-
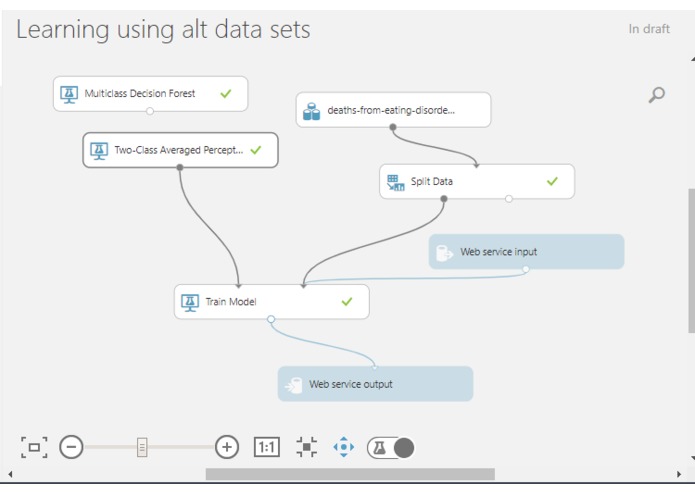
Last iteration of the model
Doc Assist By: John Daley 07/04/19
Abstract: The premise of “Doc-Assist” is to allow doctors to reduce the frequency of misdiagnosis, in the area stress/mental health related symptoms, as it pertains to the physical manifestations of said health issues. By using Microsoft Azure Machine Learning Studio, the team tried to create correlations/relationships by analyzing and learning from data sets sent into the cloud service. Which would then be featured in a simple easy to use web app. The primary target group is doctors in countries which have less resources, thous allowing the doctor to make fast more accurate diagnosis and be able to see more patients. This was unsuccessful as the team was very new to machine learning and the platform used. It is also worth noting that the data sets needed for this were not readily available.
Introduction: In many countries around the world mental health issues are often misdiagnosed, even more so in countries lower on the economic spectrum. In countries that had lower amounts of psychiatrist in ratio to their total populations showed large increases in mental disorders(s) along with higher substance abuse.[1] The web application would allow a doctor to get assistance in making connections between physical symptoms and the underlying causes, which when concerning mental health, can be hard to properly identify. It would provide a list of 3-5 results with weights attached to them and follow up suggested questions to help eliminate them as potential diagnosis. Research was primarily done through online research in database repositories, scientific papers and Microsoft's documentation. Research was conducted in this manner because of limited time and knowledge in the areas surrounding the project by the team. Method: The data sets ranged in size but were consistently between 202 and 212 tuples. The idea in principle was to collect data sets, pass them to a data model built in Machine Learning Studio to establish a baseline. The web app would then allow the doctor to enter a patient's information and get back results that might be overlooked due to their more stressful schedules. The web app was planned to be built using angular.js.
Results : The results were poor, as mentioned before, because the researcher did not have access to the required data sets and lacked the proper knowledge to build and utilize the tools needed properly build a prototype. Other data sets were used involving mental health statistics and substance abuse in relation to GDP among other metrics. As would seem logical countries that were lower on the economic scale showed an increase in most mental health areas. An interesting point was that eating disorders and depressions appeared often higher in high income countries. These data sets were used to learn more about machine learning and Machine Learning Studio, thus the project is a success in the context of learning much in a short amount of time along with having a wonderful time. Inputting data properly was a serious challenge, even more so when sleep deprived. Also using the wrong types of machine learning algorithms did not help the process proceed quickly.
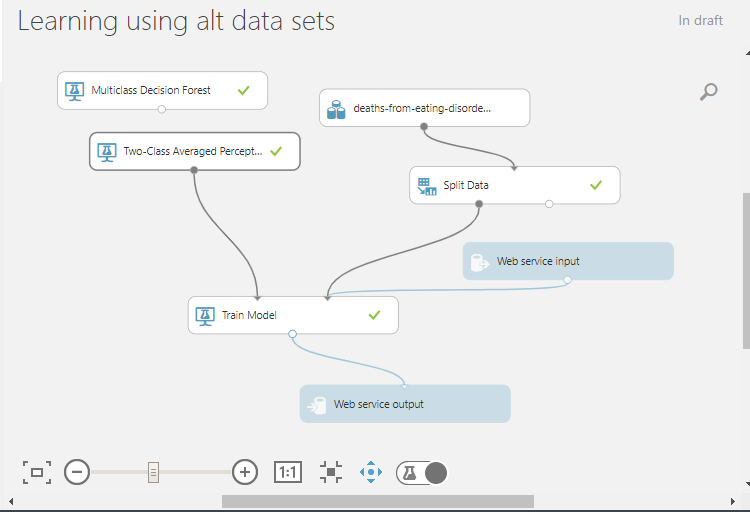
Below is the results of the alternative data sets after being passed through the simple data model (figure 1), which is followed by a screen of the last iteration of the model(figure 2 which is moved to the thumb nail), as there was many iterations that were not documented.
Averaged Perceptron Classifier Settings Setting Value Batch Size 256 Initial Learning Rate 1 Learning Rate Decay Exponent 0.5 Averaging Weight 0.5 Tolerance 1E-05 Maximum Number Of Iterations 10 Allow Unknown Levels True Random Number Seed
Feature Weights Feature Weight Drug use disorders (%) -0.770137 Eating disorders (%) 0.491947 Schizophrenia (%) 0.402179 Depression (%) -0.377172 Bipolar disorder (%) 0.315855 Alcohol use disorders (%) 0.221333 Suicide rate (deaths per 100,000) -0.151786 Bias 0.119231 Anxiety disorders (%) -0.0457013 Deaths - Eating disorders -0.000099353
Figure 1. Visualized training model of the last iteration
Conclusion : Although on the surface this may seem like a failure the experience, learning and enjoyment had was well worth the struggle and lack of sleep. The general premise of the application was motivating and research will be continued in the coming months. After pivoting to use the freely available data sets online a lot of research was done in the basics of machine learning and the connection of household income as it relates to mental health, which showed a strong connection to worse mental health with low income countries. The entire experience left a strong urge to move forward with machine learning research in the future and showed just the tip of what is possible and what kind of positive change machine learning will have on the world. Thanks for the invitation to take part in this hackathon and look forward to returning in the future.
References:
- Ritchie H, Roser M. Mental Health [Internet]. Our World in Data. 2018 [cited 2019Apr7]. Available from: https://ourworldindata.org/mental-health#prevalence-of-mental-health-and-substance-use-disorders
Built With
- microsoft

Log in or sign up for Devpost to join the conversation.