
Inspiration
These felt like separate frustrations in my life: managing personal files, understanding medical results, dealing with government paperwork, etc. But I realized they all share the same root problem: The data already exists — but it’s trapped.
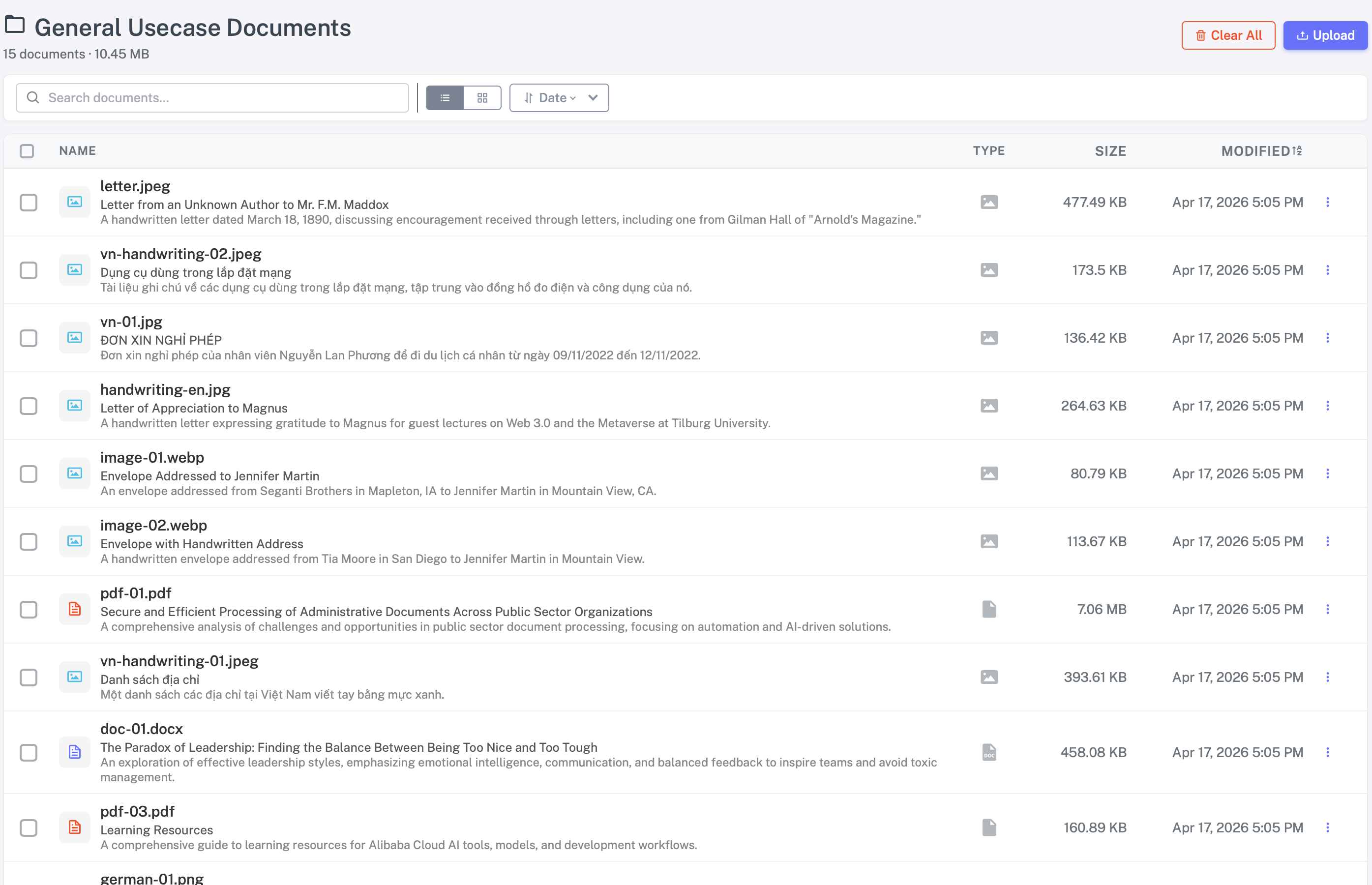
Personal Data
I’ve accumulated countless personal and family documents—medical records, images, important files. Finding the right one can take hours. Organizing them takes even longer. That’s time I could have spent with my family.
Healthcare Experience
Last month, after a routine health check, I received my lab results after a few day and had to re-visit the doctor again just to understand them. The data was already there. But it wasn’t accessible.
Administrative Reality
In Vietnam, everyone understands how slow administrative procedures can be. I’ve personally been stuck in a land process for 14 months — still unresolved. Stacks of documents. Repeated submissions. Unclear requirements. It’s not just my story. It’s a shared frustration.
The Insight
Across all these moments, I kept seeing the same thing:
- The answers exist
- But they’re buried in documents
- And humans are forced to do the work machines should handle
Why I Built DocLens
As an engineer, I wanted to change that.
DocLens turns images, PDFs, and documents into structured, understandable, and trustworthy data.
Because this isn’t just about extraction.
It’s about giving people back their time, their clarity, and their peace of mind.
What it does
DocLens transforms messy, unstructured documents into structured data that machines can understand and process reliably.
The goal is simple: free people from repetitive, manual document work so they can focus on decisions, care, and meaningful tasks.
Where it applies
This core capability naturally fits multiple hackathon tracks:
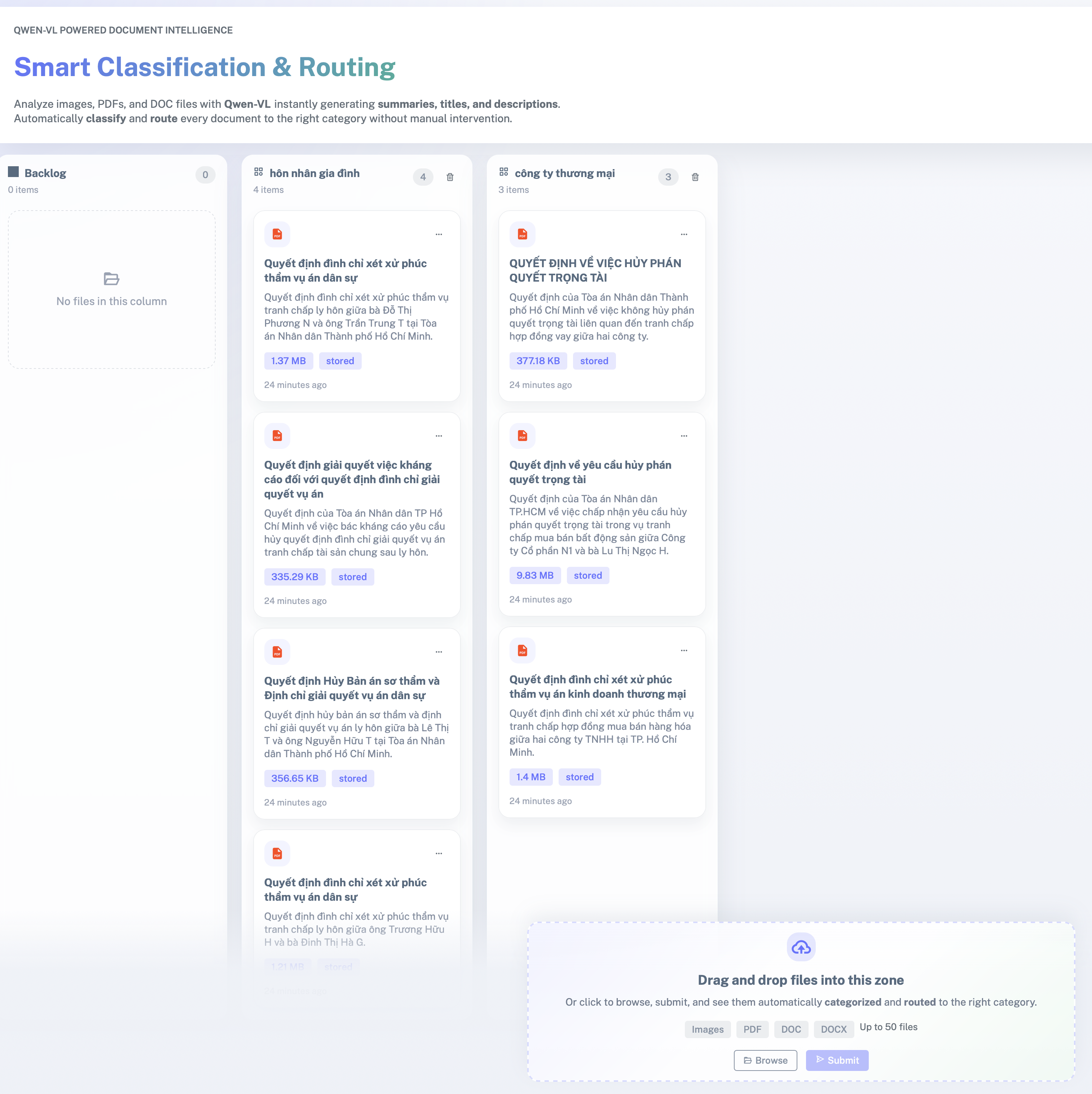
- Public Sector: Automatically categorize and route incoming documents to the right department within seconds—reducing delays and human error.
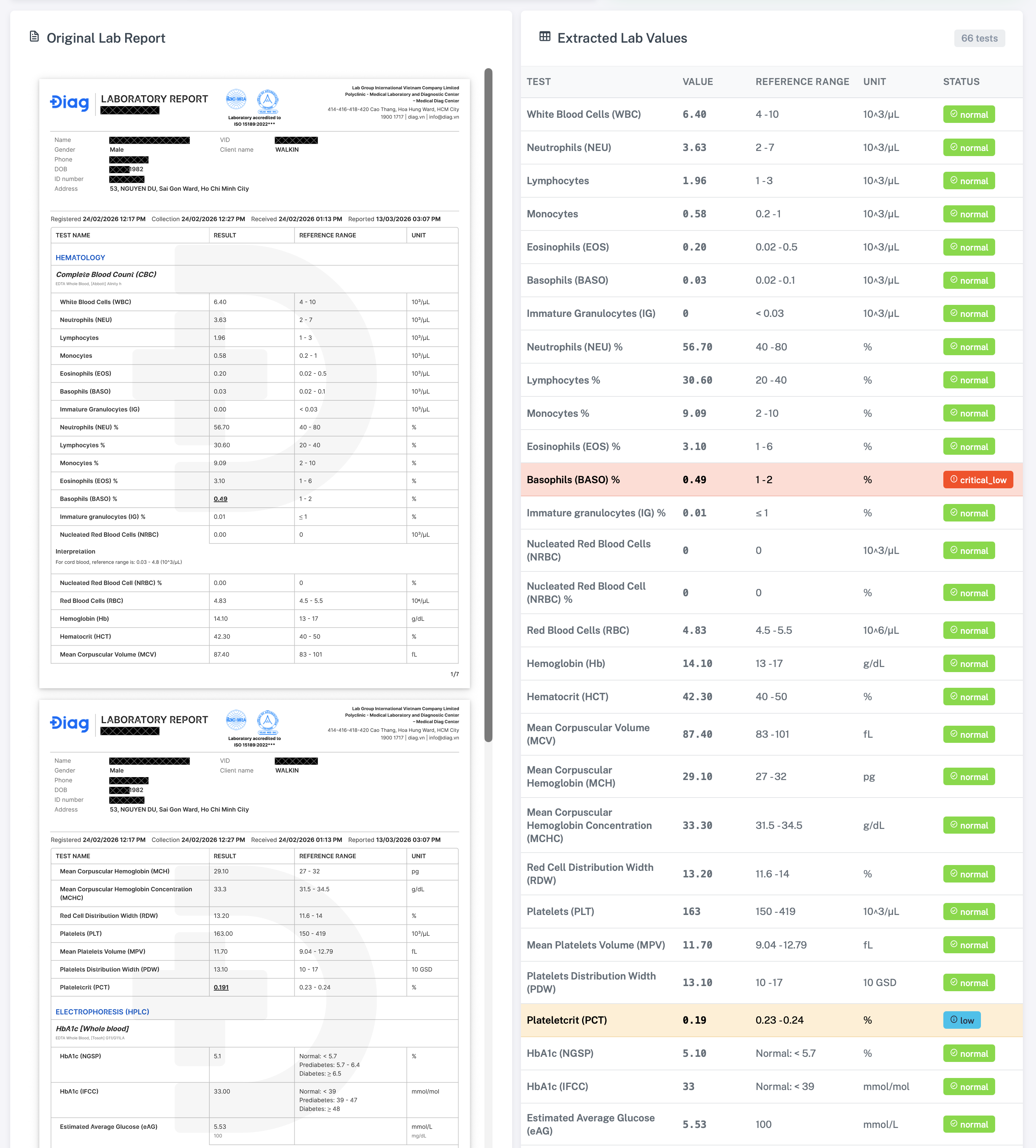
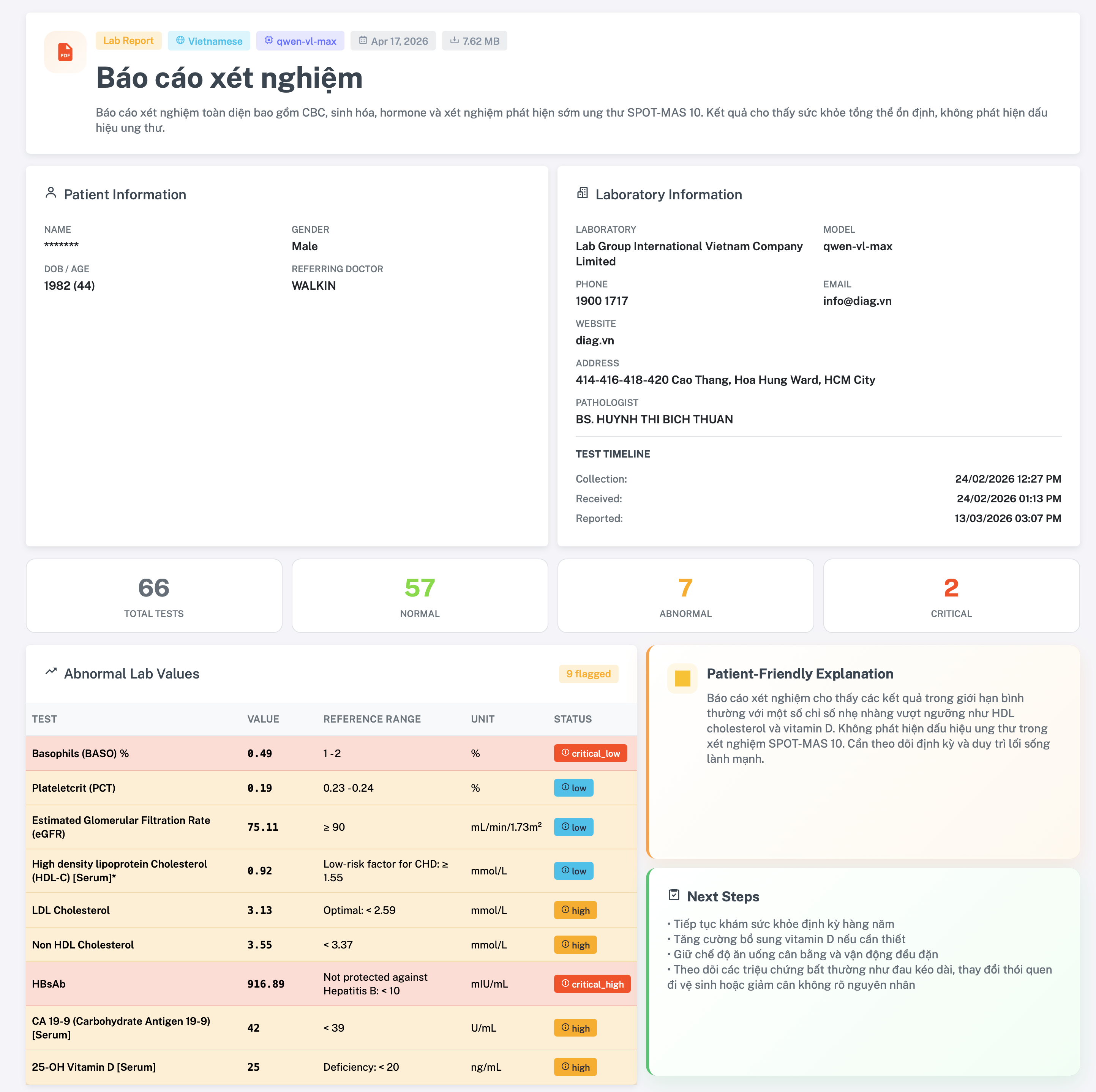
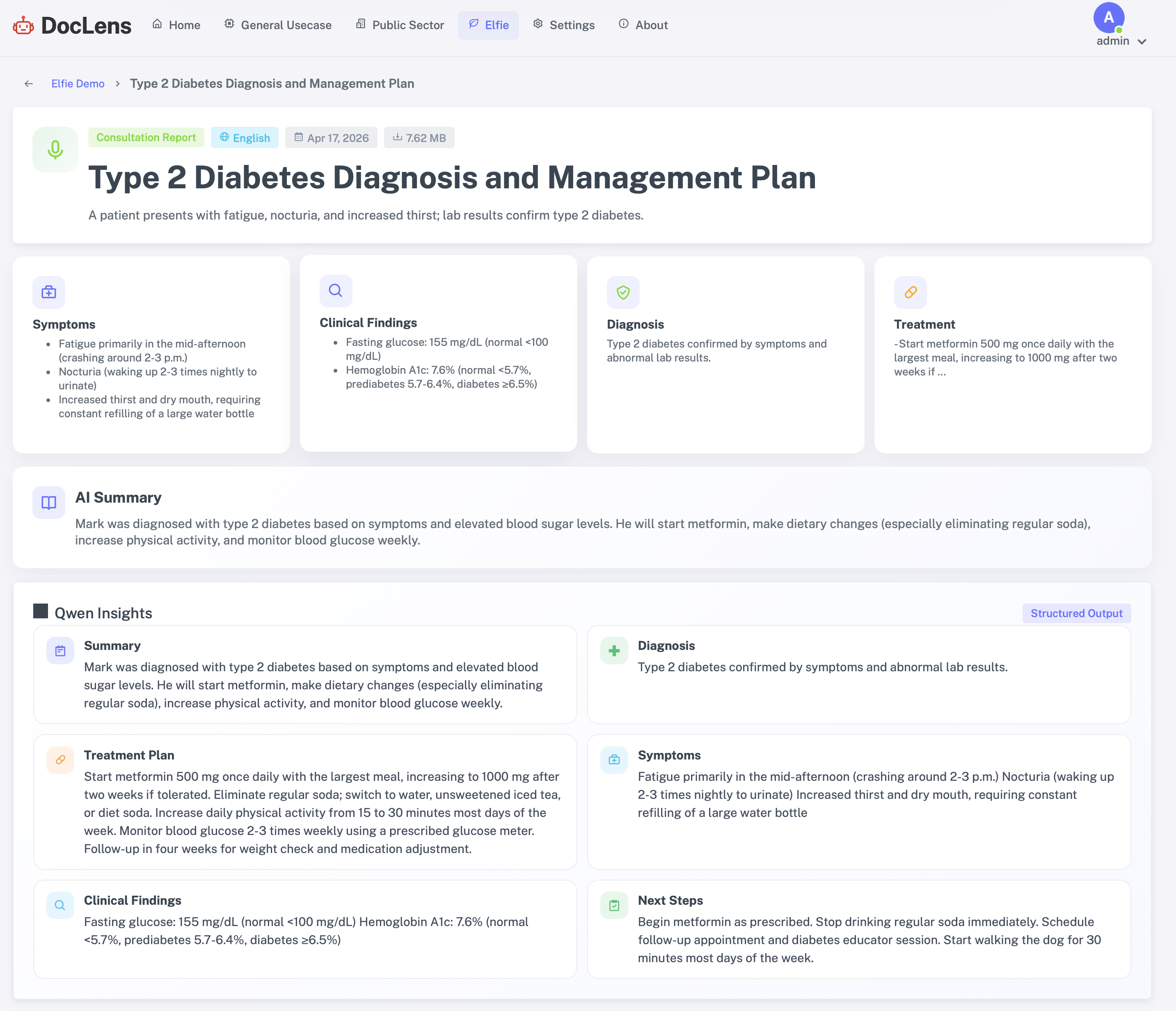
- Elfie Lab Analyzer: Convert complex lab reports into clear, patient-friendly insights, highlight abnormal values, and suggest next steps.
Beyond the demo
Due to hackathon time constraints, the demo only covers a small part of what’s possible.
But the idea is much bigger:
Anywhere information is trapped in documents, DocLens can turn it into clear, actionable data.
How we built it
I built DocLens around multimodal AI as the core engine, not just as an add-on.
The most important layer is vision-language and audio AI models that can process PDF, image, DOC, and audio inputs, then reason over what they detect.
- Vision-language models: I use them to "see" documents similarly to human eyes, read layout + content together, and understand tables, forms, stamps, and mixed formatting.
- Audio AI models: I use them to transcribe consultations and convert spoken medical context into structured, machine-usable signals.
- Reasoning layer: after extraction, I use model reasoning to judge data quality, summarize key points, categorize documents by purpose/department, and generate user-friendly outputs.
- Orchestration layer (Node.js/Express): I handle upload, pipeline routing, schema validation, normalization, storage, and response delivery.
- Product layer (Vue): I expose transparent outputs so judges can inspect extracted data, abnormal findings, summaries, and routing decisions.
I designed this pipeline so the AI does what humans currently do manually at scale: see the document, understand meaning, judge relevance, and convert everything into actionable structure.
Challenges we ran into
I faced many major challenges:
- Document diversity across use cases: public-sector workflows include many document types (forms, notices, letters, scans, mixed-language files, handwritten notes), each with different structure and quality.
- Complex classification and routing: summarizing documents correctly and categorizing them into the right department is difficult when content is ambiguous, incomplete, or spread across multiple pages.
- Extraction reliability at scale: in healthcare and public-sector contexts, a small extraction mistake can change meaning, so schema consistency and validation are critical.
- Ground-truth scarcity under hackathon constraints: without enough labeled examples across both sectors, it is hard to benchmark summarization and categorization quality with confidence.
The key lesson is the same across all tracks: a strong demo is not enough unless results are measured against solid ground-truth data.
Accomplishments that we're proud of
As a solo engineer, I am proud that I shipped a working DocLens foundation that covers multiple hackathon tracks, not only Elfie.
- Elfie track: I built end-to-end lab report understanding with structured lab values, abnormal highlighting, patient-friendly explanations, and next-step guidance.
- Public Sector track: I built the core pipeline for document understanding, summarization, categorization, and routing support to the appropriate department.
- Cross-track platform: I unified PDF, image, DOC, and audio processing into one reasoning pipeline that can turn unstructured inputs into actionable outputs.
- Judge transparency: I added clear result views so outputs can be reviewed, validated, and improved against ground-truth data.
Most importantly, I demonstrated that the same document-intelligence approach can potentially solve many real-life problems where information is trapped in files and manual processing is slow.
What we learned
I learned that document AI value comes from reliable outcomes in real workflows, not just impressive model outputs.
- Ground-truth data is the foundation for trust, benchmarking, and fast iteration across every track.
- Multimodal understanding matters: PDF, image, DOC, and audio each fail differently, so one pipeline must handle all of them well.
- Summarization and categorization are hard in practice because real documents are noisy, inconsistent, and context-dependent.
- Public-sector routing requires not only extraction, but strong judgment about intent, priority, and department fit.
- Healthcare outputs require clear, patient-friendly language that stays faithful to source values and clinical context.
- Judge-facing demos are stronger when they show structured evidence, uncertainty, and validation signals, not just polished text.
For me, this hackathon reinforced one principle: if I cannot evaluate outputs against solid ground-truth, I cannot claim real-world reliability.
What's next for DocLens
My next phase is focused on cross-domain accuracy, operational reliability, and real-world deployment readiness.
- Expand ground-truth datasets across healthcare and public-sector documents, including noisy scans, mixed layouts, and multilingual files.
- Measure quality beyond extraction: summarization accuracy, categorization precision, routing correctness, and reasoning consistency.
- Improve document-intent understanding so category and department assignment are more robust in ambiguous cases.
- Strengthen multimodal pipelines for PDF, image, DOC, and audio with better fallback logic and uncertainty handling.
- Upgrade reviewer tooling so humans can validate, correct, and feed improvements back into the system faster.
- Continue improving patient-friendly outputs in Elfie while keeping strict alignment with source lab values and reference ranges.
- Extend DocLens into additional real-life workflows where manual document processing still causes delay, confusion, and avoidable errors.
The roadmap is simple: broader ground-truth, stronger evaluation, and dependable performance across use cases.
Built With
- node.js
- qwen
- vue.js

Log in or sign up for Devpost to join the conversation.