-
-
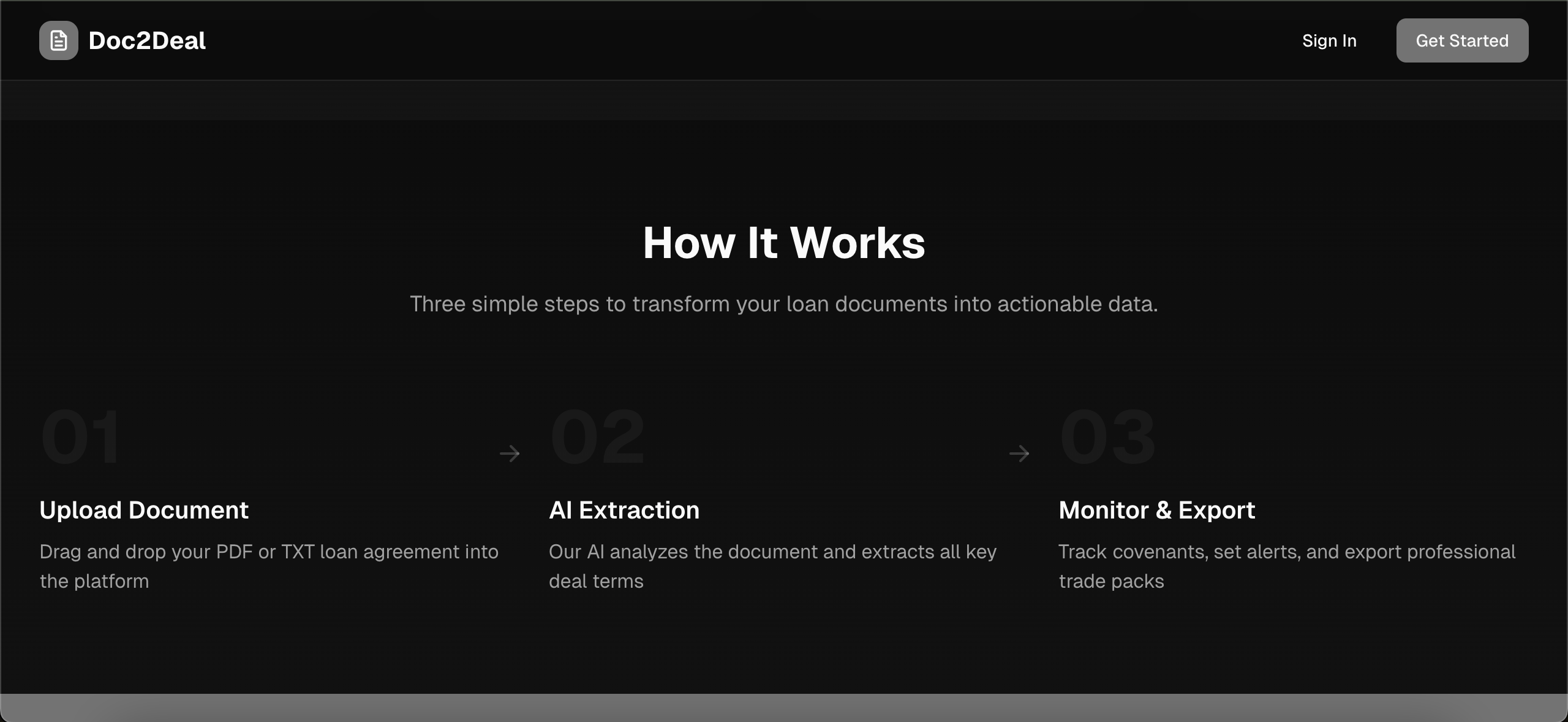
How it Works
-
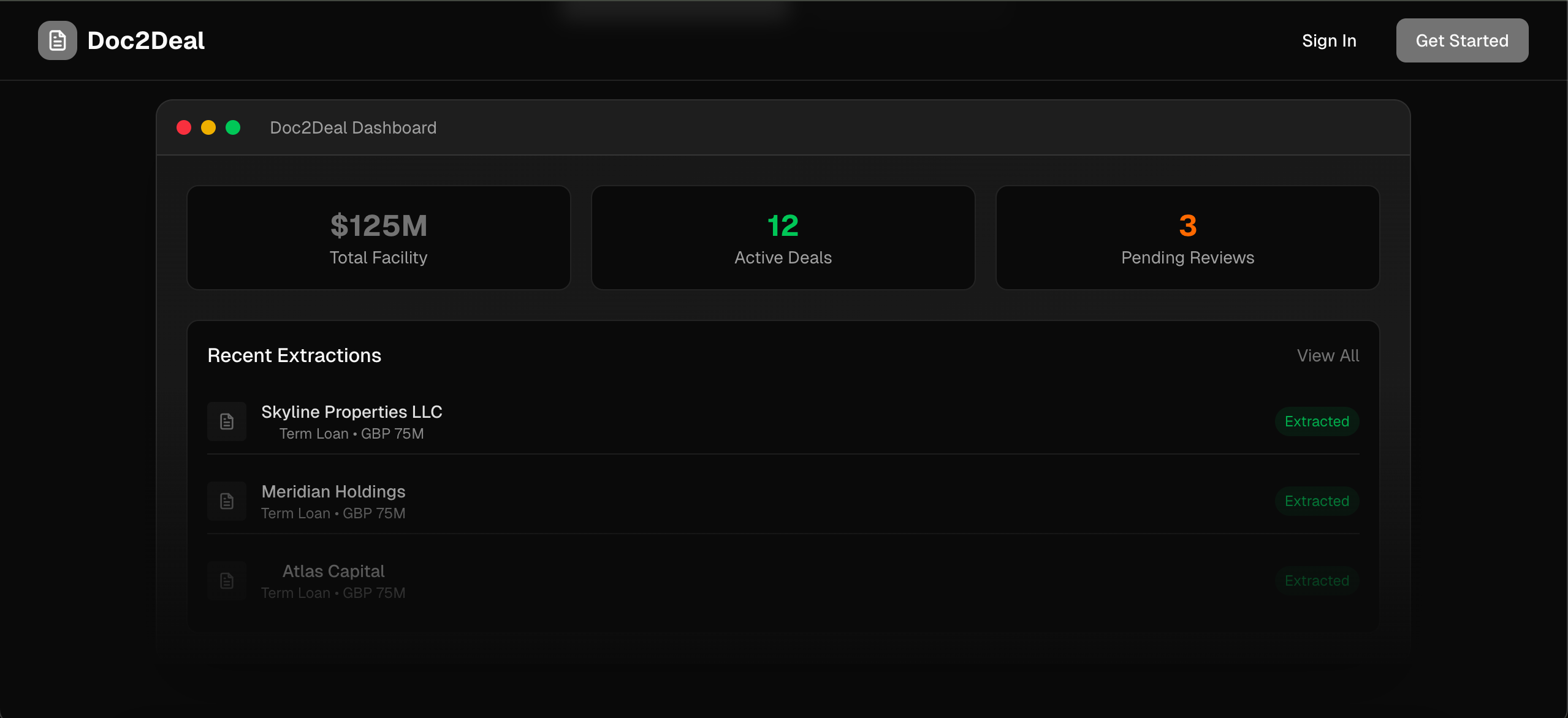
Dashboard Overview
-
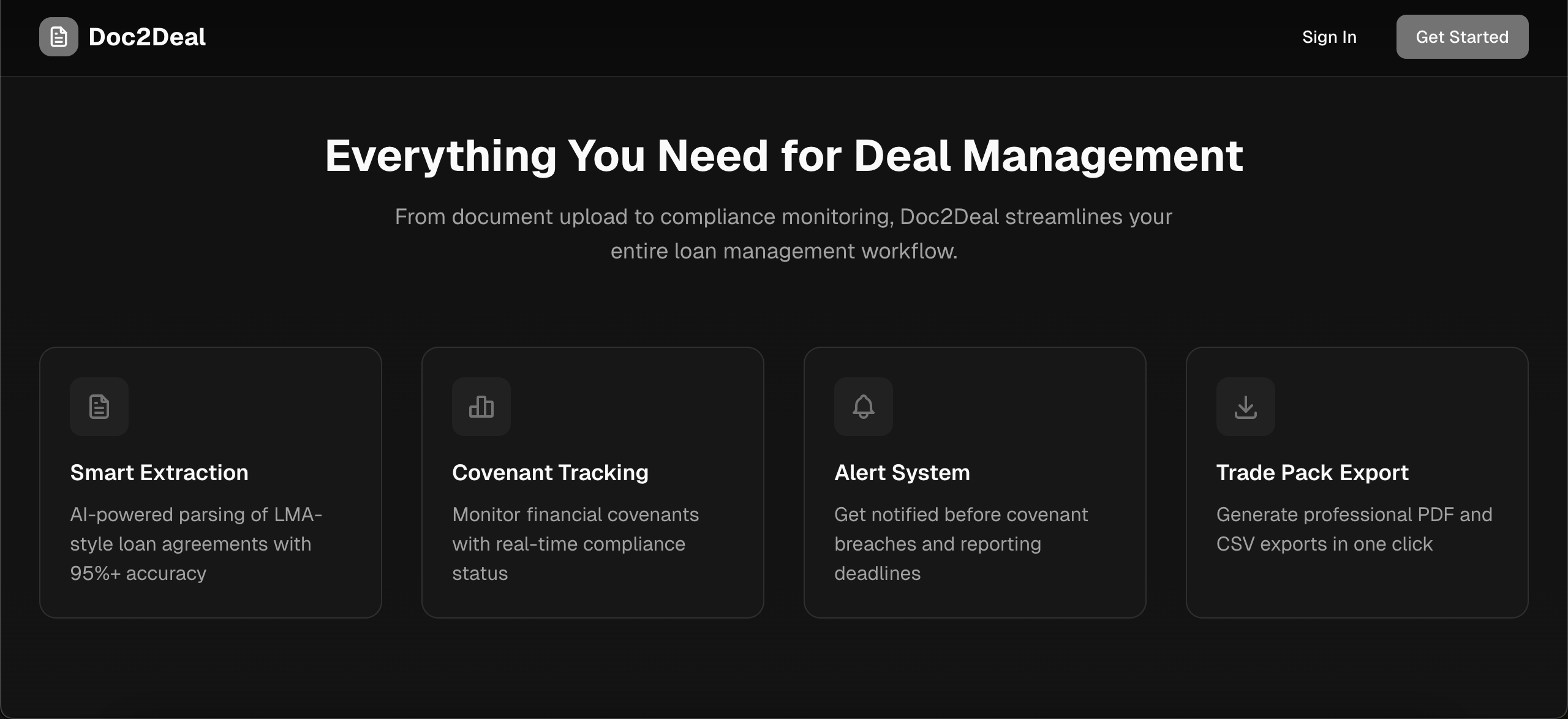
Features
-
Landing page
Doc2Deal
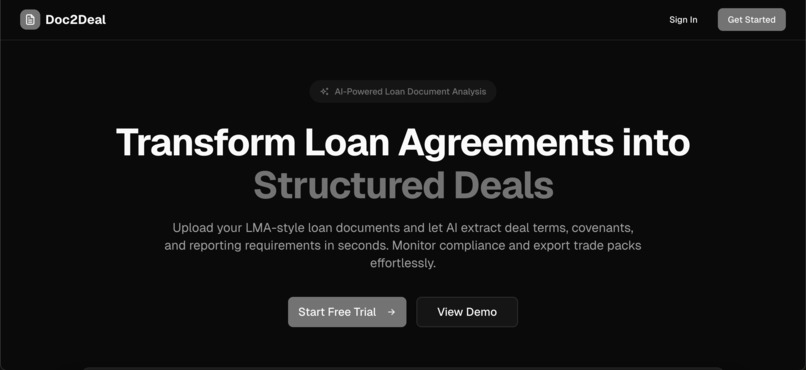
Doc2Deal transforms complex loan agreements into structured, actionable data.
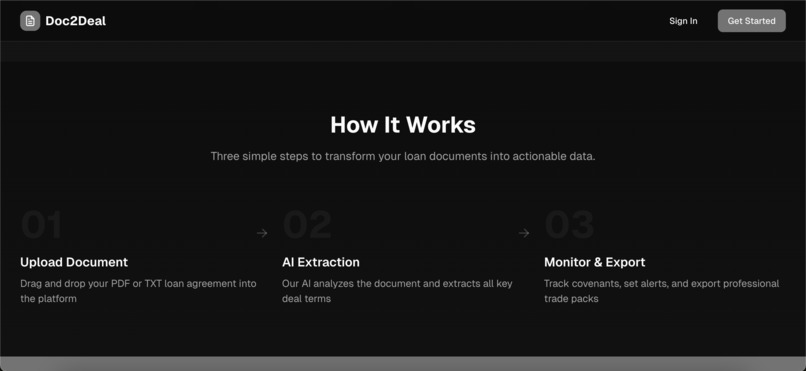
Upload → Extract → Monitor → Export
- Smart Document Upload - Drag and drop PDF or TXT loan agreements
- AI-Powered Extraction - Cerebras LLM extracts borrower info, facility details, interest rates, dates, and covenants
- Covenant Tracking - Monitor financial covenants with thresholds, test frequencies, and compliance status
- Trade Pack Export - Generate professional PDF and CSV exports with one click
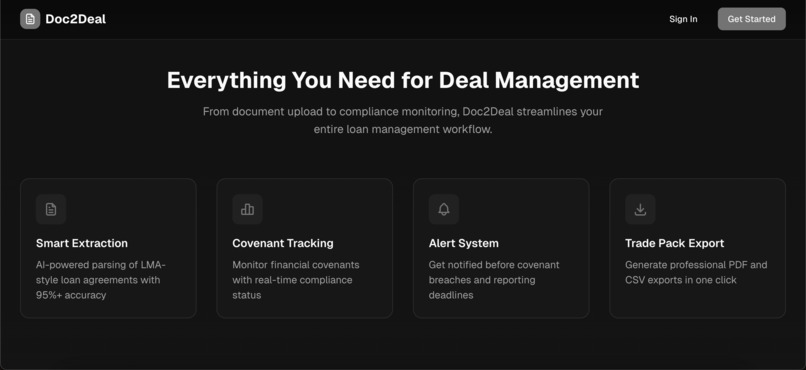
Key features:
- Extracts 20+ data points from LMA-style loan documents
- Identifies financial covenants (LTV, ICR, DSCR, etc.) with thresholds
- Captures reporting requirements and deadlines
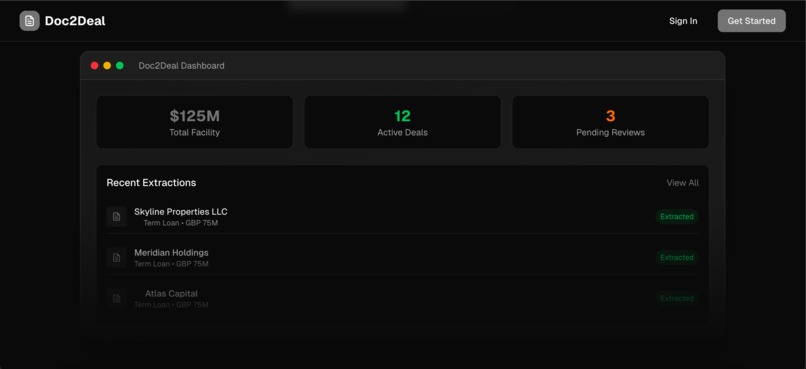
- Beautiful dashboard for deal management
- Instant term sheet generation
How we built it
Frontend:
- Next.js 14 with App Router for a modern React experience
- Tailwind CSS + shadcn/ui for a polished, professional UI
- Clerk for secure authentication
- React Query for efficient data fetching
Backend:
- FastAPI for high-performance async Python APIs
- Cerebras Cloud SDK for AI-powered document extraction
- PyMuPDF for PDF text extraction
- Pydantic for robust data validation
Database:
- Supabase (PostgreSQL) for reliable data storage
- Structured schema for documents, deals, covenants, and reporting dates
AI Pipeline:
- Primary: Cerebras LLM with custom extraction prompts
- Fallback: Rule-based regex extraction for reliability
- Load balancing across multiple API keys
Challenges we ran into
1. Handling Diverse Document Formats Loan agreements come in countless formats. Some have clear section headers, others are walls of text. We built a hybrid extraction system—AI for understanding context, regex patterns for fallback reliability.
2. Covenant Extraction Complexity Financial covenants are expressed in many ways: "not greater than 3.0x", "minimum of 2.5:1", "shall not exceed 65%". We trained our prompts to recognize these patterns and normalize them into structured data.
3. Data Validation Edge Cases AI sometimes returns unexpected values—null where we expected numbers, "continuous" instead of "quarterly". We added defensive validation layers to handle edge cases gracefully.
4. Real-time Processing UX Document extraction takes a few seconds. We implemented progress indicators and status updates to keep users informed and engaged during processing.
Accomplishments that we're proud of
✅ End-to-end working product - From upload to export, everything works
✅ Beautiful, professional UI - A landing page and dashboard that looks production-ready
✅ Robust extraction pipeline - AI primary with rule-based fallback ensures reliability
✅ Real document support - Successfully extracts data from actual loan agreement formats
✅ Complete data model - Handles deals, covenants, reporting dates, and term sheets
✅ Export functionality - Professional PDF and CSV trade pack generation
What we learned
1. Prompt Engineering is Critical The difference between good and great extraction is in the prompt. We iterated dozens of times on our extraction prompt to get consistent, accurate results.
2. Always Have a Fallback AI is powerful but not perfect. Our rule-based fallback has saved us countless times when the LLM returns unexpected formats.
3. Validation at Every Layer From file upload to database insertion, validate everything. Pydantic models caught bugs before they reached production.
4. Cerebras Speed is a Game-Changer The fast inference time means we can process documents interactively. Users don't have to wait minutes—they see results in seconds.
What's next for Doc2Deal
Short-term:
- OCR support for scanned documents
- Batch upload for processing multiple documents
- Covenant breach alerts and notifications
- Deal comparison and analytics
Medium-term:
- Integration with loan origination systems
- Custom extraction templates for different document types
- Collaborative features for team workflows
- Audit trail and version history
Long-term:
- Predictive covenant breach analysis
- Natural language querying ("Show me all deals with LTV > 60%")
- Multi-language document support
- On-premise deployment for enterprise customers
Tech Stack Summary
| Layer | Technology |
|---|---|
| Frontend | Next.js, Tailwind, shadcn/ui, Clerk |
| Backend | FastAPI, Python, Hypercorn |
| AI | Cerebras Cloud (qwen-3-235b-a22b-instruct-2507) |
| Database | Supabase (PostgreSQL) |
| PDF Parsing | PyMuPDF |
Links
- Live Demo: https://doc2deal.vercel.app
- GitHub: https://github.com/todorakai/Doc2Deal
Try It Out
- Visit https://doc2deal.vercel.app
- Sign up for an account
- Upload a loan agreement (PDF or TXT)
- Watch the magic happen!
Built with intention and precision
Built With
- cerebras
- nextjs
- python
- qwen
- supabase

Log in or sign up for Devpost to join the conversation.