-
-
front page
-
Ai looks and works perfectly. Just on github I did not send env. so it wont be able to use api key.
-
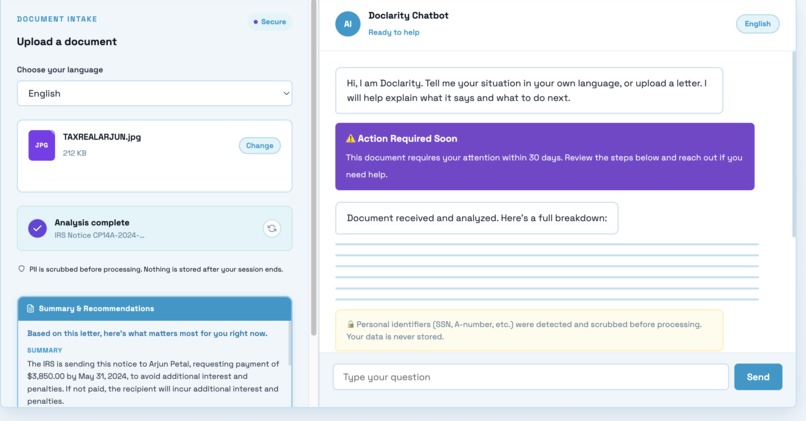
This is it working real time.
-
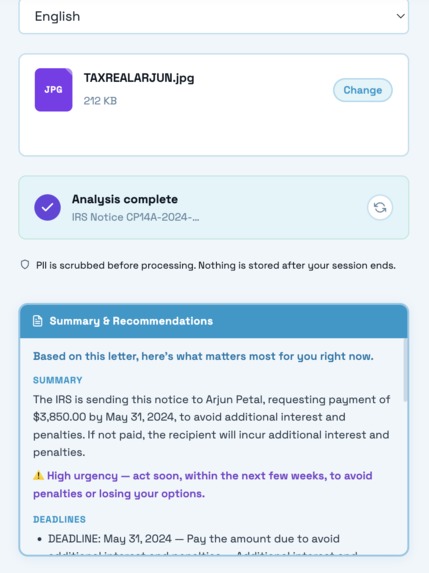
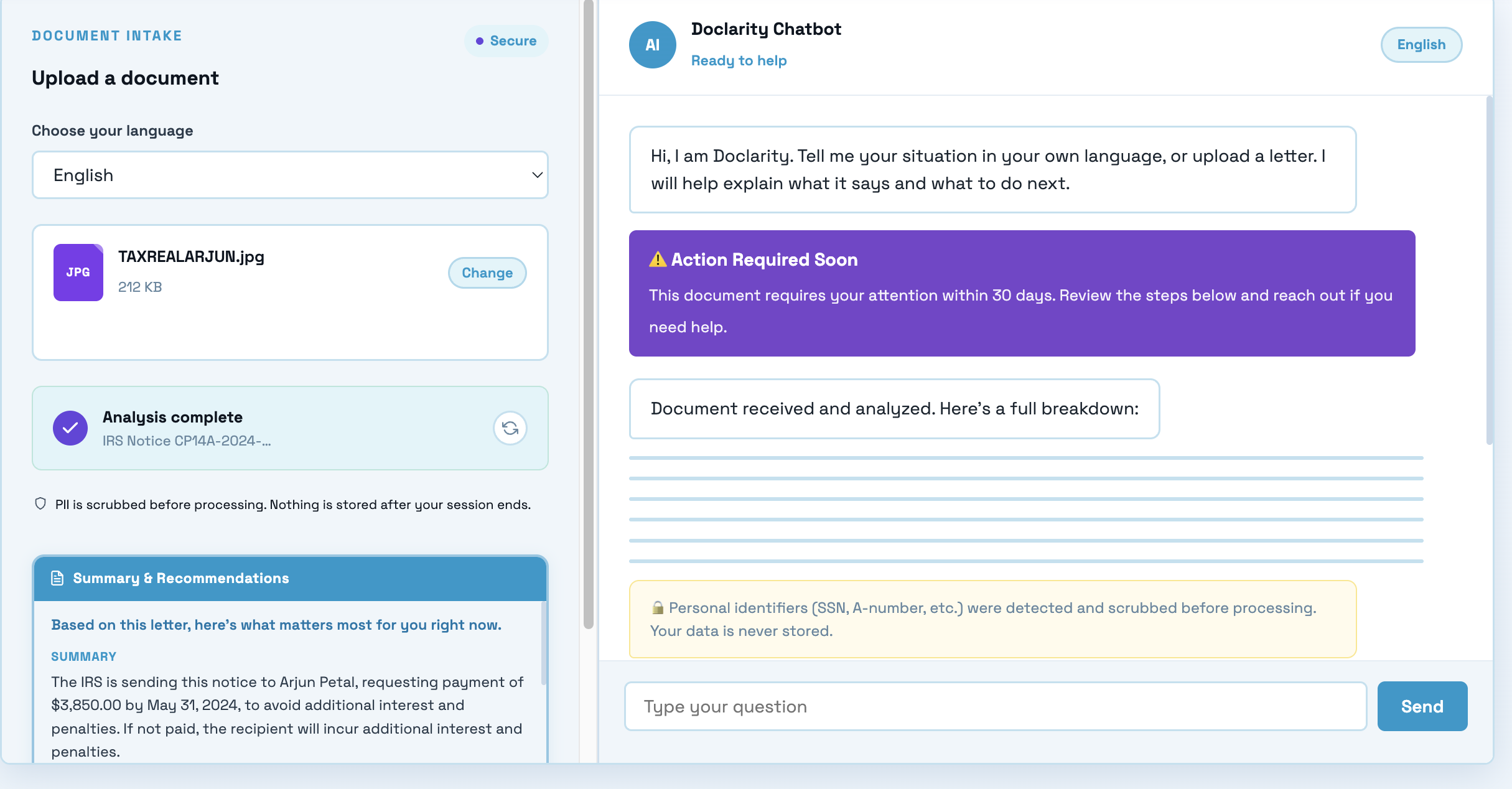
close up of summary and recommendations
-

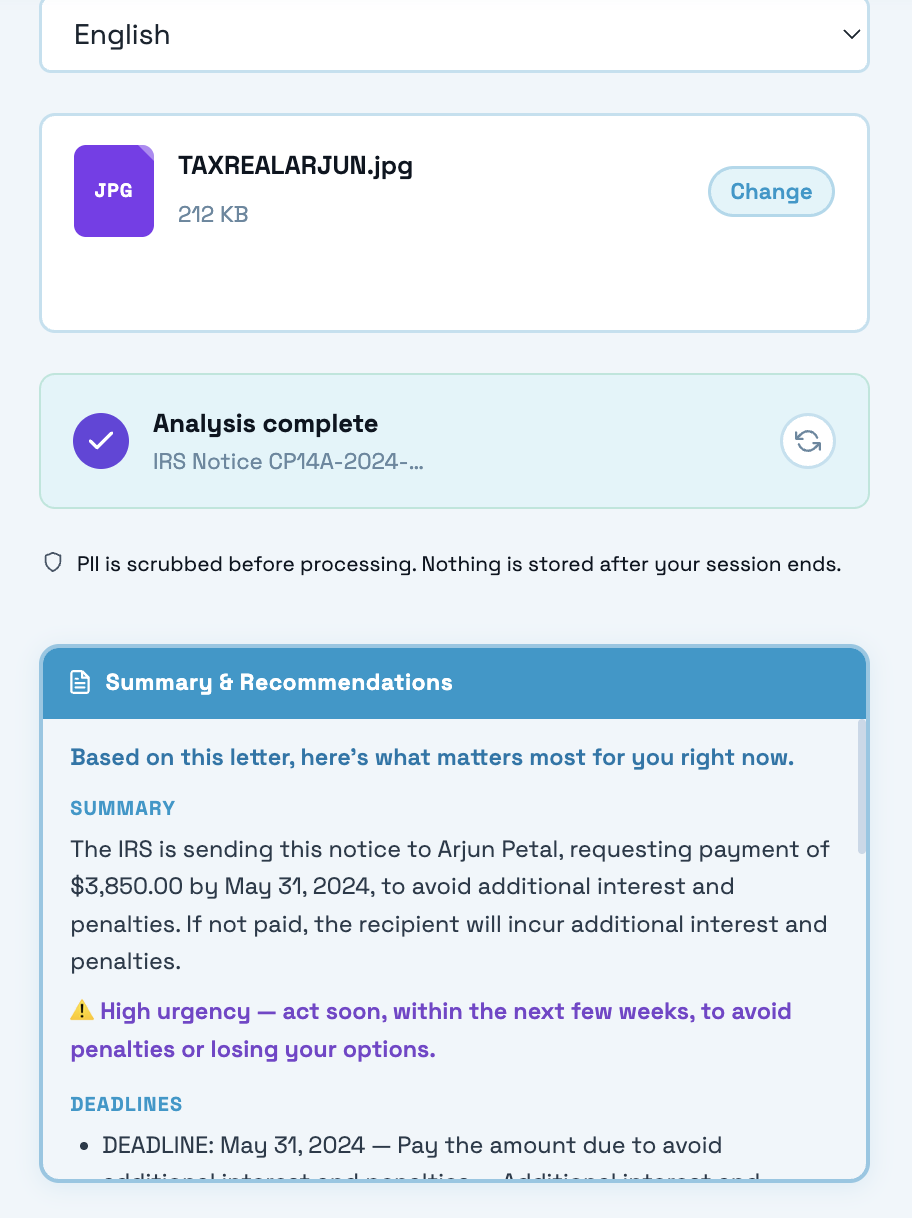
more closs up and more details
-

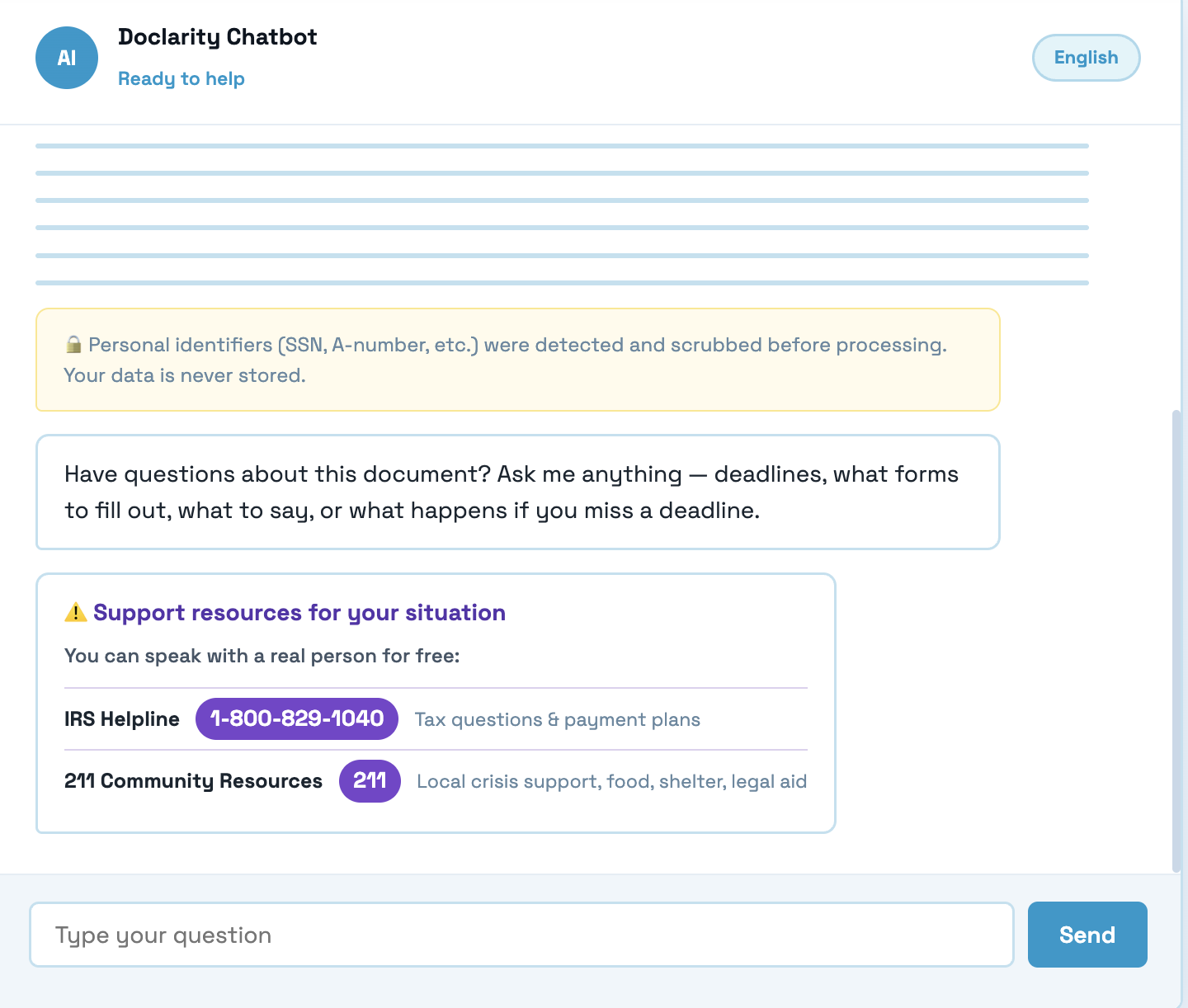
more close up (urgency, ai limitations, recommendations)
-
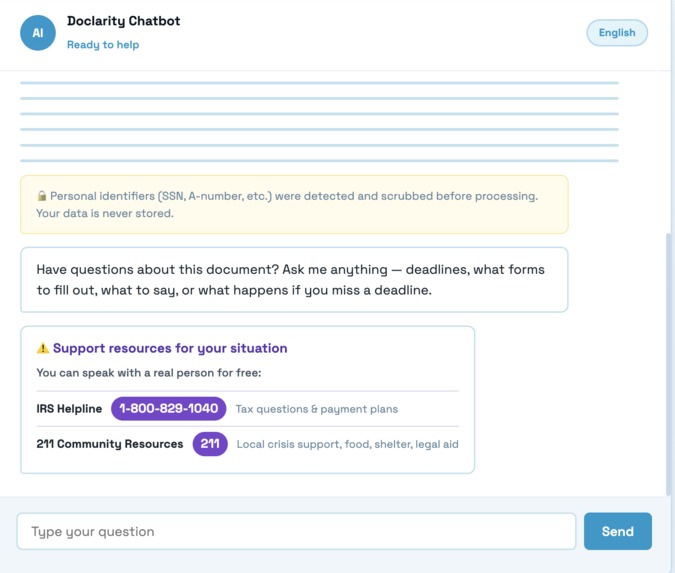
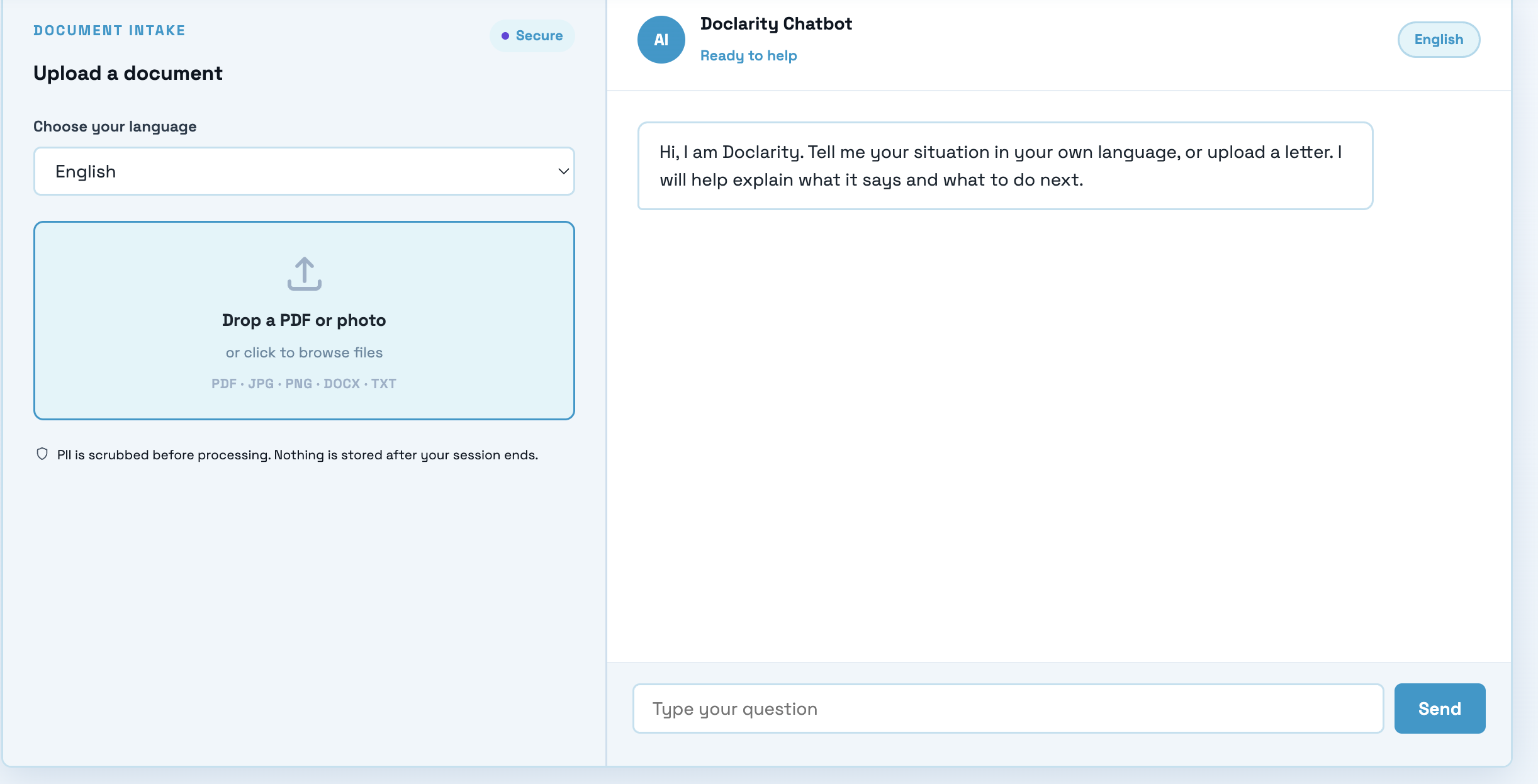
screen of the chatbot and what it provides before asking it anything
-

section that explains to people how it works and guides them through it.
-

what doclarity provides and more in depth understanding
-
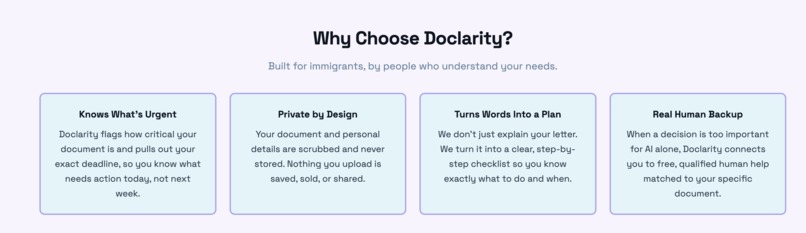
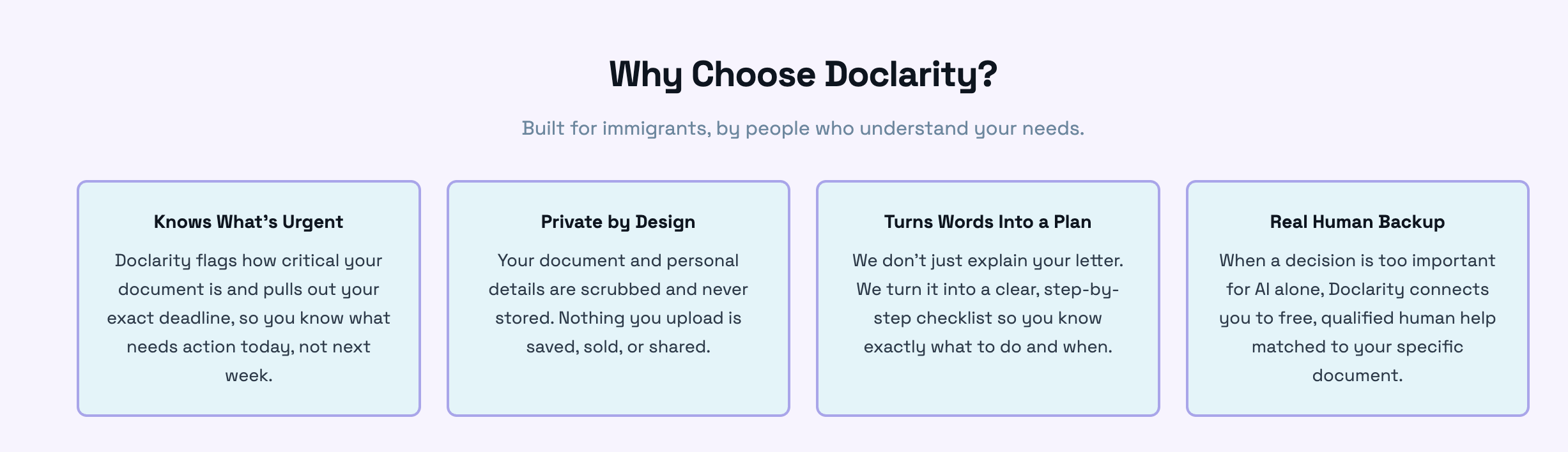
explains why doclarity and again provides understanding for the user
-
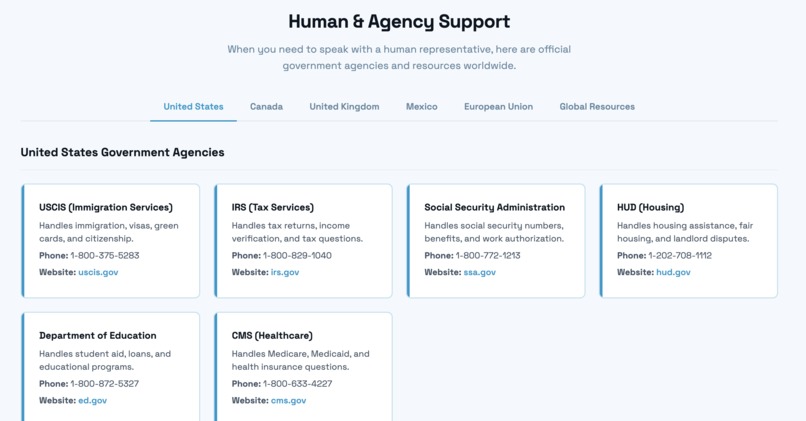
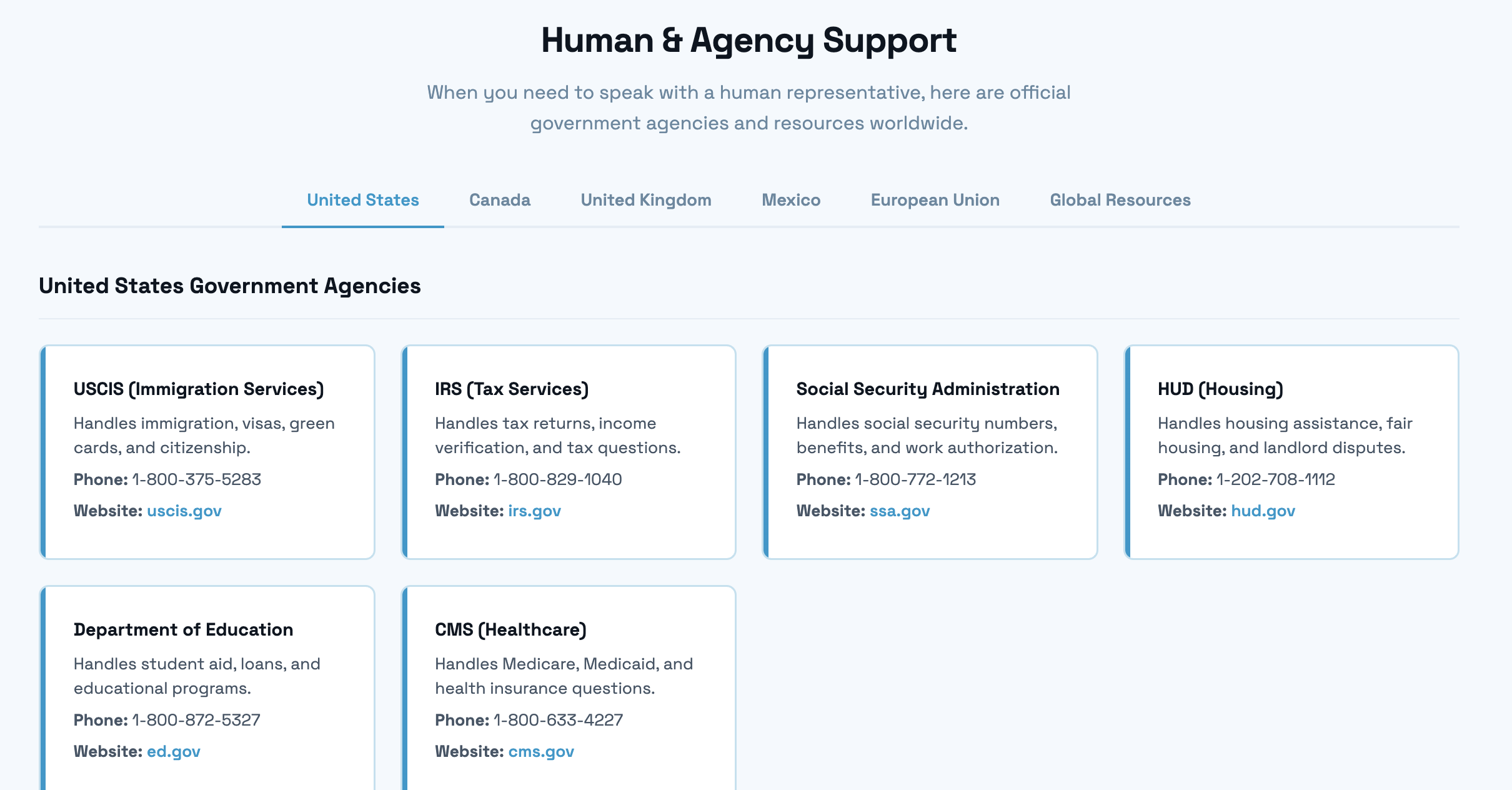
human and agency support. USA, Canada, UK, Mexico, European Union, Global Resources




Inspiration
We are immigrants ourselves, so we have watched what happens when an official letter lands in a home where no one yet understands the system. A single government, tax, or medical notice, written in dense legal language and carrying a deadline buried somewhere inside it, can decide whether a family keeps a benefit, avoids a penalty, or holds onto their status. The help technically exists, but it is scattered, written for lawyers instead of people under stress, and impossible to trust when you do not even know who is safe to ask. We built Doclarity for someone like Arjun, a twenty-year-old who moved to a new country alone to find work and opened a five-day IRS notice with no one to turn to. That moment, where uncertainty turns to fear, is exactly the gap we wanted to close.
What it does
Doclarity is a crisis-to-action translator. A user uploads or photographs a confusing government, legal, or medical letter, and Doclarity does four things. It scrubs out personal information so nothing private is ever stored, it reads the letter and explains in plain language what it means and what to do, it classifies how urgent the document is so the user instantly knows whether this is a problem for today, and it connects them to free, real human help matched to their situation. The result is a single, clear, trustworthy next step, including the amount owed, the exact deadline, how to respond, and who to call, and the whole experience can be read in the user's own language, including Hindi, with the interface, summary, and chat all translating together.
How we built it
The frontend is vanilla HTML, CSS, and JavaScript with no paid frameworks, talking to a FastAPI (Python) backend. For document understanding we use the Groq API running open-weight Llama models. Llama 4 Scout, a vision model, reads text directly from scanned photos, and Llama 3.1 8B Instant turns that text into a structured analysis containing the summary, deadlines with consequences, required actions, and an urgency level. A regex-based redaction layer scrubs identifiers such as Social Security numbers, phone numbers, A-numbers, and account numbers before any text reaches the model, and document content lives only in temporary in-memory session state that is never written to a database or logged. Translation is handled by a batched endpoint that sends the entire interface in one call, so switching languages stays fast.
Challenges we ran into
Our hardest problems were privacy, reliability, and translation. To guarantee nothing private is ever stored, we built the pipeline to strip identifiers before the model sees them and keep sessions in memory only. Translation was the trickiest. Our first version wiped the whole conversation on every language change, so we rebuilt it to keep the text on screen and translate it in place. We also had to make sure exact amounts, dates, and phone numbers survived translation, add Hindi as a supported language, and replace slow one-by-one calls with a single batched request. Along the way we hit a daily token limit and switched models, and we saw that a blurry scan can make the AI misread a figure, which shaped our responsible-AI design.
Accomplishments that we're proud of
We built a working end-to-end product that reads a real scanned letter, flags critical urgency, produces an actionable checklist, surfaces the correct free human resources for that document type, and translates the entire experience into another language, all while storing nothing. Most of all, we are proud that it genuinely moves a person from uncertainty to clarity and to action in under a minute, in the exact moment when help is hardest to find.
What we learned
We learned that clarity is a design problem as much as an AI one, and that responsible AI means knowing precisely where the model should stop and a human must decide. We also learned to respect the cost of an AI error in a high-stakes setting. If the probability that any single extracted field is misread is $p$, then across $n$ fields the chance that everything is correct is only $(1-p)^n$, which shrinks quickly as a document grows, so honest verification prompts and a human handoff are not optional, they are the safeguard.
What's next for Doclarity
Next we are adding confidence indicators on every extracted detail, so users can instantly see what is certain and what to double-check, alongside broader document coverage and a printable action plan they can bring to an appointment. Longer term, and only with explicit opt-in, Doclarity could aggregate anonymized patterns, never the documents themselves, to show local agencies where confusion is most concentrated, so help can arrive before a deadline rather than after. The human-in-the-loop boundary stays exactly where it is. The AI's job is clarity, and the human's job is judgment. We are very excited to continue growing and working with this project!
Built With
- bleach-(input-sanitization)-config:-python-dotenv-database:-none-?-document-data-is-held-in-in-memory-session-state-only
- chat
- claude
- codex
- css
- css-frontend:-vanilla-js/html/css-(no-framework)
- docx2txt
- docx2txt-(word)
- easyocr
- easyocr-and-pytesseract-(image-text)
- fastapi
- google-fonts-(space-grotesk)-backend:-fastapi
- googlefonts
- groqapi
- html
- javascript
- llama3.18binstant
- llama4scoutvision
- pdfplumber
- piiscrubbing
- pillow
- pillow-(image-handling)-security:-custom-regex-pii-scrubbing
- pydantic
- pydantic-/-pydantic-settings-ai-models-&-api:-groq-api-running-llama-3.1-8b-instant-(analysis
- pydantic-settings
- pytesseract
- python
- python-dotenv
- translation)-and-llama-4-scout-vision-(reads-scanned-letters)-document-extraction-/-ocr:-pdfplumber-(pdfs)
- uvicorn
- vanillajs



Log in or sign up for Devpost to join the conversation.