-
-
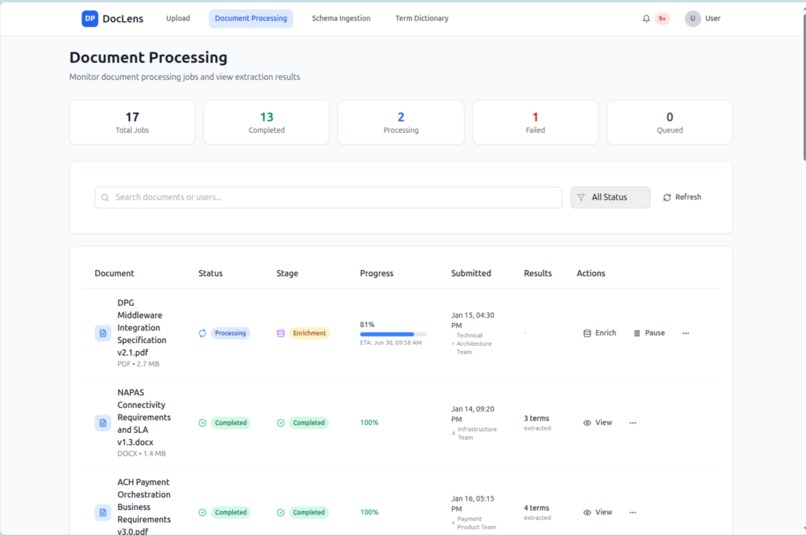
Document Ingestion
-
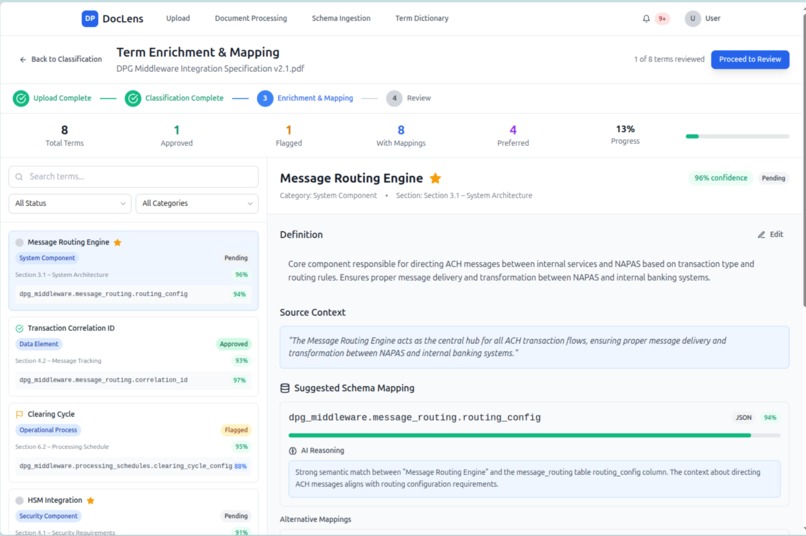
Term Extraction
-
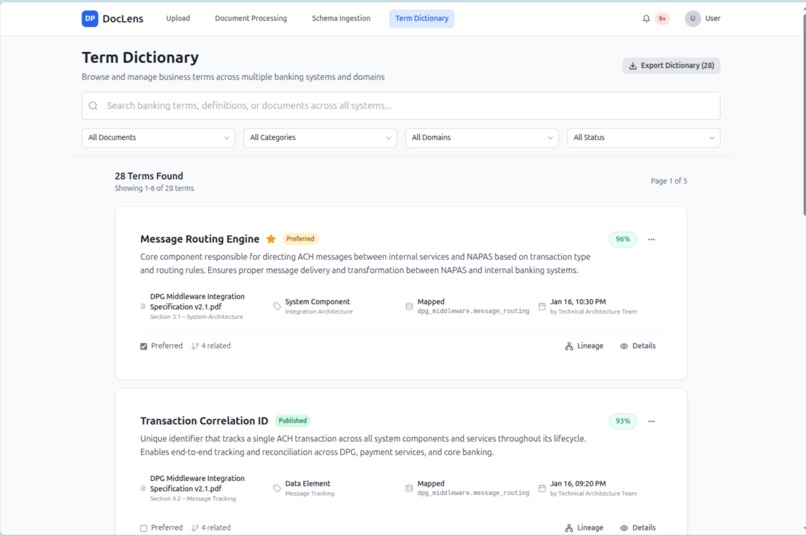
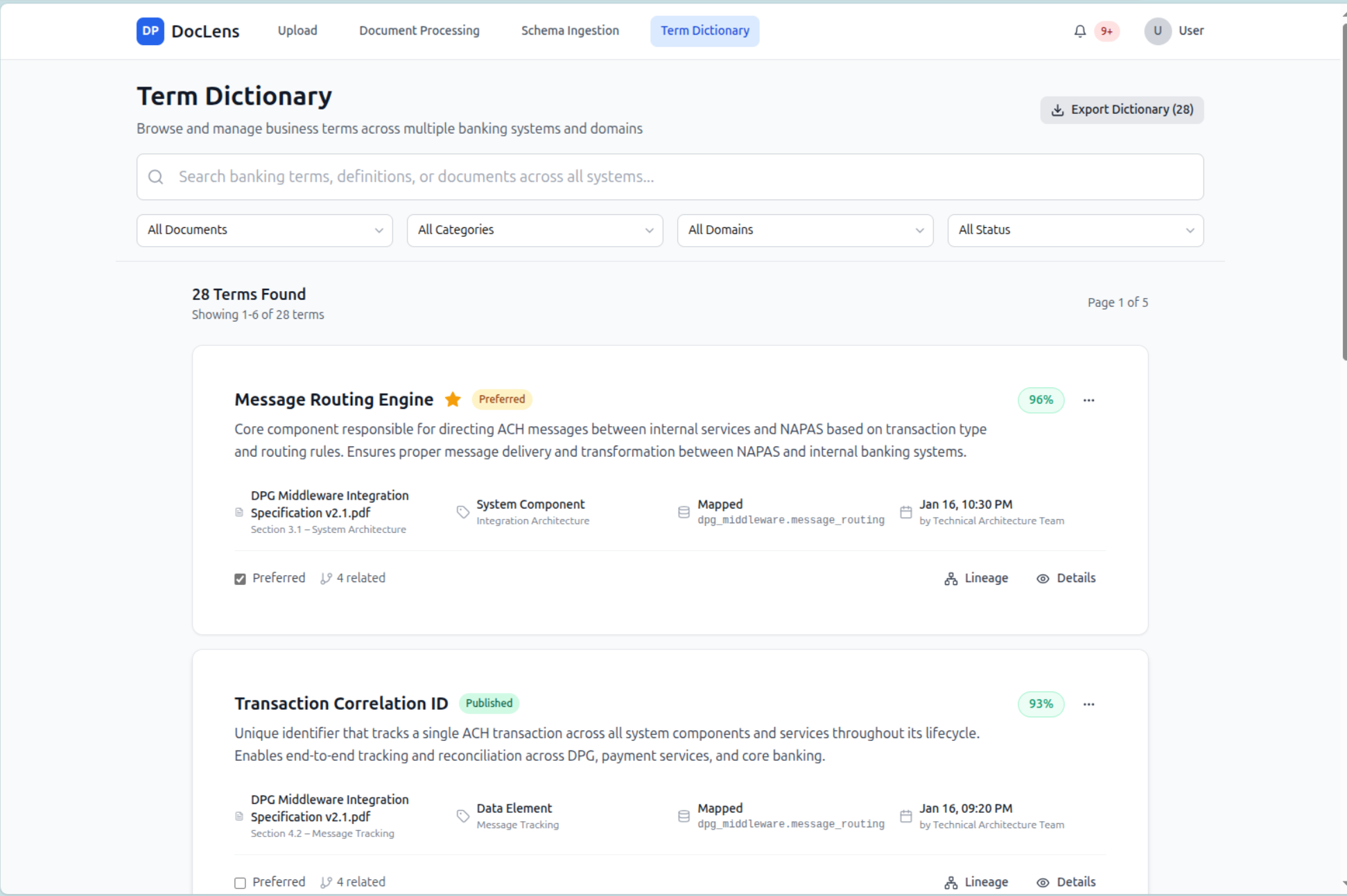
Term Dictionary
-
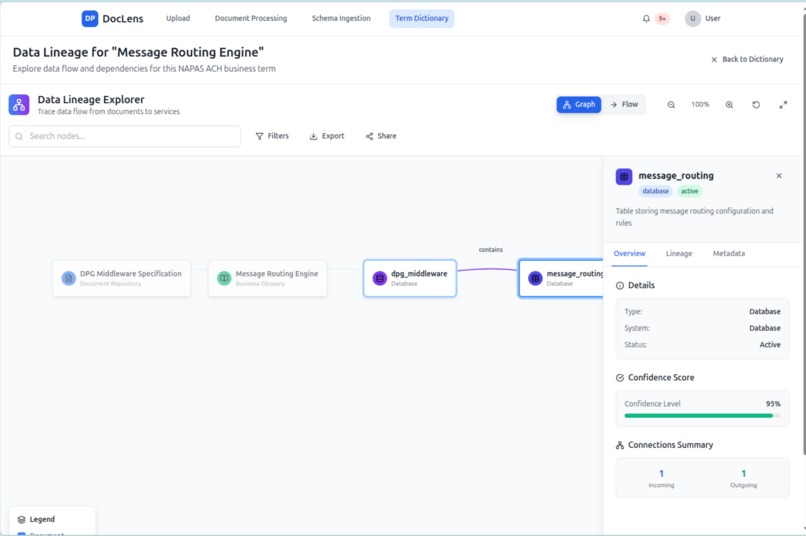
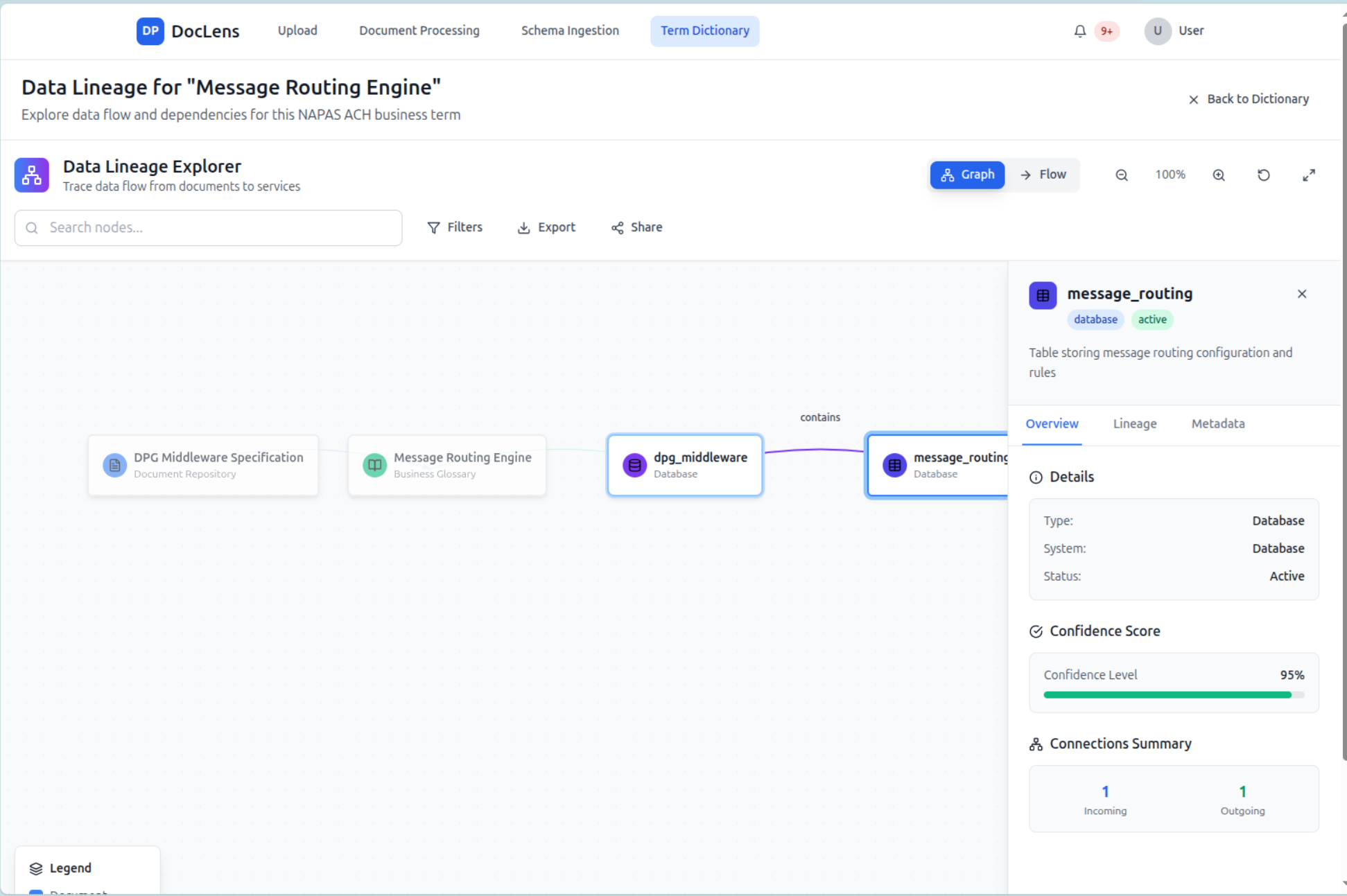
Data Lineage
-
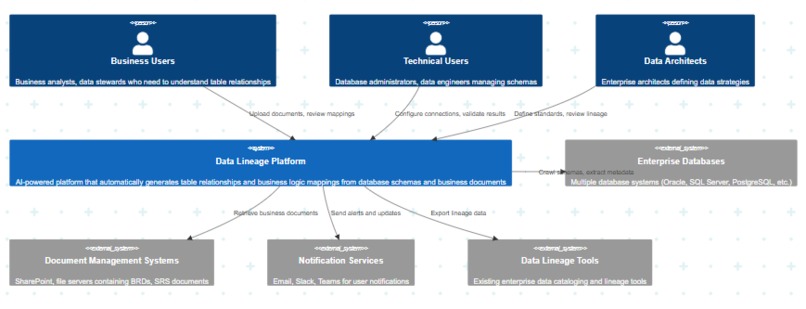
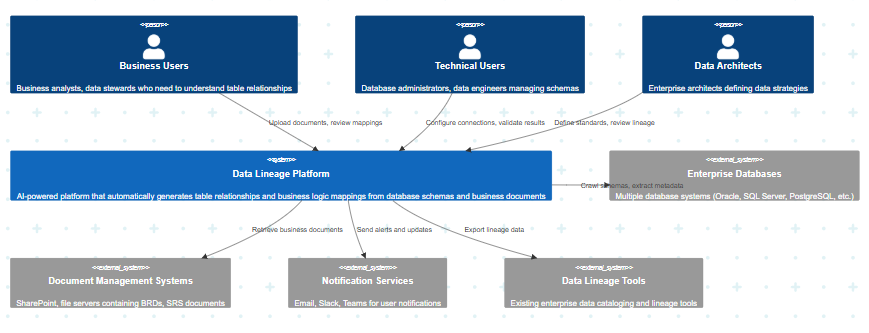
High Level Design
-
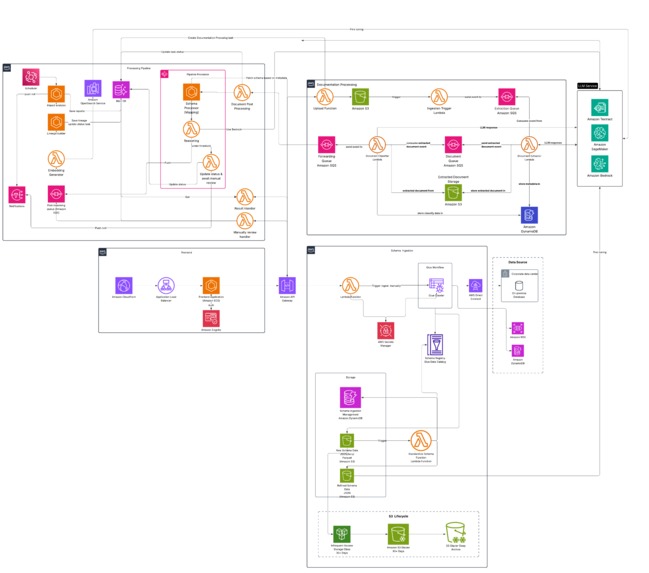
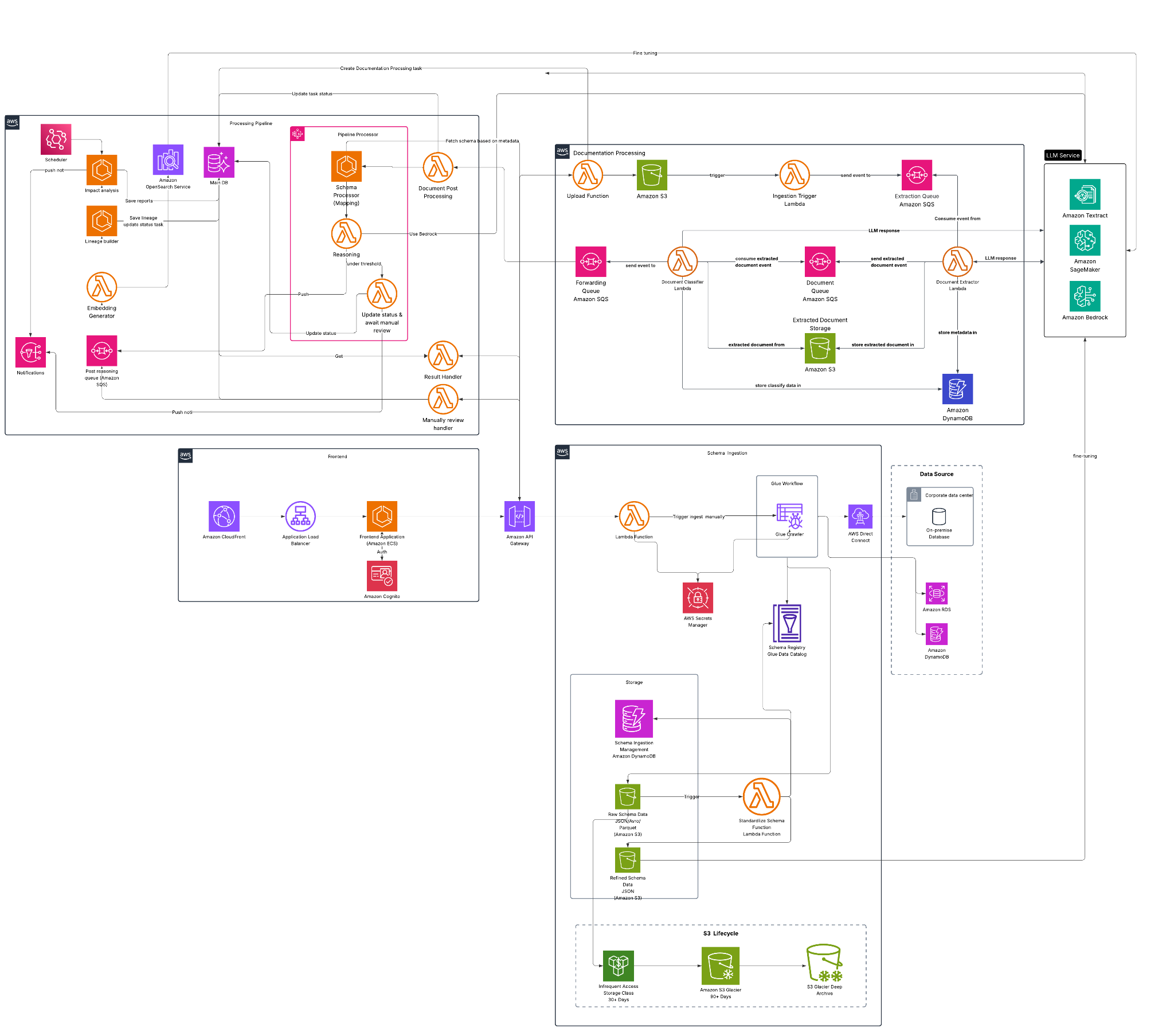
Low Level Design
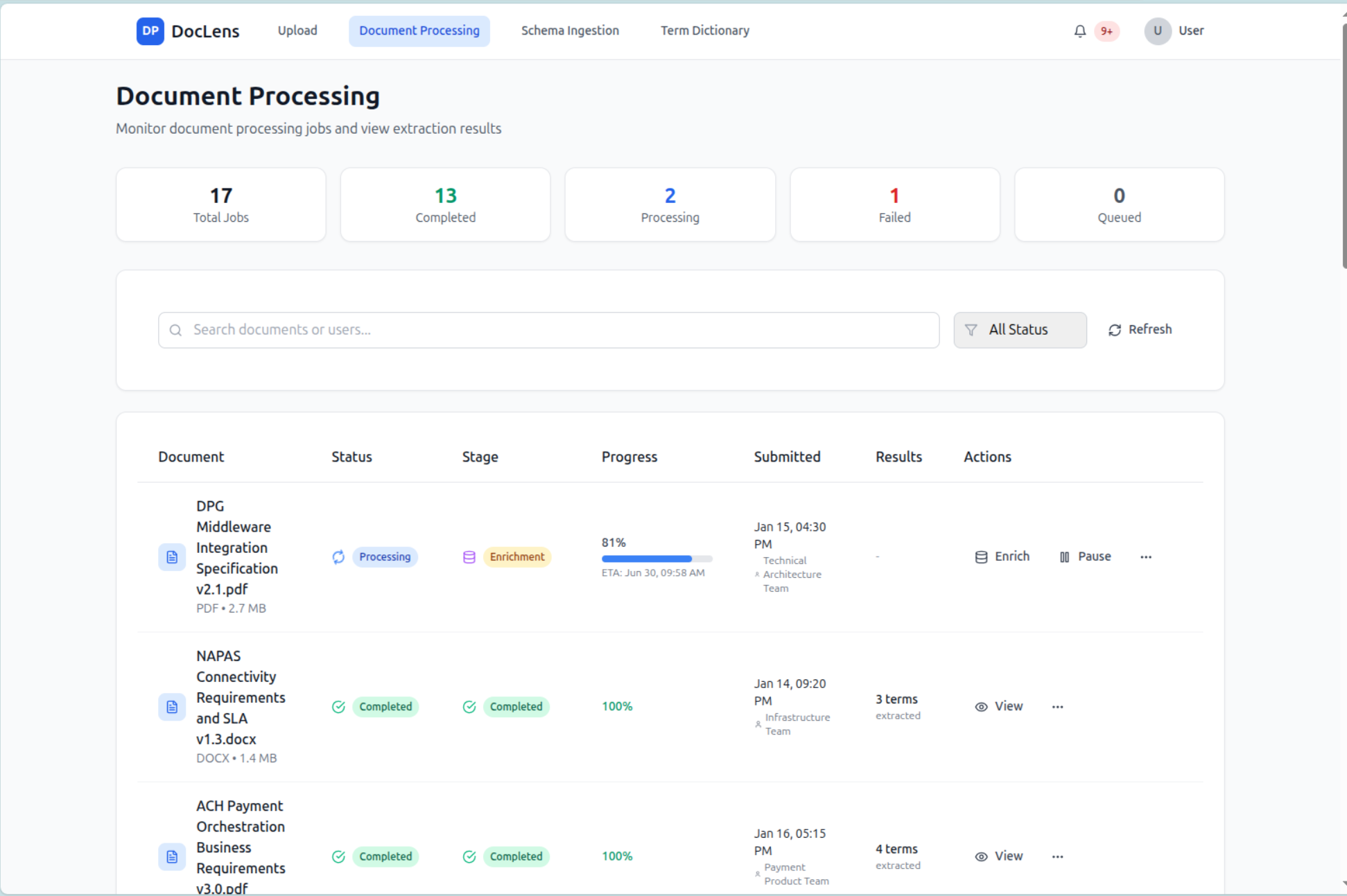
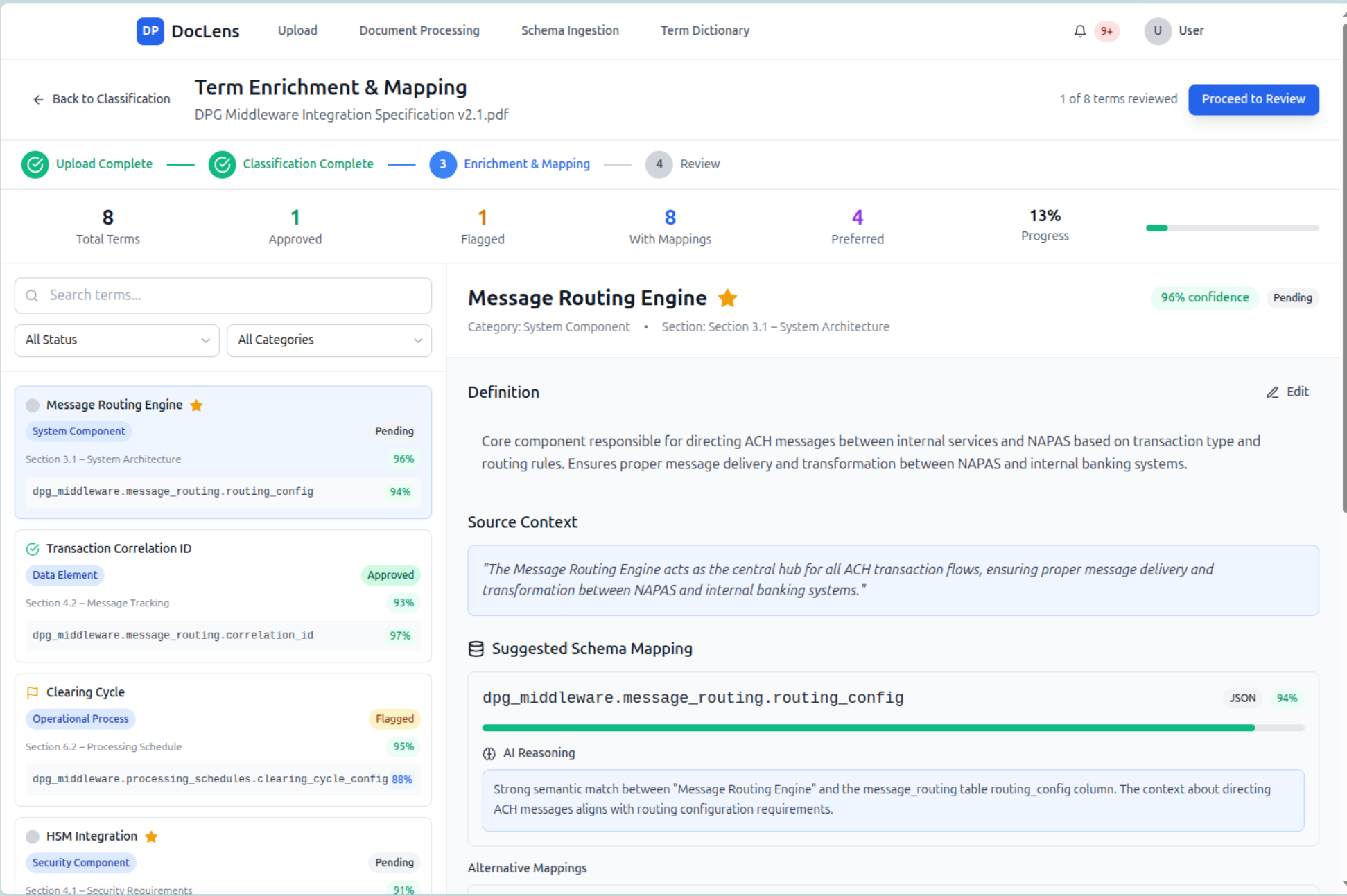
Inspiration
We often struggled with fragmented data lineage: business requirements lived in text documents while engineers managed schemas in code, leading to “inconsistent and manually-interpreted data relationships.”
We saw an opportunity to bridge this gap. We were inspired to use AI to automatically read unstructured BRDs/SRSs and procedure manuals, turning them into a unified data model. By doing so, DocLens promises a single source of truth that aligns business logic with technical implementation.
What it does
DocLens automates the creation of data lineage by ingesting both schema metadata and business documents. It uses a fine-tuned Large Language Model (LLM) to parse text and extract:
- Technical entities: table/column names
- Business terms: "Customer", "Primary Identifier", etc.
- Relationships: mappings, key constraints, and derivations
The AI engine then constructs a data model—defining tables, columns, primary/foreign keys, and the business rules justifying each connection.
The output is an interactive lineage graph with clickable nodes/edges. Users can trace data relationships back to the exact sentence in the source document—providing transparency and trust.
Result: Free-form requirements become a structured lineage graph + data dictionary, with drastic reduction in manual effort.
How we built it
Cloud-Native Architecture on AWS and Bolt
- Frontend: Built using Bolt and React – for document upload & graph visualization
- Backend: Built using Bolt to connect with API Gateway + Lambda functions
- Processing Workflow: AWS Step Functions for document-to-lineage orchestration
- AI Layer: Amazon Bedrock + LLMs (e.g. Claude) fine-tuned for financial metadata
- Storage:
- Amazon S3 (documents)
- Amazon Aurora PostgreSQL (lineage metadata)
- Semantic Engine: Vector similarity search and real-time matching between business rules and schema metadata
Schema Ingestion System:
- Built with AWS Glue + custom crawlers
- Automatically extracts schemas from databases (tables, columns, keys)
- Keeps lineage graph aligned with actual data sources
Semantic Matching + Human-in-the-Loop:
- NLP + vector embeddings match document terms with schema fields
- Low-confidence matches are routed for human expert review, improving quality with feedback loops
Challenges we ran into
Bridging business language and schema syntax
- Dealing with document noise (e.g. PDFs, scanned images, inconsistent terms)
- Needed advanced OCR and NLP for accurate extraction
Semantic alignment
- Mapping "Customer ID" in a BRD to
cust_idin a schema isn't trivial - Built synonym handling + business glossary integration
Security & Access
- Enforced IAM permissions, secret rotation via AWS Secrets Manager
Despite the complexity, these challenges helped sharpen the architecture and made the system more production-ready.
Accomplishments that we're proud of
- 90%+ accuracy in detecting relationships from business text
- Reduced manual analysis time from days to seconds
- Interactive UI with real traceability to original documents
- End-to-end automation pipeline with human-review workflow
- API export compatibility with Unity Catalog / AWS DataZone
Our system is not just a proof-of-concept—it’s a ready-to-integrate solution that augments modern data governance platforms.
What we learned
- The “why” matters as much as the “what”: Business context is essential
- Cloud-native AI stacks accelerate innovation: Bedrock + Step Functions = rapid iteration
- Trust-building matters: Human validation boosts adoption & accuracy
- AI needs a domain: Fine-tuning on financial metadata vastly improves results
We also sharpened our skills in LLM prompt engineering, secure cloud deployment, and end-user UX for technical insights.
What's next for DocLens
Continuous Learning from Feedback
- Every expert review updates the AI model
Expand document type support
- Excel specs, code annotations, multilingual documents
Governance Platform Integration
- Deep link lineage graphs into AWS DataZone / Unity Catalog
Scalability + UX Enhancements
- Faster load times, filter/search lineage, mobile support
DocLens is evolving into a production-grade tool for automated, AI-powered data lineage with audit-ready traceability.
Built by Team Chicken | Bolt Hackathon 2025
Built With
- amazon-web-services
- bolt
- claude
- llm
- postgresql
- react
- typescript

Log in or sign up for Devpost to join the conversation.