Inspiration
The Problem: As organizations grow, talent tends to become invisible. When a manager needs someone with specific expertise, they don't have a way to find them beyond asking colleagues or guessing based on job titles. A developer who knows Kubernetes might be hidden in the ops team. A designer with machine learning experience might be unknown to the AI team.
Why It Matters:
- Teams struggle to form because expertise is undiscovered
- Projects get delayed waiting for the "right person"
- Cross-functional collaboration is harder than it needs to be
- Employee skills go underutilized
- New hires can't find mentors or collaborators with shared interests
Our Solution: dobrandoCulleres (Galician for "bending spoons") is an intelligent talent discovery platform that makes invisible expertise visible. We use AI-powered semantic search to help organizations instantly find the right people for any project.
What It Does
Core Features
1. Intelligent Skill Discovery
- Semantic skill search using vector embeddings (Ollama + pgvector)
- Find experts even when you don't know the exact skill name
- Search "golang" and find people with "Go", "Go programming", "Golang", etc.
- Relevance-ranked results by skill level and match score
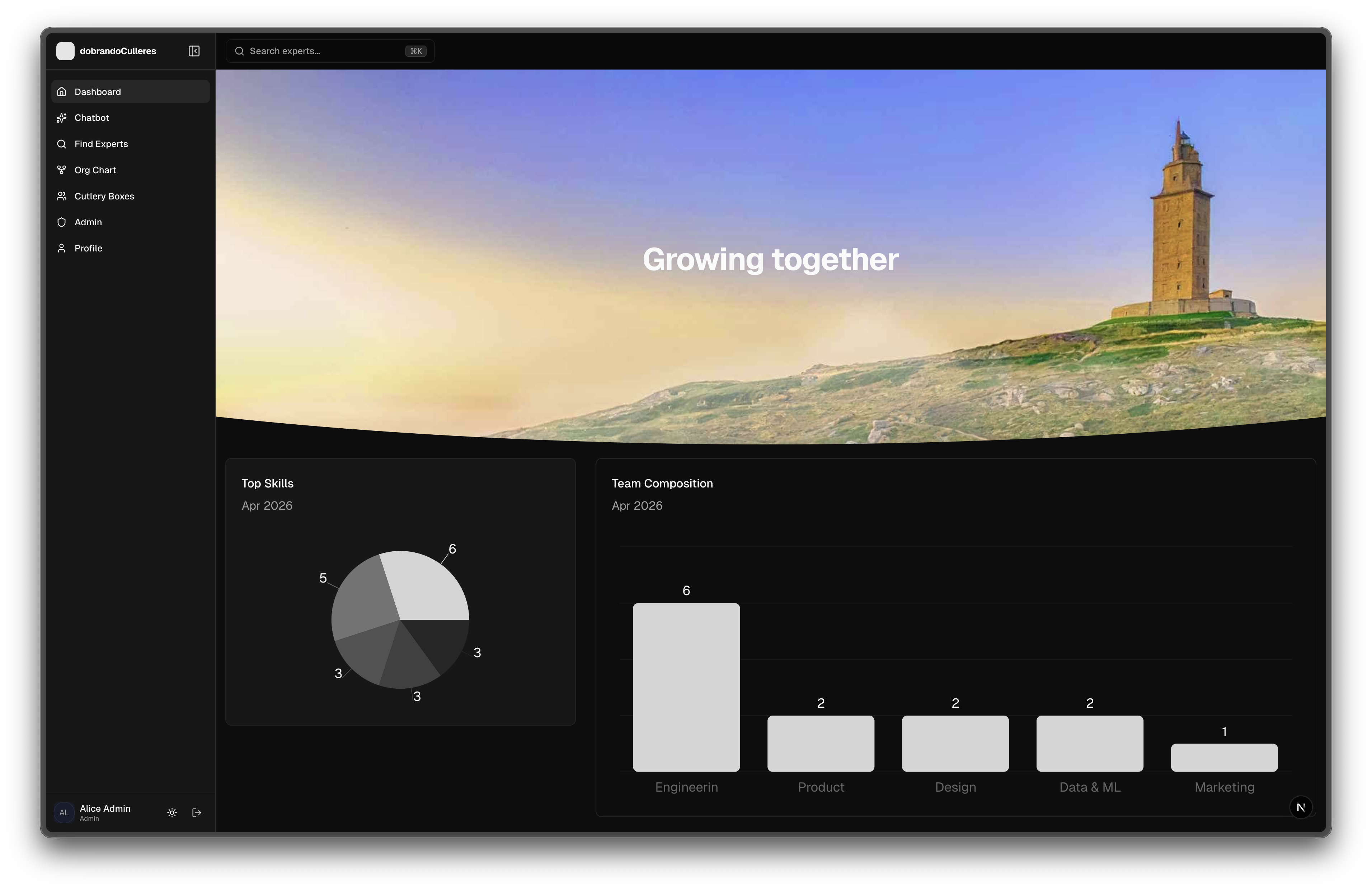
2. Team Intelligence
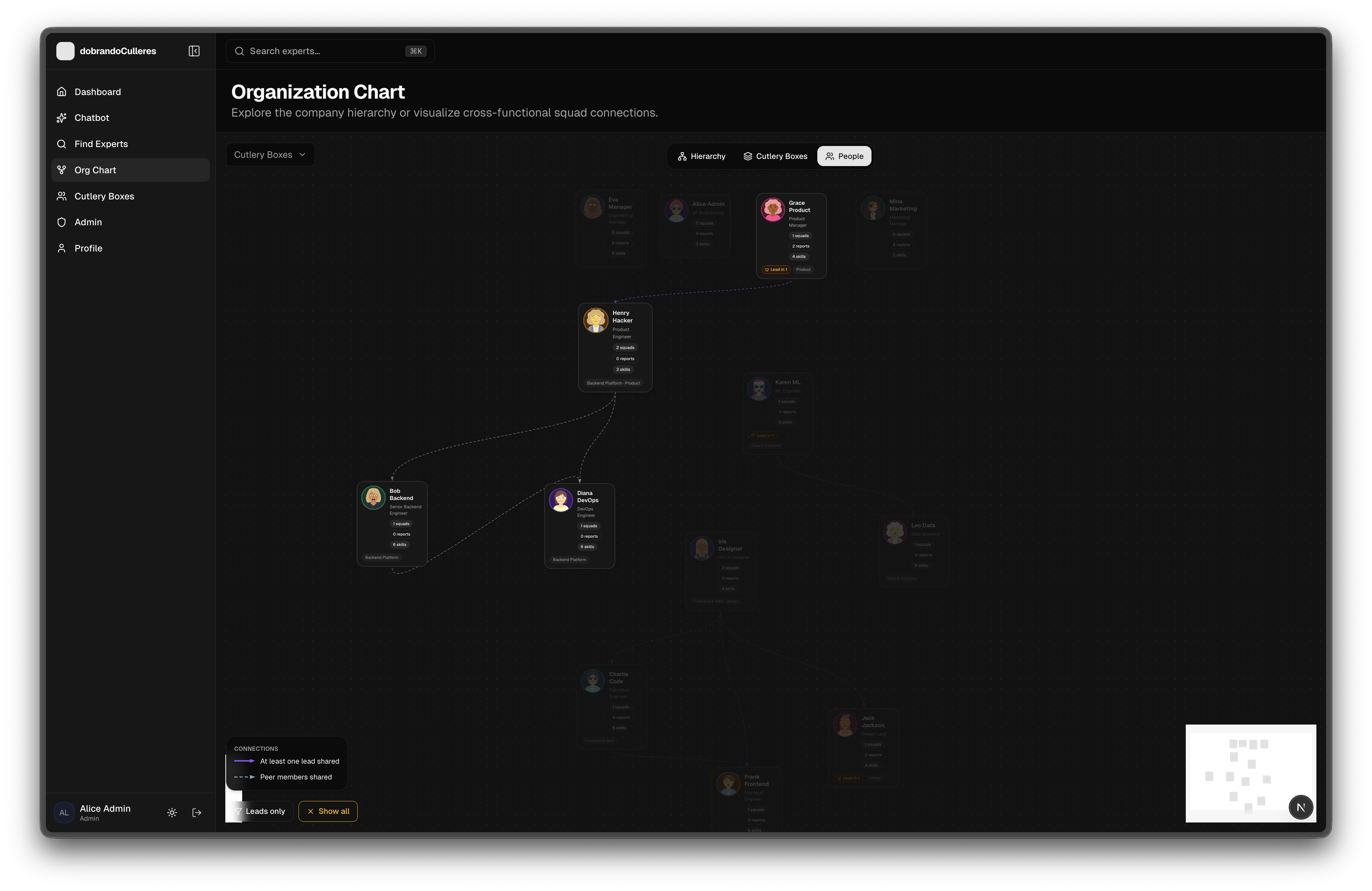
- Organize employees into groups/teams with designated leaders
- View organizational hierarchy with interactive org charts
- See team composition and skill distribution
- Track which skills exist in which teams
3. Expert Finder
- Search for experts across multiple dimensions:
- By skill keywords (semantic matching)
- By specific skills with level filters
- By department or team
- By skill level (beginner to expert)
- Get relevance-scored results showing match confidence
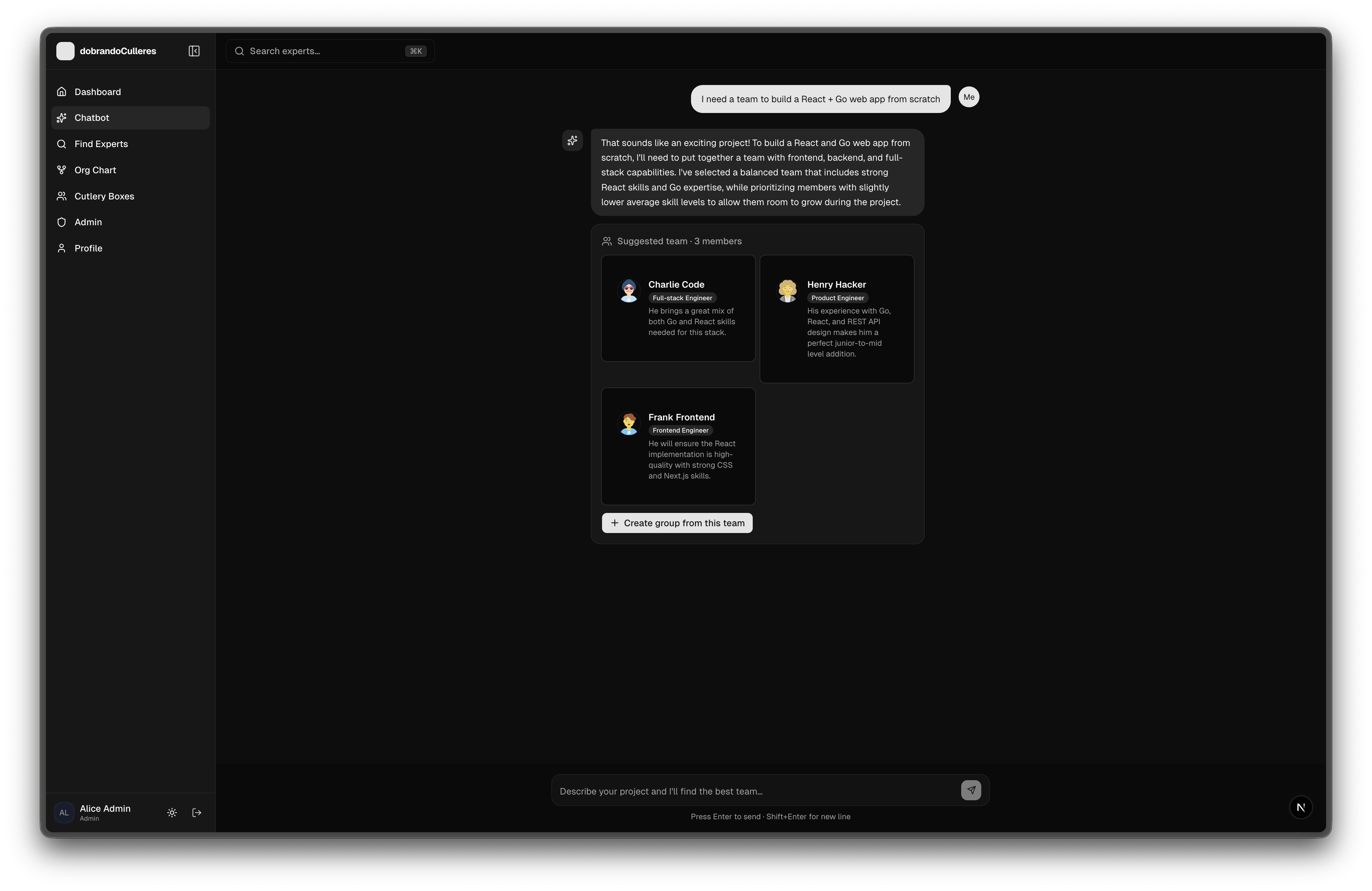
4. AI-Powered Chatbot
- Chat interface to ask for team recommendations
- Natural language queries: "Who can help with Kubernetes?"
- Get team suggestions for specific project needs
- Discover expertise patterns in your organization
5. User Management & Admin Tools
- Comprehensive user profiles with job titles and departments
- Skill management with proficiency levels (1-5)
- User roles (Admin, Manager, Employee) with role-based access control
6. Multi-Language Support
- Built-in internationalization
- Language-specific routing
- Support for multiple locales
How We Built It
Technology Stack
Frontend: Modern React Ecosystem
- Next.js
- React
- TypeScript
- Tailwind CSS
- Radix UI (accessible components)
- React Query
- React Hook Form + Zod (form validation)
- Framer Motion
- XY Flow (interactive diagrams for org charts)
Backend: Go + PostgreSQL
- Go
- PostgreSQL
- pgvector (vector embeddings)
- Ollama (local embedding generation)
- Gorilla Sessions
Architecture Decisions
Why Go for the Backend?
- High-performance API suitable for real-time search
- Excellent concurrency handling
- Easy deployment (single binary)
- Built-in HTTP support
Why Vector Embeddings?
- Semantic search works beyond keyword matching
- Users can search in natural language
- Skill similarity detection (Kubernetes ≈ K8s ≈ container orchestration)
- Scalable with pgvector (native PostgreSQL support)
Why Next.js?
- Server-side rendering
- API routes for backend integration
- Built-in optimization (image, font, code splitting)
- Natural i18n support
Key Implementation Details
Skill Matching Pipeline:
- User creates/searches for a skill
- Text is embedded using Ollama's
mxbai-embed-largemodel - Embedding is stored in PostgreSQL pgvector column
- Vector similarity search finds related skills
- Results ranked by cosine similarity
Authentication & Authorization:
- Cookie-based sessions with 30-minute timeout
- Role hierarchy: Admin → Manager → Employee
- Middleware enforces permissions at API level
- Session keys configured via environment variables
Challenges We Ran Into
1. Vector Embedding Complexity
Implementing semantic search with vector embeddings was new territory for most of our team. Solution:
- Studied pgvector documentation thoroughly
- Tested embedding quality with various models
2. UI/UX for Complex Features
Making skill search and team recommendations intuitive for non-technical users. Solution:
- Used familiar patterns (search bars, filters)
- Clear labeling and help text
- Interactive org charts for visualization
- Chatbot as natural language interface
Accomplishments We're Proud Of
1. Intelligent Semantic Search
- Implemented vector embeddings from scratch
- Skill matching that understands synonyms and similar concepts
- Fast search even with large datasets (pgvector is optimized)
- Relevance ranking by match score
2. AI Integration
- Chatbot feature that understands natural language queries
- Demonstrates practical AI application (not just a demo)
3. Multi-Language Support
- Built internationalization from day one
- Language-aware routing
What We Learned
Technical Learnings
Vector Embeddings Are Powerful
- They enable semantic search that keyword-matching can't do
- The quality of embeddings matters a lot
- pgvector brings vector search to PostgreSQL efficiently
Go is Perfect for APIs
- Incredibly fast to build REST APIs
- Deployment is simple (single binary)
Built With
- gemma4
- go
- next.js
- ollama
- postgresql
- radix



Log in or sign up for Devpost to join the conversation.