-
-
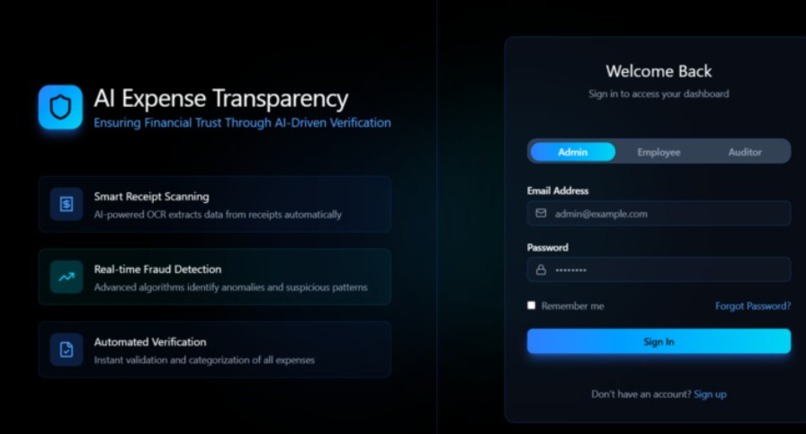
ROLE BASED ACCESS
-
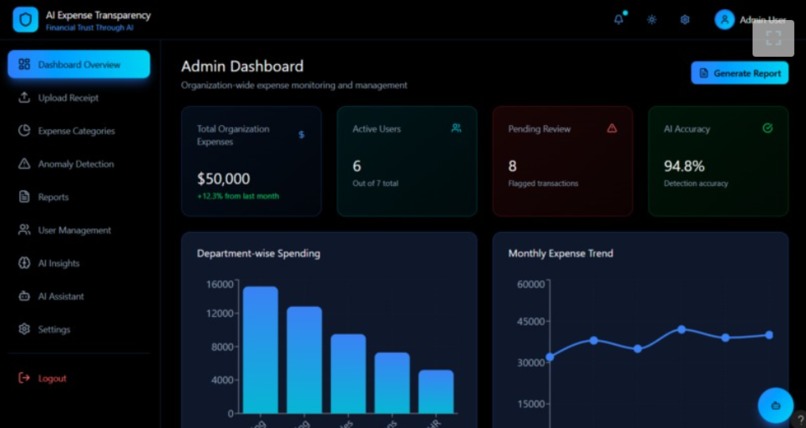
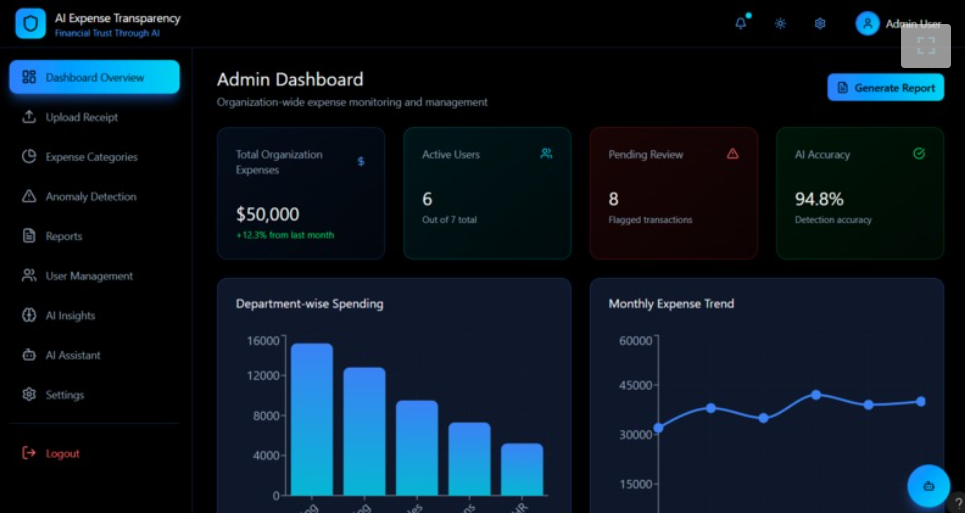
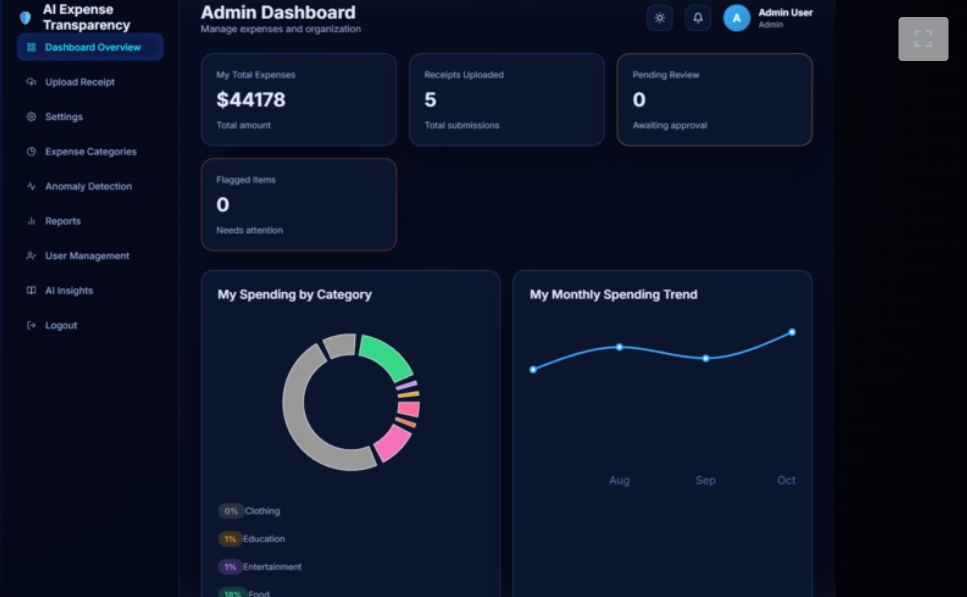
ADMIN DASHBOARD
-
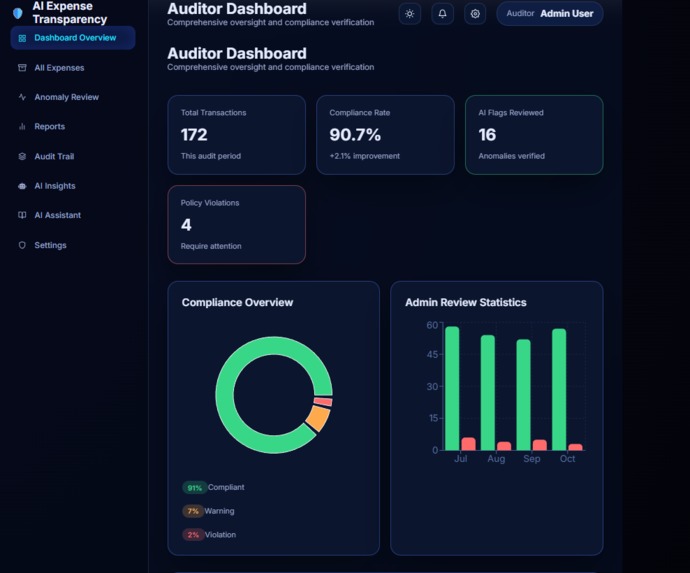
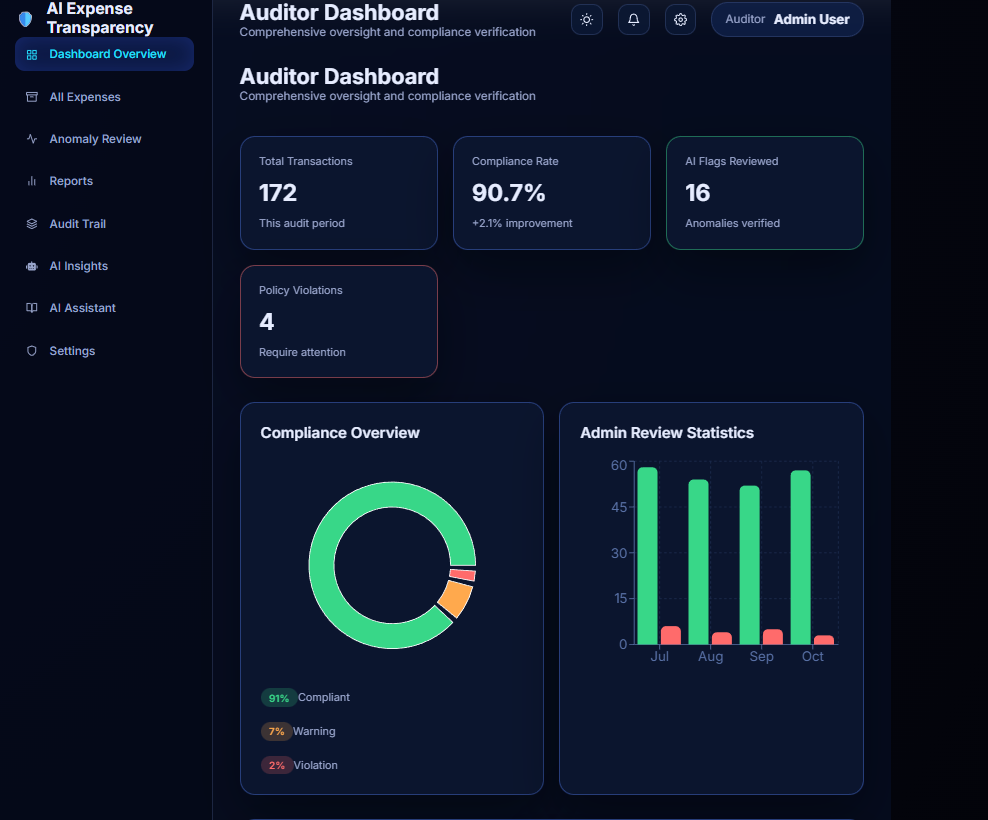
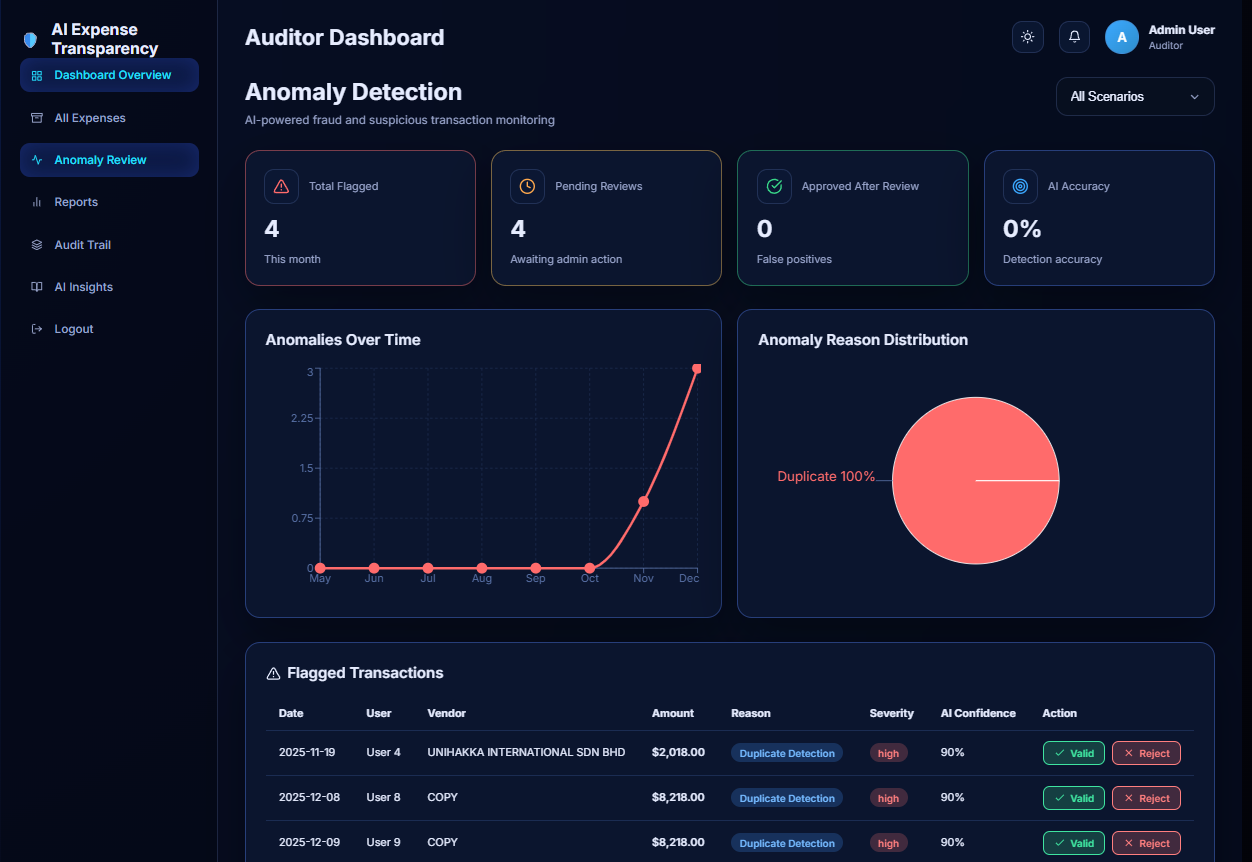
AUDITOR DASHBOARD
-
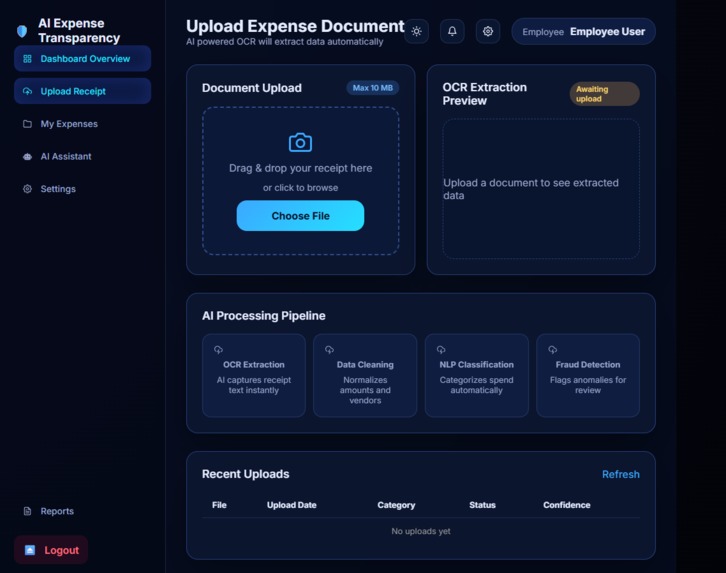
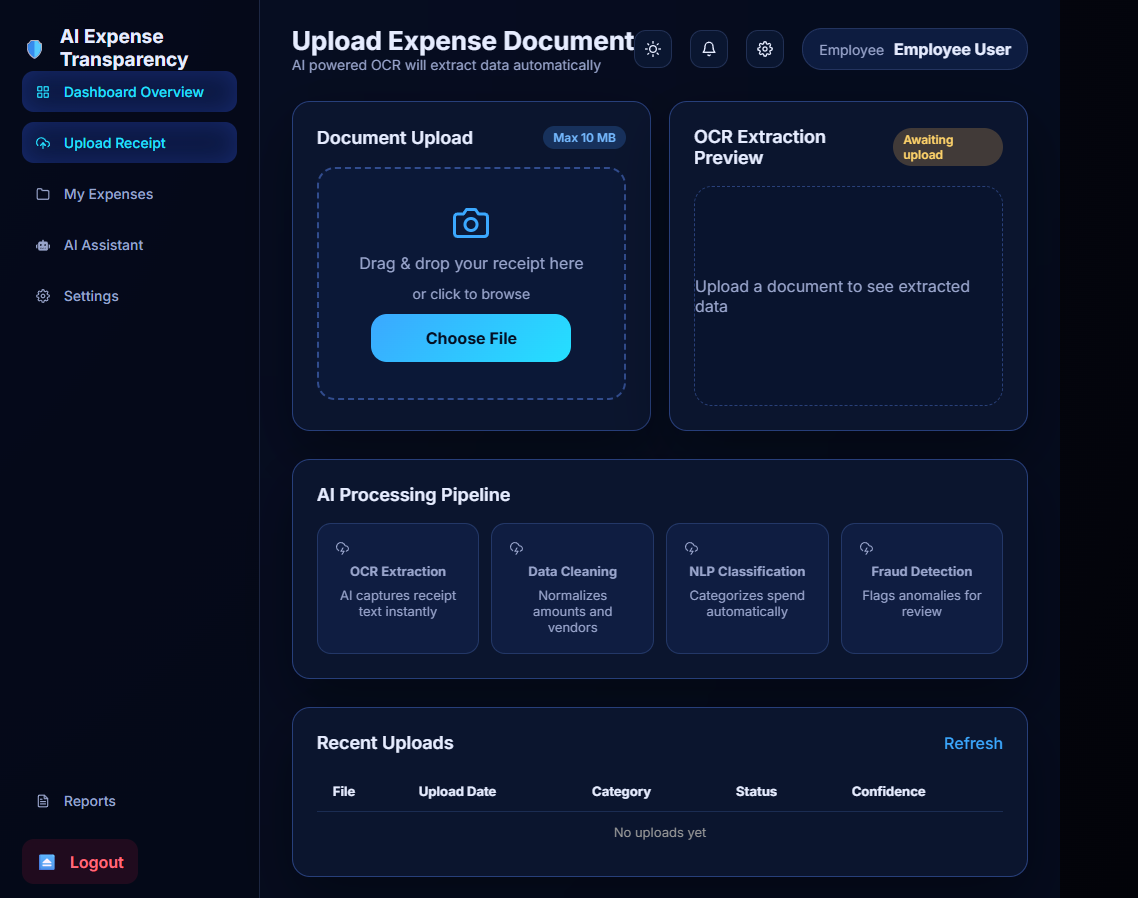
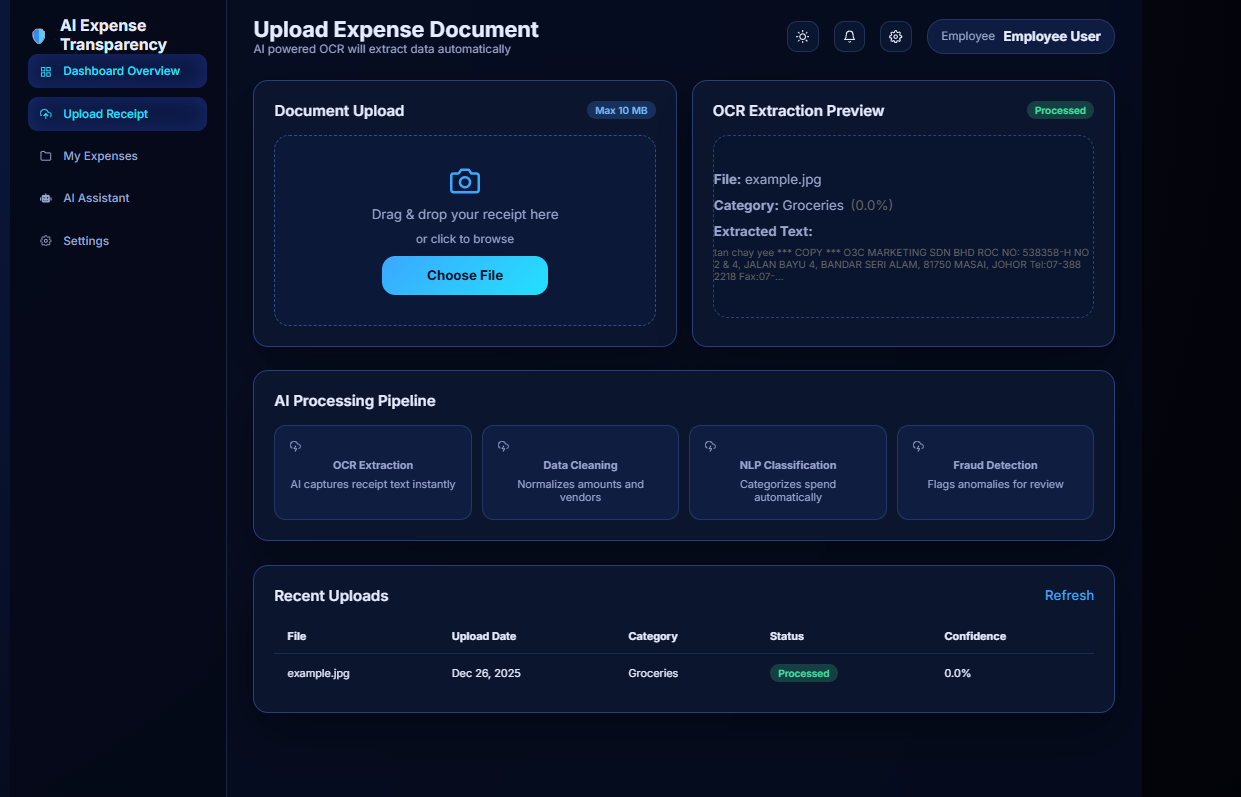
EMPLOYEE DASHBOARD
-
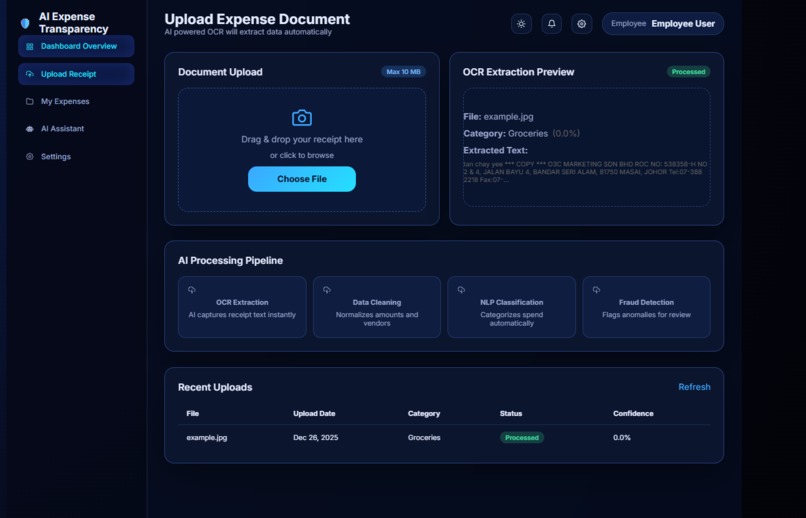
EXTRACTED TEXT USING PADDLEOCR
-
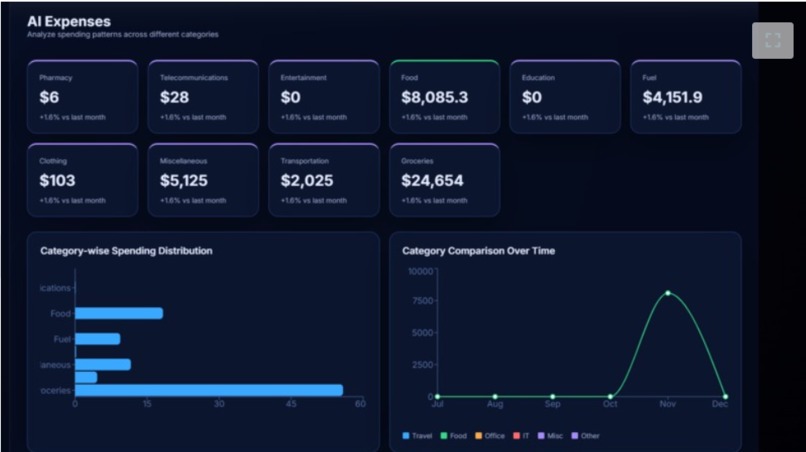
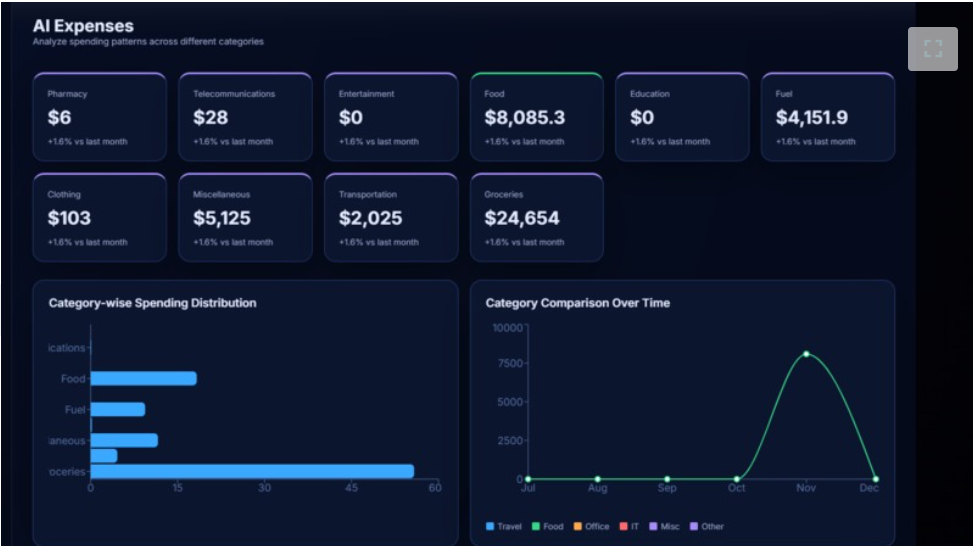
AI EXPENSES
-
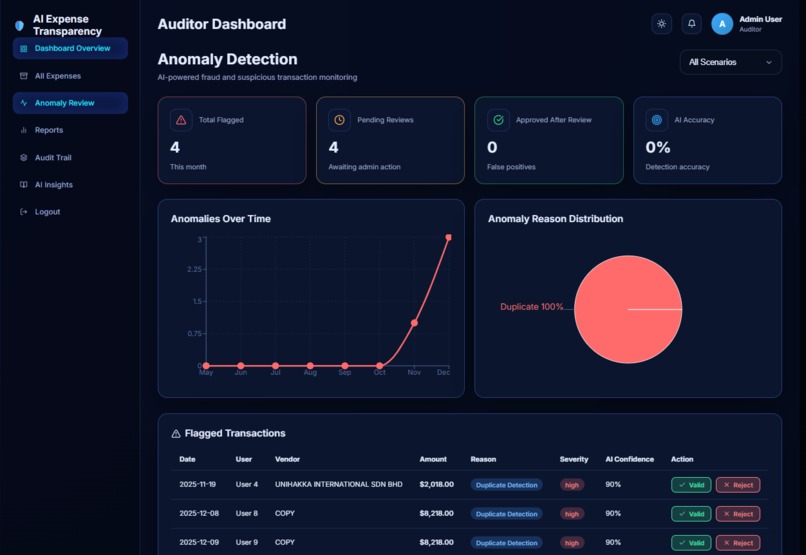
FRAUD DETECTION
-
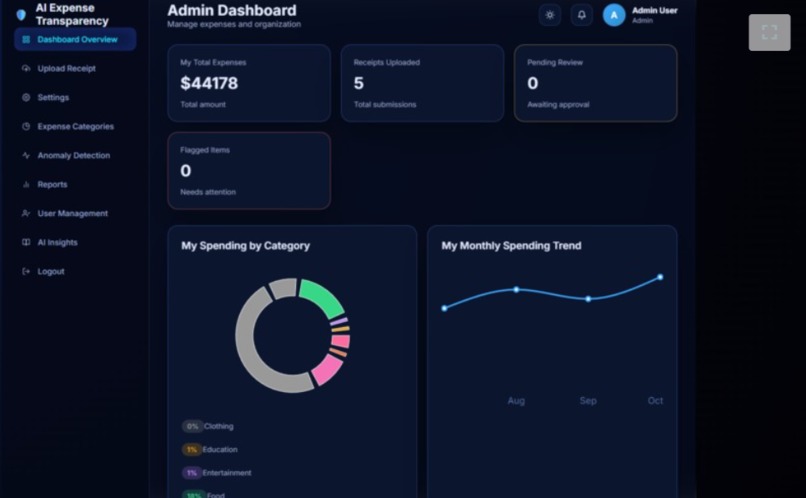
TRENDS IN DASHBOARD
Inspiration
-Manual bill verification is slow and inefficient in NGOs -High chances of human error in financial records -Lack of transparency in expense tracking -Difficulty in detecting fraudulent or duplicate bills -Need for automation in small businesses with limited resources -Growing importance of digital transformation in finance -Paper-based bills are hard to store and retrieve -Lack of intelligent systems to understand bill content -Auditors spend too much time on repetitive validation tasks -No easy tool for real-time financial monitoring
What it does
-Uploads bill images or PDFs -Extracts text using OCR -Cleans and preprocesses extracted data -Identifies key entities (items, price, tax, total) -Classifies bill into categories (food, electronics, etc.) -Calculates total bill amount automatically -Verifies extracted total vs computed total -Detects anomalies and suspicious patterns -Flags high-risk transactions -Supports Admin, Employee, Auditor roles -Stores structured data in database -Provides audit-ready outputs
How we built it
OCR-Based Text Extraction We used Tesseract OCR to extract raw text from uploaded bill images and PDFs. This allowed us to convert unstructured visual data into machine-readable text. Image Preprocessing for Better OCR Accuracy Before feeding images to OCR, we applied preprocessing techniques such as: Grayscale conversion Noise removal Thresholding Image resizing This significantly improved text extraction quality.
Text Cleaning and Normalization The extracted text was cleaned using: Lowercasing Removing special characters Regex-based filtering Tokenization This step ensured consistency for downstream ML models.
Feature Extraction using DistilBERT We used DistilBERT, a lightweight transformer model, to convert text into contextual embeddings. These embeddings capture semantic meaning from the bill content rather than just keywords. Bill Classification using DistilBERT The embeddings generated by DistilBERT were used to classify bills into categories such as: Food Electronics Travel Utilities This improved accuracy compared to traditional keyword-based methods.
Structured Data Extraction (Amounts & Items) We extracted important numerical fields using pattern matching: Item prices Total amount Tax (GST) Discounts Regular expressions and heuristics were used for this step.
Rule-Based Total Calculation We computed the expected total using: Total=∑(item prices)+tax−discount
Feature Engineering for Anomaly Detection We created features such as: Total amount Number of items Average item price Category label Difference between OCR total and calculated total
Anomaly Detection using Logistic Regression We trained a Logistic Regression model to classify whether a bill is:
Normal (0) Suspicious (1)
The model learns patterns like:
Unusual spending Mismatched totals Category inconsistencies
- Rule-Based Formula Calculation
We extract values like:
Item prices → 𝑝1,𝑝2,𝑝3,...,𝑝𝑛
Tax (GST) → 𝑇
Discount → 𝐷
✅ Formula: Calculated Total=∑𝑖=1 𝑛𝑝𝑖+𝑇−𝐷
🔹 Example:
Items: ₹100, ₹200, ₹300 Tax: ₹50 Discount: ₹20
Total=(100+200+300)+50−20=630
🔹 2. ML-Based Sum Prediction (Advanced ⭐)
Instead of only formula:
We train a model using features like:
Number of items Average price Max price Presence of tax keywords Text embeddings Model: 𝑌=𝑤1𝑥1+𝑤2𝑥2+𝑤3𝑥3+...+𝑏 Where:
𝑌 = Predicted total 𝑥𝑖 = features 𝑤i = weights
🔹 3. Final Validation Logic Difference=∣OCR Total−Calculated Total|
If: Difference>Threshold
👉 Mark as Suspicious
🔹 4. Confidence Score Confidence=1−Difference
Validation Layer (Final Decision System) We combined: ML prediction (Logistic Regression) Rule-based checks (thresholds, mismatches)
If both indicate risk → bill is flagged as suspicious
Stored: Extracted text Classification results Calculated totals Anomaly flags End-to-End Pipeline Integration Final workflow: Upload → OCR → Cleaning → DistilBERT → Classification → Calculation → Logistic Regression → Output
Challenges we ran into
One of the major challenges we faced was dealing with the inconsistency and noise in bill data. Since we used OCR to extract text from images, the quality of input significantly affected the output. Blurry images, different lighting conditions, and varied bill formats often resulted in incorrect or incomplete text extraction. This made it difficult to reliably identify key information such as item prices, totals, and tax values. Handling such unstructured and imperfect data required us to implement multiple preprocessing techniques and fallback strategies.
Another significant challenge was accurate data extraction and understanding. Bills come in different layouts, and identifying the correct “total amount” among multiple numbers (like subtotal, tax, discounts) was not straightforward. Similarly, categorizing bills based on textual content required more than simple keyword matching, which is why we moved to advanced models like DistilBERT. Even then, ambiguous cases and mixed-category bills posed difficulties, requiring careful tuning and feature engineering.
We also faced challenges in building a reliable anomaly detection system. Since we used Logistic Regression, creating meaningful features was critical. Designing features like total mismatch, item distribution, and category relevance took multiple iterations. Additionally, balancing between rule-based validation and ML predictions was tricky, as too many rules increased false positives, while relying only on ML reduced interpretability. Ensuring a smooth integration of all components—OCR, NLP, ML, and role-based access—into one cohesive pipeline was another complex task.
Accomplishments that we're proud of
One of our biggest accomplishments is successfully building a complete end-to-end intelligent system that goes beyond simple OCR. We integrated text extraction, semantic classification using DistilBERT, and anomaly detection using Logistic Regression into a single pipeline. This allowed us to transform raw bill images into meaningful, structured insights, demonstrating a strong practical application of AI in solving real-world problems.
We are also proud of implementing a robust validation mechanism for financial data, especially the total amount verification. By combining rule-based calculations with machine learning predictions, we created a system that can detect mismatches and flag suspicious bills effectively. This feature adds real value, particularly for NGOs and small businesses where financial transparency and fraud detection are critical.
Another key achievement is designing a multi-user role-based system with Admin, Employee, and Auditor functionalities. This made the project more realistic and scalable, simulating how such a system would actually be used in organizations. Additionally, we managed to overcome multiple technical challenges and deliver a working prototype with good accuracy, clean workflow, and practical usability, which we believe has strong potential for further development and real-world deployment.
What we learned
-OCR requires heavy preprocessing -Real-world data is noisy and inconsistent -Feature engineering is critical in ML -Combining ML + rules gives best results -Financial systems need validation layers -Data cleaning is time-consuming but essential -Importance of UI/UX in adoption -Handling edge cases is crucial -Security in multi-user systems -Model accuracy vs performance trade-off -Importance of testing with real data
What's next for DocMindAI
To make DocMindAI more powerful, scalable, and industry-ready, we plan to enhance it across AI capabilities, product features, and deployment.
🔹 1. Advanced AI Models for Better Accuracy
We plan to replace or enhance DistilBERT with more advanced transformer models like BERT or domain-specific financial models to improve classification accuracy, especially for complex and mixed-category bills.
🔹 2. Deep Learning for Invoice Understanding
Move beyond text classification to full document understanding using models like LayoutLM, which consider both text and layout. This will help in accurately extracting:
Item tables Totals Vendor details 🔹 3. Improved Sum Calculation using ML
Enhance total prediction by:
Using regression models (Random Forest / XGBoost) Learning patterns from real invoice datasets Improving mismatch detection accuracy 🔹 4. Advanced Fraud Detection System
Upgrade anomaly detection by:
Using Isolation Forest / Autoencoders Creating a fraud risk score (0–100) Detecting patterns like: Repeated vendors Unusual spending spikes 🔹 5. Multilingual OCR Support
Extend OCR to support multiple languages (Tamil, Hindi, etc.), making the system usable across different regions and organizations.
🔹 6. Real-Time Analytics Dashboard
Build an interactive dashboard to show:
Monthly spending trends Category-wise expenses Suspicious transaction reports 🔹 7. Cloud Deployment & Scalability
Deploy DocMindAI on cloud platforms like:
AWS / Azure / GCP
Benefits:
Scalable processing Real-time access Secure storage 🔹 8. Mobile Application
Develop a mobile app where users can:
Capture bill photos instantly Upload in real-time Get instant classification and alerts 🔹 9. Integration with Accounting Tools
Integrate with tools like:
Tally QuickBooks
This will allow seamless syncing of financial data.
🔹 10. Vendor & Duplicate Detection System
Build a system to:
Identify repeated vendors Detect duplicate bill submissions Maintain vendor credibility scores 🔹 11. Smart Budget Monitoring
Add features like:
Budget limits per category Alerts when spending exceeds limits Predictive expense analysis 🔹 12. API-Based Product Expansion
Create APIs so other applications can use DocMindAI features like:
OCR extraction Bill classification Fraud detection
Built With
- camel-ai
- css
- docker
- ernie-4.5
- git
- github
- hugging-face-transformers
- javascript
- matplotlib
- mongodb
- mongodb/mysql
- mysql
- numpy
- opencv
- paddleocr-vl
- pandas
- python-(flask/fastapi)
- pytorch
- scikit-learn
- tensorflow
- typescript

Log in or sign up for Devpost to join the conversation.