
Inspiration
As a piano tutor, often times for higher level students, what they require is not a teacher but rather a guide. High level piano students aren't learning symbols or notes, they are learning where they are playing wrong. So why not create a software that does that? I wanted to build something closer to a real piano teacher than a generic score checker.
Most practice tools only tell you whether a note was right or wrong. I wanted a system that could also answer:
- Did I play the right notes, at the right time?
- Was my tempo stable?
- Did my posture look healthy while I was playing?
- What should I fix next, in plain language?
That idea became Doceo: a performance tutor that combines audio analysis, video analysis, and an AI-generated coaching layer.
What it does
Privtor AI takes in:
- a reference MIDI file
- a performance video
Then it:
- extracts audio from the video
- transcribes the performance into note events
- aligns the played notes against the reference score
- analyzes posture from sampled video frames
- generates feedback and drills
- renders the result in a web interface
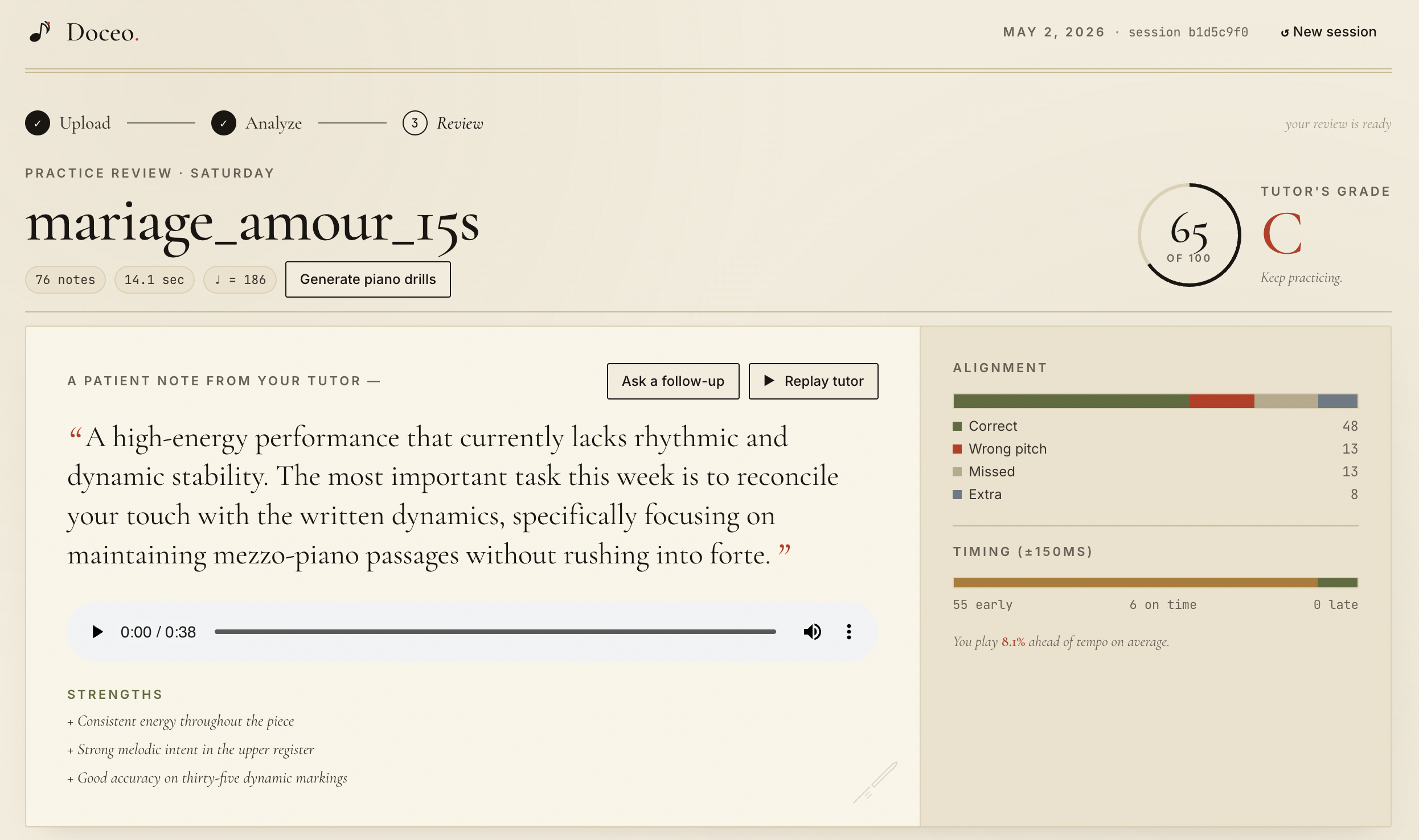
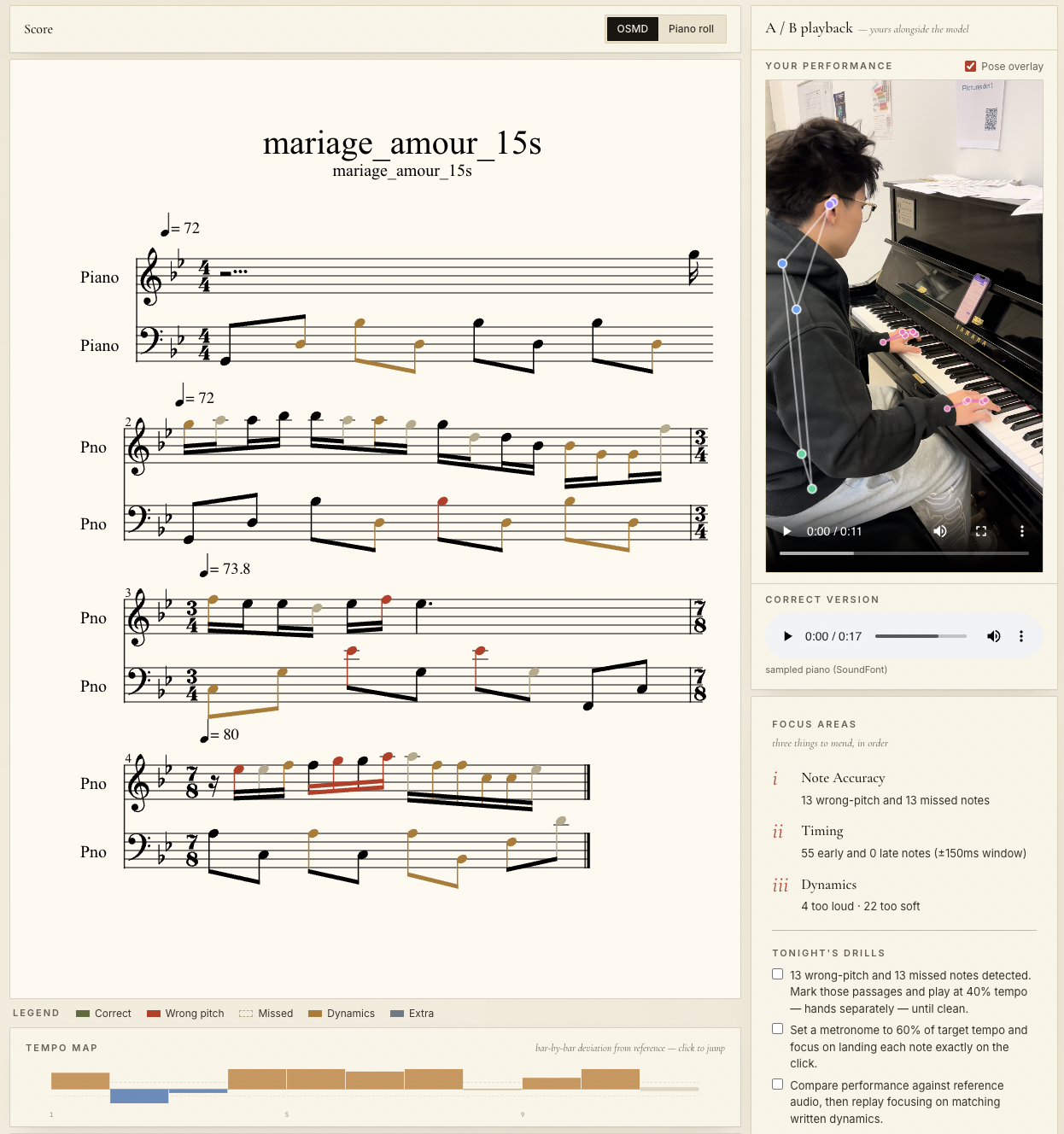
Output:
- score annotations
- piano-roll fallback
- video playback with pose overlay
- reference audio playback
- AI tutor feedback
How we built it
Frontend
- upload reference MIDI
- upload performance video
- run analysis
- view results
The results page shows:
- the annotated score
- a piano-roll fallback
- A/B playback with the user video and synthesized reference audio
- posture overlay on top of the video
- focus areas and drills
- AI tutor feedback
Backend
The backend lives in api/ and is built with FastAPI.
Pipeline:
/midiparses the reference MIDI, exports MusicXML, and synthesizes a reference audio track/videostores the performance video and extracts a mono WAV file withffmpeg/analyzetranscribes the extracted audio with Basic Pitch/alignmatches the played notes to the reference score with DTW/posesamples video frames with OpenCV + MediaPipe Pose/Hands/tutorfeeds the analysis into Gemini and ElevenLabs for spoken coaching
Core Libraries
FastAPIfor the API layerNext.jsandReactfor the frontendffmpegfor video-to-audio extractionbasic-pitchfor audio-to-note transcriptionpretty_midiandmusic21for MIDI/score handlingfastdtwfor note alignmentOpenCVfor frame samplingMediaPipefor pose and hand landmark detectionGeminifor tutor script generationElevenLabsfor voice output
Challenges we ran into
Converting Video to MIDI With High Accuracy
This was the hardest part of the project.
The raw audio coming from a performance video is messy:
- room noise leaks into the signal
- pedal resonance blurs note boundaries
- timing is not perfectly quantized
- transcribers can miss short notes or create duplicates
- performance tempo can drift compared with the reference
To make the transcription usable, I had to add multiple cleanup layers:
- extract a clean mono track from the video
- run Basic Pitch to get candidate note events
- smooth and merge near-duplicate transcribed notes
- estimate timing offset against synthesized reference audio
- reference-guide the note cleanup using the score itself
- write both raw and cleaned MIDI outputs for debugging
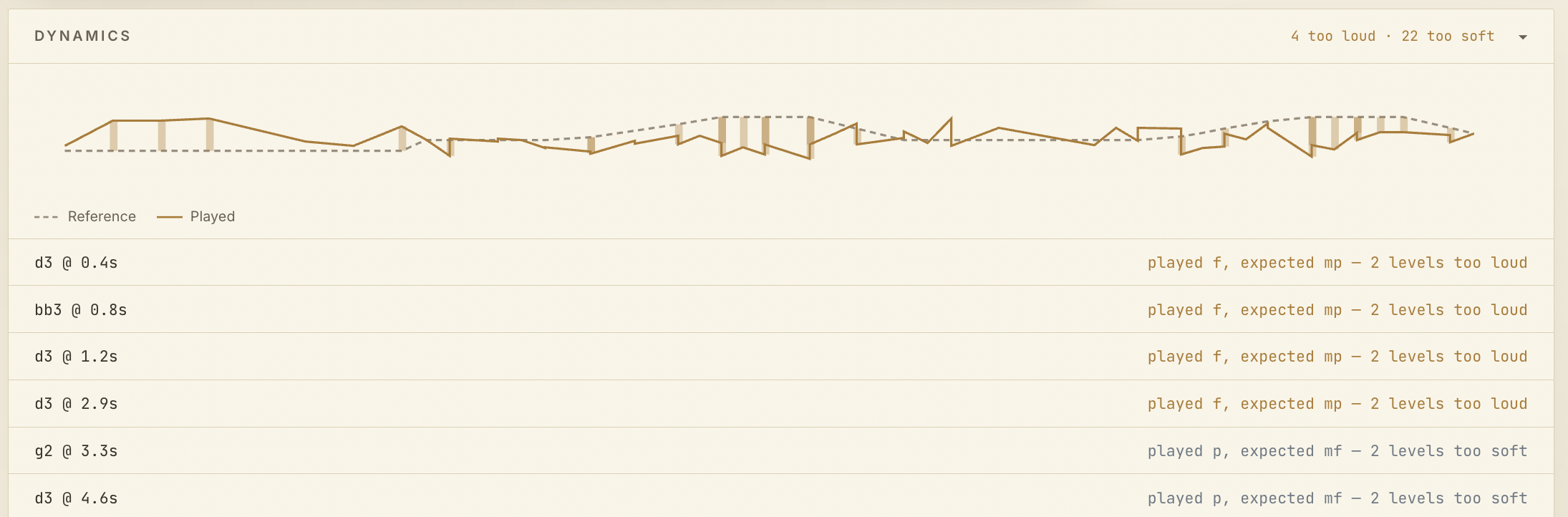
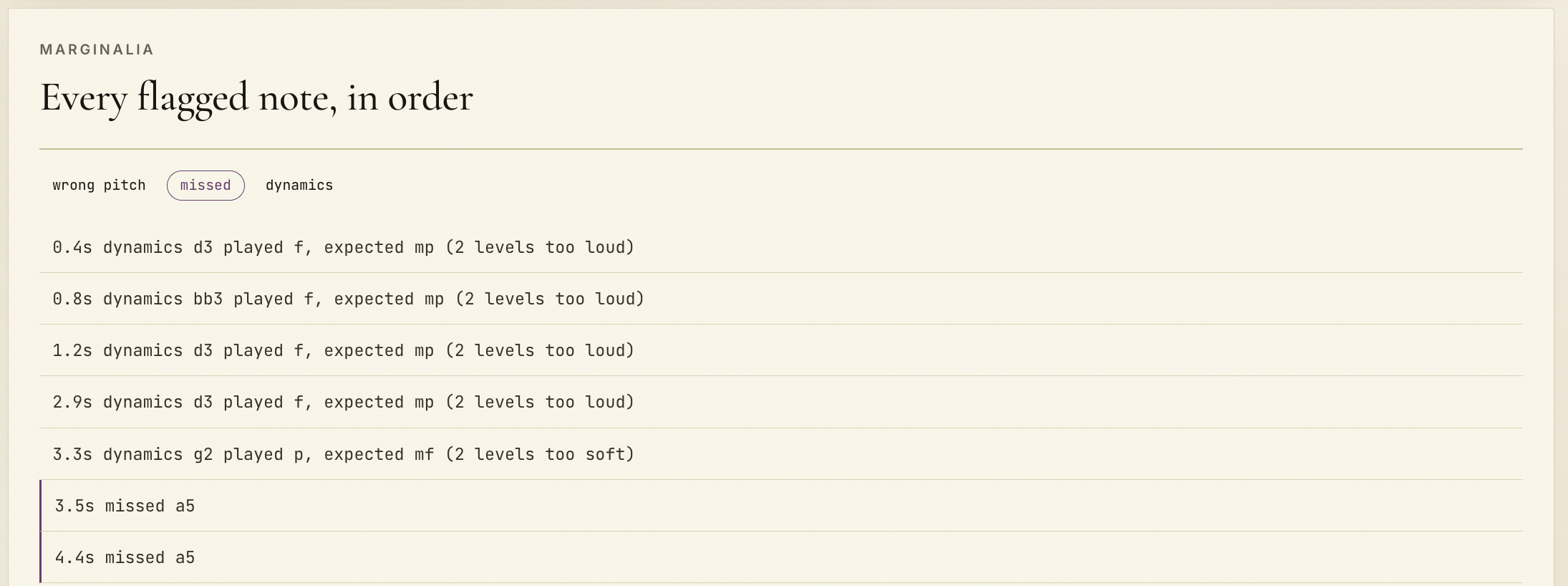
Even after transcription, note alignment still needed a second pass. I used DTW to compare the played note stream against the reference, then labeled each event as correct, wrong pitch, missed, extra, early, late, or on-time.
That combination of transcription plus alignment is what makes the output feel coherent instead of noisy.]
Accomplishments that we're proud of
Being able to put all of the moving parts together and able to scrape the audio from video into a actual usable MIDI file as this was extremely difficult.
What we learned
Audio transcription needs cleanup and alignment to be useful.
- Reference-aware heuristics matter when performances drift from the score.
- Audio and video analysis solve different parts of the problem.
- Specific feedback beats a raw score.
- Structured inputs make AI feedback much better.
What's next for Doceo
- improve transcription accuracy on noisier recordings
- support longer performances and bigger excerpts
- separate left-hand and right-hand analysis
- improve posture scoring
- support multi-song sessions
- track progress across practice attempts
- deploy the pipeline for reliable scale
- personalize feedback from recurring mistakes




Log in or sign up for Devpost to join the conversation.