-
Demo
In today's digital age, PDF (Portable Document Format) has become one of the most widely used formats for sharing and storing documents. files are known for their ability to preserve the formatting and layout of the original document, making them an ideal choice for various purposes, such as academic research, professional reports, and legal documents. However, as the size and complexity of these documents increase, navigating through them and locating specific information can become a daunting and time-consuming task.
Traditional search methods, such as keyword-based search, often fall short in providing accurate and relevant results, especially when dealing with large PDF documents. This is because keyword-based search relies on exact word matches, which may not always capture the true context or meaning of the information being sought. Furthermore, the linear structure of PDF files makes it difficult to quickly skim through the content and identify relevant sections.
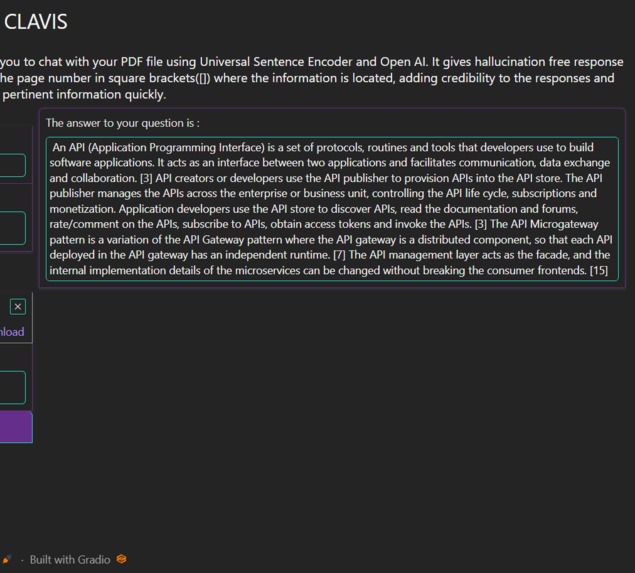
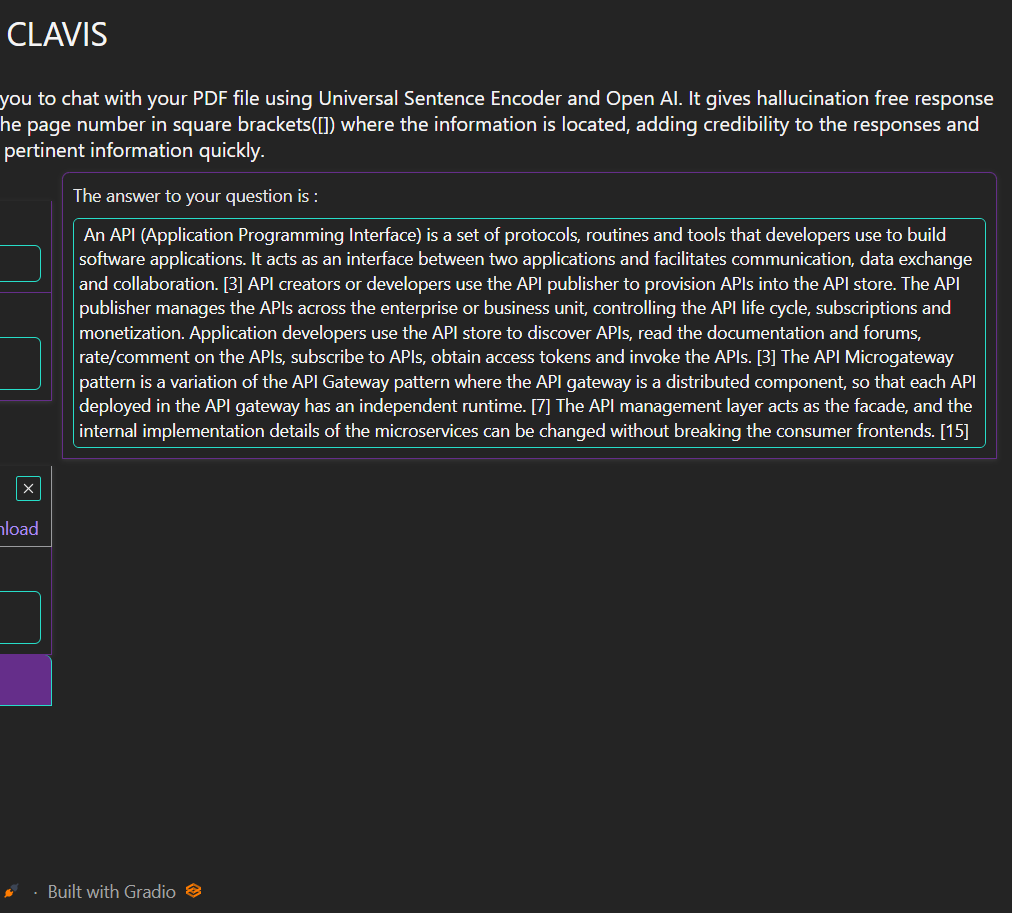
This is where CLAVIS comes into play. By leveraging the power of the Universal Sentence Encoder and OpenAI's GPT-3, CLAVIS aims to revolutionize the way users interact with PDF files. This powerful tool can perform semantic search on PDF documents and generate answers to user questions, making it an invaluable resource for quickly finding relevant information within large and complex PDF files. The development of CLAVIS is motivated by the need to overcome the limitations of traditional search methods and provide a more efficient, accurate, and user-friendly solution for navigating and exploring PDF documents.
Built With
- numpy
- openai
- pymupdf
- python
- scikit-learn
- tensorflow
- tensorflow-hub

Log in or sign up for Devpost to join the conversation.