-
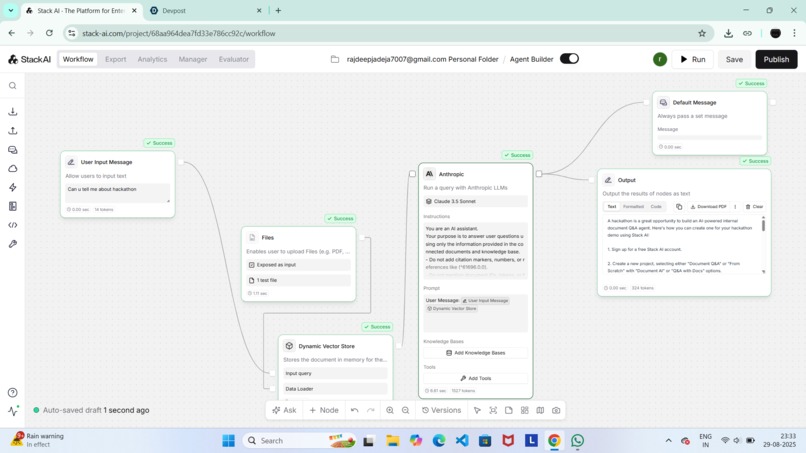
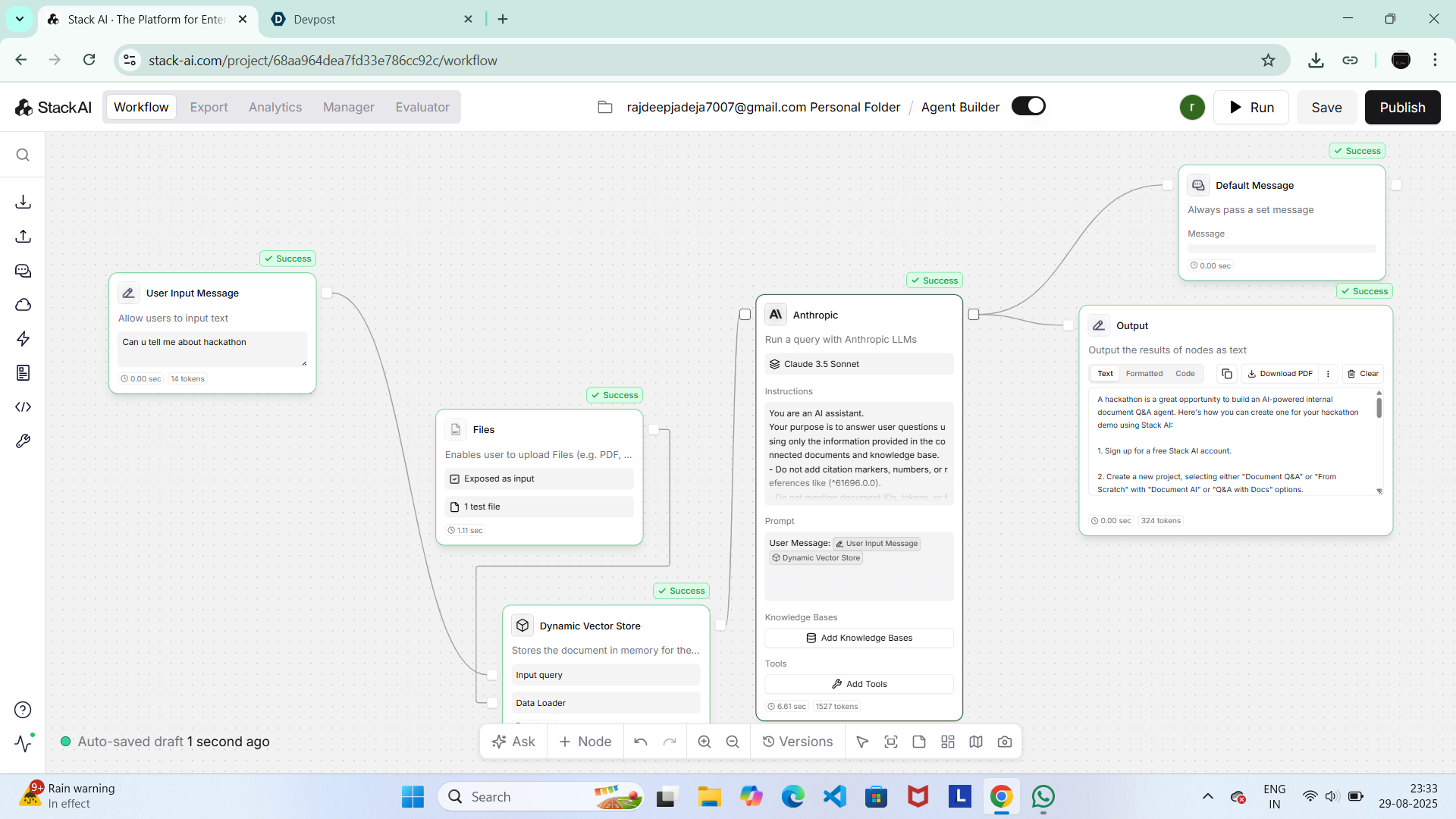
Workflow Design built in stack Ai
-
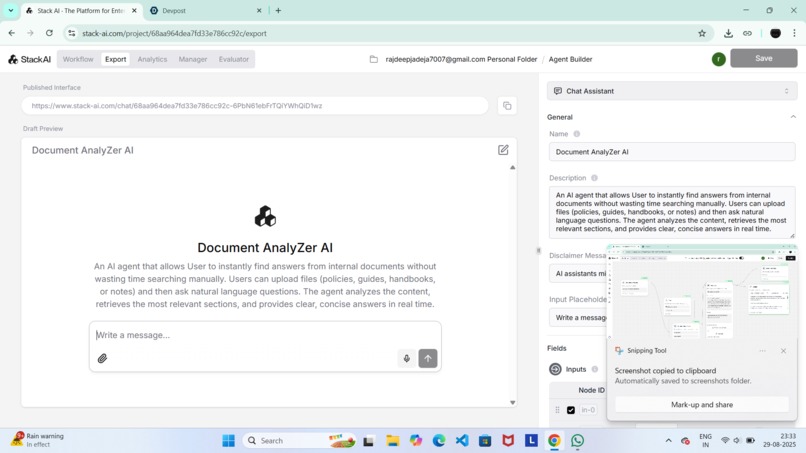
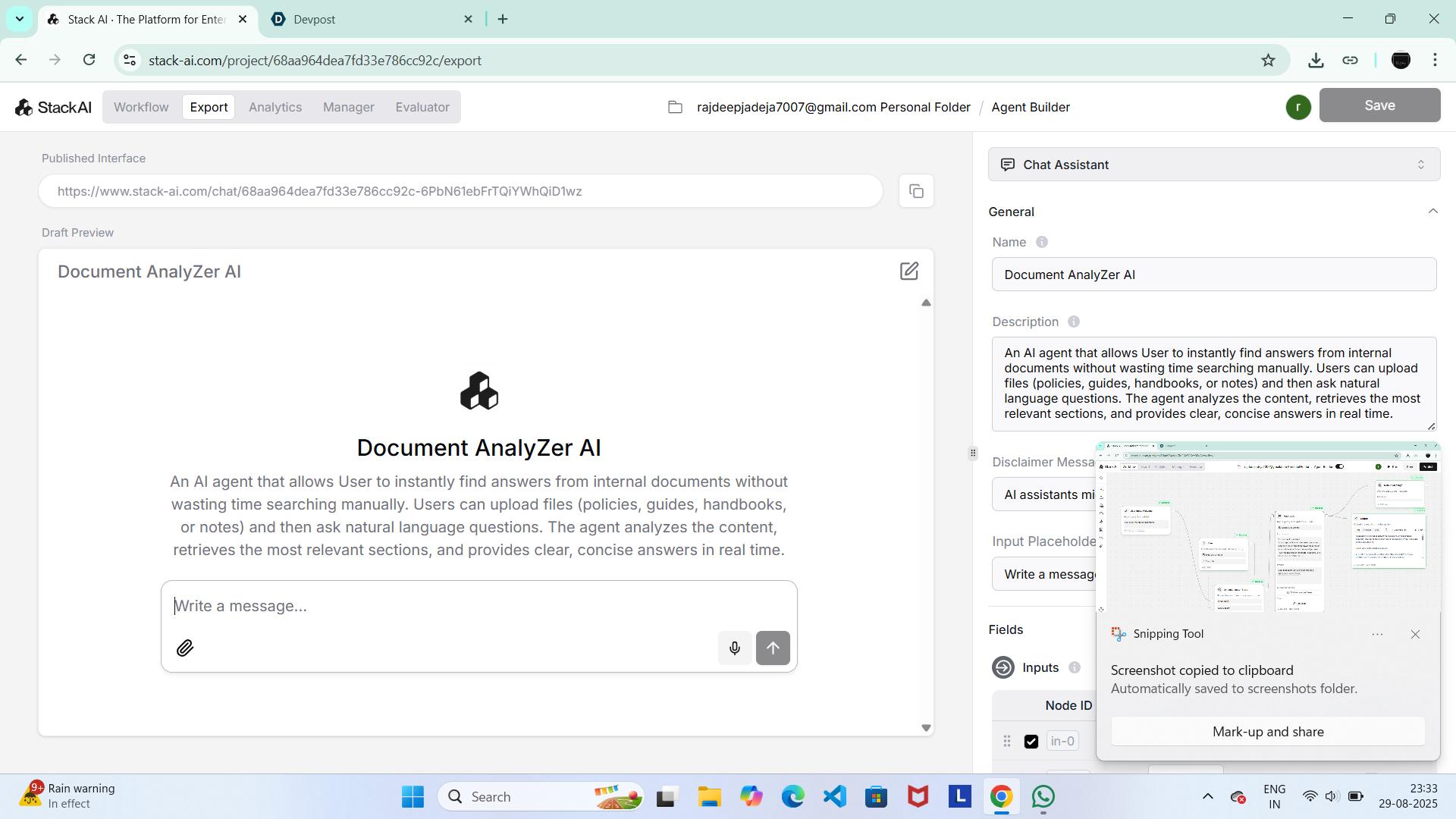
My solution which is hosted will look like this
Inspiration
As a college student I have experienced the pain of scrolling through long PDFs, policies, or handbooks just to find one small piece of information. So I was inspired solve this problem with AI — to make documents searchable by meaning, not just keywords.
What it does
Document AnalyZer AI is an AI-powered agent that: Lets users upload files (PDFs, handbooks, notes, guides). Accepts natural language questions from the user. Analyzes and retrieves the most relevant sections.
How we built it
Document Processing: Uploaded files are broken into chunks and embedded into vector space. Vector Search: When a question is asked, the system compares it with the embeddings to find the most relevant sections. Answer Generation: An LLM (via Stack AI & Claude from anthropic) summarizes and delivers a precise answer.
Platform: Built using Stack AI for orchestration and deployment, with Claude (3.5 Sonnet) embeddings + vector database for retrieval.
Challenges we ran into
Creating a smooth user flow for uploading documents and asking questions. Handling differences between various document formats.
Accomplishments that we're proud of
I Built a fully functional hosted agent within hackathon time. Created a solution that is useful not only for hackathons but also for real-world productivity.
What we learned
Importance of prompt design and evaluation for improving accuracy. How to make Ai agents Using Different Tools
What's next for Document Analyzer AI
I am thinking of including functionality that the user should be able to insert files from Google Drive.
Built With
- anthropic-claude-3.5-sonnet
- langchain
- llm
- python
- rag
- stack-ai
- vector-database


Log in or sign up for Devpost to join the conversation.