-
-

Use the Model Creation collection to generate markdown tables of your request and response objects
-

Create reports for each of your collections and find out how you can improve your documentation
-

Use Postman monitors and our Slack integration to keep up with your team's progress throughout the week.


Inspiration
We’ve been working with Postman documentation for years as it provides value for users both inside our own organization and our clients. Along the way, we encountered a few gaps in postman that we have tried to fill in ad hoc ways.
We saw the hackathon as a chance to address these gaps in a more formal, publicly-available way, so that everyone can have the resources to create top-tier documentation with the postman platform.
What it does
Currently Docu-Mentor has two functionalities:
Documentation Assistant:
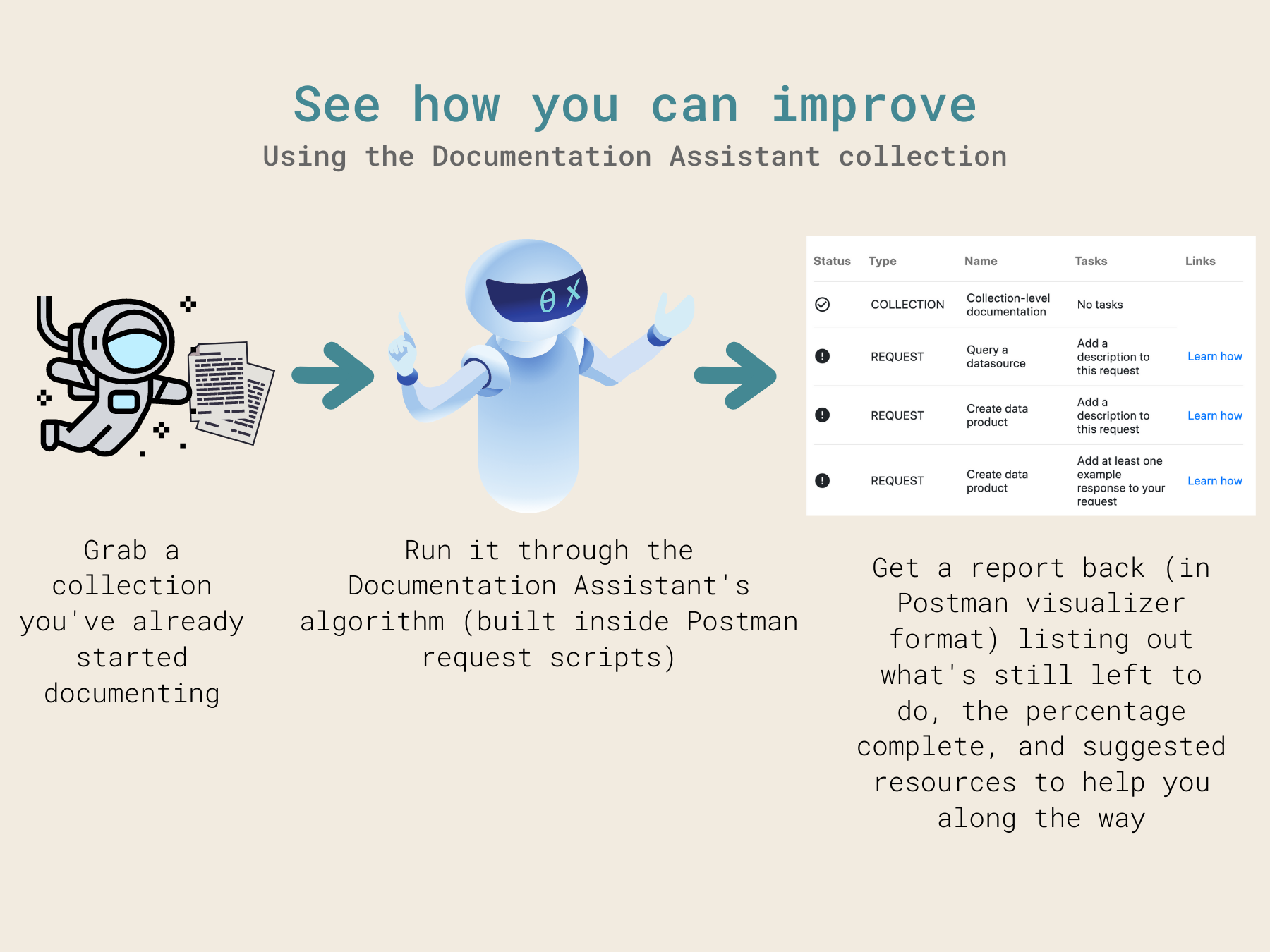
For our team at least, documenting an API or Postman collection happens over time, rather than all at once. Especially as collections get longer and your team’s collection of collections grows larger, it can be easy to lose track of what still needs to be done. With the documentation assistant (which is really just a series of postman scripts), you can keep track of how far along each of your collections are in the documentation process. When you’re ready to focus on one in particular, you can drill down into the to-do list to see the tasks that still need to be done, and work to achieve the coveted 100% completion score.
Model Generation
When working with Postman to create API documentation, one aspect we felt was missing (after migrating from the Open API spec) was a way to describe the models that are passed back and forth in the requests. Postman provides example responses, but there is no way to describe the properties of the response, what they are, and where they are used in the API. The model generation functionality will evaluate JSON request and response bodies, and build up empty requests to store these objects properties in the request description. It will provide the links between models and the requests that use them. This provides a single place for developers to document the properties of their models in a way that users can understand the models better.
How we built it
Documentation Assistant
We decided to build the documentation assistant completely inside of Postman, so that it would be super accessible to those who wanted to customize the tasks or guidelines (or grade on a curve). To do this, we used the Postman API to get both the list of collections inside a workspace and a single collection’s details, and processed the content in pre-request and test scripts throughout the workflow, utilizing collection and environment variables. We also built two ways of accessing the results. For those who are actively working on their projects inside of Postman, we included visualizer outputs to give immediate feedback. For those who’d like to stay informed and on top of their documentation progress but aren’t necessarily spending all day in the Postman app, we added a Slack integration as well. Though we have used the built-in Postman/Slack integration in the past to send monitor results to Slack, we wanted a completely custom report to display all of the detail we were gathering, so we opted for using a monitor to run our Slack webhook requests.
Model Generation
The model generation component is created as a REST API written in Java with Spring. (Its open-source and available here) It uses the open source postman model created by MTNA. It uses this to parse incoming collections, locate their request and response bodies that are written in JSON and parse those to create the models.
Challenges we ran into
Documentation Assistant
Getting all of the information I needed from the Postman API at the right time to build out the different reports while keeping the collection as short and user-friendly as possible was a challenge. I ended up reusing some functions across requests and sending some async requests inside of scripts to grab other pieces of information I needed, which wasn’t super clean, but got the job done.
Model Generation
The hardest thing about the model generation is trying to come up with a way to link things in a way that works with Postman. The links work in the published documentation, but in the workspaces the links don’t seem to open other requests or anything like that. Trying to communicate where people can go to find the information needed was an interesting challenge to try to address.
Limitations
Documentation Assistant
Because we opted for a completely Postman-based app, the Slack interactivity is limited. It didn’t seem possible to create a back-and-forth conversation with the Slack bot with only incoming webhooks. I think if this were rebuilt on a server, you could do some really cool things around writing docs right from slack (described in the “what’s next” section), or have a smoother workflow where you could pick a collection to get a report about from the list of workspace collections.
Model Generation
Currently the model creation aspect of Docu-Mentor only works with request and response bodies that are written with a content-type of application/json.
Accomplishments that we're proud of
Carson
I had only ever used the most basic of Slack integrations, but figuring out how to build up the Slack “blocks” to create richer messages right from Postman was really fun and gratifying to play around with. I am going to have to actively refrain from making everything into a Slack app from now on.
Andrew
I am most proud of using the Postman and Docu-Mentor API to come up with a workflow that seems effective and unobtrusive. By using both, the users can keep their Postman credentials private but provide Docu-Mentor with the information needed to adjust the users collections. The ability to fork a collection that Postman provides is a great way to incorporate Docu-Mentor in a production environment, adjusting the documentation and merging it in when the changes are complete.
What we learned
I think we both learned a lot about the Postman API--both things we didn’t know it could do (creating monitors and working with workspaces), and things we thought would be possible but weren’t (saving example responses, accessing certain properties we needed).
Incorporating into your own workflow
These two programs work well when used together or separately, and are meant to be unobtrusive additions to your current documentation process. All of your credentials are able to be kept secret, and we do not store anything on our end.
To get the full detail of how to use them (and to keep this section from becoming unbearably long), we recommend either watching the video tutorial above, visiting the workspace documentation for an overview, or going straight to docs for the Documentation Assistant or the Model Creation Collection.
In short, you can send the requests in the Documentation Assistant to get reports detailing your documentation progress either in the visualizer response pane or sent to you in Slack, then head over to the Model Creation collection and follow the workflow of requests to fork a collection of your choosing, generate object model tables via our API, insert them into your forked collection, and merge them back into your original collection. Here is an example of docs that have the object model tables if you'd like to poke around.
What's next for Docu-Mentor:
Documentation Assistant
I think it would be great to be able to run some text analysis on already written documentation, and be able to give more specific suggestions about what to include, especially at the collection level, which is a common place to give a thorough overview of an API. Some examples of things I would check for are a word count (probably need at least 100-200 words to give a good overview of an API), making sure I had a standard set of markdown headers (like “##Getting Started”, “##Creator information”, “##Setting up Authorization”, etc.), and maybe that I had at least a certain number of links included.
I had also thought about making the Slack bot much more interactive, possibly with the ability to edit your docs right from slack. An implementation of this might look like a daily prompt from the slack bot that asks you short questions about your collection like, “What do users need to know about authorization to use this collection” or “Are there any existing tutorial resources available for this API?” The backend could then weave these together to build up a thorough introduction over time.
Model Generator
Model updates. Assuming users have generated their models and added descriptions to them, when they make changes to their API (adding / removing properties from the models) we would like to be able to identify models, match them with the updates, and update their documentation accordingly so that users can just describe the newly added properties without having to redo the documentation that they had previously added.
Built With
- java
- javascript
- postman
- rest
- slack
- spring
- webhooks










Log in or sign up for Devpost to join the conversation.