
Inspiration
Genomic sequencing is becoming more accessible than ever, yet the results remain locked behind a wall of medical jargon. Most patients receive their life-altering data in dense, jargon-heavy PDFs. Terms like "allele frequencies," "oncogenicity," and "somatic clinical impact" mean very little to the average person without a medical degree. We were inspired by the belief that health literacy is a human right. We wanted to create a tool that uses thoughtful UI/UX design and data visualization to bridge the gap between complex biology and real human understanding.
What it does
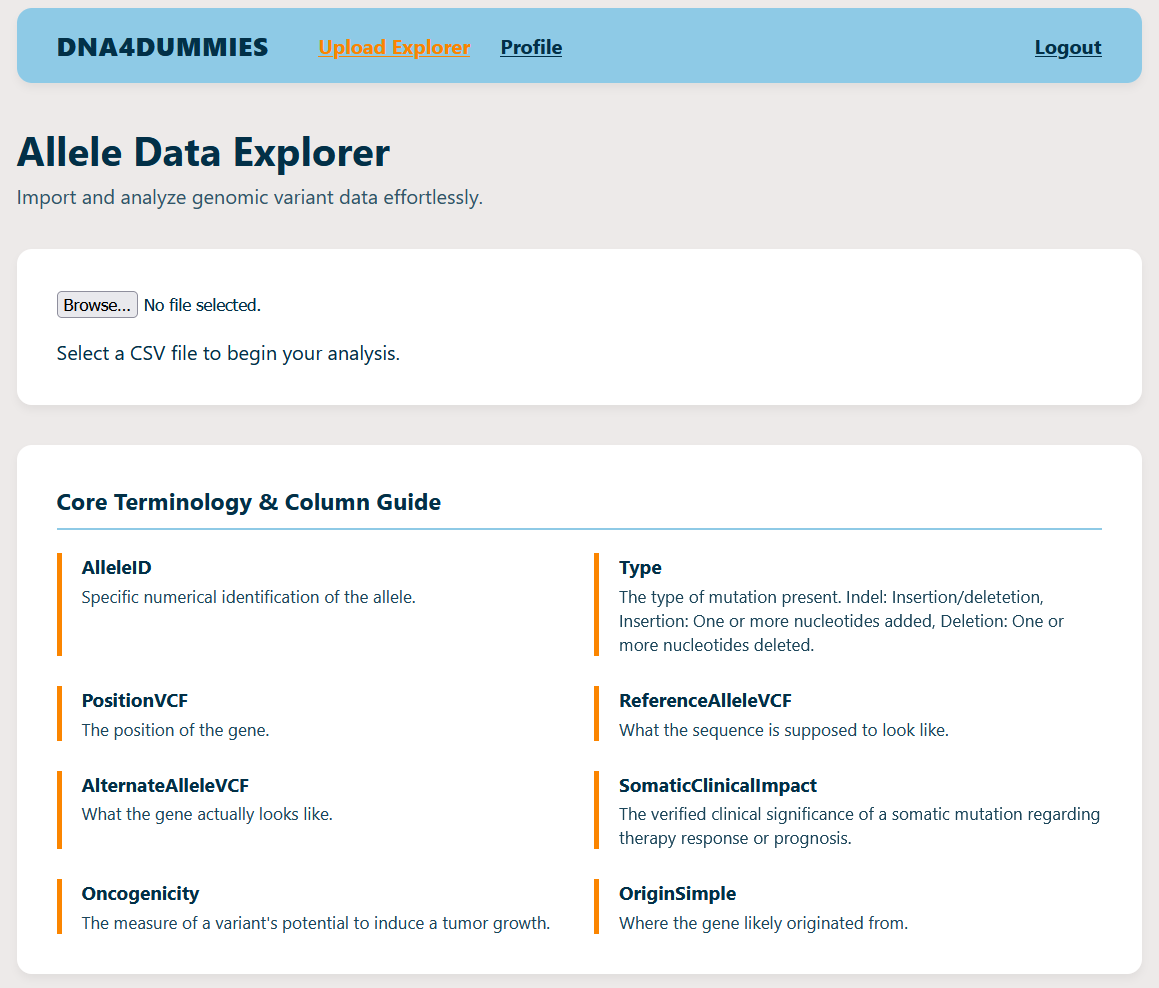
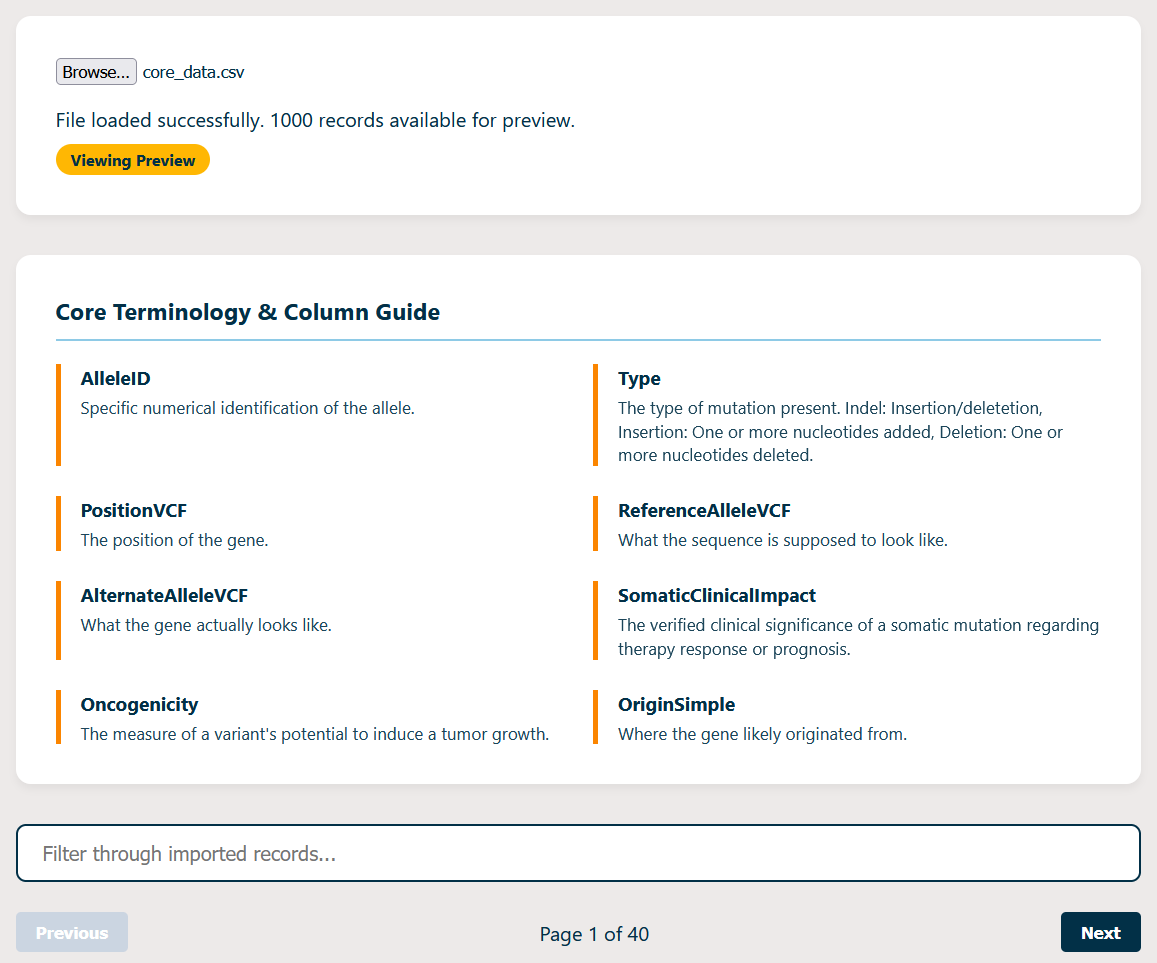
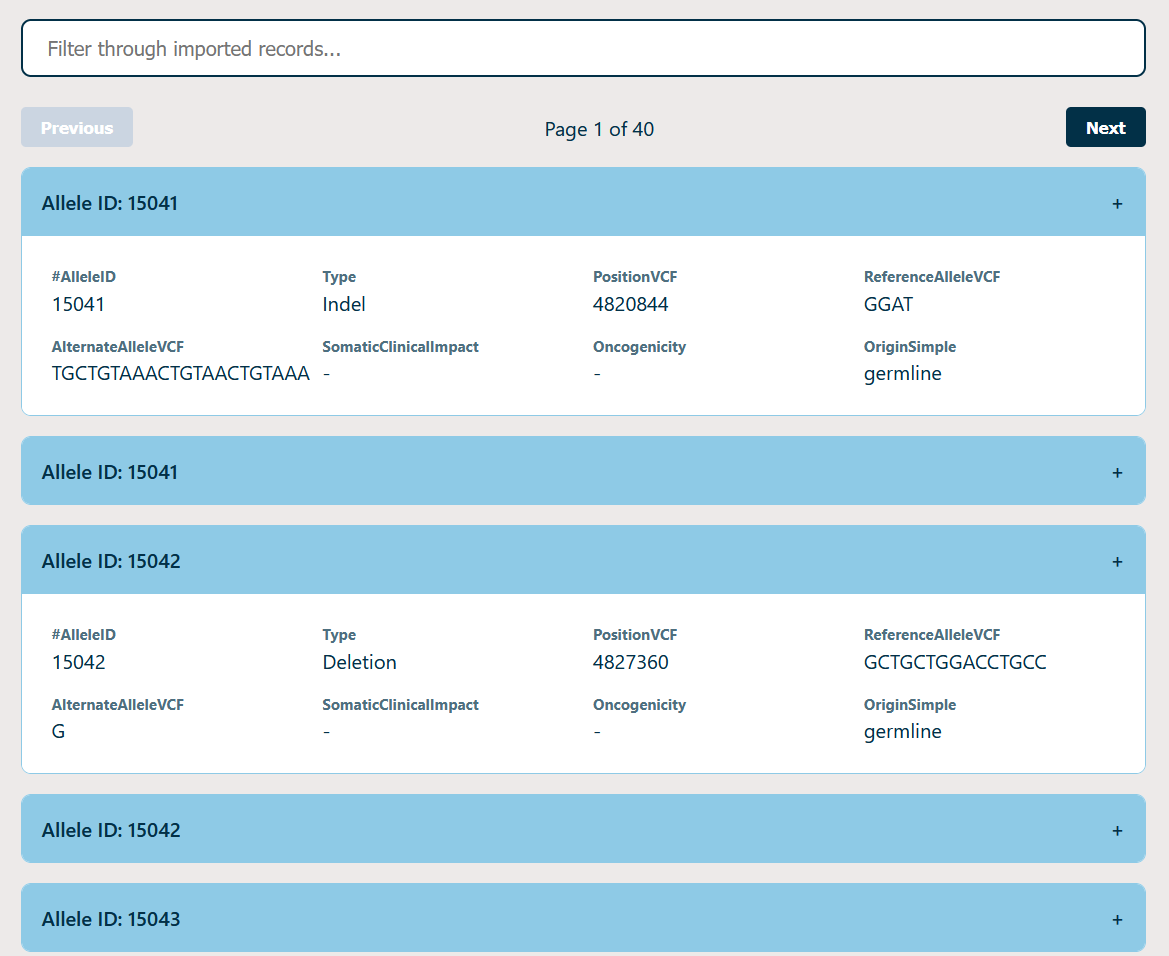
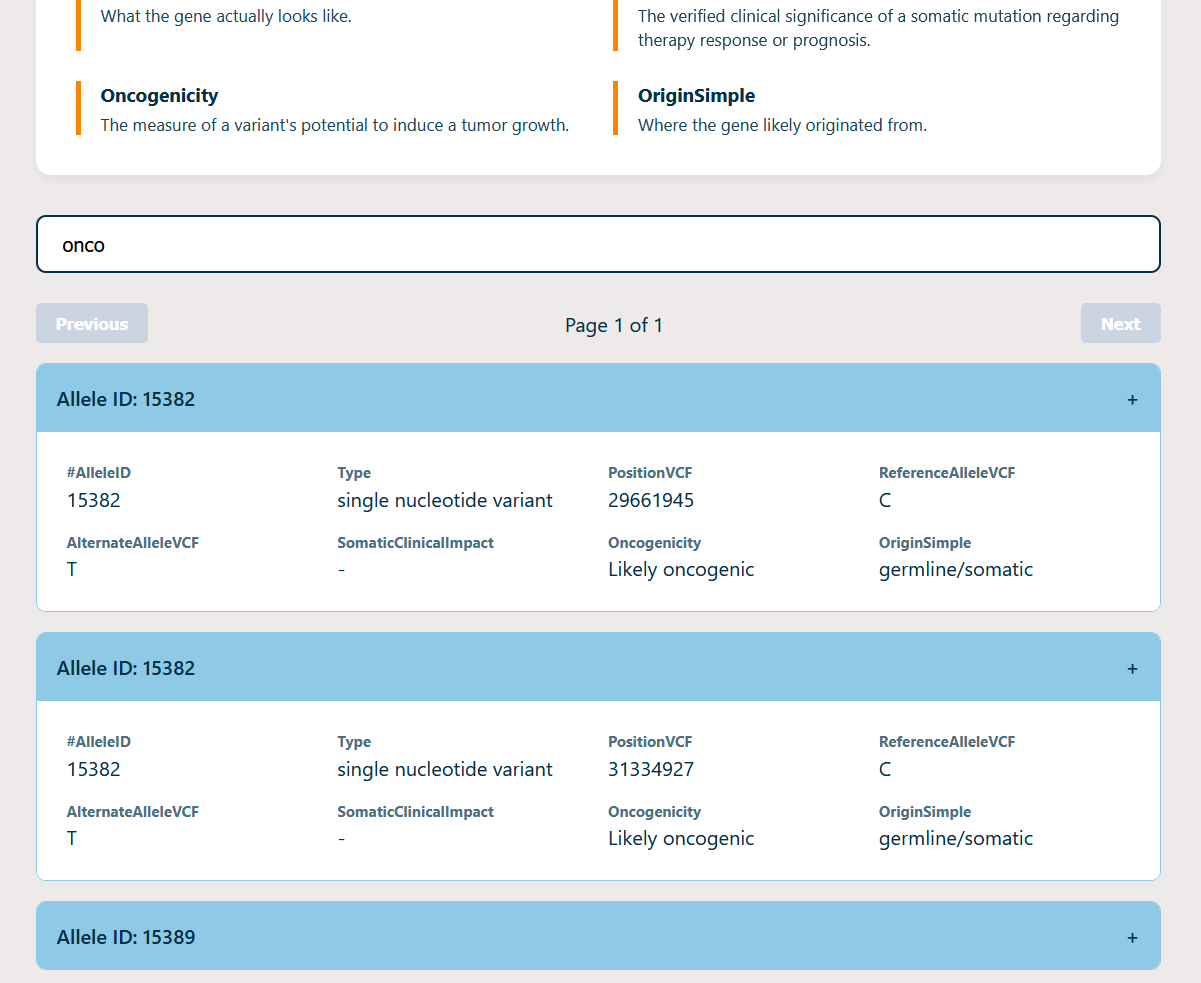
DNA4DUMMIES is an interactive web portal that transforms raw genomic variant datasets into a simplified, navigable dashboard. Users can upload their variant files (such as ClinVar data) and see their genetic information presented in a clean, card-based interface. Instead of a spreadsheet of numbers, they get a searchable explorer that helps them identify key variants and understand what those variants mean for their health.
How we built it
The project was built focusing on frontend clarity and local data processing:
Frontend: HTML5 and CSS3 with a custom designed navy and orange theme to ensure a professional yet accessible feel.
Data Parsing: We used PapaParse to handle the heavy lifting of parsing large, tab-delimited genomic files directly in the browser. These files were genuinely massive, so PapaParse made sure all the important data was loaded in a reasonable amount of time.
Architecture: A multi-page application structure featuring secure login/signup, a user profile and a main upload explorer for data interaction.
Challenges we ran into
One of the biggest hurdles was data scale. Genomic files can contain hundreds of thousands of rows. Loading all of that into a browser DOM would crash a lot of devices. We had to implement client-side pagination and optimized filtering to ensure the UI loaded in a reasonable time even when searching through large datasets. Another challenge was deciding which columns to show and which to hide to avoid overwhelming the patient while still providing accurate medical data. We made sure to stick to data that was the most helpful to the user directly and in the future we would like to implement a confidence scale for each entry.
Accomplishments that we're proud of
The website doesn't crash!!! The extremely large data file made it difficult to ensure page stability. For the demonstration, we cut the data to only the first 1000 rows for speed, but the page can handle much more! We also all greatly improved out HTML5 skills, learning new techniques for data management and UI/UX design.
What we learned
One of our biggest challenges previously was our issues with photo uploads. This year we were able to create not just a stable upload for pictures, but also an upload for large files. We also learned a lot about data management and the best strategies to handle and parse these files. We got to learn a lot about medical-jargon as well! In order to figure out what columns were important, we had to learn a lot about what was actually in these files. Then we needed to be able to simply and clearly explain what each term meant.
What's next for DNA4DUMMIES
The future of DNA4DUMMIES is about integration and education:
EHR Integration: We aim to connect directly with electronic health records so patients don't even have to manually upload files.
AI Tailoring: Incorporating Large Language Models to provide personalized, simplified explanations based on a user’s specific educational background.
Global Genes Partnership: We hope to work with Global Genes (a non-profit started in 2008) to reach rare disease communities. We plan to seek grants to fund supplemental classes taught by educated volunteers to improve health literacy in schools.
Accessibility: Expanding support for multiple languages and screen readers to ensure that every population, regardless of background, can navigate their own DNA with confidence.

Log in or sign up for Devpost to join the conversation.