-
-
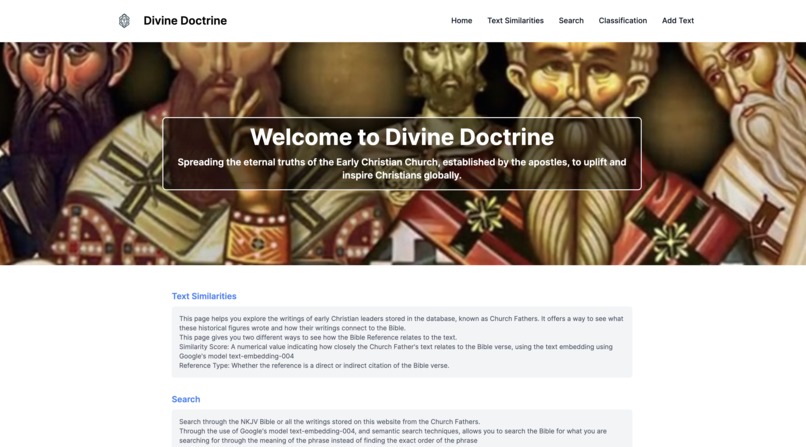
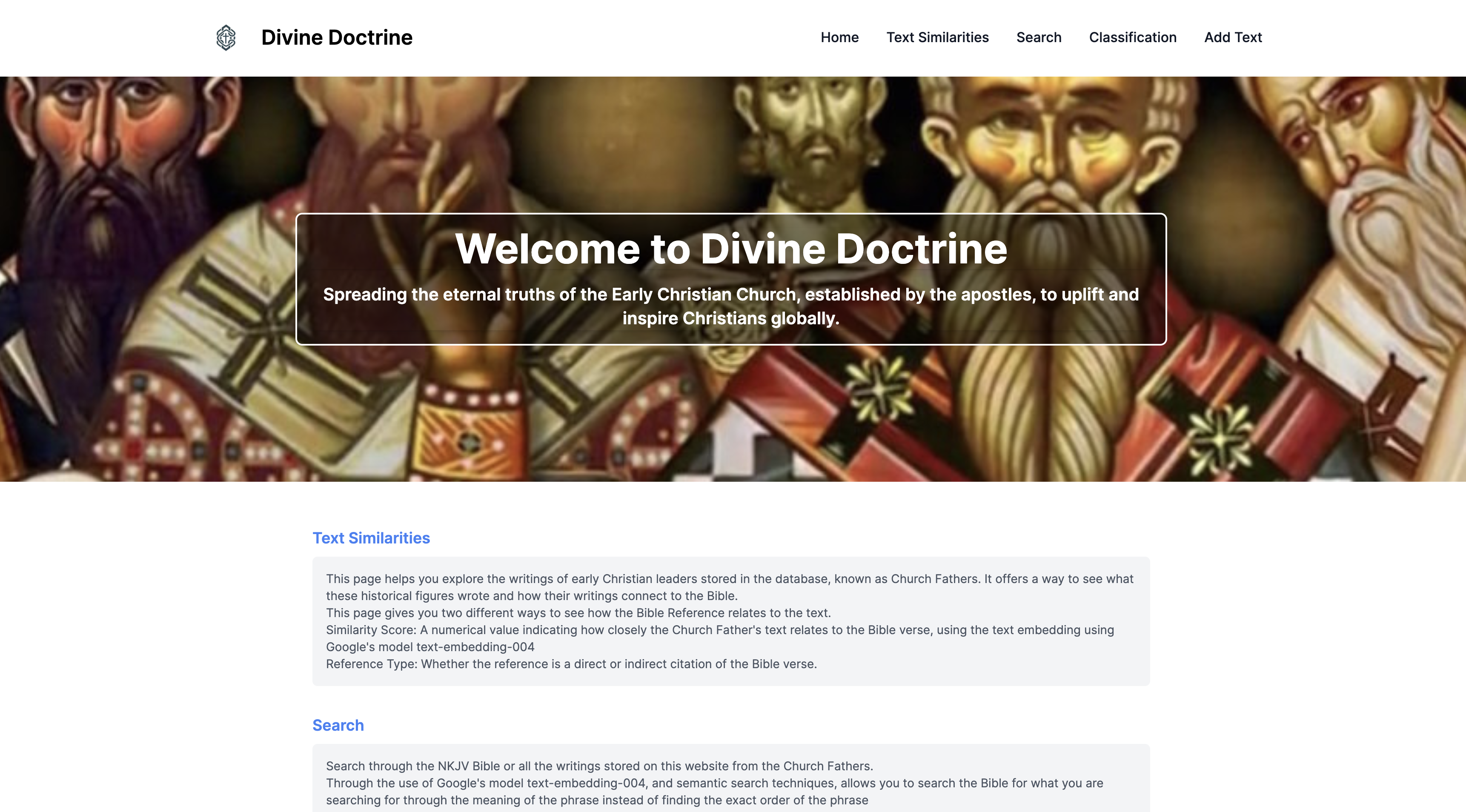
Divine Doctrine Website Screenshot
-

Divine Doctrine Logo

Inspiration
The inspiration behind the app I'm developing is rooted in the fact that Christians make up a substantial portion of the global population, totaling approximately 2.38 billion individuals out of the world's approximate 8 billion people. Despite this significant presence, many Christians lack easy access to the writings of early church fathers, which could greatly enrich their understanding of the Bible. By creating a platform that aggregates and makes these ancient texts more accessible, my goal is to bridge this gap and empower Christians from various denominations to delve deeper into their faith tradition. This initiative seeks to honor the legacy of figures like Saint John Chrysostom and others, whose wisdom continues to resonate across different branches of Christianity, thereby fostering a sense of unity and shared heritage among believers worldwide.
What it does
The Divine Doctrine app serves as a comprehensive platform that provides easy access to the writings of early church fathers, such as Saint John Chrysostom, for Christians worldwide.
This application allows you to explore the writings of early Christian leaders, also known as Church Fathers. It provides functionalities to:
- See what Church Fathers wrote and how their writings connect to the Bible.
- Search through the Bible and Church Father writings.
Key Features
Text Similarities
The "Text Similarities" section lets you explore how Church Father writings relate to the Bible. It offers two ways to view this relationship:
- Similarity Score: This is a numerical value calculated using Google's text-embedding model
text-embedding-004. It indicates how closely a Church Father's text relates to a specific Bible verse. - Reference Type: This indicates whether the Church Father's text directly cites the Bible verse or references it indirectly.
Search
The "Search" section provides a powerful search functionality:
- Search through the NKJV Bible or all Church Father writings stored on this website.
- Leverage Google's
text-embedding-004model and semantic search techniques. This allows you to search for meaning rather than exact phrasing.
Classification
The "Classification" section showcases the four different machine learning models trained for this application and the data used to train them.
Add Text
The "Add Text" section allows you to:
- Add text from a Church Father.
- See a related Bible verse extracted automatically.
- Classify the added text.
- Parse the text and make it searchable through the search function.
How I built it
Frontend:
- Tailwind
- Next.js
Backend:
- Python hosted on render (Classification ednpoint)
- Firestore
- Pinecone Vector Embedding Database
To create the four different models versions of classifying text as bible verses I used Python and Google AI embedding models(text-embedding-004). I created a flask api to run these models on python through a service called Render to create these classifications.
Challenges I ran into
One of the main challenges I encountered was sourcing and digitizing the extensive collection of writings from early church fathers while maintaining authenticity and accuracy. The amount of space embeddings take is a lot and can not be stored on Firestore to query the data, so the best thing to do is to use a storage system like pinecone to store this data, as it allows you to both store a lot of embeddings, but also call this data easily finding the top k results with using cosine comparison between embeddings for example.
- Long text lose meaning in the embedding vector the more text, it has. Had to try to make texts as small as I could but at the same time do not make texts inserted to small, or that creates bad data points.
- Time: Models can take 10 hours to run depending how much data you are shifting through
- Google Gemini 1.5, is rate limited so it was better to use Google Gemini 1.0, and I had comparable results for what I was doing.
- Converting Keras models to javascript is not as easy as tutorials online make it seem. So I need to create my model next time with a more compatible type between python and javascript.
Accomplishments that I am proud of
Being able to simulate 3 different ways to use Google AI to enrich Christians lives. Also, this opens up so much possibility to train models to label texts or audio recordings according to the verse they are mentioning. I am proud that I figured out when you constrain an LLM model it is less likey to give bad results, because you give it a finite number of answers it can give.
What I learned
- If your data is not structured your embedding results will not be as good as you would want it to be.
- The longer your text the harder it is to create an embedding for that text.
- If the text is to short it can be an outlier that needs to be accounted for.
- Gemini LLM models are really good when you constrain them and give them all the information they need to give you an answer. That way the results are a lot more accurate according to my testings.
What's next for DivineDoctrine
- Create a better model for labeling that does not only rely on embeddings
- Structure the data more to get better results for search and labeling texts according to it's bible's reference.
- Allows, me to label the whole bible with commentaries people can read at any time, when clicking a verse.
Built With
- firestore
- flask
- googleai
- models/gemini-1.0-pro-latest
- next.js
- pinecone
- python
- tailwind
- text-embedding-004
- typescript


Log in or sign up for Devpost to join the conversation.