Inspiration
Today, every engineer has to work with a myriad of open-source libraries. Because of the rapid speed of development, many of these libraries lack proper documentation. We often find ourselves having to consult external sources to supplement official documentation. We then came up with the idea to leverage LLMs to create better documentation official open-source documentation with external sources. For demo purposes, we decided to improve Langchain, a framework for developing LLM-powered applications.
What it does
Docify is an AI-Enhanced Documentation project aimed at leveraging the power of LLMs to augment the quality of documentation in open source projects. The central goal of our project is to refine existing documentations, making them more comprehensive, accurate, and user-friendly. This will not only make open source projects more approachable but also foster an environment that encourages contribution.
Some key features:
- Automated Documentation Enhancement: Docify automatically reviews and refines existing documentation, eliminating manual effort and ensuring consistency.
- LLM Augmentation: By leveraging LLMs, our system provides accurate and meaningful enhancements to existing documentation.
- Wide-Ranging Support: The project is versatile enough to cater to a broad spectrum of open source projects, making it a universally applicable tool.
How we built it
We first built a crawler module that can crawl documentation webpages and save their content and metadata. We then embedded the content and stored in a vector store. For enhanced content generation, we implemented a novel self-critiquing chain to ensure high quality generations. The chain runs for X rounds (determined by the user) and executes two steps: critique and improvement. We noticed that the output quality improved drastically after a few rounds.
We also have an experimental package that scrapes GitHub issues, YouTube transcripts, and generic webpages to further augment and improve quality further.
Challenges we ran into
The biggest issue we ran into was speed. Because we are limited by parallel executions on Claude, we couldn't generate multiple documentation pages simultaneously. This made it hard to quickly iterate on our generation process. Additionally, we were limited by having one collection on Pinecone, so we decided to not add external sources for today's purpose. Lastly, ensuring that the model doesn't hallucinate proved to be a difficult task, but our experimental solution is adding an anit-hallucination step at the end of our generation pipeline.
Accomplishments that we're proud of
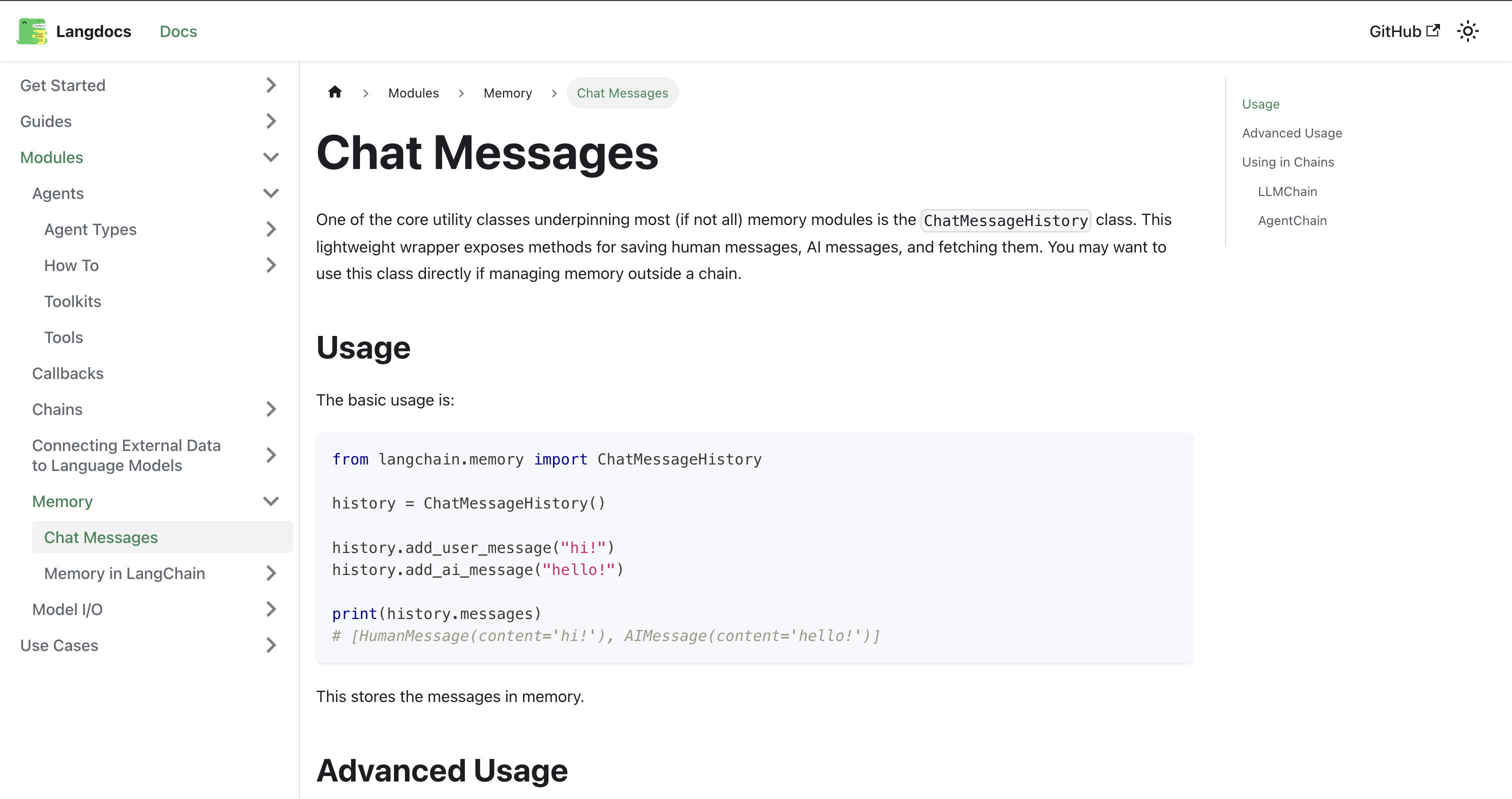
Docify works end to end, from scraping the official documentation repository to generating improved documentation in just 1 day! You can take a look here!
What we learned
We learned how to build LLM-powered applications from the ground up, integrating tools like Langchain and LlamaIndex. Connecting a vector store like Pinecone to our model was also new to us, but ended up being a crucial part of our design. Finally, we gained more intuition with prompt engineering, figuring out what works and what doesn’t, as well as new tricks to achieve the results we wanted.
What's next for Docify
- Support including more content source when generating improved documentation such as blog post, Youtube video, Github issues, and more
- Improve our documentation generation workflow
- Better prompt engineering
Built With
- anthropic
- langchain
- llamaindex

Log in or sign up for Devpost to join the conversation.