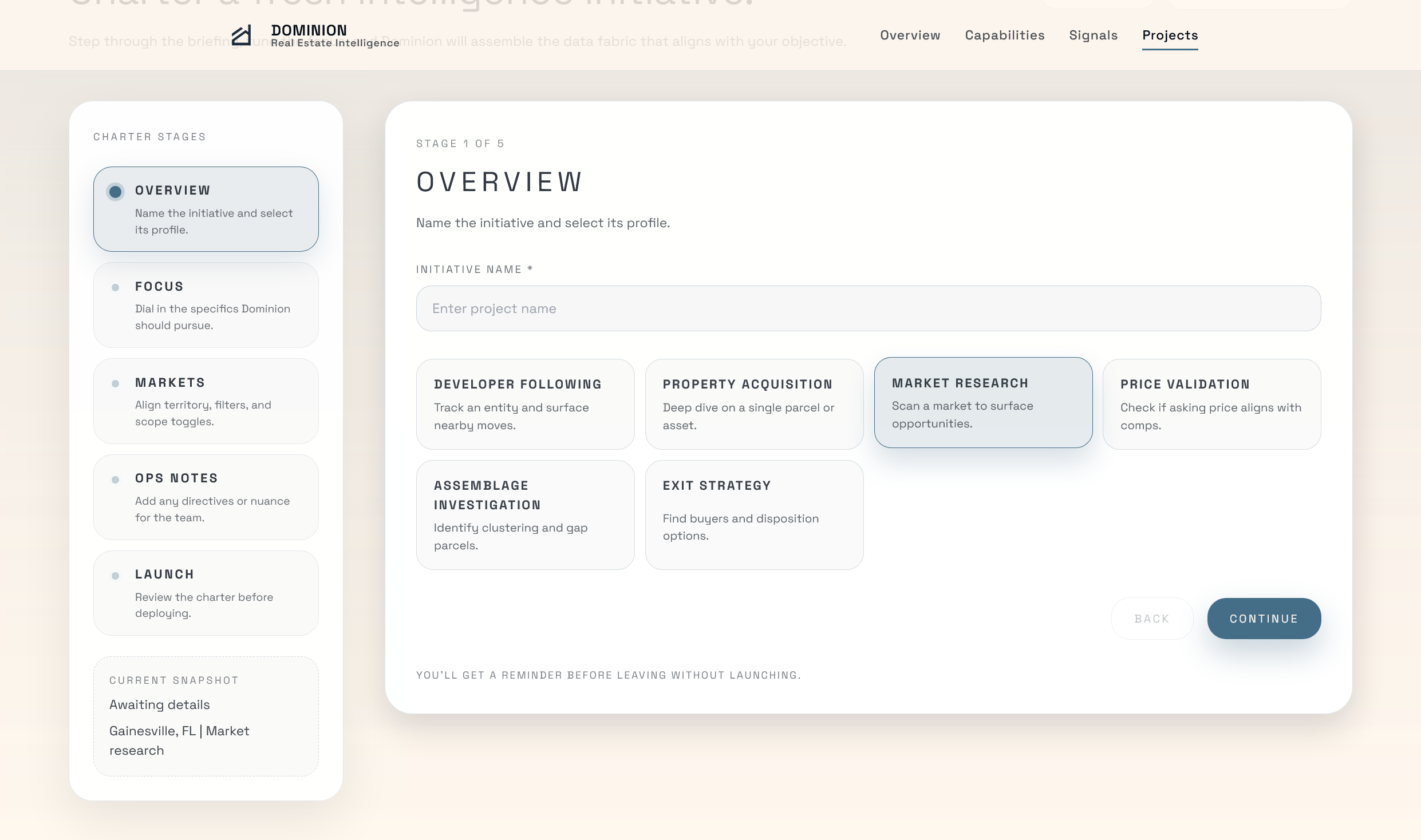
New Project Page
-
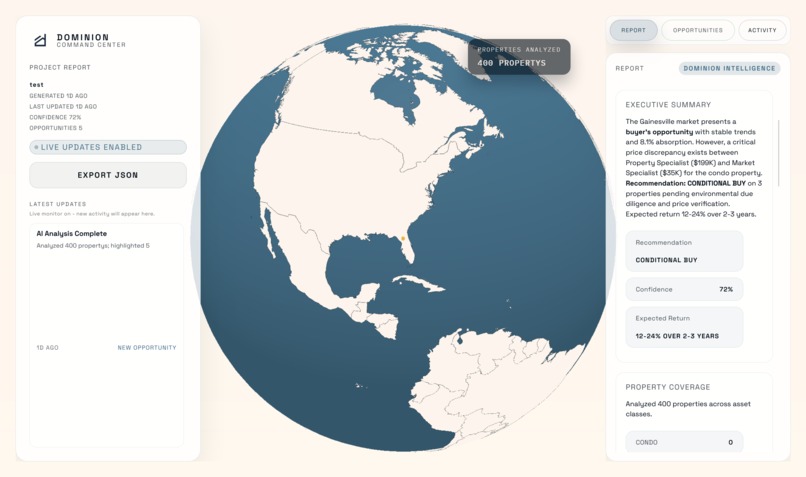
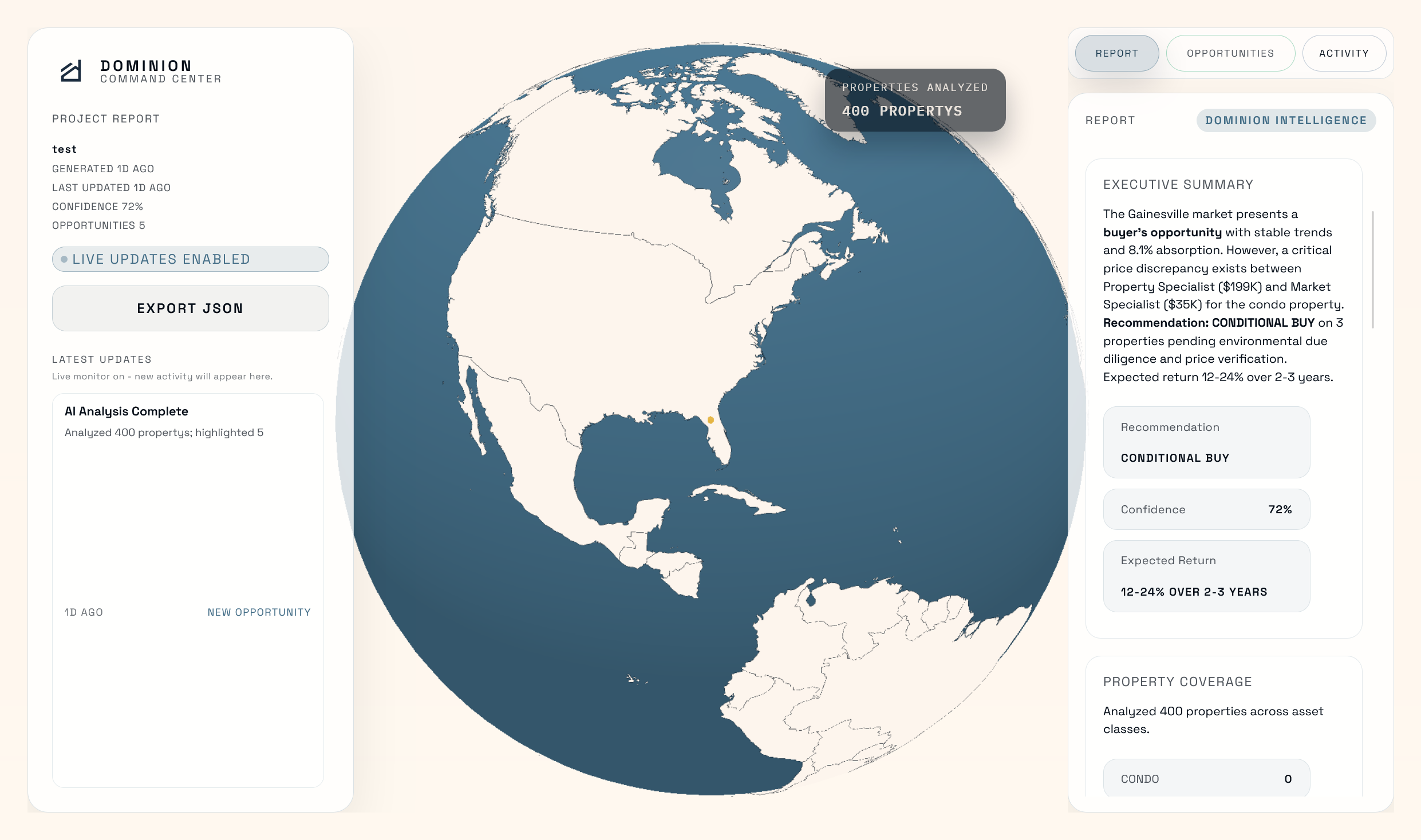
Dashboard Globe View Reports
-

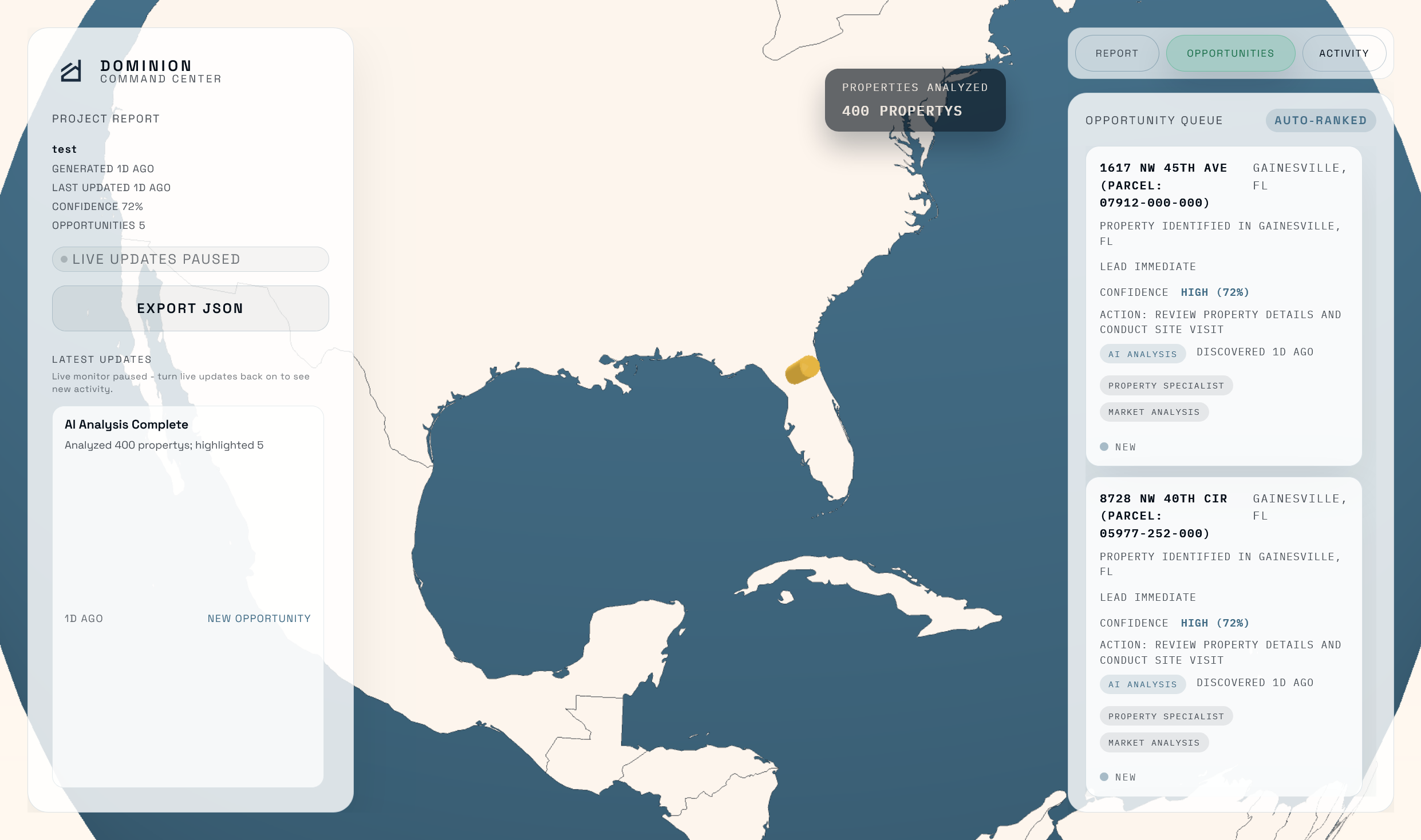
Dashboard Globe View Opportunities
-
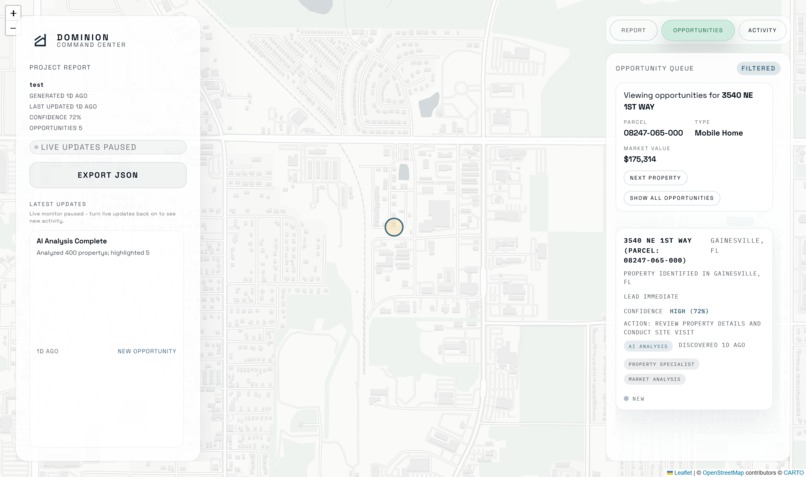
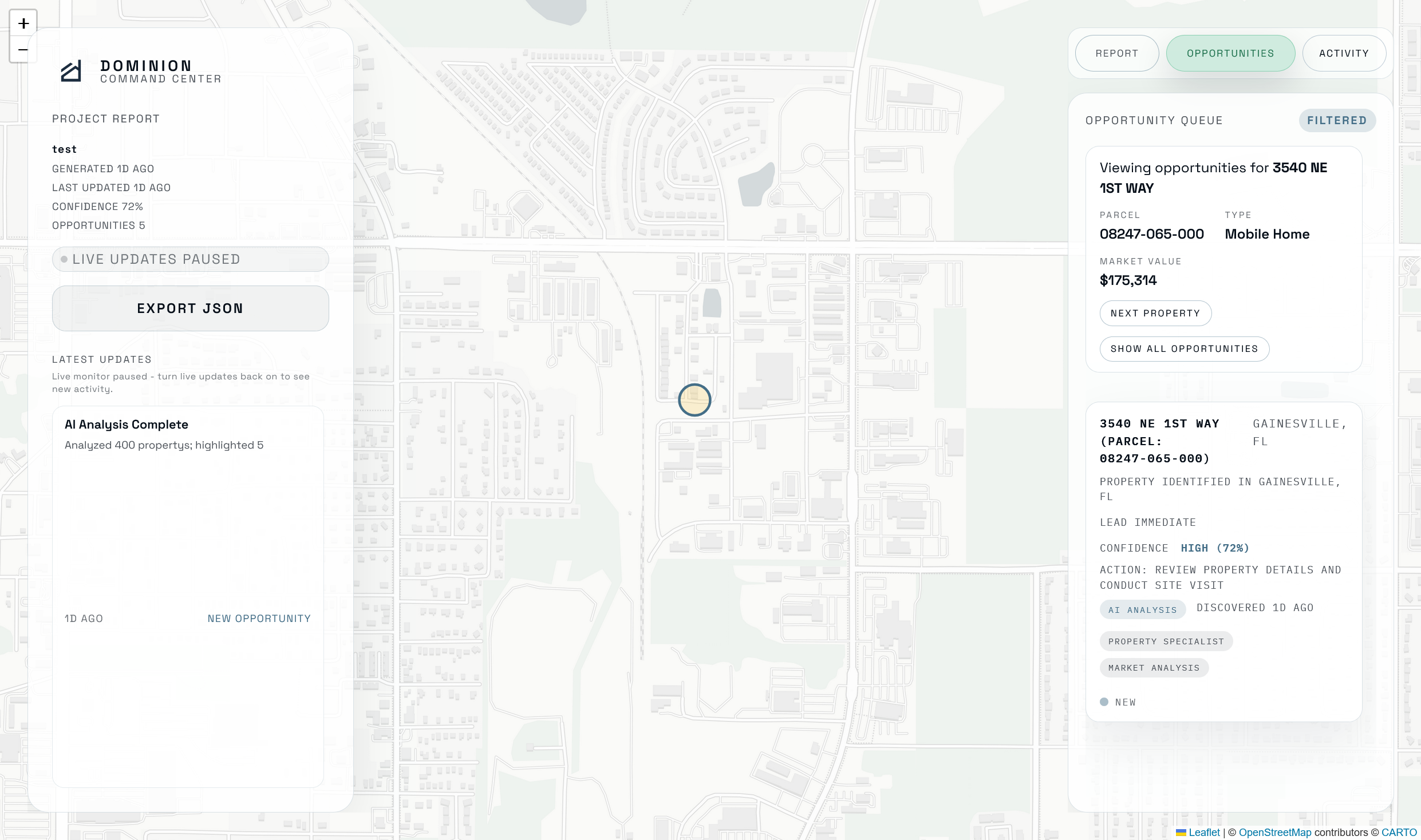
Dashboard Map View Specific Opportunity
-
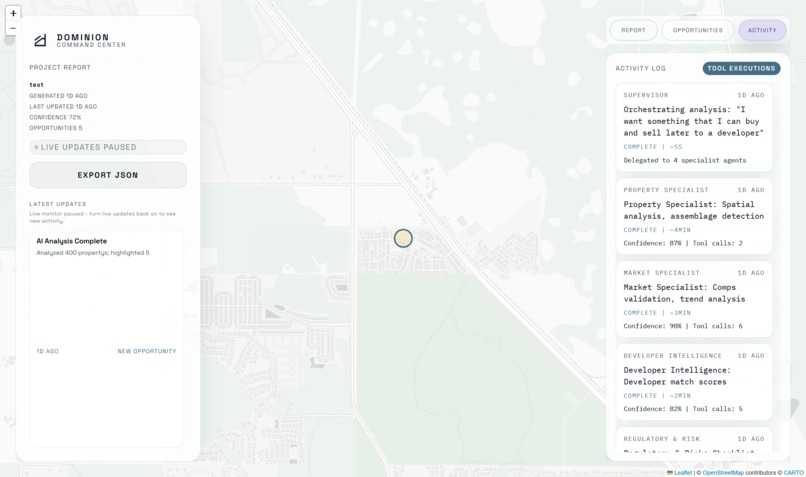
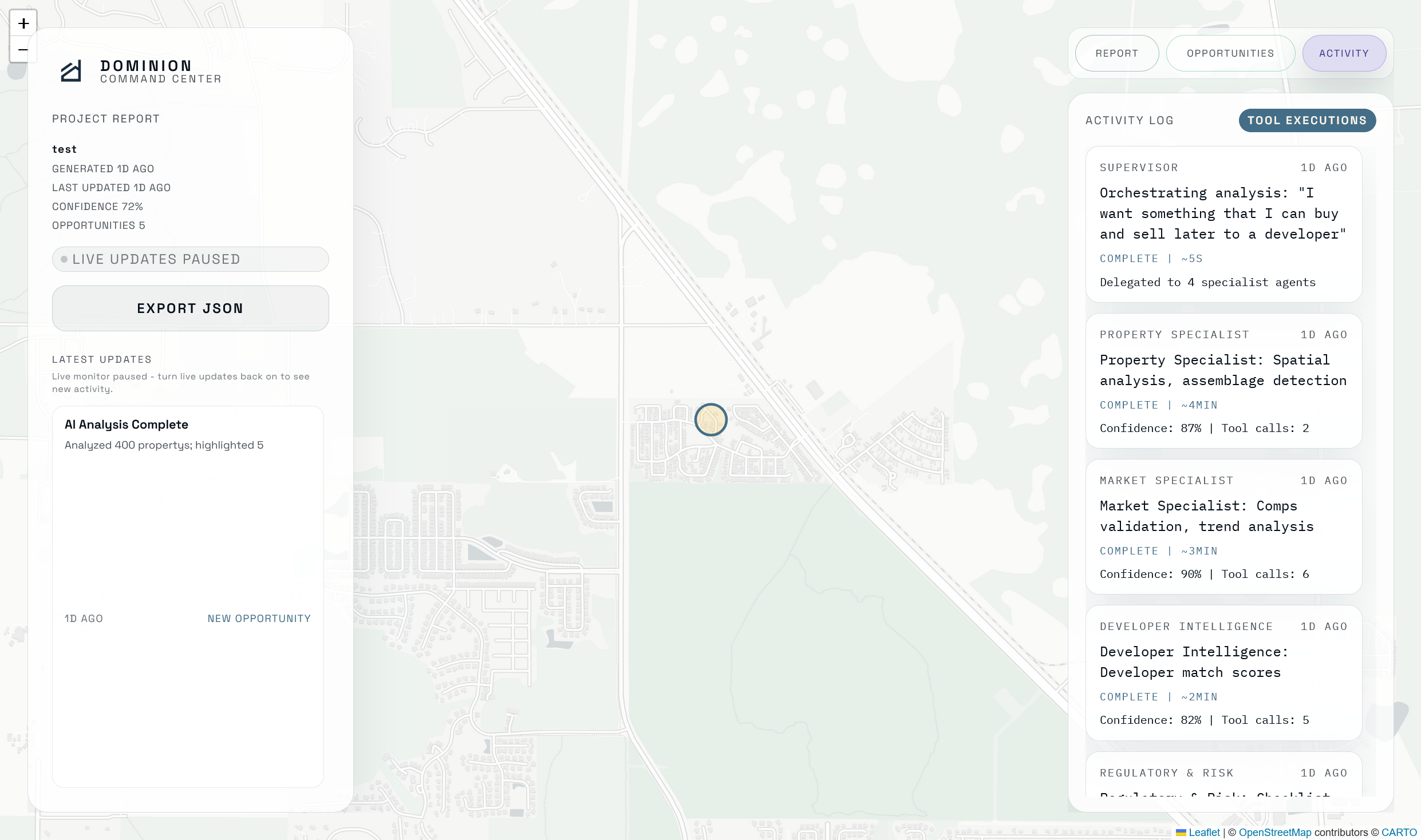
Dashboard Map View Tool Executions
-
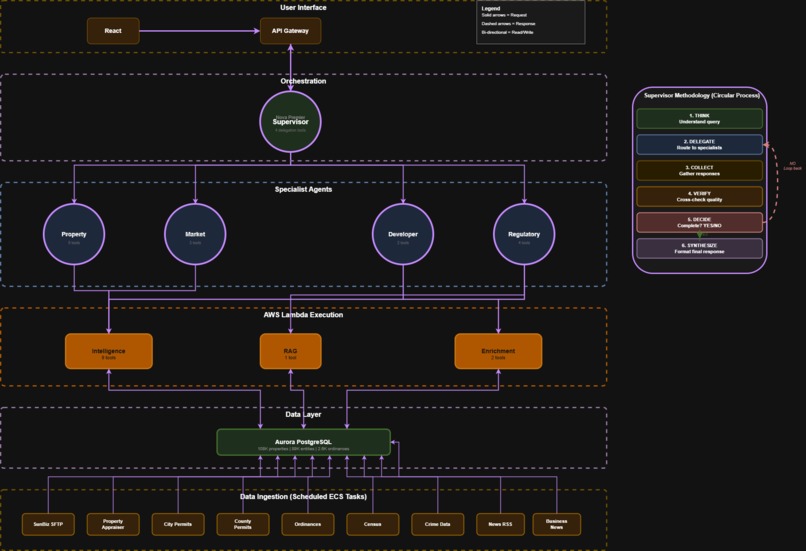
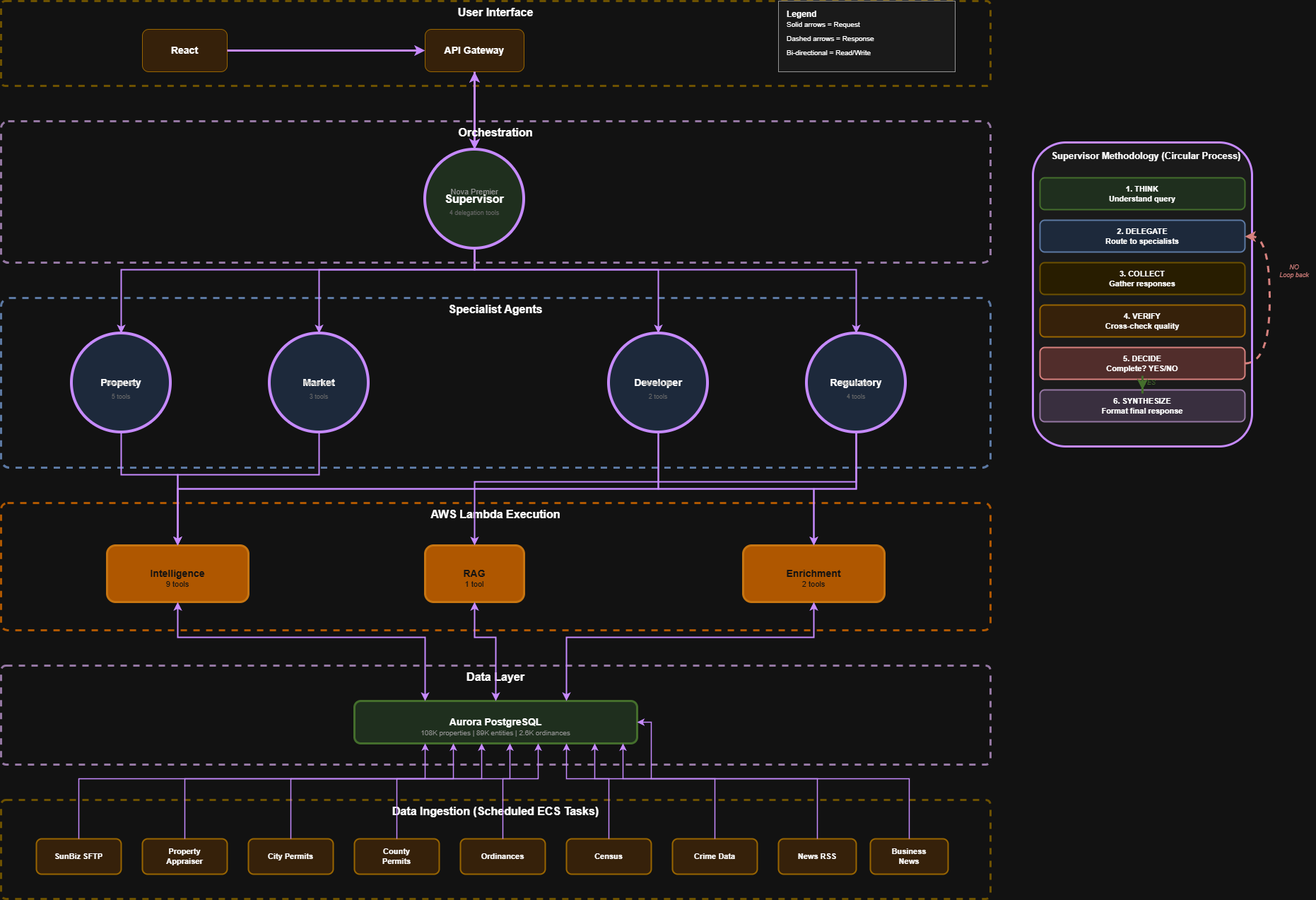
AWS Architecture Design
Inspiration
Every bad real estate deal can cost anywhere from $250K to $2M. Investors spend over 200 hours tediously filtering listings, $5,000 to $15,000 in upfront expenses, and 3 to 6 months of strenuous research, only to end up with hidden risks after committing.
Infrastructure costs weren't budgeted. Political opposition kills approvals. Environmental issues block development. Months of work wasted on deals that were destined to fail from the start.
This inefficiency is everywhere in real estate. People pour immense effort and capital into opportunities that never should have passed the first screen.
What it does
Dominion is an autonomous multi-agent AI analyst that delivers institutional-grade real estate intelligence in minutes instead of months.
Built on Amazon Bedrock AgentCore, Dominion uses a Supervisor Agent (Nova Premier) that coordinates 4 Specialist Agents (Nova Lite): Property Analysis, Market Intelligence, Developer Tracking, and Regulatory Risk. Each specialist commands dedicated Lambda tools that query 108K properties, 89K entities, and 2,588 ordinance sections stored in Aurora PostgreSQL with pgvector.
The agent validates any deal in 10 to 20 minutes instead of 3 months. It searches across 400+ properties using 42 filters, identifies developer acquisition patterns, runs professional comparable property analysis, detects assemblage opportunities through geospatial clustering, and performs zoning compliance checks. It delivers confidence-scored recommendations (BUY, CONDITIONAL BUY, or PASS) with risk assessments, expected returns, and actionable next steps, all backed by cross-verified data from multiple specialists.
How we built it
This was our first time using AWS, and we learned everything from scratch in 4 weeks.
We started with a local Python prototype (FastAPI, local Postgres, and Gemini agents) but quickly realized we needed to rebuild everything for AWS serverless architecture.
The architecture breaks down like this: React 18 + TypeScript + Vite frontend with an interactive 3D globe and 2D map visualizations. Bedrock AgentCore with Strands SDK orchestrating 1 Supervisor and 4 Specialists, with all prompts loaded from markdown files. Three Lambda functions with 12 tools total: Intelligence (9 tools), RAG (1 tool), and Enrichment (2 tools). Aurora Serverless v2 PostgreSQL with pgvector using custom BAAI/bge-large-en-v1.5 embeddings (we replaced Titan because it only hit 60% accuracy). Everything deployed through AWS CDK with 4 stacks: Database, Tools, AgentCore, and Scraper.
Data migration was brutal. We had to export from local Docker Postgres, upload to S3, use Aurora's import wizard, wait hours, then discover the first import failed and start over.
Challenges we ran into
1. Preventing Agent Hallucination
The biggest challenge was stopping the agents from making stuff up. When specialists couldn't find data, they'd fabricate property values, invent developer names, or mix data from different properties. We spent countless hours auditing model outputs, checking every claim against tool responses, and tracing reasoning chains to catch these fabrications.
The breakthrough came from building an anti-hallucination framework into every prompt. We required specialists to cite which specific tool call provided each data point and copy exact values rather than paraphrase. No rounding "$99,712" to "about $100K" or using placeholder text like "[exact value]" or "[calculate]". The supervisor agent became our last line of defense, explicitly checking for these violations before accepting any specialist response.
When a specialist violated these rules, the supervisor would reject their analysis and re-delegate with specific feedback explaining what was wrong, what data was missing, and what to do differently. For example: "REJECTED: Your analysis contains placeholder text '[calculate]' instead of actual upside percentages. You called find_comparable_properties and got avg comp price $169,500 vs market value $160,000. Calculate and show the actual upside percentage." Cross-verification across at least three sources helped catch inconsistencies that individual specialists missed. We also built mandatory thinking blocks before every delegation where the supervisor explicitly reasoned about what data was needed, whether it had that data, and what it expected back. This forced the model to be deliberate rather than reflexive, dramatically reducing hallucination rates.
2. Agent Looping Nightmares
The second major challenge was preventing infinite agent loops. We designed a circular supervisor methodology (delegate, collect, verify, accept or reject) to mimic real-world analyst teams, but this caused catastrophic looping where agents would call the same tools repeatedly with identical parameters after receiving "no data" responses, never adjusting their approach. The worst case hit 68 consecutive calls to the same specialist agent.
We solved this by implementing a MAX_REDELEGATION limit of 2 attempts per task, tracked explicitly in thinking blocks. After three total attempts, the supervisor accepts the response as final even if imperfect, notes limitations in the executive summary, and reduces the confidence score accordingly. We also added call counting, explicit rejection feedback distinguishing "missing data" from "wrong format", and phased delegation to handle dependencies. Property Specialist runs first to get real parcel IDs, then Market and Regulatory specialists receive that concrete data rather than vague instructions.
3. First-Time AWS Learning Curve
None of us had used AWS before this hackathon. Every service was new. We spent days understanding the difference between Bedrock models and AgentCore orchestration. Learning Infrastructure as Code from scratch while debugging CloudFormation stack failures was painful. Figuring out which IAM roles needed access to Aurora, Secrets Manager, and Bedrock felt like solving a puzzle with missing pieces. Understanding private subnets, NAT gateways, and security groups for Lambda-Aurora connections took longer than we'd like to admit. We optimized Docker container sizes and connection pooling to reduce 5 to 10 second cold starts. The local demo code in the src/ folder couldn't be directly used, so we rewrote everything in infrastructure/ for serverless.
4. RAG Embedding Performance
Ordinance documents use nearly identical legal language across sections, making semantic search extremely difficult. Titan embeddings gave us only about 60% retrieval accuracy, causing agents to cite wrong zoning codes. We switched to a custom BAAI/bge-large-en-v1.5 model with context-aware chunking (512 tokens, 20% overlap) and hybrid vector plus keyword search, achieving much higher recall.
5. CORS Configuration Chaos
Connecting the Vercel frontend to Lambda Function URLs required configuring CORS in 3 places: CDK stack, Lambda handler, and preflight OPTIONS handling. Debugging "No Access-Control-Allow-Origin header" errors across local dev, staging, and production environments consumed hours.
6. Prompt Engineering at Scale
The supervisor agent's prompt is 963 lines of markdown with phased delegation strategies, cross-verification rules, and anti-hallucination guards. We didn't start with that many lines. Every prompt (supervisor and all four specialists) required dozens of iterations through constant testing. The amount of times we changed one word, deployed to AWS, and tested the entire flow was crazy. Small prompt changes had massive impacts on agent behavior.
7. Time Pressure
We started September 23 (15 days late) and had only 29 days to build everything. We desperately wish we had more time for additional features, comprehensive testing, better UI polish, and a more polished demo video.
Accomplishments that we're proud of
1. Built a Production-Grade Multi-Agent System in 29 Days
Despite being AWS beginners, we deployed a fully functional multi-agent system with 1 Supervisor and 4 Specialists with distinct personas and tool access, 12 Lambda tools querying real production data (108K properties, 89K entities), custom RAG with pgvector embeddings, 10 to 20 minute analysis sessions without timeouts (async health pings), and structured JSON output for dashboard integration.
2. Solved the Agent Hallucination Problem
We implemented explicit forbidden actions in every prompt to prevent fabrication. Specialists cannot invent parcel IDs or developer names not in tool responses, cannot mix data from different properties (parcel A's price with parcel B's address), cannot paraphrase numeric values (must copy exactly: $99,712 not "about $100K"), and cannot assume field values without seeing them in tool responses. The supervisor enforces these rules by rejecting any analysis that violates them and re-delegating with specific feedback. This systematic approach dramatically reduced hallucination rates and made our multi-agent system trustworthy.
3. Solved the Agent Looping Problem
We went from 68-call infinite loops to stable, deterministic agent behavior through systematic debugging: call counting, explicit feedback loops, mandatory reasoning blocks, and retry limits. This makes our AgentCore implementation production-ready.
4. Real-World Data at Scale
Unlike synthetic demos, Dominion operates on real institutional data: 39,048 Gainesville properties, 89,189 ownership entities with fuzzy name matching and address geocoding, 2,588 ordinance sections, and geospatial assemblage detection using PostGIS.
5. Interactive Globe Visualization
The 3D globe component dynamically zooms to property locations with smooth animations, making complex real estate data engaging and intuitive. Combined with the dashboard's 3-tab interface (Report, Opportunities, Activity), users get both analytical depth and visual storytelling.
6. Reproducible Infrastructure
Everything is defined in AWS CDK. Four CloudFormation stacks deploy the entire system (Aurora, Lambdas, AgentCore, scrapers) in 15 to 20 minutes. No manual console clicking required.
What we learned
1. Building with Real Data from Day One
We focused on Alachua County because we're UF students and know the market, but more importantly, it proved the concept works with real institutional data. We built scrapers for permits, property sales, LLC filings, ordinances, GIS data, ownership records, news, and city council meetings. The dataset includes 39,048 properties, 89,189 ownership entities with fuzzy name matching and address geocoding, and 2,588 ordinance sections. This shows Dominion can actually work in production. The plan is to expand to bigger cities, then states, and eventually the whole USA, but starting local let us validate the entire system with real data instead of toy examples.
2. Architecture First, Code Second
Our biggest lesson: design your AWS architecture before writing code. We spent from September 23 to October 16 building a local Python prototype, then realized we needed to rebuild everything for AWS serverless when the hackathon deadline was approaching fast. Starting with CDK stack definitions and serverless constraints would have saved enormous time.
3. Preventing Hallucination Requires Engineering, Not Hope
We learned you cannot assume LLMs will naturally cite sources or avoid fabrication—you must engineer those behaviors through explicit prompt design, validation loops, and rejection mechanisms. Multi-agent systems amplify hallucination risk because specialists try to fill gaps with assumptions when they can't find data. The solution requires multiple defensive layers: mandatory citation of tool responses, exact value copying instead of paraphrasing, supervisor validation before accepting any specialist output, cross-verification across minimum three sources, and thinking blocks that force deliberate reasoning. We also discovered that giving specific rejection feedback ("Your response contains placeholder '[calculate]' instead of actual percentages") works far better than generic "try again" messages. The supervisor must be the last line of defense, explicitly checking for violations before synthesis.
4. Agent Orchestration is Hard
Multi-agent systems require obsessive attention to loop prevention, session isolation, structured output, and tool error handling. Phased delegation is critical. Specialists need concrete data from earlier phases, not vague instructions.
5. AWS Serverless is Powerful but Complex
Serverless scales beautifully but has a steep learning curve. IAM permissions are critical and confusing. VPC networking adds latency. CDK abstracts CloudFormation but debugging stack errors is painful. Secrets Manager and RDS Data API eliminate connection pooling headaches.
6. Team Communication is Everything
With 3 people working across backend and frontend, constant communication and staggered workflows prevented merge conflicts and integration bugs. We used clear interfaces like API contracts and JSON schemas to work in parallel.
What's next for Dominion
Dominion is an autonomous AI agent (not a platform) that replaces an entire real estate analyst team.
Over the next 12 to 18 months, we're building toward a fully autonomous real estate intelligence system. We'll add financial modeling (DCF, IRR, sensitivity analysis) so the agent can calculate actual returns instead of just identifying opportunities. We'll layer in predictive analytics with ML models that score deal success probability and political risk by analyzing city council sentiment. We’ll also integrate simulation capabilities (Monte Carlo and scenario analysis) to model uncertainty in rent growth, vacancy, and exit cap rates—enabling probabilistic forecasts instead of point estimates.
We'll expand from Gainesville to 50 markets nationwide with 24/7 monitoring that alerts investors to pre-foreclosures, assemblage opportunities, and zoning changes before competitors notice them.
The immediate next sateps are launching a pilot with 3 to 5 real estate investors in Gainesville, integrating free MLS data through HomeHarvest for rental comps, adding FEMA flood zones and EPA contamination sites for risk scoring, and building authentication for production deployment.
Dominion will transforms 3 months of fragmented research across dozens of sources into 3 hours of comprehensive analysis in one place, delivering defensible investment recommendations backed by real data.
Built With
- agentcore
- amazon-api-gateway
- amazon-aurora
- amazon-bedrock
- amazon-cloudfront
- amazon-web-services
- aws-cdk
- aws-lambda
- aws-step-functions
- docker
- node.js
- nova-lite
- nova-premier
- pgvector
- postgis
- postgresql
- python
- react
- redis
- strands-sdk
- typescript
- vercel
- vite




Log in or sign up for Devpost to join the conversation.