


Inspiration
I built DocTalk because my aging parents - and many others - struggle to understand medical forms and lab reports. With today’s AI, we can finally turn dense PDFs and images into clear, cited explanations while keeping privacy non‑negotiable. DocTalk explores how powerful tools can deliver comprehension and confidence without trading away sensitive data.
What it does
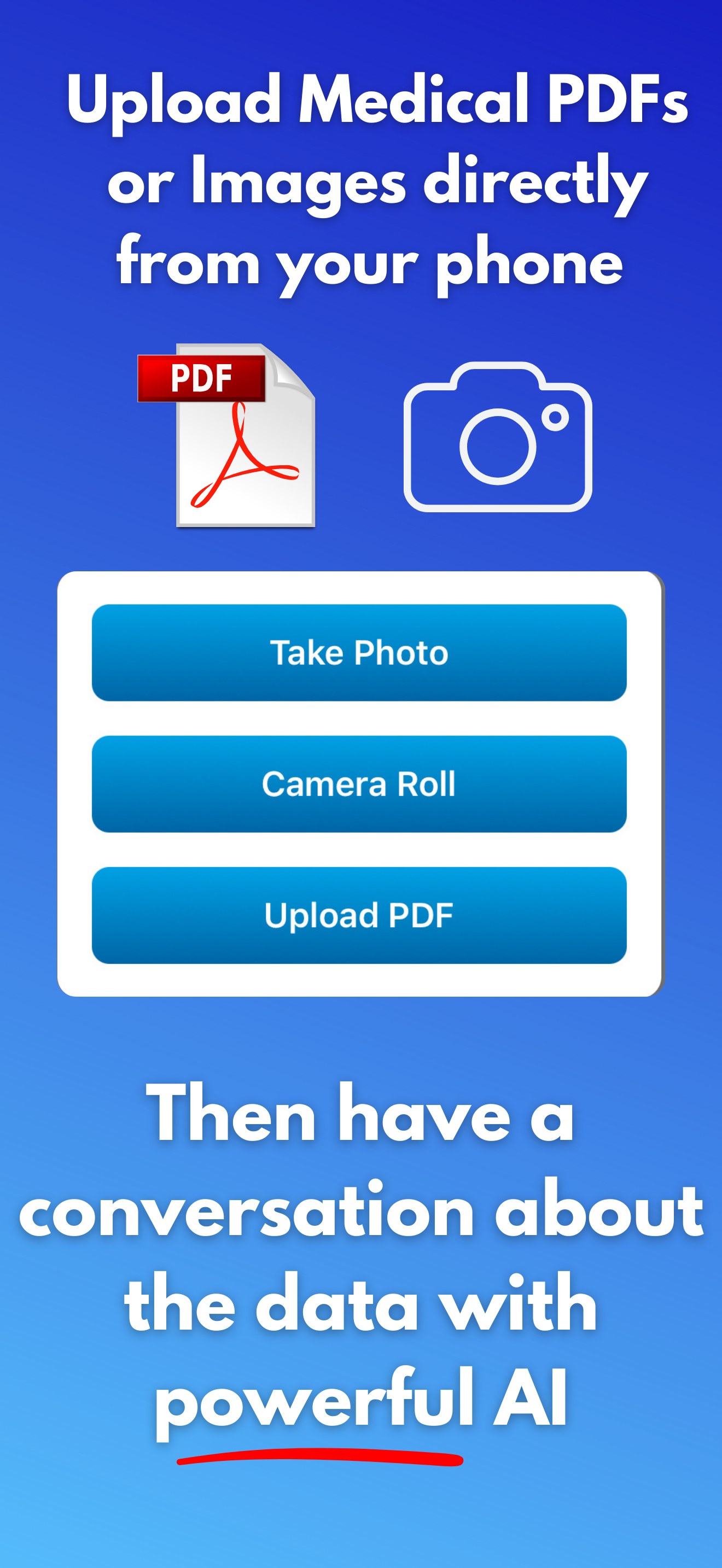
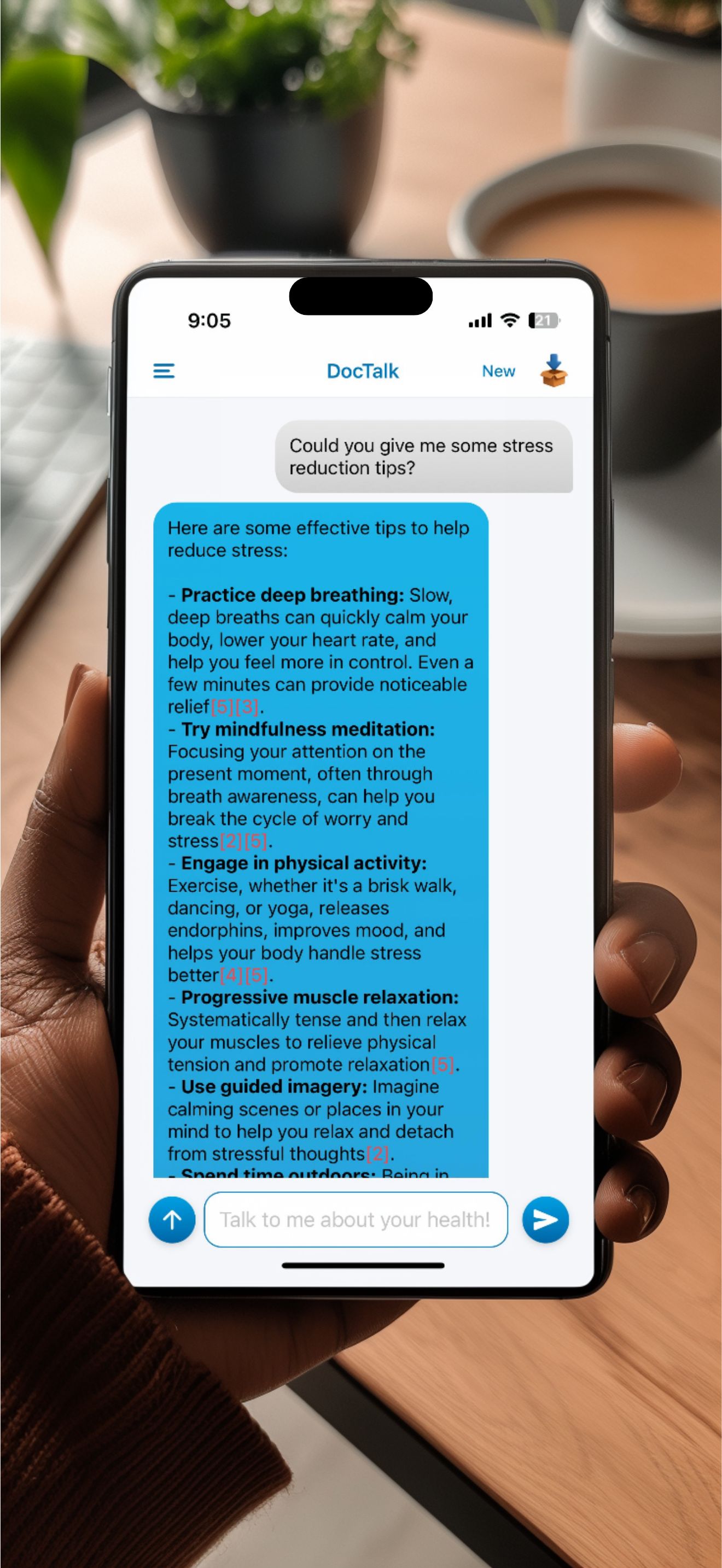
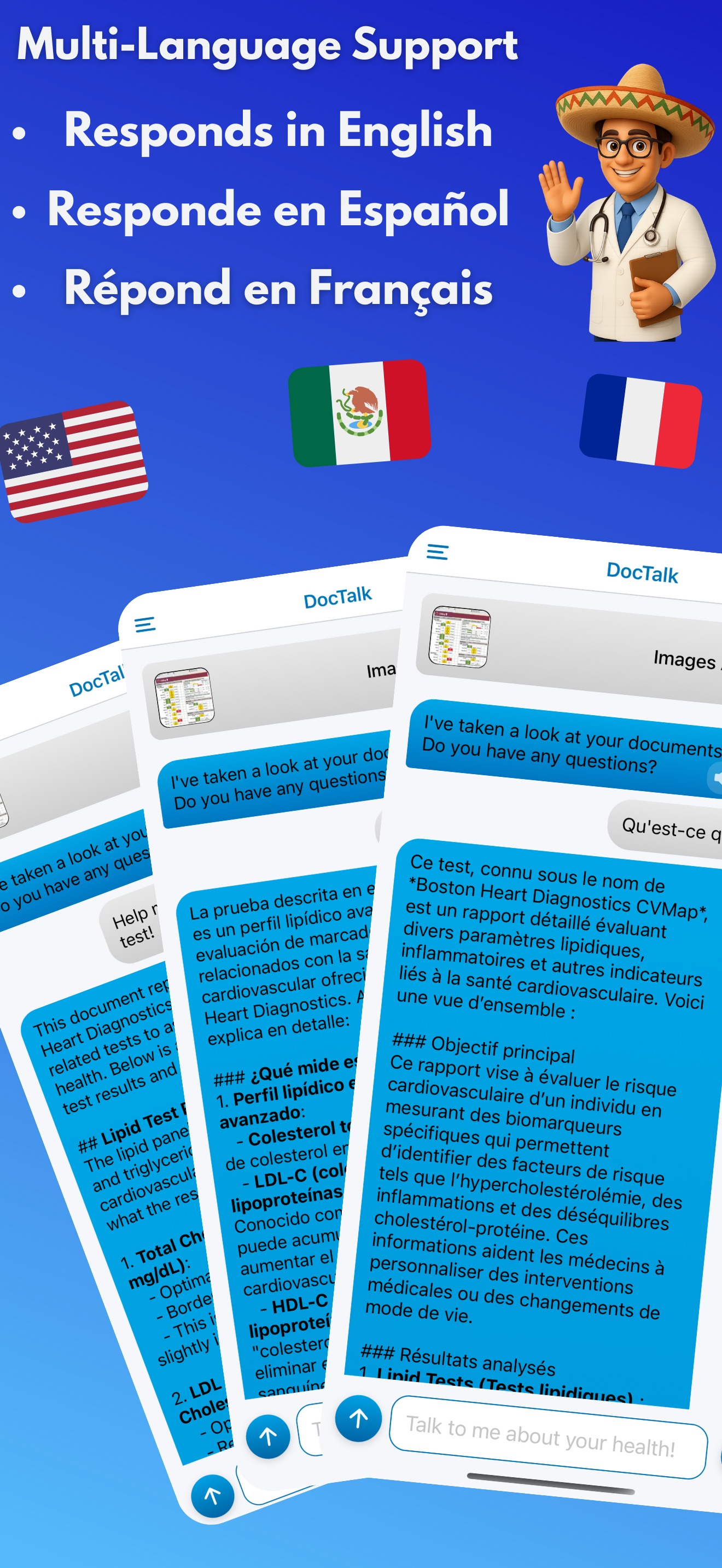
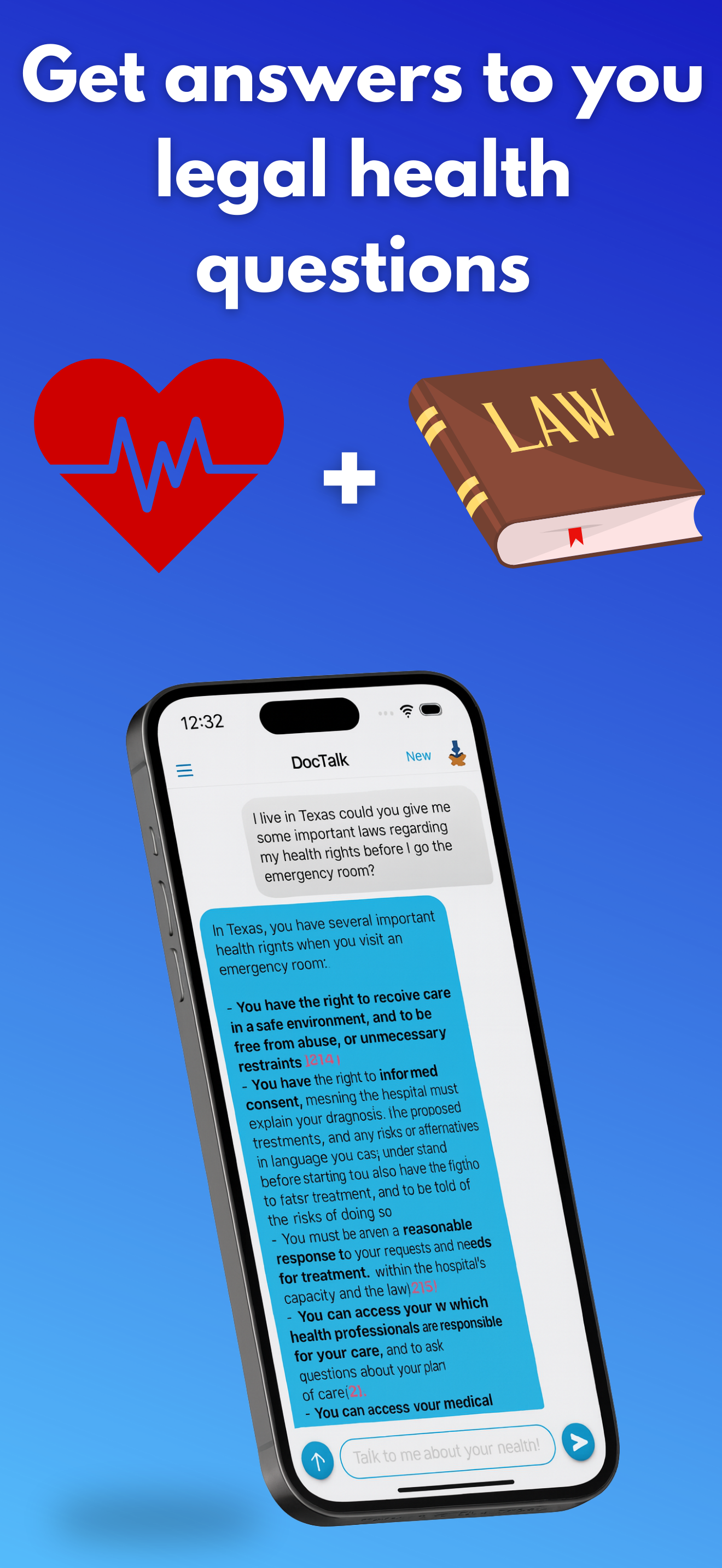
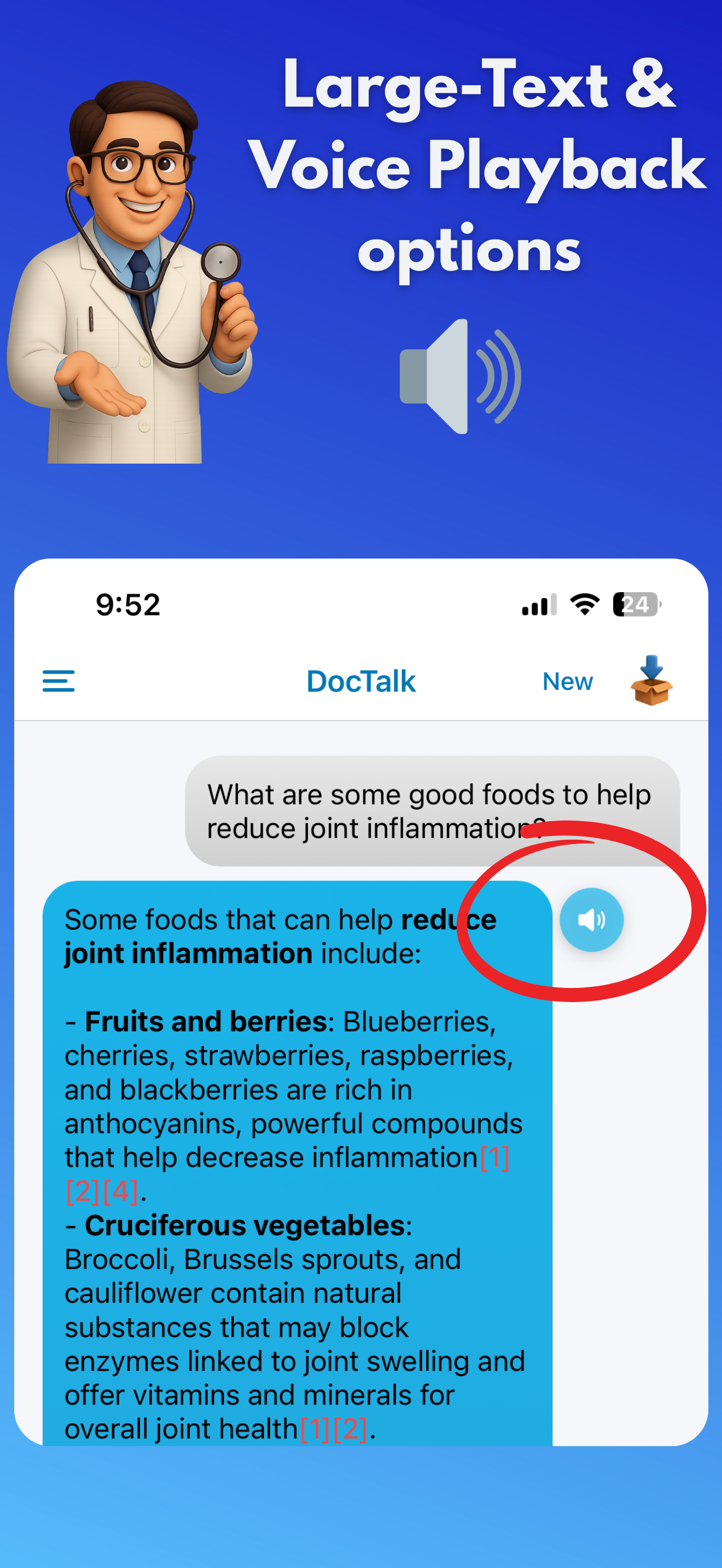
DocTalk is an AI medical chat that translates complex findings from lab results, PDFs, and medical images into plain‑language explanations with citations. Users can upload multiple documents into a single conversation to compare trends, spot contradictions, and follow changes across panels and reports. The interface is conversational - follow‑up questions refine context - while accessibility features like text‑to‑speech, adjustable text sizes, and dark mode keep the experience low‑stress. Under the hood, responses are grounded in a structured “document context,” so answers are derived rather than guessed. Attachments remain anchored to their original place in the chat for faithful replay. Privacy is foundational: encrypted transport/storage, short‑lived signed URLs, JWT‑scoped access, and zero data sharing. We don’t train models on user PHI.
How we built it
Document intelligence: PDFs/images are uploaded to a secure backend, processed asynchronously, and distilled into a structured context (tables, key‑value blocks, entities) used to ground answers and citations.
Normalization: Extracted values are mapped to canonical test names/units, validated against plausible ranges, and flagged when uncertain.
Conversation engine: A dual‑flow chat pipeline merges document‑analysis events and user messages into an ordered thread, enabling true multi‑document comparisons inside one conversation.
Privacy by design: Encryption in transit/at rest, short‑lived signed URLs, least‑privilege data paths, JWT‑based scoping, and PHI minimization across logs/metadata. No third‑party data selling; no model training on PHI.
Challenges we ran into
OCR fidelity: Mixed layouts, tiny fonts, rotated tables, and fax artifacts caused decimal and unit misreads; preprocessing (deskew, denoise, adaptive binarization) and layout detection improved accuracy, but low‑quality scans remain hard.
Structure & normalization: Turning raw OCR into a consistent schema required table/kv extraction, synonym mapping, and unit conversion. Range validation reduced downstream errors and made comparisons reliable.
PHI minimization: Stripping identifiers from working context/logs lowered risk without losing clinical meaning.
Research grounding: Focused prompts (e.g., “A1c 6.7% adult - interpretation + guideline citations”) and constrained sources helped limit hallucinations and keep results verifiable.
Conversational integration: Merging async analysis with chat, asking clarifying questions when confidence drops, and keeping answers plain‑language while preserving key numbers.
Accomplishments we’re proud of
Plain‑language explanations with citations from real documents, not templates.
Multi‑document reasoning with preserved message positions for coherent narratives.
Accessibility: text‑to‑speech, adjustable text sizes, calm dark mode.
Privacy as a product feature: encrypted, access‑controlled, zero data sharing, and no model training on PHI.
What we learned
Combining vision/OCR, LLMs, and TTS into a single, reliable experience requires grounding. Normalization of units/terms, structured prompts tied to the document context, and explicit citation requirements improved trust. Unifying analysis events with the chat thread unlocked side‑by‑side comparisons and practical workflows - like appointment prep with summaries and question lists.
What’s next
Marketing: Early‑access program, simple landing page, short demos, and targeted pilots with caregivers, chronic‑condition communities, and students.
Better analysis: Stronger OCR for low‑quality scans, expanded normalization, richer multi‑doc compare (timelines, diffs), and smarter follow‑ups.
Release: Finalize TestFlight build and App Store submission with a privacy‑first narrative; fast post‑launch patch cadence.
Built With
- cursor
- encryption
- expo.io
- firebase
- javascript
- mongodb
- openai
- perplexity
- react-native
- revenuecat
- sonnet
- typescript
- vertex


Log in or sign up for Devpost to join the conversation.