-
-

Home Page
-

Class Labels and Keywords to be added
-

Train Model
-

Test Model
-

Batch Prediction
-

Downloadable Stat charts.
-

Output Visualization
-
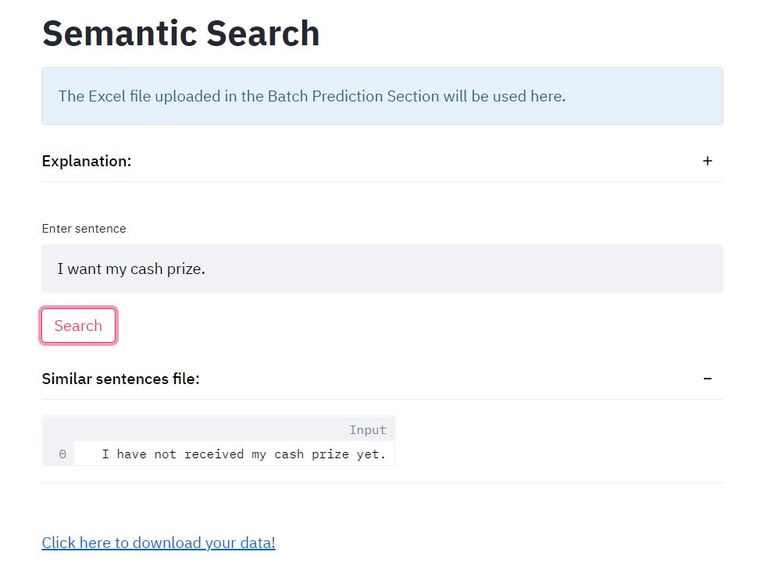
Semantic Search in action
-

Semantic Search Feature








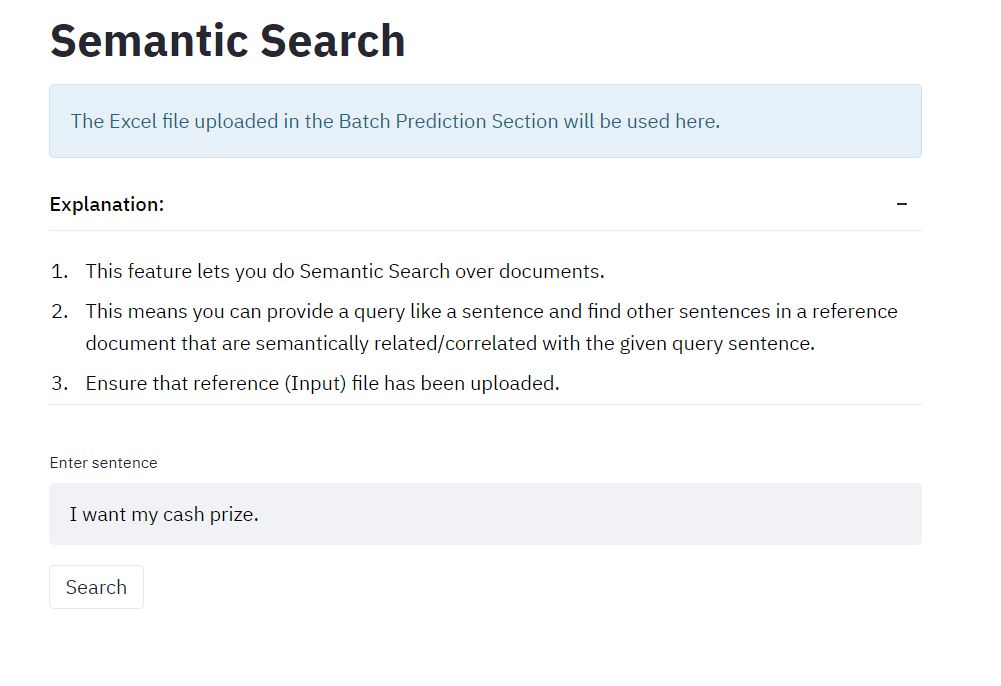
Inspiration
Tagging documents is very time consuming, costs companies and the bottleneck in this process is usually the fact that it is not quite automated. People could spend their valuable time making key decisions for their business if repetitive jobs like tagging documents were automated. Often, training an ML model for classifying sentences/tagging documents requires some technical expertise and needs some time as well. That is why I created DocTagger - a simple to use web application that tags your documents instantly given only a few examples for each possible outcome category.
What it does
Given a 'Train' file that contains examples for each output category and few keywords which may indicate the presence of a category, the application is capable of tagging new/unseen sentences with high accuracy. You can also batch predict that is upload excel files and get all rows tagged. Another helpful feature in DocTagger is Semantic Search. It lets you retrieve similar sentences from your reference file thereby letting you better analyze the problem.
How we built it
DocTagger was built using Python, Streamlit (Open source Python library) and the NLP capabilities are powered by GPT-3.
Challenges we ran into
Completing the application in the given timeframe.
Accomplishments that we're proud of
The fact that I was able to build an application that could really help businesses and individuals alike automate the repetitive task of tagging.
What we learned
Learnt about few-shot classification - a Natural Language Processing (NLP) technique to classify/tag given only a few examples.
Built With
- python
- streamlit



Log in or sign up for Devpost to join the conversation.