-
-
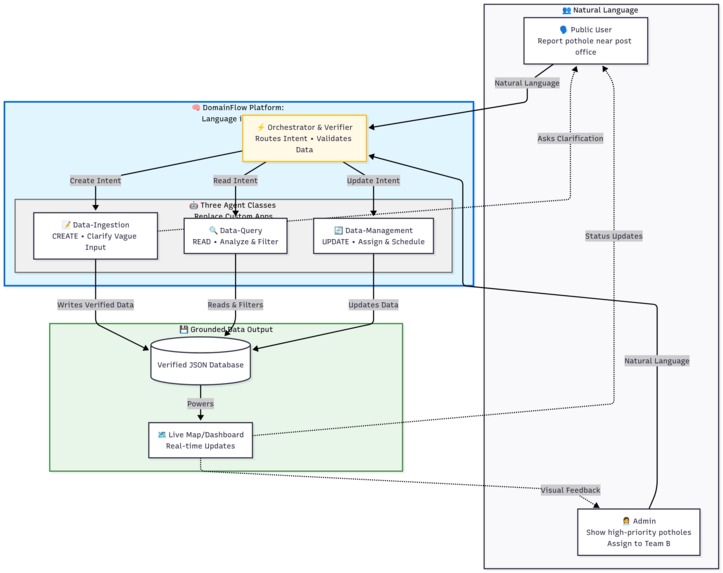
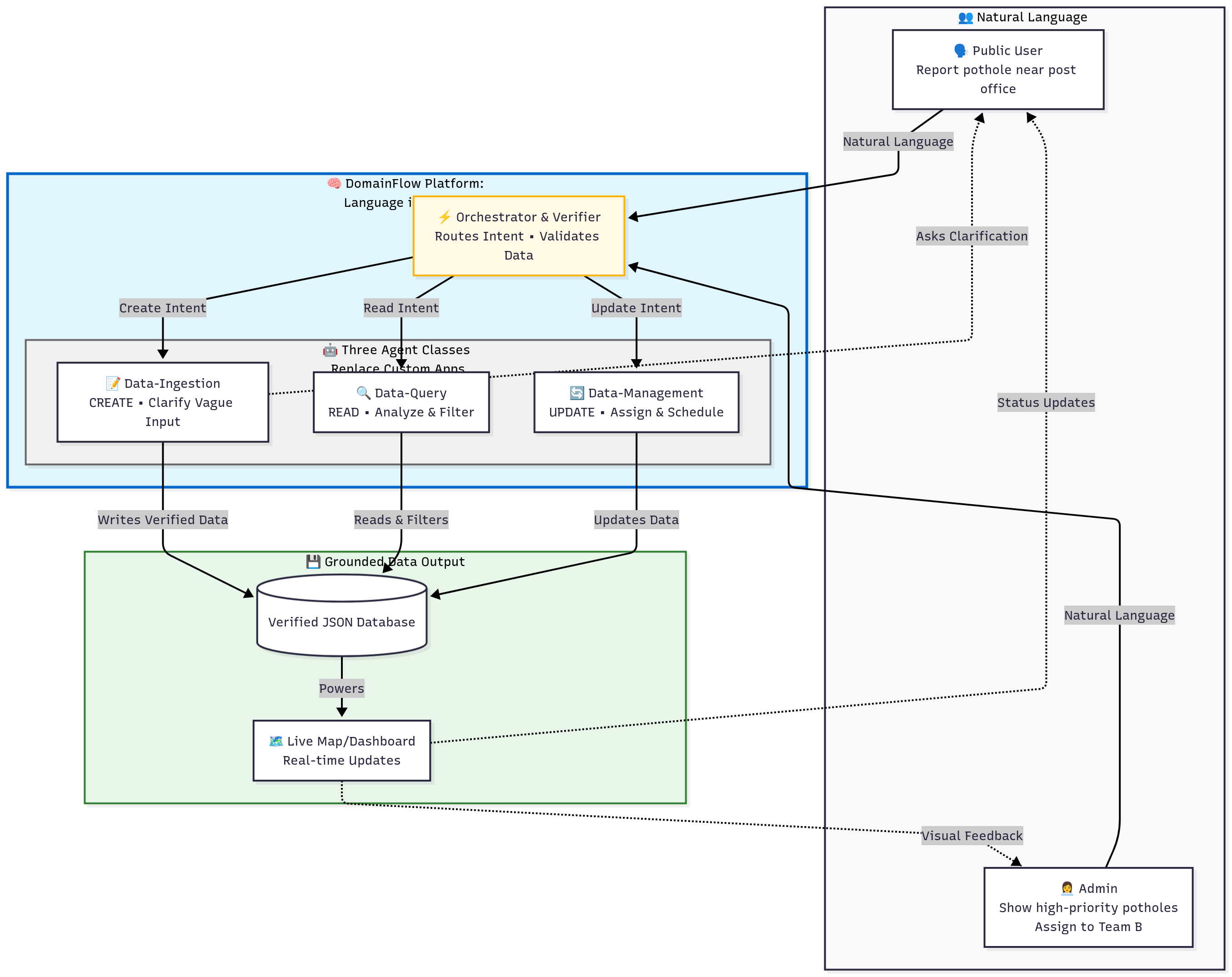
Turn natural language into verified data. Three intelligent agents (Create, Read, Update) replace custom apps—no forms, no APIs needed
Inspiration
I'm sure we've all been there: you need to build a simple data-driven app, like a contact form or a bug tracker, and it ends up being a massive project. You have to code the frontend forms, build a custom API, write rigid validation logic, and hook it all into a database. The second a user wants to change a field or add a new workflow, the whole thing has to be re-architected. It's slow and brittle.
I was inspired by the power of modern LLMs and agentic design. I asked, "What if I could stop coding rigid apps and start configuring intelligent agents? What if the application was the agent?" I wanted to build a system where I could create, analyze, and even update complex data just by talking to it.
What it does
DomainFlow is an agentic platform that replaces these rigid, custom-built apps. Instead of a developer coding a form, they configure three classes of intelligent agents:
- Data-Ingestion: This agent's job is to create new, structured data from messy, conversational language. In my demo, it's what takes a vague user report like "a pothole near the post office" and intelligently asks for clarification until it has a verified, grounded piece of data.
- Data-Query: This is the 'read' agent. It understands natural language questions like, "Show me all high-priority potholes in downtown" and translates that into a database query.
- Data-Management: This is the most powerful part. This agent handles 'write' and 'update' commands. An admin can just say, "Assign this report to Team B and make it due in 48 hours." The agent understands this intent, identifies the target data, and performs the update.
A central Orchestrator & Verifier routes every user command to the right agent and, crucially, checks its work before anything is committed to the database. This turns simple language into verified database actions.
How I built it
This project was all about designing the right meta-level architecture. The "code" isn't a long script; it's the system of prompts, agents, and verifiers.
My stack is built primarily on AWS. The core "brain" is an Orchestrator built with AWS Lambda. When a natural language request comes in, the Orchestrator's first job is to identify the user's intent (Ingest, Query, or Manage). It then routes the task to the correct agent class. These agents are powered by AWS Bedrock (using Claude 3) and are given specific playbooks that define their job. For example, the Ingestion agent is heavily prompted to be skeptical of vague data and to generate clarification questions.
The most critical piece is my Verifier layer, which is another Lambda function that double-checks the LLM's output. It confirms things like "Is this a valid GeoJSON?" or "Is this 'Team B' a real team in my system?" Only after the verifier signs off does the data get written to my Amazon DynamoDB database.
Challenges I ran into
This was, frankly, much harder than I expected. My biggest struggle by a mile was grounding the agents. By default, LLMs want to be "helpfully" creative. They will happily guess the location of "the post office." I had to put in a massive amount of prompt engineering and architectural work to force the agent to stop, admit it doesn't know, and ask for clarification.
This ties directly to consistency. Getting an agent to always output a perfect JSON schema, every single time, was a huge challenge. My Verifier layer was born from this pain; I learned you can't trust a single LLM call. You have to treat it as an untrusted input and verify its output, just like you would a user.
And then there's security and data access, which is and will continue to be my biggest challenge. How do you prevent a user from saying, "Show me all user reports," or an admin from accidentally saying, "Assign all tasks to Team B"? I started building a basic permissions check in the Orchestrator, but this is a massive area. Getting all the AWS tooling (IAM roles, Bedrock, DynamoDB) to talk to each other securely was a steep learning curve.
Accomplishments that I'm proud of
The "a-ha!" moment, the thing I'm most proud of, was seeing the full, end-to-end workflow function perfectly.
Watching a user type a vague, conversational report... seeing the agent ask for clarification... and then seeing that conversation instantly appear on the admin's map as a perfectly structured, verified JSON document was incredible.
But the real magic was the Data-Management agent. It's one thing to read data with an LLM, but to perform a verified, structured database write from a command like "Assign this to Team B" proved my core thesis. I showed that the agent can be the application.
What I learned
My single biggest takeaway is that in an agentic system, the "code" is the architecture. The real R&D isn't in the frontend; it's in the meta-level design. It’s all about defining the agents' roles, their boundaries, how they're allowed to communicate, and, most importantly, how their work is verified.
I also learned that "prompt engineering" isn't just about writing one clever "super-prompt." It's about building a system of prompts: a team of specialized agents and robust verifiers that check their work. You need a "skeptical" agent, a "formatting" agent, and a "query" agent, all working in concert.
What's next for DomainFlow: The Agent is the Application
The "Civic Complaints" domain was just my first proof-of-concept. The entire architecture was built to be domain-agnostic. My immediate next step is to prove this by configuring a completely different domain, such as "Hospital Patient-Intake" or "E-commerce Logistics," purely by writing new prompts and playbooks, not new code.
I also need to seriously invest in the security and permissions layer. My vision is a platform where you can upload any database schema, and DomainFlow will automatically configure the base Ingest, Query, and Manage agents for you, ready to be customized and deployed.


Log in or sign up for Devpost to join the conversation.