-
-
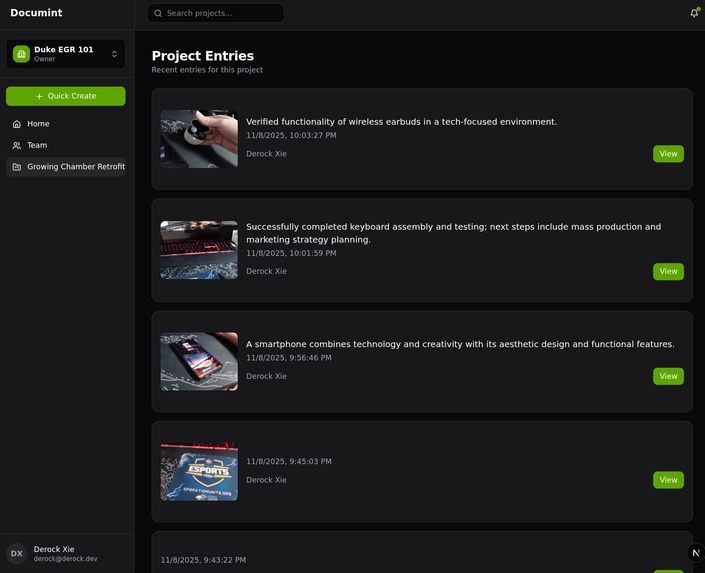
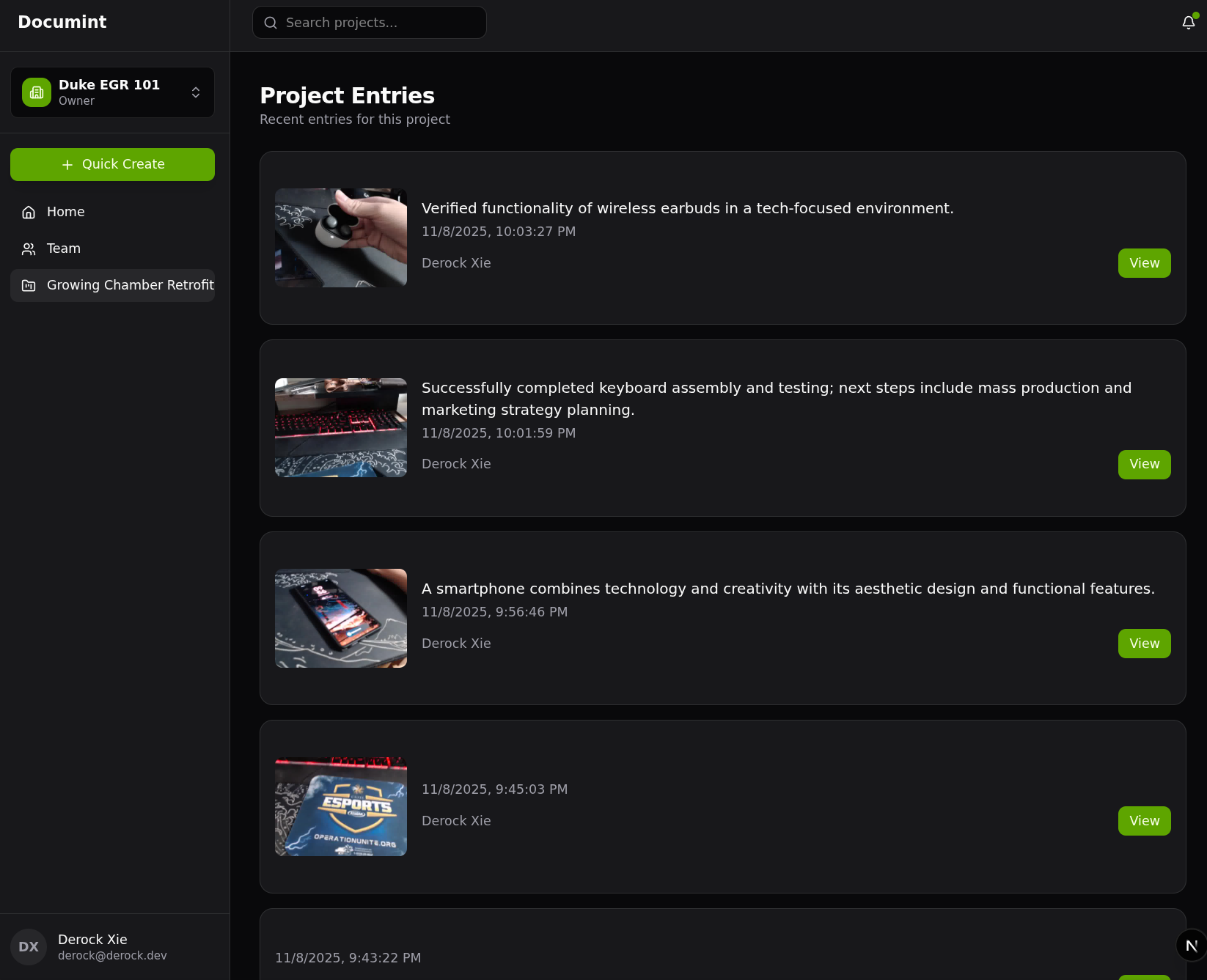
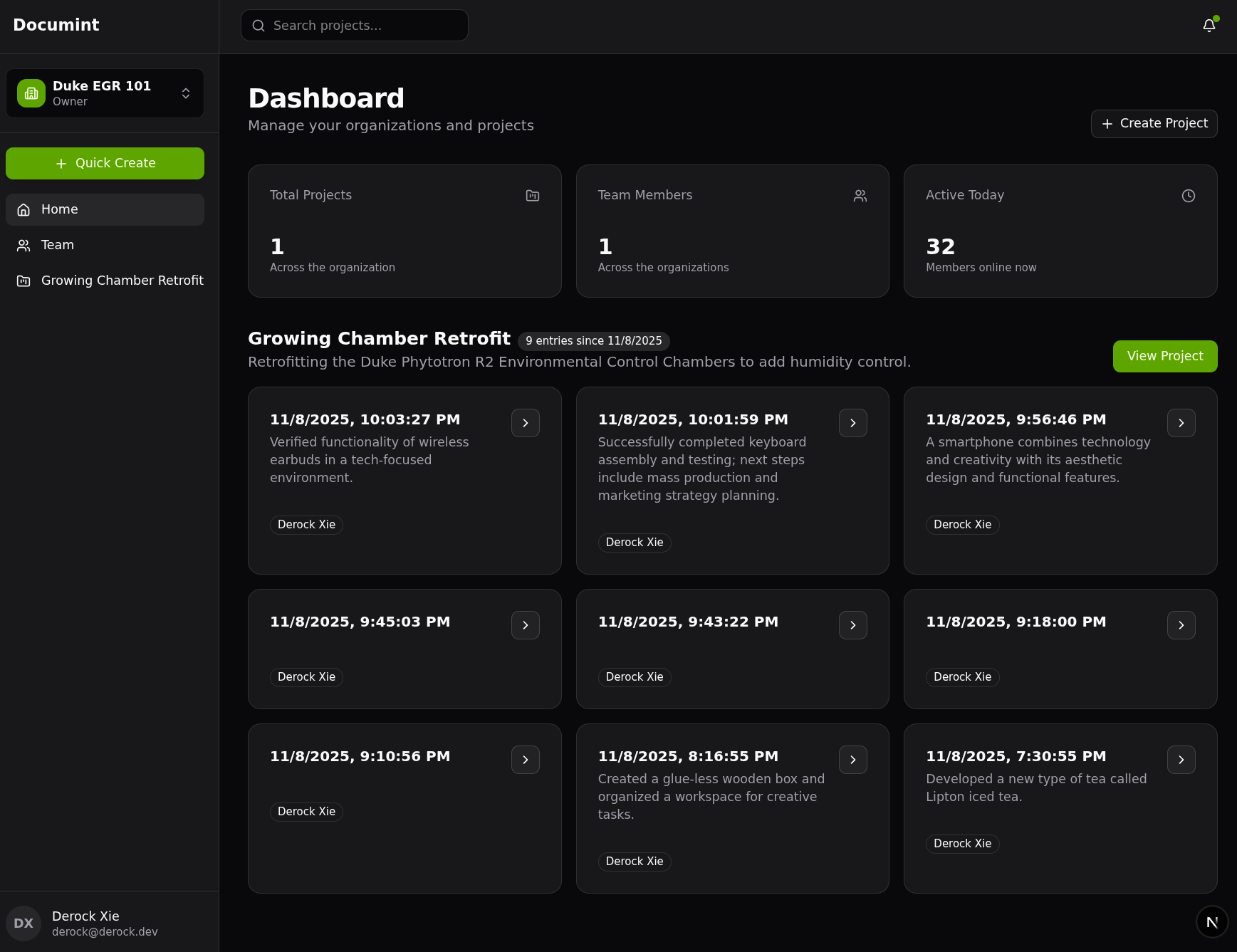
This view provides a view of the project entries, showing thumbnails from the video taken, TLDRs, author, and the option to view details.
-
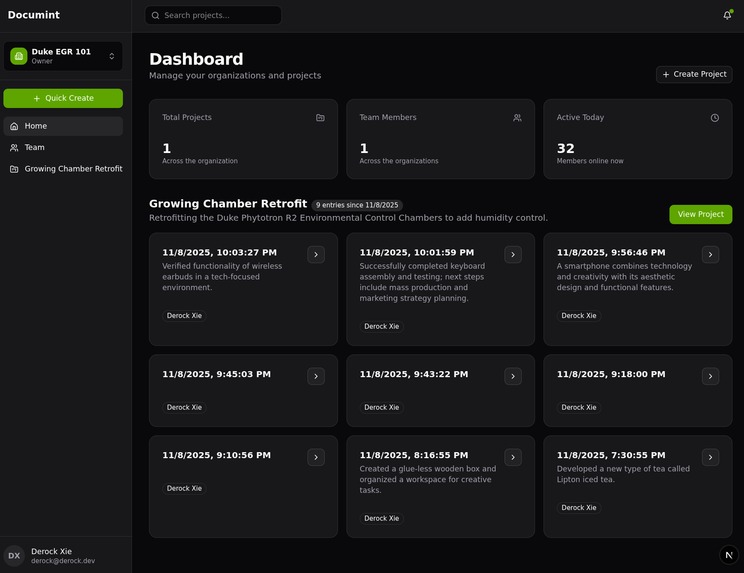
In an organization, projects will be listed out for view. The project here has multiple entries listed from previous days.
-
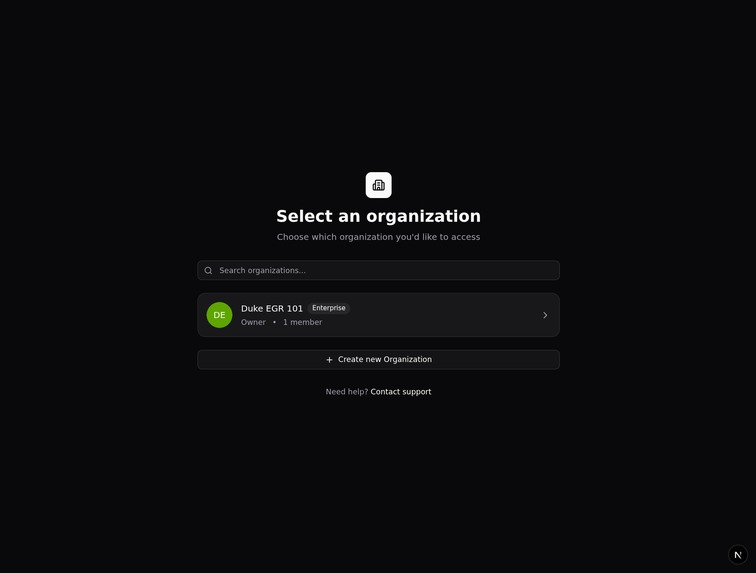
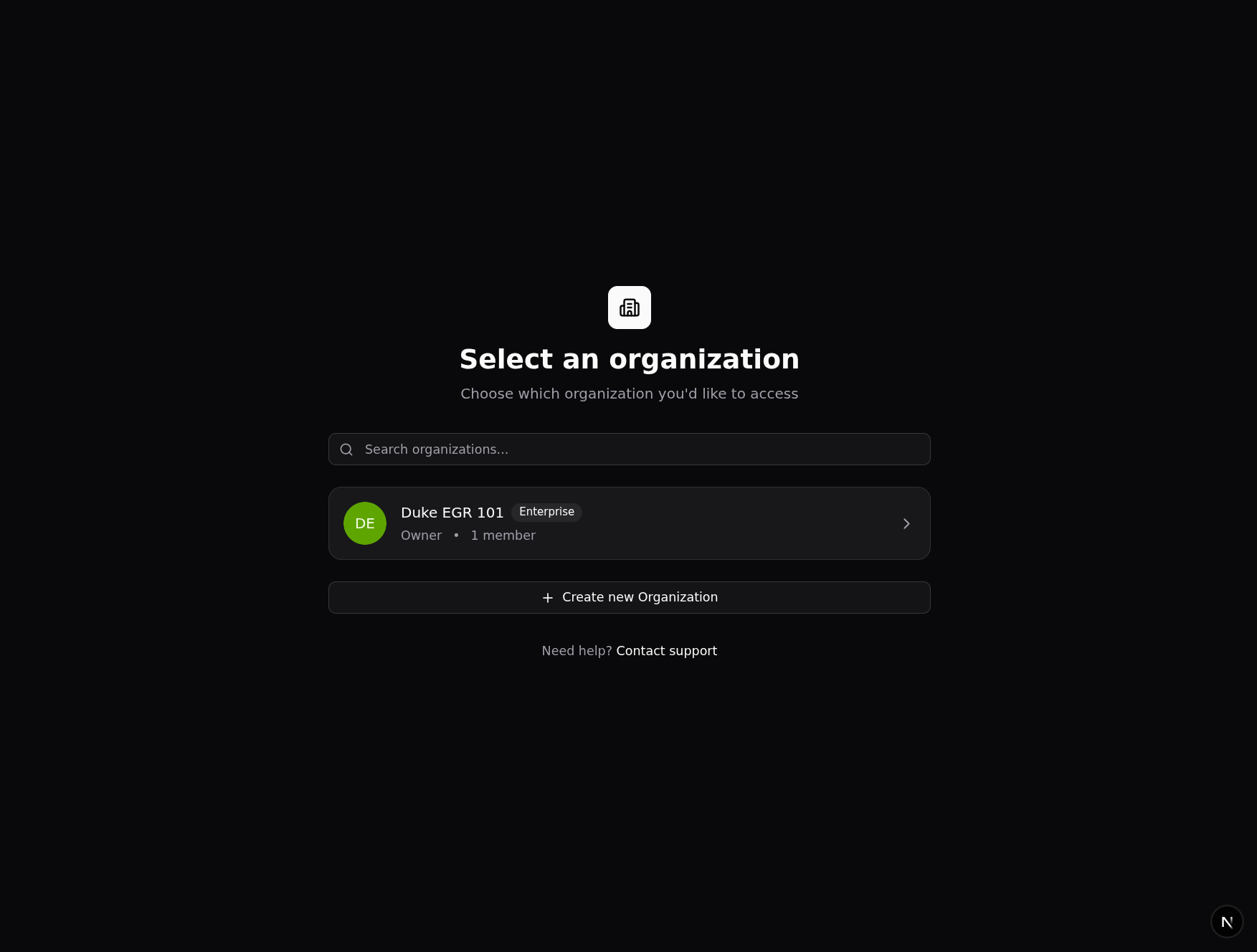
Once logged in, users can select which organization they will be working in. They also have the option to create a new organization.
-

Documint logo

Inspiration
We love making things, and so do engineers, product managers, and scientists around the world. But remember what you did, maybe a year ago, maybe a day ago, can sometimes be impossible to do.
All three of us are taking EGR 101: Engineering Design & Communication this semester. We all have struggled to stay motivated for documentation, because who wants to document their work when they could spend that time building! We wanted to build an AI-driven tool which could streamline the documentation process for everyone, from small group projects to massive enterprises.
What it does
DocuMINT is an AI powered tool which lets you easily document all the work you do! Simply create an account, join an organization, and create a project, and you can start managing an entire team's documentation in a simple dashboard!
Once you're in, you can record a video of what you have done in that day. Using the video and your verbal explanation, the application will create an entry in your dashboard, and voila! You can see a detailed description of what you've done that day. Once you create an account, you can be in multiple organizations. Each organization consists of at least one user, and can consist of multiple projects. DocuMINT is a perfect way to centralize your projects and groupwork.
How we built it
In the backend, the application using Java with the Quarkus framework. This handles everything from processing OpenAI API requests to securely authenticating users. Java/Quarkus interacts with a MySQL database. To handle file storage, we use Amazon Simple Storage Service (S3) using Garage.
Building the backend took the following steps:
- Get Quarkus set up
- Setup and design a MySQL database, determining what tables are needed
- Build basic endpoints on Quarkus
- Build authentication mechanisms and test them
- Convert Video into subsequent audio and image frames
- Write Contour edge detection on all frames to find optimal image frame with most information (thumbnail)
- Build OpenAI interactions using their Java API feeding in audio for whisper and the optimal image frame
- Allow video files to be built in and uploaded to S3
- Build extra endpoints giving necessarily data to the frontend
The frontend had a linear progression:
- Get React.js set up
- Build authentication page and inputs
- Build dashboard and inputs to create an organization/choose which organizations to view
- In an organization, list out the projects and analytics about the projects
- In projects, allow the recording and uploading of videos
- In projects, allow the display of both TLDR, detailed information, and analytics
Challenges we ran into
This was our first time building a backend using Quarkus, so we ran into multiple challenges making sure that we provided a secure application which interacted with the database.
- Uploading to S3: uploading to the S3 database from files from the frontend posed many challenges because of our method to handle file extensions. Essentially, the files passed in did not have a file extension in the filename. We were able to fix this by including “application/octet-stream” to handle video files which did not have a file extension. Right now, the uploading will handle videos and image thumbnails.
- Camera feed: accessing the camera feed on the frontend, and then passing in the resulting video created issues Different dependencies were missing features or were not compatible. We fixed this by implementing the ability with cameras by ourselves.
- Prompt Engineering: previous iterations of prompt engineering were too specific and would not return a result if there wasn’t sufficient information. However the threshold for sufficient information was interpreted as very high for gpt 4o-mini, so in cases where there was enough information present nothing was being outputted.
Updated prompts to extract the max amount of information from an image if it deemed there was not enough information from an image. This handled cases where gpt-4 deemed there was not enough information to update.
Accomplishments that we're proud of
First off, we are proud that we got a working full stack project in less than 40 hours. We are proud that we created a slick interactive front end. We are proud that we created an efficient backend. We are proud that our video processing produces thumbnails and audio for seamless integration with OpenAI. But most importantly, we are proud of teamwork and perseverance to create a project that truly helps people.
What we learned
We learned plenty of new skills and built on existing skills significantly. The members who worked on the backend did not have extensive knowledge and experience on coding a proper backend (one member hasn’t even coded a backend before). But through extensive research, reference sheets, and the effective use of AI-assisted coding tools both members who coded the backend learned various new skills including: Database management, MySQL, Rest endpoints, Quarkus, FFmpeg, and so much more. Furthermore, the user who coded the frontend learned how to make a webcam work in React. The most important skill that we learned however was to work efficiently as a team. Splitting up work, adhering to each individual member's strengths, and maintaining clear communication allowed us to effectively create a new fullstack project from scratch!
What's next for DocuMINT
DocuMINT has the potential to change the way that organizations approach their workflow. By allowing more time to be spent on projects and tasks that significantly improve the company, productivity skyrockets, innovation flourishes, and overall efficiency improves.
In the future, we will implement pricing plans per organization:
- Free: 3 projects, shared with 3 people max
- 1 minutes recording max
- Pro: 20 projects, shared with 10 people max
- 5 minute recording max
- Scale: 100 projects, shared with 50 people max
- Access to choosing models which process requests
- 10 minute recording max
- Enterprise: no restrictions on projects and people
- Use their own enterprise domain
- Data is separated from others
- All the benefits in Scale and below
- 30 minute recording max
Future plans regarding technical advancements include making the current backend much more secure, using NLP to record emotion analysis, and updating the backend and frontend to account for pricing plans.

Log in or sign up for Devpost to join the conversation.